




Стандарт IEEE 754
Рекомендуемый для всех ВМ формат представления чисел с плавающей запятой определен стандартом IEEE 754. Этот стандарт был разработан с целью облегчить перенос программ с одного процессора на другие и нашел широкое применение практически во всех процессорах и арифметических сопроцессорах.

Рис. 2.24. Основные форматы IEEE 754: а — одинарный; б — двойной
Стандарт определяет 32-битовый (одинарный) и 64-битовый (двойной) форматы (рис. 2.24) с 8- и 11-разрядным порядком соответственно. Основанием системы счисления является 2. В дополнение, стандарт предусматривает два расширенных формата, одинарный и двойной, фактический вид которых зависит от конкретной реализации. Расширенные форматы предусматривают дополнительные биты для порядка (увеличенный диапазон) и мантиссы (повышенная точность). Таблица 2.6 содержит описание основных характеристик всех четырех форматов.
Не все кодовые комбинации в форматах IEEE интерпретируются обычным путем — некоторые комбинации используются для представления специальных значений. Предельные значения порядка, содержащие все нули (0) и все единицы (255 — в одинарном формате и 2047 — в двойном формате), определяют специальные значения.
Таблица 2.6. Параметры форматов стандарта IEEE 754
| Параметр | Формат | |||
| одинарный | одинарный расширенный | двойной | двойной расширенный | |
| Ширина слова, бит | ≥43 | ≥79 | ||
| Ширина порядка, бит | ≥11 | ≥15 | ||
| Смещение порядка | Не определено | Не определено | ||
| Максимальный порядок | ≥ 1023 | ≥ 16 383 | ||
| Минимальный порядок | -126 | ≤ -1022 | -1022 | ≤ -16 382 |
| Диапазон чисел | 10-38,10+38 | Не определен | 10-308, 10-308 | Не определен |
| Длина мантиссы, бит | ≥31 | ≥63 | ||
| Количество порядков | Не определено | Не определено | ||
| Количество мантисс | Не определено | Не определено | ||
| Количество значений | 1,98 х231 | Не определено | 1,99x263 | Не определено |
Представлены следующие классы чисел:
· Порядки в диапазоне от 1 до 254 для одинарного формата и от 1 до 2036 — для двойного формата, используются для представления ненулевых нормализованных чисел. Порядки смещены так, что их диапазон составляет от -126 до +127 для одинарного формата и от -1022 до +1023 — для двойного формата. Нормализованное число требует, чтобы слева от двоичной запятой был единичный бит. Этот бит подразумевается, благодаря чему обеспечивается эффективная ширина мантиссы, равная 24 битам для одинарного и 53 битам — для двойного форматов.
· Нулевой порядок совместно с нулевой мантиссой представляют положительный или отрицательный 0, в зависимости от состояния бита знака мантиссы.
· Порядок, содержащий единицы во всех разрядах, совокупно с нулевой мантиссой представляют положительную или отрицательную бесконечность, в зависимости от состояния бита знака, что позволяет пользователю самому решить, считать ли это ошибкой или продолжать вычисления со значением, равным бесконечности.
· Нулевой порядок в сочетании с ненулевой мантиссой представляют ненормализованное число. В этом случае бит слева от двоичной точки равен 0 и фактический порядок равен -126 или -1022. Число является положительным или отрицательным в зависимости от значения знакового бита.
· Кодовая комбинация, в которой порядок содержит все единицы, а мантисса не равна 0, используется как признак «не числа» (NAN — Not a Number) и служит для предупреждения о различных исключительных ситуациях.
Упакованные числа с плавающей запятой
В последних версиях АСК, предусматривающих особые команды для обработки мультимедийной информации, помимо упакованных целых чисел используются и упакованные числа с плавающей запятой. Так, в уже упоминавшейся технологии 3DNow! фирмы AMD имеются команды, служащие для увеличения производительности систем при обработке трехмерных приложений, описываемых числами с ПЗ. Каждая такая команда работает с двумя операндами с плавающей запятой одинарной точности. Операнды упаковываются в 64-разрядные группы, как это показано на рис. 2.25.

Рис. 2.25. Формат упакованных чисел с плавающей запятой в технологиях 3DNow!, SSE, SSE2
В микропроцессорах фирмы Intel, начиная с Pentium III, для аналогичных целей поддержаны команды, реализующие технологию SSE, также ориентированную на параллельную обработку упакованных чисел с ПЗ. Здесь числа объединяются в группы длиной 128 бит, и это позволяет упаковать в группу четыре 32-разрядных числа с ПЗ (числа с одинарной точностью). Позже, в технологии SSE2, которую можно считать дальнейшим развитием SSE, появился формат, где в группу из 128 бит упаковываются два 64-разрядных числа с ПЗ, то есть числа, представленные с двойной точностью.
Разрядность основных форматов числовых данных
Данные, представляющие в ВМ числовую информацию, могут иметь фиксированную или переменную длину. Операционные устройства вычислительных машин (целочисленные арифметико-логические устройства, блоки обработки чисел с плавающей запятой, устройства десятичной арифметики и т. п.), как правило, рассчитаны на обработку кодов фиксированной длины. Общепринятые величины разрядности кодов чисел показаны на рис. 2.26.

Рис. 2.26. Стандартная длина фиксированных форматов представления чисел
Наименьшей единицей данных в ВМ служит бит (BIT, Binary digiT — двоичная цифра). В большинстве случаев эта единица информации слишком мала. Однобитовые операционные устройства использовались в ВМ с последовательной обработкой информации, а в современных машинах с параллельной обработкой разрядов они практически не применяются. Побитовую работу с данными скорее можно встретить в многопроцессорных вычислительных системах, построенных из одноразрядных процессоров.
Следующая по величине единица состоит из четырех битов и называется полубайтом или тетрадой, или реже «ниблом» (nibble — огрызок). Она также редко имеет самостоятельное значение и заслуживает упоминания как единица представления отдельных десятичных цифр при их двоично-десятичной записи.
Реально наименьшей обрабатываемой единицей считается байт, состоящий из восьми битов. На практике эта единица информации также оказывается недостаточной, и значительно чаще применяются числа, представленные двумя (полуслово), четырьмя (слово), восемью (двойное слово) или шестнадцатью (счетверенное слово) байтами[5].
Разрядность целочисленного АЛУ обычно выбирается равной ширине адреса (для большинства современных ВМ это 32 разряда). Следовательно, наиболее выгодными в плане быстродействия являются такие целые числа, длина которых совпадает с разрядностью адреса. Использование более коротких чисел позволяет сэкономить на памяти, но выигрыша в производительности не дает.
Блоки операций с плавающей запятой обычно согласованы со стандартом IEEE 754 и рассчитаны на обработку чисел в формате двойной длины (64 бита). В большинстве ВМ реальная разрядность таких блоков даже больше (80 бит). Таким образом, наилучшим вариантом при проведении вычислений с плавающей запятой можно считать формат двойного слова. При выборе формата меньшей длины (32 разряда) вычисления все равно ведутся с большей точностью, после чего результат округляется. Таким образом, использование короткого формата чисел с плавающей запятой, как и в случае целых чисел с фиксированной запятой, помимо экономии памяти никаких иных преимуществ также не дает.
В работе [120] приводятся усредненные данные о частоте использования основных форматов чисел, полученные в ходе выполнения пакета тестовых программ SPEC92 на вычислительной машине DEC VAX (рис. 2.27).
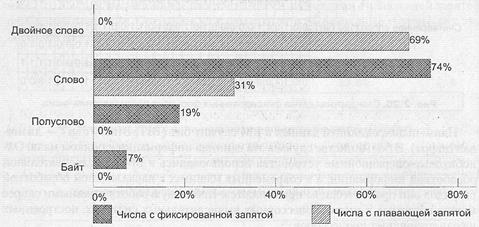
Рис. 2.27. Частота обращения к числовым данным в зависимости от их разрядности
В приложениях, оперирующих десятичными числами, где количество цифр в числе может варьироваться в широком диапазоне, что характерно для задач из области экономики, более удобными оказываются форматы переменной длины. В этом случае числа не переводятся в двоичную систему, а записываются в виде последовательности двоично-кодированных десятичных цифр. Длина подобной цепочки может быть произвольной, а для указания ее границы обычно используют символ-ограничитель, код которого не совпадает с кодами цифр. Длина цифровой последовательности может быть задана явно в виде количества цифр числа и храниться в первом байте записи числа, однако этот прием более характерен для указания длины строки символов.
Размещение числовых данных в памяти
В современных ВМ разрядность одной ячейки памяти, как правило, равна одному байту (8 бит). В то же время реальная длина кодов чисел составляет 2, 4, 8 или 16 байт. При хранении таких чисел в памяти последовательные байты числа размешают в нескольких ячейках с последовательными адресами, при этом для доступа к числу указывается только наименьший из адресов. При разработке архитектуры системы команд необходимо определить порядок размещения байтов в памяти, то есть какому из байтов (старшему или младшему) будет соответствовать этот наименьший адрес[6]. На рис. 2.28 показаны оба варианта размещения 32-разрядного числа в четырех последовательных ячейках памяти, начиная с адреса х.

Рис. 2.28. Размещение в памяти 32-разрядного числа: а — начиная со старшего байта;
б — начиная с младшего байта
В вычислительном плане оба способа записи равноценны. Так, фирмы DEC и Intel отдают предпочтения размещению в первой ячейке младшего байта, a IBM и Motorola ориентируются на противоположный вариант. Выбор обычно связан с некими иными соображениями разработчиков ВМ. В настоящее время в большинстве машин предусматривается использование обоих вариантов, причем выбор может быть произведен программным путем за счет соответствующей установки регистра конфигурации.

Рис. 2.29. Размещение чисел в памяти с выравниванием
Помимо порядка размещения байтов, существенным бывает и выбор адреса, с которого может начинаться запись числа. Связано это с физической реализацией полупроводниковых запоминающих устройств, где обычно предусматривается возможность считывания (записи) четырех байтов подряд. Причем данная операция выполняется быстрее, если адрес первого байта Л отвечает условию Л mod 5=0 (5= 2, 4, 8, 16). Числа, размещенные в памяти в соответствии с этим правилом, называются выравненными (рис. 2.29).
На рис. 2.30 показаны варианты размещения 32-разрядного слова без выравнивания. Их использование может приводить к снижению производительности.

Рис. 2.30. Размещение 32-разрядного слова без соблюдения правила выравнивания
Большинство компиляторов генерируют код, в котором предусмотрено выравнивание чисел в памяти.
Символьная информация
В общем объеме вычислительных действий все большая доля приходится на обработку символьной информации, содержащей буквы, цифры, знаки препинания, математические и другие символы. Каждому символу ставится в соответствие определенная двоичная комбинация. Совокупность возможных символов и назначенных им двоичных кодов образует таблицу кодировки. В настоящее время применяется множество различных таблиц кодировки. Объединяет их весовой принцип, при котором веса кодов цифр возрастают по мере увеличения цифры, а веса символов увеличиваются в алфавитном порядке. Так вес буквы «Б» на единицу больше веса буквы «А». Это способствует упрощению обработки в ВМ.
До недавнего времени наиболее распространенными были кодовые таблицы, в которых символы кодируются с помощью восьмиразрядных двоичных комбинаций (байтов), позволяющих представить 256 различных символов:
· расширенный двоично-кодированный код EBCDIC (Extended Binary Coded Decimal Interchange Code);
· американский стандартный код для обмена информацией ASCII (American Standard Code for Information Interchange).
Код EBCDIC используется в качестве внутреннего кода в универсальных ВМ фирмы IBM. Он же известен под названием ДКОИ (двоичный код для обработки информации).
Стандартный код ASCII—7-разрядный, восьмая позиция отводится для записи бита четности. Это обеспечивает представление 128 символов, включая все латинские буквы, цифры, знаки основных математических операций и знаки пунктуации. Позже появилась европейская модификация ASCII, называемая Latin 1 (стандарт ISO 8859-1). В ней «полезно» используются все 8 разрядов. Дополнительные комбинации (коды 128-255) в новом варианте отводятся для представления специфических букв алфавитов западно-европейских языков, символов псевдографики, некоторых букв греческого алфавита, а также ряда математических и финансовых символов. Именно эта кодовая таблица считается мировым стандартом де-факто, который применяется с различными модификациями во всех странах. В зависимости от использования кодов 128-255 различают несколько вариантов стандарта ISO 8859 (табл. 2.7).
Таблица 2.7. Варианты стандарта ISO 8859
| Стандарт | Характеристика |
| ISO 8859-1 | Западно-европейские языки |
| ISO 8859-2 | Языки стран центральной и восточной Европы |
| ISO 8859-3 | Языки стран южной Европы, мальтийский и эсперанто |
| ISO 8859-4 | Языки стран северной Европы |
| ISO 8859-5 | Языки славянских стран с символами кириллицы |
| ISO 8859-6 | Арабский язык |
| ISO 8859-7 | Современный греческий язык |
| ISO 8859-8 | Языки иврит и идиш |
| ISO 8859-9 | Турецкий язык |
| ISO 8859-10 | Языки стран северной Европы (лапландский, исландский) |
| ISO 8859-11 | Тайский язык |
| ISO 8859-13 | Языки балтийских стран |
| ISO 8859-14 | Кельтский язык |
| ISO 8859-15 | Комбинированная таблица для европейских языков |
| ISO 8859-16 | Содержит специфические символы ряда языков: албанского, хорватского, английского, финского, французского, немецкого, венгерского, ирландского, итальянского, польского, румынского и словенского |
В популярной в свое время операционной системе MS-DOS стандарт ISO 8859 реализован в форме кодовых страниц OEM (Original Equipment Manufacturer). Каждая OEM-страница имеет свой идентификатор (табл. 2.8).
Таблица 2.8. Наиболее распространенные кодовые страницы OEM
| Идентификатор | Страны кодовой страницы |
| СР437 | США, страны западной Европы и Латинской Америки |
| СР708 | Арабские страны |
| СР737 | Греция |
| СР775 | Латвия, Литва, Эстония |
| СР852 | Страны восточной Европы |
| СР853 | Турция |
| СР855 | Страны с кириллической письменностью |
| СР860 | Португалия |
| СР862 | Израиль |
| СР865 | Дания, Норвегия |
| СР866 | Россия |
| СР932 | Япония |
| СР936 | Китай |
Хотя код ASCII достаточно удобен, он все же слишком тесен и не вмещает множества необходимых символов. По этой причине в 1993 году консорциумом компаний Apple Computer, Microsoft, Hewlett-Packard, DEC и IBM был разработан 16-битовый стандарт ISO 10646, определяющий универсальный набор символов (UCS, Universal Character Set). Новый код, известный под названием Unicode, позволяет задать до 65 536 символов, то есть дает возможность одновременно представить символы всех основных «живых» и «мертвых» языков. Для букв русского языка выделены коды 1040-1093.
В «естественном» варианте кодировки Unicode, известном как UCS-2, каждый символ описывается двумя последовательными байтами т и п, так что номеру символа соответствует численное значение 256хт + п. Таким образом, кодовый номер представлен 16-разрядным двоичным числом. Наряду с UCS-2 в рамках Unicode существуют еще несколько вариантов кодировки Unicode (UTF, Unicode Transformation Formats), основные из которых UTF-8 и UTF-7.
В кодировке UTF-8 коды символов меньшие, чем 128, представляются одним байтом. Все остальные коды формируются по более сложным правилам. В зависимости от символа его код может занимать от двух до шести байтов, причем старший бит каждого байта всегда имеет единичное значение. Иными словами, значение байта лежит в диапазоне от 128 до 255. Ноль в старшем бите байта означает, что код занимает один байт и совпадает по кодировке с ASCII. Схема формирования кодов UTF-8 показана в табл. 2.9.
Таблица 2.9. Структура кодов UTF-8
| Число байтов | Двоичное представление | Число свободных битов |
| 0ххххххх | ||
| 110ххххх 10хххххх | 11 (5 + 6) | |
| 1110хххх 10хххххх 10хххххх | 16(4 + 6× 2) | |
| 11110ххх 10хххххх 10хххххх 10хххххх | 21 (3 + 6× 3) | |
| 111110хх 10хххххх 10хххххх 10хххххх 10хххххх | 26(2 + 6× 4) | |
| 1111110х 10хххххх 10хххххх 10хххххх 10хххххх 10хххххх | 31 (1 +6× 5) |
В UTF-7 код символа также может занимать один или более байтов, однако в каждом из байтов значение не превышает 127 (старший бит байта содержит ноль). Многие символы кодируются одним байтом, и их кодировка совпадает с ASCII, однако некоторые коды зарезервированы для использования в качестве преамбулы, характеризующей последующие байты многобайтового кода.
Стандарт Unicode обратно совместим с кодировкой ASCII, однако если в ASCII для представления схожих по виду символов (минус, тире, знак переноса) применялся общий код, в Unicode каждый из этих символов имеет уникальную кодировку. Впервые Unicode был использован в операционной системе Windows NT. Распределение кодов в Unicode иллюстрирует табл. 2.10.
Таблица 2.10. Блоки символов в стандарте Unicode
| Коды | Символы |
| 0-8191 | Алфавиты — английский, европейские, фонетический, кириллица, армянский, иврит, арабский, эфиопский, бенгали, деванагари, гур, гуджарати, ория, телугу, тамильский, каннада, малайский, сингальский, грузинский, тибетский, тайский, лаосский, кхмерский, монгольский |
| 8192-12287 | Знаки пунктуации, математические операторы, технические символы, орнаменты и т." п. |
| 12288-16383 | Фонетические символы китайского, корейского и японского языков |
| 16384-59391 | Китайские, корейские, японские идеографы. Единый набор символов каллиграфии хань |
| 59392-65024 | Блок для частного использования |
| 65025-65536 | Блок обеспечения совместимости с программным обеспечением |
Параллельно с развитием Unicode исследовательская группа ISO проводит работы над 32-битовой кодовой таблицей, однако ввиду широкой распространенности кодировки Unicode дальнейшие перспективы новой разработки представляются неопределенными.
Логические данные
Элементом логических данных является логическая (булева) переменная, которая может принимать лишь два значения: «истина» или «ложь». Кодирование логического значения принято осуществлять битом информации: единицей кодируют истинное значение, нулем — ложное. Как правило, в ВМ оперируют наборами логических переменных длиной в машинное слово. Обрабатываются такие слова с помощью команд логических операций (И, ИЛИ, НЕ и т. д.), при этом все биты обрабатываются одинаково, но независимо друг от друга, то есть никаких переносов между разрядами не возникает.
Строки
Строки — это непрерывная последовательность битов, байтов, слов или двойных слов. Битовая строка может начинаться в любой позиции байта и содержать до 232 бит. Байтовая строка может состоять из байтов, слов или двойных слов. Длина такой строки варьируется от нуля до 232 - 1 байт (4 Гбайт). Приведенные цифры характерны для превалирующих в настоящее время 32-разрядных ВМ.
Если байты байтовой строки представляют собой коды символов, то говорят о текстовой строке. Поскольку длина текстовой строки может меняться в очень широких пределах, то для указания конца строки в последний байт заносится код-ограничитель — обычно это нули во всех разрядах байта. Иногда вместо ограничителя длину строки указывают числом, расположенным в первом байте (двух) строки.
Прочие виды информации
Представляемая в ВМ информация может быть статической или динамической [33]. Так, числовая, символьная и логическая информация является статической — ее значение не связано со временем. Напротив, аудиоинформация имеет динамический характер — существует только в режиме реального времени и не может быть остановлена для более подробного изучения. Если изменить масштаб времени, аудиоинформация искажается, что используется, например, для создания звуковых эффектов.
Видеоинформация
Видеоинформация бывает как статической, так и динамической. Статическая видеоинформация включает в себя текст, рисунки, графики, чертежи, таблицы и др. Рисунки делятся также на плоские — двумерные и объемные — трехмерные.
Динамическая видеоинформация — это видео-, мульт- и слайд-фильмы. В их основе лежит последовательное экспонирование на экране в реальном масштабе времени отдельных кадров в соответствии со сценарием. Динамическая информация используется либо для передачи движущихся изображений (анимация), либо для последовательной демонстрации отдельных кадров (слайд-фильмы).
Для демонстрации анимационных и слайд-фильмов опираются на различные принципы. Анимационные фильмы демонстрируются так, чтобы зрительный аппарат человека не мог зафиксировать отдельных кадров (для получения качественной анимации кадры должны сменяться порядка 70 раз/с). При демонстрации слайд-фильмов каждый кадр экспонируется на экране столько времени, сколько необходимо для восприятия его человеком (обычно от 30 с до 1 мин). Слайд-фильмы можно отнести к статической видеоинформации.
В вычислительной технике существует два способа представления графических изображений: матричный (растровый) и векторный. Матричные (bitmap) форматы хорошо подходят для изображений со сложными гаммами цветов, оттенков и форм, таких как фотографии, рисунки, отсканированные данные. Векторные форматы более приспособлены для чертежей и изображений с простыми формами, тенями и окраской.
В матричных форматах изображение представляется прямоугольной матрицей точек — пикселов (picture element), положение которых в матрице соответствует координатам точек на экране. Помимо координат каждый пиксел характеризуется своим цветом, цветом фона или градацией яркости. Количество битов, выделяемых для указания цвета пиксела, изменяется в зависимости от формата. В высококачественных изображениях цвет пиксела описывают 24 битами, что дает около 16 млн цветов. Основной недостаток матричной (растровой) графики заключается в большой емкости памяти, требуемой для хранения изображения, из-за чего для описания изображений прибегают к различным методам сжатия данных. В настоящее время существует множество форматов графических файлов, различающихся алгоритмами сжатия и способами представления матричных изображений, а также сферой применения. Некоторые из распространенных форматов матричных графических файлов перечислены в табл. 2.11.
Таблица 2.11. Матричные графические форматы
| Обозначение | Полное название |
| BMP | Windows и OS\2 Bitmap |
| GIF | Graphics Interchange Format |
| PCX | PC Paintbrush File Format |
| JPEG | Joint Photographic Experts Group |
| TIFF | Tagged Image File Format |
| PNG | Portable Network Graphics. |
Векторное представление, в отличие от матричной графики, определяет описание изображения не пикселами, а кривыми — сплайнами. Сплайн — это гладкая кривая, которая проходит через две или более опорные точки, управляющие формой сплайна. В векторной графике наиболее распространены сплайны на основе кривых Безье. Суть сплайна: любую элементарную кривую можно построить, зная четыре коэффициента Р(), Р„ Р2 и Р3, соответствующие четырем точкам на плоскости. Перемещение этих точек влечет за собой изменение формы кривой (рис. 2.31).

Рис. 2.31. Варианты сплайнов
Хотя это может показаться более сложным, но для многих видов изображений использование математических описаний является более простым способом. В векторной графике для описания объектов используются математические формулы. Это позволяет при рисовании объектов вычислять, куда необходимо помещать реальные точки изображения. Имеется ряд простейших объектов, или примитивов, например эллипс, прямоугольник, линия. Эти примитивы и их комбинации служат основой для создания более сложных изображений. В простейшем случае изображение может быть составлено из отрезков линий, для которых задаются начальные координаты, угол наклона, длина, толщина линии, цвет линии и цвет фона.
Основное достоинство векторной графики — описание объекта, является простым и занимает мало памяти. Кроме того, векторная графика в сравнении с матричной имеет следующие преимущества:
· простота масштабирования изображения без ухудшения его качества;
· независимость емкости памяти, требуемой для хранения изображения, от выбранной цветовой модели.
Недостатком векторных изображений является их некоторая искусственность, заключающаяся в том, что любое изображение необходимо разбить на конечное множество составляющих его примитивов. Как и для матричной графики, существует несколько форматов графических векторных файлов. Некоторые из них приведены в табл. 2.12.
Таблица 2.12. Векторные графические форматы
| Обозначение | Полное название |
| dxf | drawing interchange format |
| cdr | corel drawing |
| hpgl | hewlett-packard graphics language |
| ps | postscript |
| svg | scalable vector graphics |
| vsd | microsoft visio format |
Матричная и векторная графика существуют не обособленно друг от друга. Так, векторные рисунки могут включать в себя и матричные изображения. Кроме того, векторные и матричные изображения могут быть преобразованы друг в друга. Графические форматы, позволяющие сочетать матричное и векторное описание изображения, называются метафайлами. Метафайлы обеспечивают достаточную компактность файлов с сохранением высокого качества изображения.
Таблица 2.13. Форматы метафайлов
| Обозначение | Полное название |
| eps | encapsulated postscript |
| wmf | windows metafile |
| cgm | computer graphics metafile |

