




Самой ранней і наиболее известной является классификация архитектур обчислювальних систем, предложенная в 1966 году М.Флинном (Flynn). Классификация базируется на понятии потока, под которим понимается последовательность элементов, команд чи данних, обрабативаемая процессором. На основе числа потоков команд і потоков данних Флинн виделяет четире класса архитектур:
- SISD = Single Instruction Single Data
- MISD = Multiple Instruction Single Data
- SIMD = Single Instruction Multiple Data
- MIMD = Multiple Instruction Multiple Data)
- SISD (single instruction stream / single data stream) - одиночний поток команд і одиночний поток данних. Вообще говоря, эта архитектура не имеет отношения к високопроизводительним системам. К этому классу відносяться, прежде всего, классические последовательние машини. В таких машинах есть только один поток команд, все команди обрабативаются последовательно друг за другом і каждая команда инициирует одну операцию с одним потоком данних. Не имеет значения тот факт, що для увеличения скорости обробки команд і скорости виполнения арифметических операцій может применяться конвейерная обробка. В случае векторних систем векторний поток данних следует рассматривать як поток з одиночних неделимих векторов.
MISD (multiple instruction stream / single data stream) - множественний поток команд і одиночний поток данних. Определение подразумевает наличие в архитектуре многих процессоров, обрабативающих один і тот же поток данних. Однако ни Флинн, ни другие специалисти в области архитектури компьютеров до сих пор не смогли представить убедительний пример реально существующей вичислительной системи, построенной на данном принципе. Ряд исследователей относят конвейерние машини к данному классу, однако это не нашло окончательного признания в научном сообществе. В качестве аналог работи такой системи, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду і що-то сделать с имеющимся банком данних. Поскольку база данних одна, а команд багато, то ми имеем дело с множественним потоком команд і одиночним потоком данних.
SIMD (single instruction stream / multiple data stream) - одиночний поток команд і множественний поток данних. В архитектурах подобного рода сохраняется один поток команд, включающий, векторние команди. Это позволяет виполнять одну арифметическую операцию сразу над многими данними - элементами вектора. Способ виполнения векторних операцій не оговаривается, поэтому обробка элементов вектора может производиться либо процессорной матрицей, либо с помощью конвейера.
MIMD (multiple instruction stream / multiple data stream) - множественний поток команд і множественний поток данних. Этот класс предполагает, що в вичислительной системе есть несколько устройств обробки команд, об’единенних в единий комплекс і работающих каждое со своим потоком команд і данних. Таким образом, в системе такого рода можно наблюдать реальное распараллеливание. Класс MIMD чрезвичайно широк, поскольку включает в себя всевозможние мультипроцессорние системи: В настоящее час он является чрезвичайно заполненним і возникает потребность в классификации, более избирательно систематизирующее архитектури, які попадают в один класс, но совершенно различни по числу процессоров, природе і топологии связи между ними, по способу организации пам’яті і, конечно же, по технологии программирования. Основная идея такой классификации может состоять, наприклад, в следующем. Считаем, що множественний поток команд может бить обработан двумя способами: либо одним конвейерним устройством обробки, работающем в режиме разделения часу для отдельних потоков, либо каждий поток обрабативается своим собственним устройством. Первая возможность используется в MIMD компьютерах, які обично називают конвейерними чи векторними, вторая - в параллельних компьютерах. В основе векторних компьютеров лежит концепция конвейризации, т.е. явного сегментирования арифметического устройства на отдельние части, каждая з яких виполняет свою подзадачу для пари операндов. В основе параллельного компьютера лежит идея использования для решения одной задачі нескольких процессоров, работающих сообща, причому процессори могут бить як скалярними, так і векторними. SMP архитектура
 |
Классификация Базу
По мнению А.Базу (A.Basu), любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых на этапе ее проектирования, а сам процесс проектирования представить в виде дерева. В самом деле, корень дерева - это вычислительная система (см. рисунок), а последующие ярусы дерева, фиксируя уровень паралелізму, метод реалізації алгоритма, параллелизм инструкций и способ управления, последовательно дополняют друг друга, формируя описание системы.
Способность выполнять более одной операции одновременно говорит о параллелизме на уровне команд (буква O на рисунке). Если же компьютер спроектирован так, что целые последовательности команд могут быть выполнены одновременно, то будем говорить о параллелизме на уровне задач (буква T).
Второй уровень в классификационном дереве фиксирует метод реалізації алгоритма. С появлением сверхбольших интегральных схем (СБИС) стало возможным реализовывать аппаратно не только простые арифметические операции, но и алгоритмы целиком. Например, быстрое преобразование Фурье, произведение матриц и LU-разложение относятся к классу тех алгоритмов, которые могут быть эффективно реализованы в СБИС'ах. Данный уровень классификации разделяет системы с аппаратной реализацией алгоритмов (буква C на схеме) и системы, использующие традиционный способ программной реалізації (буква P).
Третий уровень конкретизирует тип паралелізму, используемого для обработки инструкций машины: конвейеризация инструкций (Pi) или их независимое (параллельное) выполнение (Pa). В большей степени этот выбор относится к компьютерам с программной реализацией алгоритмов, так как аппаратная реализация всегда предполагает параллельное исполнение команд. Отметим, что в случае конвейерного исполнения имеется в виду лишь конвейеризация самих команд, разбивающая весь цикл обработки на выборку команды, дешифрацию, вычисление адресов и т.д., - возможная конвейеризация вычислений на данном уровне не принимается во внимание.
Последний уровень данной классификации определяет способ управления, принятый в вычислительной системе: синхронный (S) или асинхронный (A).
Описав основные принципы классификации, посмотрим, куда попадают различные типы параллельных вычислительных систем.
Изучение систолических массивов, имеющих, как правило, одномерную или двумерную структуру, показывает, что обозначения DCPaS и DCPaA могут быть использованы для их описания в зависимости от того, как происходит обмен данными: синхронно или асинхронно. Систолические деревья, введенные Кунгом для вычисления арифметических выражений могут быть описаны как OCPaS либо OCPaA по аналогичным соображениям. Матричные процессоры, в которых целое множество арифметических устройств работает одновременно в строго синхронном режиме, принадлежат к группе DPPaS.
Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда можно корректно описать в рамках предложенного формализма. Если процессоры дополнительно не используют параллелизм на уровне операций или данных, то для описания можно использовать лишь букву T. В противном случае, Базу предлагает использовать знак '*' между символами, обозначающими уровни паралелізму, одновременно присутствующие в системе.
Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной классификации. В этом случае для корректного описания автор использует знак '+'. Например, практически все векторные компьютеры имеют скалярную и векторную части, что можно описать как OPPiS+DPPiS (пример - это TI ASC и CDC STAR-100). Если в системе есть возможность одновременного выполнения более одной векторной команды (как в CRAY-1) то для описания векторной части можно использовать запись O*DPPiS, а полное описание данного компьютера выглядит так: O*DPPiS+OPPiS. Действуя по такому же принципу, можно найти описание и для систем CRAY X-MP и CRAY Y-MP. В самом деле, данные системы объединяют несколько процессоров, имеющих схожую с CRAY-1 структуру, и потому их описание имеет вид: T*(O*DPPiS+OPPiS).
Классификация Дункана
Р.Дункан излагает свой взгляд на проблему классификации архитектур параллельных вычислительных систем, причем сразу определяет тот набор требований, на который, с его точки зрения, может опираться искомая классификация:
Из класса параллельных машин должны быть исключены те, в которых параллелизм заложен лишь на самом низком уровне, включая:
· конвейеризацию на этапе подготовки и выполнения команды (instruction pipelining), т.е. частичное перекрытие таких этапов, как дешифрация команды, вычисление адресов операндов, выборка операндов, выполнение команды и сохранение результата;
· наличие в архитектуре нескольких функциональных устройств, работающих незалежно, в частности, возможность параллельного выполнения логических и арифметических операций;
· наличие отдельных процессоров ввода/вывода, работающих незалежно и параллельно с основными процессорами.
Причины исключения перечисленных выше особенностей автор объясняет следующим образом. Если рассматривать компьютеры, использующие только параллелизм низкого уровня, наравне со всеми остальными, то, во-первых, практически все существующие системы будут классифицированны как "параллельные" (что заведомо не будет позитивным фактором для классификации), и, во-вторых, такие машины будут плохо вписываться в любую модель или концепцию, отражающую параллелизм высокого уровня.
· Классификация должна быть согласованной с классификацией Флинна, показавшей правильность выбора идеи потоков команд и данных.
· Классификация должна описывать архитектуры, которые однозначно не укладываются в систематику Флинна, но, тем не менее, относятся к параллельным архитектурам (например, векторно-конвейерные).
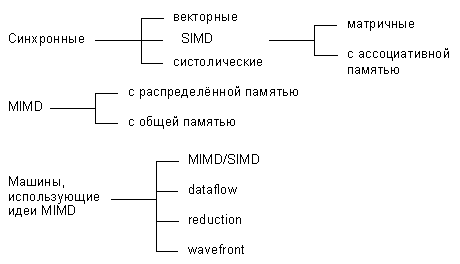
Учитывая вышеизложенные требования, Дункан дает неформальное определение параллельной архитектуры, причем именно неформальность дала ему возможность включить в данный класс компьютеры, которые ранее не вписывались в систематику Флинна. Итак, параллельная архитектура - это такой способ организации вычислительной системы, при котором допускается, чтобы множество процессоров (простых или сложных) могло бы работать одновременно, взаимодействуя по мере надобности друг с другом. Следуя этому определению, все разнообразие параллельных архитектур Дункан систематизирует так, как показано на рисунке:
По существу систематика очень простая: процессоры системы работают либо синхронно, либо незалежно друг от друга, либо в архитектуру системы заложена та или иная модификация идеи MIMD. На следующем уровне происходит детализация в рамках каждого из этих трех классов. Дадим небольшое пояснение лишь к тем из них, которые на сегодняшний день не столь широко известны.
Систолические архитектуры (их чаще называют систолическими массивами) представляют собой множество процессоров, объединенных регулярным образом (например, система WARP). Обращение к памяти может осуществляться только через определенные процессоры на границе массива. Выборка операндов из памяти и передача данных по массиву осуществляется в одном и том же темпе. Направление передачи данных между процессорами фиксировано. Каждый процессор за интервал времени выполняет небольшую инвариантную последовательность действий.
Гибридные MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы осуществляют параллельную обработку информации на основе асинхронного управления, как и MIMD системы. Но они выделены в отдельную группу, поскольку все имеют ряд специфических особенностей, которыми не обладают системы, традиционно относящиеся к MIMD.
MIMD/SIMD - типично гибридная архитектура. Она предполагает, что в MIMD системе можно выделить группу процессоров, представляющую собой подсистему, работающую в режиме SIMD (PASM, Non-Von). Такие системы отличаются относительной гибкостью, поскольку допускают реконфигурацию в соответствии с особенностями решаемой прикладной задачи.
Остальные три вида архитектур используют нетрадиционные модели вычислений. Dataflow используют модель, в которой команда может выполнятся сразу же, как только вычислены необходимые операнды. Таким образом, последовательность выполнения команд определяется зависимостью по данным, которая может быть выражена, например, в форме графа.
Модель вычислений, применяемая в reduction машинах иная и состоит в следующем: команда становится доступной для выполнения тогда и только тогда, когда результат ее работы требуется другой, доступной для выполнения, команде в качестве операнда.
Wavefront array архитектура объединяет в себе идею систолической обработки данных и модель вычислений, используемой в dataflow. В данной архитектуре процессоры объединяются в модули и фиксируются связи, по которым процессоры могут взаимодействовать друг с другом. Однако, в противоположность ритмичной работе систолических массивов, данная архитектура использует асинхронный механизм связи с подтверждением (handshaking), из-за чего "фронт волны" вычислений может менять свою форму по мере прохождения по всему множеству процессоров.
Классификация Кришнамарфи
Е.Кришнамарфи для классификации параллельных вычислительных систем предлагает использовать четыре характеристики [19], очень похожие на характеристики классификации А.Базу:
1. степень гранулярности;
2. способ реалізації паралелізму;
3. топология и природа связи процессоров;
4. способ управления процессорами.
Принцип построения классификации очень прост. Для каждой степени гранулярности будем рассматривать все возможные способы реалізації паралелізму. Для каждого полученного таким образом варианта рассмотрим все комбинации топологии связи и способов управления процессорами. В результате получим дерево (см. pисунок), в котором каждый ярус соответствует своей характеристике, каждый лист представляет отдельную группу компьютеров в данной классификации, а путь от вершины дерева однозначно определяет значения указанных выше характеристик. Разберем характеристики подробнее.

Первые два уровня практически один к одному повторяют А.Базу, поэтому останавливаться подробно на них мы не будем. Третий уровень классификации, топология и природа связи процессоров, тесно связан со вторым. Если был выбран аппаратный способ реалізації паралелізму, то надо рассмотреть топологию связи процессоров (матрица, линейный массив, тор, дерево, звезда и т.п.) и степень связности процессоров между собой (сильная, слабая или средняя), которая определяется относительной долей накладных расходов при организации взаимодействия процессоров. В случае комбинированной реалізації паралелізму, помимо топологии и степени связности, надо дополнительно учесть механизм взаимодействия процессоров: передача сообщений, разделяемые переменные или принцип dataflow (по готовности операндов).
Наконец, последний, четвертый уровень - способ управления процессорами, определяет общий принцип функционирования всей совокупности процессоров вычислительной системы: синхронный, dataflow или асинхронный.
На основе выделенных четырех характеристик нетрудно определить место наиболее известных классов архитектур в данной систематике.
Векторно-конвейерные компьютеры:
· гранулярность - на уровне данных;
· реализация паралелізму - аппаратная;
· связь процессоров - простая топология со средней связностью;
· способ управления - синхронный.
Классические мультипроцессоры:
· гранулярность - на уровне задач
· реализация паралелізму - комбинированная;
· связь процессоров - простая топология со слабой связностью и использованием разделяемых переменных;
· способ управления - асинхронный.
Матрицы процессоров:
· гранулярность - на уровне данных;
· реализация паралелізму - аппаратная;
· связь процессоров - двумерные массивы с сильной связностью;
· способ управления - синхронный.
Систолические массивы:
· гранулярность - на уровне данных;
· реализация паралелізму - аппаратная;
· связь процессоров - сложная топология с сильной связностью;
Несмотря на то, что классификация Е. Кришнамарфи построена лишь на четырех признаках, она позволяет выделить и описать такие "нетрадиционные" параллельные системы, как систолические массивы, машины типа dataflow и wavefront. Однако эта же простота является и основной причиной ее недостатков: некоторые архитектуры нельзя однозначно отнести

