




Теорема не указывает конкретного способа кодирования, но из нее следует, что при выборе каждого символа кодовой комбинации необходимо стараться, чтобы он нес максимальную информацию.
Следовательно, каждый символ должен принимать значения 0 и 1 по возможности с равными вероятностями и каждый выбор должен быть независим от значений предыдущих символов.
Для случая отсутствия статистической взаимосвязи между знаками конструктивные методы построения эффективных кодов были даны впервые американскими учеными Шенноном и Фано. Их методики существенно не различаются и поэтому соответствующий код получил название кода Шеннона — Фано.
Код строят следующим образом: знаки алфавита сообщений выписывают в таблицу в порядке убывания вероятностей. Затем их разделяют на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем знакам верхней половины в качестве первого символа приписывают 0, а всем нижним — 1. Каждую из полученных групп, в свою очередь, разбивают на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одному знаку.
Пример 5.5. Проведем эффективное кодирование ансамбля из восьми знаков, характеристики которого представлены в табл. 5.4.
Таблица 5.4

Ясно, что при обычном (не учитывающем статистических характеристик) кодировании для представления каждого знака требуется три двоичных символа. Используя методику Шеннона — Фано, получаем совокупность кодовых комбинаций, приведенных в табл. 5.4.
Так как вероятности знаков представляют собой целочисленные отрицательные степени двойки, то избыточность при кодировании устраняется полностью. Среднее число символов на знак в этом случае точно равно энтропии. Убедимся в этом, вычислив энтропию:

и среднее число символов на знак
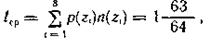
где n(zi) — число символов в кодовой комбинации, соответствующей знаку zi.
В более общем случае для алфавита из восьми знаков среднее число символов на знак будет меньше трех, но больше энтропии алфавита Η(Ζ).
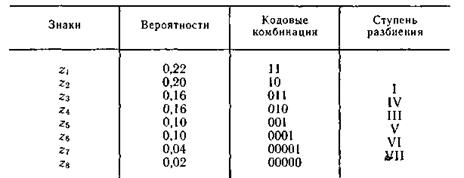
Пример 5.6. Определим среднюю длину кодовой комбинации при эффективном кодировании знаков ансамбля, приведенного в табл. 5.5.
Энтропия ансамбля равна 2,76. В результате сопоставления отдельным знакам ансамбля кодовых комбинаций по методике Шеннона — Фано (табл. 5.5) получаем среднее число символов на знак, равное 2,84.
Таблица 5.5

Следовательно, некоторая избыточность в последовательностях символов осталась. Из теоремы Шеннона следует, что эту избыточность также можно устранить, если перейти к кодированию достаточно большими блоками.
Пример 5.7. Рассмотрим процедуру эффективного кодирования сообщений, образованных с помощью алфавита, состоящего всего из двух знаков z1 и z2 с вероятностями появления соответственно р(z1) = 0,9 и ρ(z2) = 0,1.
Так как вероятности не равны, то последовательность из таких букв будет обладать избыточностью. Однако при побуквенном кодировании мы никакого эффекта не получим.
Действительно, на передачу каждой буквы требуется символ либо 1, либо 0, в то время как энтропия равна 0,47.
При кодировании блоков, содержащих по две буквы, получим коды, показанные в табл. 5.6.
Таблица 5.6
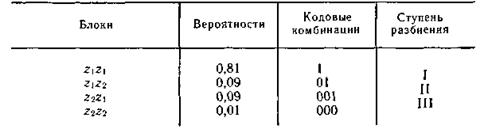
Так как знаки статистически не связаны, вероятности блоков определяются как произведение вероятностей составляющих знаков.
Среднее число символов на блок получается равным 1,29, а на букву — 0,645.
Кодирование блоков, содержащих по три знака, дает еще больший эффект. Соответствующий ансамбль и коды приведены в табл. 5.7.
Таблица 5.7

Среднее число символов на блок равно 1,59, а на знак — 0,53, что всего на 12 % больше энтропии. Теоретический минимум Η(Ζ) = 0,47 может быть достигнут при кодировании блоков, включающих бесконечное число знаков:

Следует подчеркнуть, что увеличение эффективности кодирования при укрупнении блоков не связано с учетом все более далеких статистических связей, так как нами рассматривались алфавиты с некоррелированными знаками. Повышение эффективности определяется лишь тем, что набор вероятностей, получающихся при укрупнении блоков, можно делить на более близкие по суммарным вероятностям подгруппы.
Рассмотренная методика Шеннона — Фано не всегда приводит к однозначному построению кода. Ведь при разбиении на подгруппы можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппы. Например, множество вероятностей, приведенных в табл. 5.5, можно было бы разбить так, как показано в табл. 5.8.
Таблица 5.8
От указанного недостатка свободна методика Хаффмена. Она гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву.
Для двоичного кода методика сводится к следующему. Буквы алфавита сообщений выписывают в основной столбец в порядке убывания вероятностей. Две последние буквы объединяют в одну вспомогательную букву, которой приписывают суммарную вероятность. Вероятности букв, не участвовавших в объединении, и полученная суммарная вероятность снова располагаются в порядке убывания вероятностей в дополнительном столбце, а две последние объединяются. Процесс продолжается до тех пор, пока не получим единственную вспомогательную букву с вероятностью, равной единице.
Пример 5.8. Используя методику Хаффмана, осуществим эффективное кодирование ансамбля знаков, приведенного в табл. 5.5.
Процесс кодирования поясняется табл. 5.9. Для составления кодовой комбинации, соответствующей данному знаку, необходимо проследить путь перехода знака по строкам и столбцам таблицы.
Таблица 5.9

 Для наглядности строим кодовое дерево. Из точки, соответствующей вероятности 1, направляем две ветви, причем ветви с большей вероятностью присваиваем символ 1, а с меньшей 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до вероятности каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в табл. 5.9, приведено на рис. 5.16.
Для наглядности строим кодовое дерево. Из точки, соответствующей вероятности 1, направляем две ветви, причем ветви с большей вероятностью присваиваем символ 1, а с меньшей 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до вероятности каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в табл. 5.9, приведено на рис. 5.16.
Теперь, двигаясь по кодовому дереву сверху вниз, можно записать для каждой буквы соответствующую ей кодовую комбинацию:

Требование префиксности эффективных кодов. Рассмотрев методики построения эффективных кодов, нетрудно убедиться в том, что эффект достигается благодаря присвоению более коротких кодовых комбинаций более вероятным знакам и более длинных менее вероятным знакам. Таким образом, эффект связан с различием в числе символов кодовых комбинаций. А это приводит к трудностям при декодировании. Конечно, для различения кодовых комбинаций можно ставить специальный разделительный символ, но при этом значительно снижается эффект, которого мы добивались, так как средняя длина кодовой комбинации по существу увеличивается на символ.
Более целесообразно обеспечить однозначное декодирование без введения дополнительных символов. Для этого эффективный код необходимо строить так, чтобы ни одна комбинация кода не совпадала с началом более длинной комбинации. Коды, удовлетворяющие этому условию, называют префиксными кодами. Последовательность 100000110110110100 комбинаций префиксного кода, например кода

декодируется однозначно:

Последовательность 000101010101 комбинаций непрефиксного кода, например кода

(комбинация 01 является началом комбинации 010), может быть декодирована по-разному:

или

Нетрудно убедиться, что коды, получаемые в результате применения методики Шеннона — Фано или Хаффмена, являются префиксными.
Методы эффективного кодирования коррелированной последовательности знаков. Декорреляция исходной последовательности может быть осуществлена путем укрупнения алфавита знаков. Подлежащие передаче сообщения разбиваются на двух-, трех- или n-знаковые сочетания, вероятности которых известны:

Каждому сочетанию ставится в соответствие кодовая комбинация по методике Шеннона — Фано или Хаффмена.
Недостаток такого метода заключается в том, что не учитываются корреляционные связи между знаками, входящими в состав следующих друг за другом сочетаний. Естественно, он проявляется тем меньше, чем больше знаков входит в каждое сочетание.
Указанный недостаток устраняется при кодировании по методу диаграмм, триграмм или l -грамм. Условимся называть l-граммой сочетание из l смежных знаков сообщения. Сочетание из двух смежных знаков называют диаграммой, из трех — триграммой и т. д.
Теперь в процессе кодирования l -грамма непрерывно перемещается по тексту cсообщения:

Кодовое обозначение каждого очередного знака зависит от l -1 предшествовавших ей знаков и определяется по вероятностям различных l -грамм на основании методики Шеннона - Фано или Хаффмена.
Конкретное значение l выбирают в зависимости от степени корреляционной связи между знаками или сложности технической реализации кодирующих и декодирующих устройств.
Недостатки системы эффективного кодирования. Причиной одного из недостатков является различие в длине кодовых комбинаций. Если моменты снятия информации с источника неуправляемы (например, при непрерывном съеме информации с запоминающего устройства на магнитной ленте), кодирующее устройство через равные промежутки времени выдает комбинации различной длины. Так как линия связи используется эффективно только в том случае, когда символы поступают в нее с постоянной скоростью, то на выходе кодирующего устройства должно быть предусмотрено буферное устройство («упругая» задержка). Оно запасает символы по мере поступления и выдает их в линию связи с постоянной скоростью. Аналогичное устройство необходимо и на приемной стороне.
Второй недостаток связан с возникновением задержки в передаче информации.
Наибольший эффект достигается при кодировании длинными блоками, а это приводит к необходимости накапливать знаки, прежде чем поставить им в соответствие определенную последовательность символов. При декодировании задержка возникает снова. Общее время задержки может быть велико, особенно при появлении блока, вероятность которого мала. Это следует учитывать при выборе длины кодируемого блока.
Еще один недостаток заключается в специфическом влиянии помех на достоверность приема. Одиночная ошибка может перевести передаваемую кодовую комбинацию в другую, не равную ей по длительности. Это повлечет за собой неправильное декодирование ряда последующих комбинаций, который называют треком ошибки.
Специальными методами построения эффективного кода трек ошибки стараются свести к минимуму [18].
Контрольные вопросы:
- Понятие эффективного кодирования
- Теорема Шеннона
- Методы эффективного кодирования некорреляционной последовательности знаков.
- Метод Хаффмена

