




В предыдущих главах мы определили наилучшую модель с двумя значимыми факторами - х3-стоимость автомобиля и х6 - стаж наименее опытного водителя. Теперь проверим линейность регрессии. Самый простой способ тестировать справедливость линейной спецификации модели – это добавить в правую часть нелинейные члены и тестировать их значимость. Воспользуемся RESET-тестом, который заключается в следующем: если модель  верна, то добавление нелинейных переменных не должно помогать объяснять y. В частности, можно добавлять степени:
верна, то добавление нелинейных переменных не должно помогать объяснять y. В частности, можно добавлять степени:  .То есть выдвигается гипотеза Н0 о том, что:
.То есть выдвигается гипотеза Н0 о том, что:  Используем статистику Фишера для сравнения «короткого» и «длинного» уравнения:
Используем статистику Фишера для сравнения «короткого» и «длинного» уравнения:
 ,
,
где R20 – коэффициент детерминации короткой регрессии, который равен 0,8908, а R20 – коэффициент детерминации длинной регрессии, который равен 0,8909.
Т.к. наблюдаемое значение меньше критического (Fкрит = 4,05), то гипотеза о линейности не отвергается на уровне значимости 0,05, вводить дополнительные нелинейные регрессоры не нужно. Заметим также, что все статистики значимы.
Регрессионная однородность выборки.
Далее, логично было бы проверить однородность нашей выборки. Исследуем, одинаково или нет различные группы водителей по стажу влияют на стоимость полиса КАСКО. С помощью Чоу-теста проверим, нужно ли рассматривать отдельно случаи, когда водитель за рулем меньше 5 лет и случаи, когда водитель обладает стажем больше 5 лет. То есть построим регрессионные уравнения по двум подвыборкам:  , где х6 от 0 до 5, и
, где х6 от 0 до 5, и  , где стаж больше 5.
, где стаж больше 5.
Выдвигается следующая гипотеза: H0 :  , то есть не нужно разбивать выборку на подвыборки.
, то есть не нужно разбивать выборку на подвыборки.
Гипотеза проверяется на основе F статистики:
 . Коэффициент значим на уровне значимости 0,05.
. Коэффициент значим на уровне значимости 0,05.
На основе этого, можем сделать вывод о том, что первоначальная выборка неоднородна и юных и «опытных» водителей нужно рассматривать отдельно при изучении стоимости полиса автострахования каско.
Проверка спецификации ошибок.
Нормальность.
Как уже упоминалось в предыдущей главе, модель называется нормальной линейной регрессией в случае, когда ошибки  имеют совместное нормальное распределение:
имеют совместное нормальное распределение: 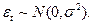 То есть на данном этапе анализа необходимо проверить следующую гипотезу: H0:
То есть на данном этапе анализа необходимо проверить следующую гипотезу: H0:
Сперва воспользуемся критерием Харке- Бера.
Если нулевая верна, то при достаточно больших выборках, статистика Харке-Бера (JB) имеет распределение, близкое к распределению Х2.
Если распределение ошибок действительно является нормальным, то значения выборочного коэффициента асимметрии (Аs) близки к нулю, а значения выборочного куртозиса (Кs) близко к трем. Поэтому гипотеза нормальности ошибок отвергается, если
значения этой статистики «слишком велики», т.е когда JB > X2.
В данном случае:

 , коэффициент асимметрии = 0,53, а куртозис 3,76.
, коэффициент асимметрии = 0,53, а куртозис 3,76.
Нулевая гипотеза принимается на уровне значимости 0,05, т.к JB < Х2крит, который равен 5,99. Соответственно, если мы построим гистограмму остатков, то приближение к нормальному закону распределения не может остаться незамеченным.

Рисунок 6 График остатков
Однако стоит заметить, что критерий Харке-бера является асимптиточеским, то есть распределение статистики JB приближается распределением Х2 только при большом числе наблюдения n. Т.к. мы исследуем выборку все из 50 единиц, то следует проверить нормальность остатком и другими способами, для достоверности результатов.
По такому же принципу, проверим с помощью критерия Колмагорова-Смирнова и критерия согласия Пирсона выдвинутую ранее гипотезу о нормальном распределении ошибок, а результаты вычислений сведем в следующую таблицу для наглядности:
| критерий | статистика | набл. зн. | крит. знач. | значимость |
| Колмогорова-Смирнова | D | 0,112 | 0,895 | 0,050 |
| Согласия Пирсона | X2 | 6,664 | 7,879 | 0,005 |
Таблица 15 Критерии на нормальнось
Как видно из таблицы, наблюдаемые значения статистик не превосходят критические, что говорит о нормальности распределения ошибок. Нулевая гипотеза не отвергается на уровне значимости 0,05 всеми тремя методами. Соответственно, модель  - является нормальной линейной регрессией.
- является нормальной линейной регрессией.
Гомоскедастичность.
Понятие гетероскедастичность говорит о том, что ошибки некоррелированы, но имеют непостоянные дисперсии. (Классическая модель с постоянными дисперсиями ошибок называется гомоскедастичной). Гетероскедастичность возникает, если анализируемые объекты, говоря нестрого, неоднородны. Например, в нашем случае, при исследовании зависимости полиса автострахования КАСКО от цены автомобиля, можно ожидать, что для иномарок класса люкс колебание цены полиса будет выше, чем у отечественных автомобилей.
Для краткости, исследуем влияние только одного фактора – стоимости автомобиля на цену полиса.
Тест Спирмена основан на статистике  , где
, где  =-0,03.
=-0,03.
Выдвигаем гипотезу о том, что p0=0, p0 в свою очередь является коэффициентом корреляции между модулем ошибок и регрессором. Так как tнабл (-0,22) < tкрит (2,01), следовательно нулевая гипотеза не отвергается, то есть корреляции между ними нет - гетероскедастичности нет.
Тест Голфелда-Куандта применяется, как правило, когда есть предположение о прямой зависимости дисперсии от величины некоторой зависимой переменной.
Идея состоит в следующем: выборка делится на три части, так, что первая и третья части равны и примерно составляют три четверти всех наблюдений. Далее оцениваются регрессии по первой и третьей частям выборки. Проверяется гипотеза о равенстве остаточных дисперсий для этих моделей:  .
.
| группа 1 | группа 3 | ||||
| коэффиц-ты | СКО | коэффиц-ты | СКО | ||
| свободный член | 398,09 | 569,12 | 1655,76 | 588,42 | |
| переменная | 0,0020 | 0,0011 | 0,0004 | 0,0007 | |
| R2=0,16 n=19 ст.ош.= 380 | R2=0,02 n=19 ст.ош.= 417 | ||||
Таблица 16 Тест Годфелда-Куандта
Используется статистика Фишера в виде отношения суммы квадратов остатков, причем, большее значение делится на меньшее значение: F=1,206. Наблюдаемое значение меньше критического (2,27), то есть гипотеза не отвергается, следовательно, выборка однородна, это свидетельствует о гомоскедастичности. Если бы гипотеза отвергалась, то следовало бы осуществить поправки Уайта или Нью-Веста.
Тест Бреуша-Пагана применяется в тех случаях, когда априорно предполагается, что дисперсии зависят от некоторых дополнительных переменных:.  Тогда нулевая гипотеза задается следующим образом:
Тогда нулевая гипотеза задается следующим образом:  , которая проверяется на основе
, которая проверяется на основе  . Наблюдаемое значение статистики 0,31меньше критического 3,84. На основе всего вышесказанного, можем сделать вывод: гипотеза о равенстве коэффициентов новой регрессии Z нулю отвергается на уровне значимости 0,05. Гетероскедастичность отсутствует.
. Наблюдаемое значение статистики 0,31меньше критического 3,84. На основе всего вышесказанного, можем сделать вывод: гипотеза о равенстве коэффициентов новой регрессии Z нулю отвергается на уровне значимости 0,05. Гетероскедастичность отсутствует.
Тест Уайта говорит о том, что если в модели присутствует гетероскедастичность, то это связанно с тем, что дисперсии ошибок некоторым образом зависят от регрессоров, а гетероскедастичность должна как-то отражаться в остатках обычной регрессии исходной модели. Строится регрессия квадратов остатков на исходные регрессоры, их квадраты,
произведения и константу:  .
.
Гипотеза Н0:  Для проверки гипотезы используется Х2 статистика. Наблюдаемое значение Х2 = nR2 =0,93, тогда как X2кр=5,99 => о гомоскедостичности не отвергается.
Для проверки гипотезы используется Х2 статистика. Наблюдаемое значение Х2 = nR2 =0,93, тогда как X2кр=5,99 => о гомоскедостичности не отвергается.
Тест Бартлетта предполагает существование l групп наблюдений с близкими значениями регрессора. Проверяется гипотеза о равенстве дисперсий ошибок для этих групп: Ϭ21=Ϭ22=Ϭ23. Для проверки гипотезы используется статистика  , которая равна 1,25, что меньше критического значения 5,99. Следовательно, гипотеза о равенстве дисперсий выборок не отвергается. Гетероскедастичности нет.
, которая равна 1,25, что меньше критического значения 5,99. Следовательно, гипотеза о равенстве дисперсий выборок не отвергается. Гетероскедастичности нет.
Все разобранные в данной главе критерии отвергли гетероскедастичность, а значит, дисперсии ошибок в данной модели не зависят от значений регрессоров и являются однородными.
Автокорреляция.
Следующим этапом в проверке спецификации ошибок является изучение сериальной корреляции. Автокоррелированность ошибок обычно возникает вследствие неправильной спецификации модели, например, при невключении в модель существенной объясняющей переменной с выраженной автокорреляцией, что приводит к негативным последствиям. Так, в случае положительной автокоррелированности ошибок, стандартные оценки дисперсий случайных величин оказываются заниженными, а при отрицательной – завышенными.
Проведем краткий графический анализ и посмотрим на зависимость остатков от номеров наблюдений. Если наблюдаются серии остатков, имеющих одинаковые знаки, то это характерно для моделей, в которых имеется положительная автокоррелированность ошибок. Если же знак остатков чередуется – то, скорее всего, есть отрицательная коррелированность ошибок.

Рисунок 7 График проверка остатков на автокорреляцию
Данный график не дает четкой картины о наличии или отсутствии автокорреляции и о ее знаке, т.к. одновременно присутствуют «зубчатые» перепады и «волны» с одинаковым знаком.
Для точного определения автокорреляции воспользуемся следующими тестами: Бокса-Пирса, Льюинга-Бокса, z-тест, Дарбина-Уотсона и Бреуша-Годфри.
Большинство тестов исследуют идею: если корреляция есть у ошибок, то она присутствует и в остатках, получаемых после применения к модели обычного метода наименьших квадратов. Автокорреляционная функция имеет следующий вид:  , где t=1,2…n. Выдвигается следующая гипотеза: Н0 : p(m)=0.
, где t=1,2…n. Выдвигается следующая гипотеза: Н0 : p(m)=0.
Наиболее широко используется тест Дарбина –Уотсона, который основан на статистике:
 , в данном случае – первый порядок. При этом считается, что постоянный член включен в число регрессоров. Тогда, проводя элементарные преобразования, не трудно заметить, что эта статистика тесно связанна с выборочным коэффициентом корреляции между
, в данном случае – первый порядок. При этом считается, что постоянный член включен в число регрессоров. Тогда, проводя элементарные преобразования, не трудно заметить, что эта статистика тесно связанна с выборочным коэффициентом корреляции между  и
и  ,а именно: DW ~ 2(1-r). Отсюда следует что, если в остатках существует полная положительная автокорреляция и r = 1, то DW = 0. Если в остатках полная отрицательная автокорреляция, то r = – 1 и, следовательно, DW = 4. Если автокорреляция остатков отсутствует, то r = 0 и d = 2. Следовательно, 0 < DW< 4. Однако, чтобы понять отвергается или принимается первоначальная гипотеза – знать значение статистики DW недостаточно. Специфичность данного теста заключается в необходимости определения границ du – верхней и dl –нижней, что можно сделать с помощью специальной таблицы. Тогда: если (4-dl < DW < 4),то нулевая гипотеза отвергается и есть отрицательная корреляция, если (0 < DW < dl) – есть положительная корреляция, а если (du < DW < 4-du), то гипотеза не отвергается. Так же есть ситуации неопределенности: (4-du < DW < 4-dl) и (dl < DW < du), то есть, нет оснований для того, чтобы принять или отвергнуть гипотезу. Схематично можно изобразить следующим способом:
,а именно: DW ~ 2(1-r). Отсюда следует что, если в остатках существует полная положительная автокорреляция и r = 1, то DW = 0. Если в остатках полная отрицательная автокорреляция, то r = – 1 и, следовательно, DW = 4. Если автокорреляция остатков отсутствует, то r = 0 и d = 2. Следовательно, 0 < DW< 4. Однако, чтобы понять отвергается или принимается первоначальная гипотеза – знать значение статистики DW недостаточно. Специфичность данного теста заключается в необходимости определения границ du – верхней и dl –нижней, что можно сделать с помощью специальной таблицы. Тогда: если (4-dl < DW < 4),то нулевая гипотеза отвергается и есть отрицательная корреляция, если (0 < DW < dl) – есть положительная корреляция, а если (du < DW < 4-du), то гипотеза не отвергается. Так же есть ситуации неопределенности: (4-du < DW < 4-dl) и (dl < DW < du), то есть, нет оснований для того, чтобы принять или отвергнуть гипотезу. Схематично можно изобразить следующим способом:

Рисунок 8 Правило определения гипотезы Дарбина-Уотсона
Наконец, после разбора спецификации метода, можем проверить нашу модель на присутствие автокорреляции. Для данной задачи DW = 2,12, нижняя граница dl=1,36, а верхняя граница du=1,4[1]. Тогда, (4-du =2,6 > DW > du), то есть гипотеза от отсутствии автокорреляции принимается на уровне значимости 0,05.
Проверим полученный вывод с помощью теста Бреуша-Годфри. Практическое применение теста также заключается в оценивании методом наименьших квадратов, однако по сравнению с тестом Дарбина-Уотсона, тест Бреуша- Годфри имеет весомые преимущества: во-первых, нет зоны неопределенности, а, во-вторых, в число регрессоров могут входить остатки не только с 1 лагом, но и 2,3 и т.д, что позволит выявить корреляцию не только между соседними, но и между более отдаленными переменными.
Исследуется модель:  . Нулевая гипотеза выглядит следующим образом:
. Нулевая гипотеза выглядит следующим образом:  .
.
В нашем случае была рассмотрена авторегрессионная зависимость остатков от их предыдущих значений с помощью модели 3-ого порядка.. Применяя МНК, получили следующее: 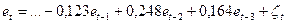 . Ни один из коэффициентов при et-m незначим, P-значения соответственно равны 0,43, 0,1 и 0,29. Однако все же рассчитаем статистику X2набл =nR2 . Критическое значение X2крит =7,81, что явно больше наблюдаемого (4,22). То есть, гипотеза об отсутствии автокорреляции до третьего порядка включительно принимается на уровне значимости 0.05.
. Ни один из коэффициентов при et-m незначим, P-значения соответственно равны 0,43, 0,1 и 0,29. Однако все же рассчитаем статистику X2набл =nR2 . Критическое значение X2крит =7,81, что явно больше наблюдаемого (4,22). То есть, гипотеза об отсутствии автокорреляции до третьего порядка включительно принимается на уровне значимости 0.05.
Проведем еще несколько тестов[2] на автокорреляцию. Нулевая гипотеза остается той же. Данные занесем в таблицу для наглядности:

Таким образом, все проведенные тесты указывают на отсутствие автокорреляции, что можно объяснить совершенными знаниями о причинах и взаимосвязях, определяющих то или иное значение стоимости полиса автострахования КАСКО.
Коррекция МНК-оценок и процедуры ДОМНК.

