




В работе обосновано применение метода группового учета аргумента, базирующегося на экспертных оценках, для решения многокритериальной задачи оптимизации управляющих воздействий конструкторской подготовки производства электронных аппаратов и прогнозирования вида модели управления, когда неизвестна ни сама зависимость, ни предполагаемый ее вид. Применение МГУА позволяет минимизировать погрешность прогноза и предусматривает механизмы самоорганизации, необходимые для построения системы поддержки принятия решений конструкторской подготовки производства электронных аппаратов. Ист. 2
Введение. Методы обработки и анализа статистических выборок и прогнозирования необходимы непосредственно для генерации управляющих воздействий, формирования последовательности и количества выполняемых управляющих воздействий. Также необходима оптимизация управляющих воздействий, направленная на выбор наиболее воздействующих, обеспечивающих оптимальную компоновку, параметры и свойства при минимальных затратах времени и материальных средств, то есть обеспечивающие наибольшую эффективность управления конструкторской подготовкой производства электронных аппаратов [1]. Важен не тот факт что дороже, а что дешевле, важна не сама стоимость, а важен факт - значение какого параметра стоимости или ее составляющих более приоритетно при производстве электронного аппарата конкретного назначения и условий эксплуатации. Приоритет какого параметра наиболее существенен при организации управления конструкторской подготовкой производства электронного аппарата. Именно оценки и сравнительная шкала позволят оценить эффективность управления конструкторской подготовкой производства электронных аппаратов.
Постановка задачи. Целью исследований является обоснование использования одного из методов обработки и анализа статистических выборок и прогнозирования для организации управления процессом производства электронных аппаратов.
Решение задачи. К методам обработки и анализа статистических выборок отнесены следующие: линейный анализ главных компонент, линейная регрессия, метод группового учета аргументов и др. Существующие методы прогнозирования с некоторой степенью условности разделены на: аналитические методы прогнозирования, основанные на использовании методов экстраполяции эмпирических функций, полученных в результате аппроксимации экспериментальных зависимостей параметров объектов; методы распознавания Байеса – относятся к статистическим методам прогнозирования и основаны на использовании условных априорных и апостериорных вероятностей; методы минимального риска, относящиеся к методам дифференциальной оценки, когда исследуемый объект находится в конечном наборе состояний; прогнозирование с использованием цепей Маркова связанное с определением вероятностей возможных состояний объекта с использованием дискретных или непрерывных цепей Маркова и др.
Методы экстраполяции в математическом смысле представляют собой распространение характера изменения функции из области её наблюдения в область, лежащую вне этого интервала. Задача экстраполяции формируется так: пусть в интервале (t0, t) известны значения функции f(x), требуется определить значения этой функции в точке t+1, лежащей вне этого интервала. Предположение об эволюционном характере развития прогнозируемых объектов ограничивает применение метода экстраполяции только теми периодами времени, в течение которых в развитии объектов не предлагается скачкообразных изменений. Оценка и экстраполяция тенденций получила широкое применение в нормативном прогнозировании. Несмотря на многообразие явлений, технологическое и экономическое прогнозирование с помощью метода экстраполяции можно проводить ограниченным числом функций, которые подразделяются на четыре класса:
Класс 1: линейный рост функции на большей части интервала с уменьшением темпов в его конце. Такие кривые характерны для роста производительности труда, когда исчерпаны ресурсы данной технологии и рост производительности труда начинает замедляться. Для дальнейшего его возрастания необходим переход на новую технологию.
Класс 2а: на всём интервале развития наблюдаются экспоненциальный рост. Уравнение кривой для функции этого класса имеет вид
y = Aeat, (1)
где А – значение процесса при t = 0; а – параметр процесса.
Необходимо отметить, что этот процесс является линейным для логарифма рассматриваемой функции lnA = lnA+at.
Класс 2б: S-образные кривые, характеризующие начальным экспоненциальным или почти экспоненциальным ростом. Примером функции класса 2б служит кривая логического роста (кривая Перла)
y = L/(l+a0e-alt), (2)
где L – предел развития объекта; a0, a1 – константы; t – время.
Класс 3: функция с дважды экспоненциальным ростом или даже ещё более крутым подъёмом с последующим переходом в более пологую кривую. Эти функции характеризуются ростом технических систем в условиях интенсивности исследований и разработок.
Класс 4: функция с медленным экспоненциальным ростом в начале развития, который сменяется внезапным, более быстрым ростом и, наконец, замедлением в конце развития.
Уравнения множественной регрессии являются одним из наиболее распространённых методов многофакторного прогнозирования. Для линейного случая модель множественной регрессии записывается в виде
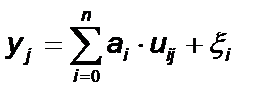 , при j = 1…m, (3)
, при j = 1…m, (3)
где ai – коэффициент модели, i = 0…n; uij – значения i-й функции независимой переменной; n – число независимых переменных в модели, ξi – случайная ошибка.
К недостаткам регрессионного анализа следует отнести необходимость субъективного определения исследователем структуры модели. Кроме того, регрессионный анализ позволяет строить модели только в области, где число коэффициентов модели меньше или равно числу точек опытных данных.
Метод группового учета аргументов свободен от недостатков, присущих моделям, которые получены методом классического анализа. В основу положен принцип самоорганизации, основанный на применении внешних критериев выбора. Критерий называется внешним, если его определение основано на новой информации, неиспользованной при синтезе модели. Суть принципа самоорганизации моделей оптимальной сложности состоит в том, что при постепенном усложнении математической модели отдельные её элементы проверяются в соответствии с внешними критериями, после этого часть модели допускается для дальнейшего усложнения. Метод группового учета аргумента направлен на уменьшение необходимой априорной информации, вводимой для исследуемого объекта. Алгоритм метода группового учета аргумента с последовательным выделением трендов позволяет создавать модели множественной регрессии, основу которых составляет сумма уравнений регрессии по одному аргументу. По этому алгоритму расчет ведется следующим образом: первоначально определяется первый тренд и рассчитывается соответствующее отклонение истинных значений функции от тренда. Затем полученные отклонения аппроксимируются вторым трендом и определяется второй остаток. Число выделяемых трендов зависит от размерности функции. Их может быть два, три, четыре и более. Полученные значения трендов складываются. Окончательное выражение множественной регрессии:
y = Σ a 0j+ a 1 f (x 1)+ a 2 f (x 2)+…+ a n f (x n), (4)
где a 0j – свободный член j-го тренда.
Обобщенный алгоритм метода группового учета аргумента обеспечивает получение оптимальных моделей при использовании в качестве опорной функции аддитивной и мультипликативной моделей трендов. Для сокращения числа входных аргументов в этом алгоритме используется алгоритм последовательного выделения трендов для выбора оптимальной опорной модели. Затем осуществляется перебор всех возможных комбинаций выделенных трендов либо в классе сумм, либо в классе произведений. Результат перебора – оптимальная комбинация, дающая наиболее регулярные решения. При проведении расчётов по алгоритму метода группового учета аргумента таблица исходных данных делится на две части: обучающая (A) и проверяющая (B). Деление исходных данных проводят в отношении:
NA = 0,7N и NB = 0,3N или NA = 0,5N и NB = 0,5N, (5)
где N – общее число данных.
В качестве критерия получения оптимальной модели метод группового учета аргумента использует минимум среднеквадратичной ошибки на проверочной последовательности данных: первая разность прогнозных и реальных значений Δ(1) или минимум среднеквадратичной ошибки приращений; вторая разность прогнозных и реальных значений Δ(2).
Первый критерий рассчитывается по формуле:
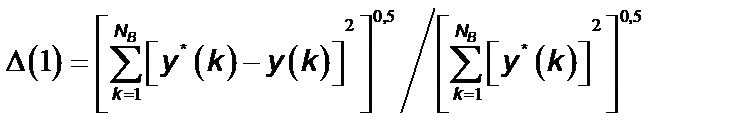 , (6)
, (6)
где y *(k) – данные прогноза; y (k) – реальные данные части В.
Второй критерий рассчитывается по формуле:
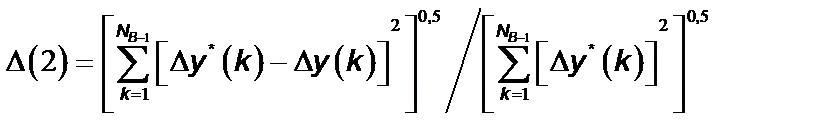 , (7)
, (7)
где Δ y *(k) – разности между данными прогноза; Δ y (k) – разности междуреальными данными.
Методы эвристических оценок основаны на выявлении мнений экспертов о перспективах развития объекта прогнозирования. Из подобных методов наиболее известен метод Дельфы, характерными особенностями которого является анонимный опрос экспертов, проводящийся в несколько туров; статистическая обработка результатов опроса каждого тура с последующим ознакомлением экспертов с её результатами. Перед каждым новым туром опроса эксперты имеют право изменять высказанное ими ранее мнение. Анонимность ответов необходима для того, чтобы исключать ряд нежелательных психологических факторов, которые наблюдаются в группах специалистов, проводящих очный обмен мнениями. К таким факторам относится склонность группы к компромиссу, принятие группой мнения "авторитетов", приспособление её к мнению большинства.
Процедура проведения экспертизы может быть различной. Однако в ней всегда можно выделить три этапа. На первом этапе эксперты привлекаются к работе по уточнению модели объекта прогнозирования. На втором – дают ответы на поставленные в анкете вопросы. При этом структурно-организованный набор вопросов должен быть логически связан с основной целью экспертизы, а формулировка вопросов должна исключать всякую смысловую неопределённость. На третьем этапе, после статистической обработки результатов опроса тура, эксперты привлекаются для консультации по недостающей информации, необходимой для формирования окончательного прогноза. При статистической обработке содержащихся в анкетных результатах экспертных оценок определяются статистические параметры прогнозируемых характеристик, их доверительные интервалы, статические оценки согласованности мнений экспертов. Проведение опроса в несколько туров и обязательное ознакомление экспертов с результатами каждого тура обеспечивает сходимость данных прогноза к медианному значению.
Морфологические методы прогнозирования позволяют не только получить технические характеристики прогнозируемого объекта, но и определить его структуру. Для этого исследуемый объект (проблема) разбивается на относительно независимые части (элементы). Затем для каждой из частей разрабатывается многовариантное решение, в основу которого берутся её конструктивные, технологические, функциональные или другие особенности. Общее решение о структуре и свойствах объекта или процесса получают, взяв одно решение от каждой части, руководствуясь при этом возможными ограничениями. Морфологический метод связан с системным подходом к изучаемому объекту, так как предусматривает использование всей совокупности знаний об объекте. Благодаря упорядоченному подходу к рассмотрению проблемы, он дает систематизированную информацию по всем возможным решениям изучаемой проблемы. Метод включает этапы исследования: точную формулировку подлежащей решению проблемы; тщательный анализ всех параметров, важных с точки зрения решения проблемы: построение морфологического ящика; выбор оптимального решения.
Каждый метод прогнозирования обладает своими достоинствами и недостатками, поэтому их объединение повышает достоверность прогнозов. Общий алгоритм комплексных методов прогнозирования предусматривает объединение формализованных и эвристических методов в одной системе. Эти методы могут находиться в следующих соотношениях: данные обоих прогнозов не противоречат друг другу, их можно совместно обрабатывать и получать комбинированный прогноз, данные этих прогнозов противоречивы, здесь требуется ввести обратные связи, раскрывающие причины расхождения данных прогнозов и произвести измерения условий прогнозирования. Выбор комплексных методов в значительной степени зависит от сроков, на которые делается прогноз и от объема имеющейся информации. В общем, комплексные методы наиболее приемлемы для долгосрочных прогнозов. Стоит заметить, что именно метод наименьших квадратов, как средство подстройки линейно зависимых параметров модели, является немаловажной составляющей метода группового учета аргумента.
Имеем случай многокритериальной задачи, опирающейся на статистические данные, результаты прогнозов и экспертные оценки. Выделяя в рассматриваемой проблеме управления конструкторской подготовкой производства электронных аппаратов конечное число управляющих воздействий [2], к примеру, тридцать один, ориентируя применение выбранных воздействий на решение задачи обеспечения эффективности управления, исключая неопределенность, связанную с видом функциональной зависимости, получаем, что для формирования экспериментально-статистической модели при построении регрессионных зависимостей методом полного факторного эксперимента следует выполнить 2.147х109 операций по определению промежуточных параметров модели, дробного факторного эксперимента - 2.684х108 операций (для трех вновь вводимых факторов), а методом группового учета аргумента - 1.438х104 (для наихудшего случая). То есть использование метода группового учета аргумента в 1.493х105 раз эффективнее в сравнении с дробным факторным экспериментом и в 1.866х104 раза эффективнее в сравнении с полным факторным экспериментом (для наихудшего случая сходимости метода группового учета аргумента).
Выводы. Для решения многокритериальной задачи оптимизации управляющих воздействий конструкторской подготовки производства электронных аппаратов и прогнозирования вида модели управления, когда неизвестна ни сама зависимость, ни предполагаемый ее вид, метод группового учета аргумента, базирующийся на экспертных оценках, позволяет минимизировать погрешность прогноза и предусматривает механизмы самоорганизации, необходимые для построения системы поддержки принятия решений конструкторской подготовки производства электронных аппаратов.
Список литературы:
1. Смолій В.М. Автоматизація процесів виробництва блоків електронних апаратів: Монографія. – Луганськ: Вид-во СНУ ім. В.Даля, 2006. – 124 с.: табл. 11, іл. 56, бібліогр. 88 найм.
2. Смолий В.Н. Автоматизированное управление процессом производства электронных аппаратов / В.Н. Смолий// Праці Луганського відділення Міжнародної Академії інформатизації. – Луганськ: СНУ ім.В.Даля, 2008. – №2(17). - C. 89-94.
УДК 681.322
Поркуян О.В., Самойлова Ж.Г.
ИСПОЛЬЗОВАНИЕ НЕЙРОННОЙ СЕТИ ДЛЯ УПРАВЛЕНИЯ АППАРАТАМИ ИТН ПРОИЗВОДСТВА АММИАЧНОЙ СЕЛИТРЫ.
В данной статье приведены результаты исследований построения искусственных нейронных сетей, используемых в автоматизированных системах управления аппаратами ИТН производства аммиачной селитры с помощью программного симулятора Matlab (Neural Network Toolbox). Приведены структурные схемы подобных систем. Рис.2, Табл.2, Ист. 17
Для управления сложными системами необходимо построить модель, которая адекватно отображает свойства объекта управления. Во многих случаях параметры такой модели определяются непосредственно в процессе эксплуатации объекта, то есть осуществляется идентификация по случайным входным и выходным сигналам. В наше время достаточно активно развивается способ построения автоматизированных систем управления на основе использования технологий искусственного интеллекта (нейронные сети, нечеткая логика, генетические алгоритмы) [1-7]. Обобщению могут подлежать такие факторы, которые плохо формализуются с использованием обычных математических методов (например, собственный опыт или интуиция специалистов и так далее). Известно немного попыток использования в химической промышленности технологий искусственного интеллекта. Их используют для интерпретации показаний сенсоров, отбора сенсоров для контроля химических процессов, прогноза температурного режима технологических процессов [8-17].
Моделирование и исследование работы искусственных нейронных сетей можно проводить с помощью программных симуляторов. Наиболее распространёнными пакетами для моделирования свойств нейросетей являются: Neural Works Pro Plus, Neuro Solution, Matlab (Neural Network Toolbox), Neuro Wisard, ANsim, Neural Ware и другие. Программы отличаются сложностью, количеством типов нейронов и алгоритмов обучения, которые поддерживаются в системе.
В данной работе для построения и исследования свойств сети использовалась среда программного симулятора Neural Network Toolbox MATLAB 7.1.0. Этот пакет рекомендован для моделирования нейросетей на основе персептронов с разным типом функции активации.
Для моделирования использовались статистические данные аппаратов ИТН Северодонецкого СГПП «Азот», используемых при производстве аммиачной селитры.
В качестве входных параметров использовались:
- Концентрация азотной кислоты на входе в цех (ωк).
- Температура азотной кислоты на входе в цех (Тк).
- Температура газообразного аммиака после подогревателя (ТА).
- Давление газообразного аммиака после подогревателя (ТА).
- Расход аммиака (FА)
В качестве выходных параметров использовались:
1. Температура реакции внутри ИТН (Т)
2. Концентрация селитры (ωС).
3. Давление сокового пара (Р).
В процессе обучения нейронной сети было задействовано 50% основной выборки (другая часть выборки использовалась для проверки).
В результате работы программного симулятора Neural Network Toolbox MATLAB 7.1.0. была построена и обучена нейронная сеть прямого распространения, структура которой приведена на рис.1.
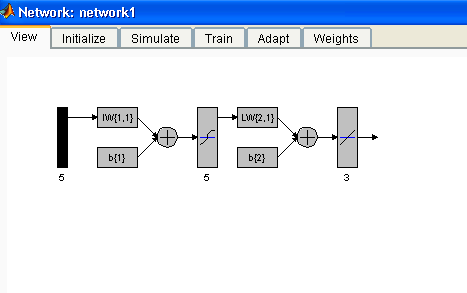
Рисунок 1. Структура сети.
Сеть была построена на основе персептронов (Feed-Forward Back Propagation) с пятью сигмоидными (TANSIG) нейронами скрытого слоя и тремя линейными (PURELIN) нейронами выходного слоя. Для построенной сети были определены функции, реализующие алгоритм обучения, функции тренировки и ошибки, обеспечивающие минимальную относительную погрешность. В таблице 1 приведены соответствующие параметры сети для трёх аппаратов ИТН.
Сравнивая соответствующие параметры сетей, можно видеть, что для первого и второго аппарата ИТН наименьшую относительную погрешность обеспечивает сеть, для которой использовали обучающую функцию метода Левенберга-Маркара (Levenberg-Marquardt), функцией тренировки являлась функция градиентного спуска с учетом моментов (LEARNGDM), функцией ошибки являлась средняя квадратичная ошибка (MSE). Для третьего аппарата ИТН наименьшую относительную погрешность обеспечивает сеть, которая обучалась с помощью метода градиентного спуска с учетом моментов, функцией тренировки являлась функция градиентного спуска с учетом моментов (LEARNGDM), функцией ошибки являлась средняя квадратичная ошибка (MSE).
Таблица 1.

