




Содержание
1) Цели и задачи ……………………………………………………………... 3
2) Описание базы данных …………………………………………………... 4
3) Работа с базой данных …………………………………………………… 6
4) Нагрузочное тестирование базы данных ………………………………...11
5) Вывод ……………………………………………………………………....15
6) Литература ………………………………………………………………....16
Цели и задачи
Цель: создать базу данных эликсиров по игре Ведьмак 3, которая будет содержать в себе информацию о виде эликсиров, их свойствах, из чего они изготавливаются, местах где их можно найти и о чудовищах, против которых их можно применять. Создать оптимизированные запросы к данной базе данных и протестировать ее на нагрузку.
Задачи:
· Создать в MYSQL Workbench схему базы данных минимум с 5 сущностями. Описать эти сущности и их связи.
· Описать использование этой БД, расписать основные запросы, посмотреть на их время исполнения и сделать выводы
· Оптимизация БД
· Выполнить нагрузочное тестирование с помощью apache-jmeter. Использовать для него расширения для построения графиков.
Описание базы данных
В курсовой работе используется созданная база данных Witcher1, основными сущностями которой являются таблицы:
1) Ingredients
2) Elixirs
3) Locations
4) Monsters
5) ML
6) IL

Рис.1 Схематическое отображение базы данных Witcher1
В таблице Ingridients содержатся необходимые ингредиенты для создания эликсиров в игре, которые описаны в таблице Elixirs. Для создания эликсира используется несколько ингредиентов, но каждый из них уникален для своего эликсира. Именно по этой причине между этими таблицами была установлена связь 1: n (один ко многим), что и показано на схеме базы данных (Рис.1).
Так же в таблице Ingridients содержится информация о названиях ингредиентов (Discription) и о том, где можно найти данный ингредиент (WhereFind). Колонка idElixirs является связующей колонкой для таблиц Ingridients и Elixirs.
В таблице Elixirs содержится информация о том, как использовать конкретный эликсир и название данного эликсира. Данная таблица является ключевой для остальных таблиц.
В таблице Locations содержится информация о том, в каком именно месте или около какого города можно найти конкретный ингредиент.
Таблица IL содержит объединённую информацию о том, где и как найти конкретный ингредиент в данной местности и что он из себя представляет. Между таблицами Ingridients и Locations была установлена связь n: m (многие ко многим), так как несколько ингредиентом могут быть найдены в нескольких локациях, о чем и указано в дочерней таблице IL.
В таблице Monsters содержится информация о видах чудовищ в
«Witcher 3», о том, как распознать то или иное чудовище и характерные для них имена.
Таблица ML является дочерней таблицей к объединению связью n: m таблиц Location и Monsters и содержит в себе конкретную информацию о том, как победить именно данное чудище и какие эликсиры для этого могут быть использованы, включая специальные ведьмачьи знаки, а так же в какой местности и по каким признакам искать именно этот вид чудища.
Работа с базой данных
База данных Witcher1 содержит в себе информацию о том, какие эликсиры против каких чудовищ необходимо использовать, специальную тактику для особо опасных чудовищ, таких как: Моровая дева, Черт, Бес, Леший и т.д. Анализировать информацию из каждой таблицы по порядку займет очень много времени, поэтому создадим специальные запросы к базе данных, которые максимально будут полезны для пользователя.
· Запрос о том, как найти конкретное чудище.
Данный запрос будет содержать в себе ключевое слово JOIN, благодаря которому и будет осуществляться обращение к таблицам ML и Monsters базы данных Witcher1.
Данный запрос будет выглядеть следующим образом:
SELECT
monsters.MonstersName, monsters.MonstersDiscription,
ml.DiscriptionHowFind, ml.idLocations
FROM
ml JOIN monsters ON monsters.idMonsters=ml.idMonsters;
После выполнения запроса мы получим на выход достаточно объемную таблицу, которая является результатом объединения двух таблиц. Чтобы выводимая таблица не была столь огромной, можно задать по какому именно чудовищу выводить информацию. То есть, для, например, Хима, запрос будет выглядеть следующим образом:
SELECT
monsters.MonstersName, monsters.MonstersDiscription,
ml.DiscriptionHowFind, ml.idLocations
FROM
ml JOIN monsters ON monsters.idMonsters=ml.idMonsters
where monsters.MonstersName=’Hym’;
Какому чудовищу соответствует тот или иной ID можно узнать из запроса к таблицам Monsters или ML. Запросы будут выглядеть следующим образом:
SELECT SELECT
IdMonsters, MonstersName idMonsters, MonstersName
FROM ml; FROM monsters;
Для проверки соответствия можно сделать запрос к обеим таблицам ML и Monsters, предварительно объединив их по idMonsters.
SELECT
ml.idMonsters, monsters.MonstersName
FROM
ml JOIN monsters ON
ml.idMonsters=monsters.idMonsters
ORDER BY monsters.idMonsters;
· Запрос о том, какой эликсир подходит к данному чудовищу.
Для реализации данного запроса будет использован JOIN. Запрос будет обращен к двум таблицам Elixirs и Monsters и будет содержать в себе информацию о том, когда и какой эликсир выпить в борьбе с чудовищем:
SELECT
monsters.MonstersName,elixirs.ElixirName, elixirs.ElixirDiscription
FROM
elixirs JOIN monsters ON
elixirs.idElixirs=monsters.idElixirs;
· Запрос о том, какой ингредиент находится в той или иной местности.
Для реализации данного запроса будет использован JOIN. Запрос будет обращен к двум таблицам Ingridients и Locations и будет содержать в себе информацию о том, какой ингредиент в какой локации находится и информацию о его виде:
SELECT
ingridients.Discription, locations.Discription, ingridients.WhereFind
FROM
ingridients JOIN locations ON
ingridients.idIngridients=locations.idIngridients
ORDER BY ingridients.Discription;
· Запросы UPDATE
Данный запрос реализуем для чудовища в таблице Monsters по имени Хим (Hym). Допустим, мы хотим поменять ему имя на Him:
UPDATE
monsters
SET MonstersName='Him'
where idMonsters=1;
Но, так как в английском варианте верно Hym то вернем все обратно:
UPDATE
monsters
SET MonstersName='Hym'
 where idMonsters=1;
where idMonsters=1;
Рис.2. Реализация запросов UPDATE
· Запросы «агрегации». COUNT и COUNT(DISTINCT)
 Функция COUNT подсчитывает количество не пустых строк (внутри них не NULL) в данной таблице. COUNT имеет оптимизированную версию для вывода количества строк, если она используется для 1 таблицы. Например:
Функция COUNT подсчитывает количество не пустых строк (внутри них не NULL) в данной таблице. COUNT имеет оптимизированную версию для вывода количества строк, если она используется для 1 таблицы. Например:
Рис.3. Подсчет строк в таблицах Elixirs, Monsters и объединенной таблице Monsters JOIN elixirs.
Функция же COUNT(DISTINCT) используется для вывода количества не повторяющихся строк в таблицах и является более оптимизированной версией семейства функций COUNT:
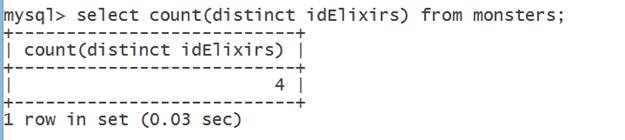
Рис.4. Подсчет неповторяющихся эликсиров в таблице Monsters.
· Функция DELETE.
Добавим в таблицу Elixirs еще одну строчку, используя INSERT:
INSERT INTO elixirs VALUES (6,’ForDelete’,’DiscriptionDelete’);

Рис.5. Добавление строки в таблицу Elixirs.
Теперь сделаем запрос на удаление этой строки, так как нет необходимости в эликсире, который никак не поможет в борьбе с чудищами:
 DELETE FROM elixirs WHERE idElixirs=6;
DELETE FROM elixirs WHERE idElixirs=6;
Рис.6. Удаление добавленной строки.
Нагрузочное тестирование базы данных
Теперь, когда выполнены запросы и обращение к базе данных налажено, её можно протестировать по нескольким параметрам:
· Response Times Over Time или Времена отклика в зависимости от времени – данная проверка отображает информацию для каждого запроса его среднее время отклика в миллисекундах.
· Response Times Distribution или Распределение времени отклика - данная проверка отображает количество ответов в определенный интервал времени, во время которого выполнялся запрос.
· Response Time Percentiles или Процентили времени отклика – данная проверка отображает процентили для значений времени отклика. На графике по оси X будут располагаться проценты, по оси Y- время отклика.
Для максимально правдоподобных тестов зададим определенные
параметры:

Рис.7. Параметры тестирования
Number of Threads(users) – Число виртуальных пользователей. В нашем случае поставим 1000, чтобы максимально нагрузить нашу базу данных.
Ramp-Up Period – период, в течение которого все пользователи будут задействованы.
Проверять будем все запросы JOIN на их быстродействие при одновременной их активации несколькими пользователями.

Рис.8. Запросы и построители графиков
Последние 3 пункта – это графопостроители тех проверок, по которым мы будем тестировать базу данных.
· 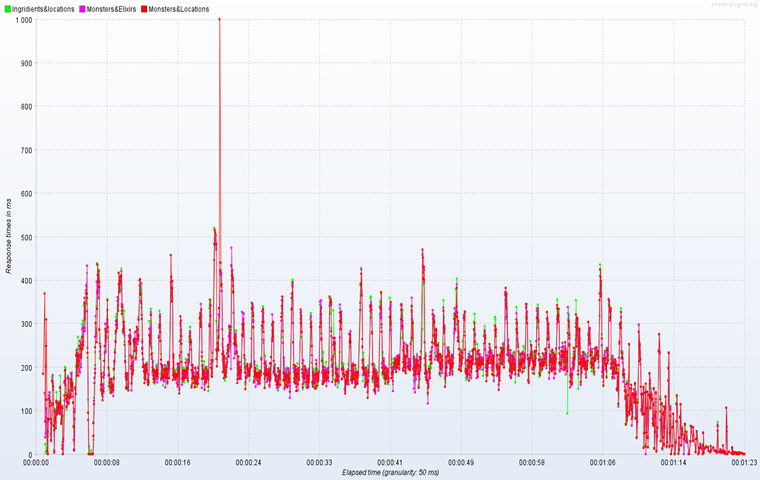 Проверка Response Times Over Time
Проверка Response Times Over Time
Рис.7. Результат выполнения запросов при тесте Response Times Over Time
Как видно из графика, самый трудновыполнимый запрос был «Monsters&Locations» и потребовал больше всего времени на его отклик. Убедиться в причине длительного выполнения запроса можно выполнив запрос в консоли. Основная причина такой задержки объясняется тем, что и в таблице Monsters, и в таблице ML содержатся объемные пояснения к чудовищам или к местам, где их найти. Из-за этого запрос выполняется достаточно длительное время.
·  Проверка Response Times Distribution
Проверка Response Times Distribution
Рис.8. Результат выполнения запросов при тесте Response Times Distribution.
По данному графику можно сделать вывод, что количество ответов для каждого из наших запросов в один и тот же период времени одинаково.
·  Проверка Response Time Percentiles
Проверка Response Time Percentiles
По оси ординат указано время выполнения, а по оси абсцисс размещены проценты от общего кол-ва. По графику можно заключить, что 90% запросов выполняются в интервал времени от 0 до 340 миллисекунд, причем с 5% до 15% количество запросов возрастает линейно, а далее по экспоненте с очень малым коэффициентом степени возрастания.
Оставшиеся 10% выполняются в интервал времени от 340 миллисекунд до 700 миллисекунд, благодаря чему можно сделать вывод, что осуществляется очень большая нагрузка на базу данных.
Вывод
В данной курсовой работы были выполнены все задачи. База данных была спроектирована, заполнена данными, показаны основные возможности ее использования в виде запросов и их результаты выполнения.
В конце, было выполнено тестирования и анализ его результатов, с последующими выводами.
Необходимо отметить, что сама БД была создана в качестве лишь учебной, поэтому она не столь объемна.
Еще одной важной характеристикой является безопасность: пароли, если будет создана такая таблица, нужно хранить в зашифрованном виде и оберегать от неправомерного доступа.
Литература
1. http://phpclub.ru/mysql/doc/ - интернет ресурс «MySQL - справочное руководство»
2. Шварц Б., Зайцев П., Ткаченко В. и др. - MySQL. Оптимизация производительности (2-е издание)
3. Талманн Л., Киндал М., Белл Ч. – «Обеспечение высокой доступности систем на основе MySQL»
4. Сапковский Анджей – «Ведьмак (большой сборник)», Количество страниц: 571
5. CD PROJECT RED, GOG COM. «Ведьмак 3: Дикая Охота».

