




Лекция 4. Данные и знания
Всегда вызывает интерес соотношение между данными и знаниями, в особенности представления (способы формализации) тех и других, модели представления данных и знаний, поскольку данные и знания — это форма представления информации в ЭВМ (рис. 1.17).
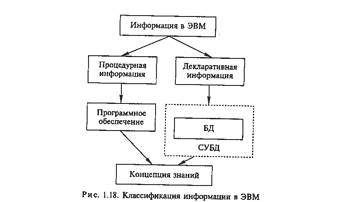
Информация, с которой имеет дело ЭВМ, разделяется на процедурную и декларативную.
Процедурная информация овеществлена в программах, которые выполняются в процессе решения задач, декларативная — в данных, с которыми эти программы работают (рис. 1.18).

Стандартной формой представления информации в ЭВМ является машинное слово, состоящее из определенного для данного типа ЭВМ числа двоичных разрядов — битов. В ряде случаев машинные слова разбиваются на группы по восемь двоичных разрядов, которые называются байтами.
Одинаковое число разрядов в машинных словах для команд и данных позволяет рассматривать их в ЭВМ в качестве одинаковых информационных единиц (ИЕ) и выполнять операции над командами, как над данными. Содержимое памяти образует информационную базу (рис. 1.19).

Для удобства сравнения данных и знаний можно выделить основные формы (уровни) существования знаний и данных. Как представлено в табл. 1.2, у данных и знаний много общего. Однако знания имеют более сложную структуру, и переход от данных к знаниям является закономерным следствием развития и усложнения информационных структур, обрабатываемых на ЭВМ.
Данные
Параллельно с развитием структуры ЭВМ происходило развитие информационных структур для представления данных.
Появились способы описания данных в виде: векторов, матриц, списочных структур, иерархических структур, структур, создаваемых программистом (абстрактных типов данных).
В настоящее время в языках программирования высокого уровня используются абстрактные типы данных, структура которых создается программистом. Появление баз данных (БД) знаменовало собой еще один шаг по пути организации работы с декларативной информацией.
По мере развития исследований в области ИнС возникла концепция знаний, которая объединила в себе многие черты процедурной и декларативной информации.
Сегодня термины «база данных», «информационная интеллектуальная система», как и многие другие термины информатики, стали широко употребительными. Причина этого — всеобщее осознание (социальная потребность) необходимости интенсивного внедрения ЭВМ и других средств автоматизированной обработки информации в самые различные области деятельности современного общества. Начало последней четверти нынешнего столетия по праву можно назвать началом эры новой информационной технологии — технологии, поддерживаемой автоматизированными информационными ИнС.
Актуальность проблематики ИнС и лежащих в их основе БД определяется не только социальной потребностью, но и научно-технической возможностью решения классов задач, связанных с удовлетворением информационных нужд различных категорий пользователей (включая как человека, так и программно-управляемое устройство). Такая возможность возникла (примерно на рубеже 70-х годов) благодаря значительным достижениям в области технического и программного обеспечения вычислительных систем.
База данных как естественнонаучное понятие характеризуется двумя основными аспектами: информационным и манипуляцион-ным. Первый аспект отражает такую структуризацию данных, которая является наиболее подходящей для обеспечения информационных потребностей, возникающих в предметной области (ПО). С каждой ПО ассоциируется совокупность «информационных объектов», связей между ними (например, «поставщики», «номенклатура выпускаемых изделий», «потребители» — категории информационных объектов, а «поставки» — тип отношений, имеющих место между этими объектами), а также задач их обработки. Манипуляционный аспект БД касается смысла тех действий над структурами данных, с помощью которых осуществляются выборка из них различных компонентов, добавление новых, удаление и обновление устаревших компонентов структур данных, а также их преобразования.
Под системой управления базами данных (СУБД) понимается комплекс средств (языковых, программных и, возможно, аппаратных), поддерживающих определенный тип БД. Главное назначение СУБД, с точки зрения пользователей, состоит в обеспечении их инструментарием, позволяющим оперировать данными в абстрактных терминах (именах и/или характеристиках информационных объектов), не связанных со способами хранения данных в памяти ЭВМ. Следует заметить, что средств СУБД может, вообще говоря, не хватать для решения всех задач той или иной ПО. Поэтому на практике приходится адаптировать (дополнять, настраивать) средства СУБД для обеспечения требуемых возможностей. Системы, получаемые путем адаптации СУБД к данной ПО, относятся к ИнС.
Жизнеспособная ИнС, т. е. способная поддерживать модель БД с учетом динамики развития ПО, по необходимости должна в качестве своего ядра содержать СУБД. Выработанная на сегодняшний день методология проектирования ИнС (с точки зрения БД) включает четыре основные задачи:
1) системный анализ ПО, спецификацию информационных объектов и связей между ними (в результате вырабатывается так называемая концептуальная, или семантическая, модель ПО);
2) построение модели БД, обеспечивающей адекватное представление концептуальной модели ПО;
3) разработку СУБД, поддерживающей выбранную модель БД;
4) функциональное расширение (посредством некоторой системы программирования) СУБД с целью обеспечения возможностей решения требуемого класса задач, т.е. задач обработки данных, характерных для данной ПО.
Знания
Рассмотрим общую совокупность качественных свойств для знаний (специфических признаков знаний) и перечислим ряд особенностей, присущих этой форме представления информации в ЭВМ и позволяющих охарактеризовать сам термин «знания».
Прежде всего знания имеют более сложную структуру, чем данные (метаданные). При этом знания задаются как экстенсионально (т.е. через набор конкретных фактов, соответствующих данному понятию и касающихся предметной области), так и интенсионально (т.е. через свойства, соответствующие данному понятию, и схему снязсй между атрибутами).
С учетом сказанного перечислим свойства.

Внутренняя интерпретируемость знаний.
Каждая информационная единица (ИЕ) должна иметь уникальное имя, по которому ИС находит ее, а также отвечает на запросы, в которых это имя упомянуто. Когда данные, хранящиеся в памяти, были лишены имен, то отсутствовала возможность их идентификации системой. Данные могла идентифицировать лишь программа.
Если, например, в память ЭВМ нужно было записать сведения о студентах вуза, представленные в табл. 1.10, то без внутренней интерпретации в память ЭВМ была бы записана совокупность из четырех машинных слов, соответствующих строкам этой таблицы.
При этом информация о том, какими группами двоичных разрядов в этих машинных словах закодированы сведения о студентах, у системы отсутствует. Они известны лишь программисту.
При переходе к знаниям в память ЭВМ вводится информация о некоторой протоструктуре информационных единиц. В рассматриваемом примере она представляет собой специальное машинное слово, в котором указано, в каких разрядах хранятся сведения о фамилиях, годах рождения, специальностях и курсе. При этом должны быть заданы специальные словари, в которых перечислены имеющиеся в памяти системы фамилии, года рождения, название специальностей и курса. Все эти атрибуты могут играть роль имен для тех машинных слов, которые соответствуют строчкам таблицы. По ним можно осуществлять поиск нужной информации. Каждая строка таблицы будет экземпляром протоструктуры. В настоящее время СУБД обеспечивают реализацию внутренней интерпретируемости всех ИЕ, хранимых в базе данных.
Структурированность (рекурсивная структурированность) знаний.
Информационные единицы должны обладать гибкой структурой. Для них должен выполняться «принцип матрешки», т.е. рекурсивная вложимость одних ИЕ в другие. Каждая ИЕ может быть включена в состав любой другой, и из каждой ИЕ можно выделить некоторые составляющие ее ИЕ.
Другими словами, должна существовать возможность произвольного установления между отдельными ИЕ отношений типа «часть — целое», «род— вид» или «элемент — класс».

