




Excel располагает достаточно мощными средствами статистической обработки данных. Большое количество статистических функций можно найти в списке встроенных функций Мастера в категории статистические и вручную выполнить статистический анализ, последовательно применяя к исходным данным соответствующие функции. Здесь вы найдете функции:
- для вычисления описательных статистик
- для построения регрессионной зависимости
- для проведения дисперсионного анализа и т.д.
Чтобы воспользоваться набором этих функций, нужно очень хорошо представлять себе цель исследования и этапы статистического анализа, т. е. нужно иметь хороший сценарий этой работы.
Другой путь – воспользоваться автоматизированным способом анализа данных. Все инструменты статистического анализа в Excel реализованы в надстройке Пакет анализа (см. инструкцию по установке).
Для освоения технологии работы с надстройкой Пакет анализа рассмотрим все этапы регрессионного анализа (именно это вам предстоит проделать в лабораторной работе).
Этап 1. Формирование набора исходных данных. Выполнять этот этап будем с помощью инструмента анализа “ Генерация случайных чисел ”. Он служит для формирования массива случайных чисел, распределенных по одному из теоретических распределений. В работе используются распределения (каждое со своими параметрами):
- Нормальное (H:m;s);
- Равномерное (P:a;b);
- Пуассона (П:l)
1).На рабочем листе Excel создаем шапку таблицы исходных данных для проведения статистического анализа (А, В, n, X, EPS, Y) и заполняем таблицу.
| Коэффициенты линейной зависимости (исх.д) | Число случайных чисел (исх.д) | Значения независимой переменной (генерация) | Случайная ошибка (генерация) | Y=AX+B+EPS (формула) | |
| A | B | n | X | EPS | Y |
Параметры A, B и n – это константы из индивидуального задания;
А, В – параметры линейной функции y=Ax+B (истинная зависимость).
n – объем выборки данных (число случайных чисел)
2). Значения переменной Х генерируем по указанному закону, для этого:
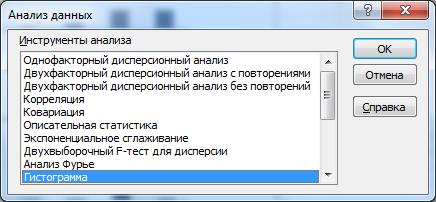
- На вкладке данные выполняем команду Анализ данных;
- в диалоговом окне Анализ данных среди инструментов анализа выбираем Генерация случайных чисел;

- в диалоговом окне Генерация случайных чисел заполняем параметры генерируемой последовательности данных из индивидуального задания. Пример для случайной величины Х (Н: среднее=0, ст. отклонение=1)
Параметры окна:
Число переменных – число переменных (в нашем случае число столбцов данных), с одинаковым распределением и с одинаковыми параметрами этого распределения. Если переменные имеют разное распределение или разные параметры, генерация проводится для каждой переменной отдельно, при этом в поле ввода указывается значение 1.
Число случайных чисел – объем выборки данных (n)
Распределение – в раскрывающемся списке выбирается тип распределения, в зависимости от теоретического распределения меняются и параметры диалогового окна (у разных распределений разные параметры).
Параметры (в зависимости от распределения)
нормальное, параметры – среднее и стандартное отклонение;
равномерное, параметры – начальное и конечное значение, между которыми находятся случайные числа;
Пуассона, параметр l - интенсивность потока заявок.
Случайное рассеивание (необязательный параметр) – вводится стартовое число для генерации определенной последовательности случайных чисел. Впоследствии это число можно снова использовать для получения той же самой последовательности чисел.
Параметры вывода – три положения переключателя:
Выходной интервал активизируется поле, в которое необходимо ввести ссылку на левую верхнюю ячейку выходного диапазона – D5. Размер выходного диапазона будет определен автоматически. И на экране появится сообщение в случае возможного наложения выходного диапазона на исходные данные.
Новый рабочий лист открывается новый лист, на котором начиная с ячейки А1 размещаются результаты. Если необходимо задать имя нового рабочего листа, введите его в соответствующее поле.
Новая рабочая книга открывается новая рабочая книга и на первом листе, начиная с ячейки А1 размещаются результаты. Если необходимо задать имя новой рабочей книги, введите его в соответствующее поле.
3).Значения случайной ошибки EPS генерируем по указанному закону (аналогично);
Число переменных - 1
Число случайных чисел – n(20)
Распределение - равномерное
Параметры
Начальное значение -1
Конечное значение -2
Параметры вывода
Выходной интервал – E5
4) Значения переменной Y вычисляем по формуле Y=A*X+B+ EPS: в ячейку F5: =$A$5*D5+$B$5+E5
| Коэффициенты линейной зависимости (исх.д) | Число случайных чисел (исх.д) | Значения независимой переменной (генерация) | Случайная ошибка (генерация) | Y=AX+B+EPS (формула) | ||||
| A | B | n | X | EPS | Y | |||
| -0,0158 | 0,926328318 |
| = | $A$5*D5+$B$5+E5 | ||||
| 1,346989 | 0,961485641 | 6,655463517 | ||||||
| 0,264723 | 0,91155736 | 4,441003784 | ||||||
| 1,504745 | 0,626636555 | 6,636127238 | ||||||
| -0,04994 | 0,08948027 | 2,989608657 | ||||||
| -0,13015 | 0,46375927 | 3,203466434 | ||||||
| 0,231352 | 0,790246284 | 4,25294944 | ||||||
| 1,35768 | 0,749626148 | 6,464986245 | ||||||
| 0,034546 | 0,69512009 | 3,764212129 | ||||||
| -1,53188 | 0,967345195 | 0,903594058 | ||||||
| 0,582547 | 0,585833308 | 4,750927853 | ||||||
| -0,66318 | 0,641193884 | 2,314841381 | ||||||
| -0,29248 | 0,593676565 | 3,008719131 | ||||||
| 0,127369 | 0,327372051 | 3,582110148 | ||||||
| 0,25934 | 0,012512589 | 3,53119287 | ||||||
| 0,297352 | 0,819299905 | 4,414004848 | ||||||
| -1,19054 | 0,749382 | 1,368293039 | ||||||
| -0,44321 | 0,597064119 | 2,710641024 | ||||||
| -1,91843 | 0,573351238 | -0,263515871 | ||||||
| -2,10584 | 0,287026582 | -0,924661483 |
 3,894732472
3,894732472
Этап 2. Предварительный статистический анализ данных
1) для каждого ряда данных (X, EPS, Y), используя Мастер функций, вычисляем статистики – математическое ожидание (среднее), стандартное отклонение, дисперсию, располагаем внизу таблицы как итоговые строки (функции из категории Статистические):
мат. ожидание – функция СРЗНАЧ
ст. отклонение - СТАНДОТКЛОН
дисперсия - ДИСП
2) для каждого ряда данных (X, EPS, Y) на рабочем листе выводим гистограммы распределений, для чего выполняем команду Анализ данных ®Гистограмма;
Этот инструмент строит таблицу распределения частот данных и на ее основе создает диаграмму. Перед использованием инструмента следует определить интервалы разбиения, иначе Excel автоматически определит интервалы разбиения, максимальное значение для каждого интервала называется карманом (аi<x£bi)
Входные данные
Входной интервал – D5-D24–ссылки на ячейки сданными, включая метку
Интервал карманов (необязательный параметр) – вводится ссылка на ячейки, содержащие набор граничных значений, определяющих интервалы (карманы), включая метку. Эти значения должны быть введены в возрастающем порядке. Вычисляется число попаданий данных в сформированные интервалы, причем границы интервалов являются строгими нижними границами и нестрогими верхними: a<x£b. Если диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Метки – ставим флажок, указывая, что метки были включены в ссылки для входного интервала и интервалов карманов
Параметры вывода
Выходной интервал – адрес левого верхнего угла области, где будет расположена таблица с выходными данными.
Новый рабочий лист
Новая рабочая книга
Парето (отсортированная гистограмма) – устанавливается, чтобы представить данные в порядке убывания частоты. Если флажок снят, то данные в выходном диапазоне будут приведены в порядке следования интервалов.
Интегральный процент устанавливается для расчета выраженных в процентах накопленных частот и включения в гистограмму графика куммуляты.
Вывод графика устанавливается для автоматического создания встроенной диаграммы на листе, содержащем выходной диапазон.
3). На отдельном листе вывести таблицу описательной статистики для переменных Х, Y и случайной ошибки, для чего выполняем Анализ данных ®Описательная статистика; в результате получим полную таблицу всех статистик исходных случайных величин;
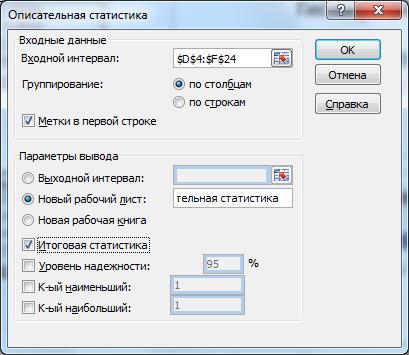
Инструмент Описательная статистика служит для создания статистического отчета по основным статистикам (положения, разброса, асимметрии) выборочной совокупности.
Входные данные
Входной интервал – D5-F24
Группирование – по столбцам (где расположены ряды данных)
Метки
Параметры вывода
Выходной интервал/Новый рабочий лист/Новая рабочая книга

