




В условиях перехода страны к рыночной экономике возрастает интерес и потребность в статистических методах анализа и прогнозирования, в количественных оценках социально-экономических явлений, получаемых с использованием многомерных статистических методов на ПЭВМ.
В данном разделе излагаются основные теоретические положения таких многомерных статистических методов, как корреляционный, регрессионный, компонентный и кластерный анализ, ряд задач эконометрики.
Значительное внимание уделяется логическому анализу исходной информации и экономической интерпретации получаемых результатов, а также рассмотрению подробно разработанных типовых примеров, взятых из экономической практики и решенных с использованием ЭВМ.
Примеры иллюстрируют необходимость комплексного применения многомерных статистических методов. При этом корреляционный анализ используется, с одной стороны, на этапе предварительного анализа для выявления мультиколлинеарности, а с другой — при оценке адекватности регрессионной модели; компонентный анализ используется в задачах снижения размерности, а также при построении уравнения регрессии на главных компонентах и в задачах классификации. При окончательном выборе модели рекомендуется использовать как экономические, так и статистические критерии. Наряду с точечными оценками рассматриваются методы построения интервальных оценок коэффициентов и уравнения регрессии.
В 53.5 «Основы эконометрики» рассматриваются производственные функции и системы одновременных эконометрических уравнений, двухшаговый метод наименьших квадратов.
Настоящий раздел предназначен для студентов, изучающих многомерные статистические методы, и специалистов, желающих повысить свою квалификацию в области применения современных эконометрических методов для анализа и прогнозирования социально-экономических явлений.
Глава 53. Методы многомерного статистического анализа и моделирования социально-экономических явлений
Корреляционный анализ
Корреляционный анализ является одним из методов статистического анализа взаимозависимости нескольких признаков.
Основная задача корреляционного анализа состоит в оценке корреляционной матрицы генеральной совокупности по выборке и определении на основе этой матрицы частных и множественных коэффициентов корреляции и детерминации.
Парный и частный коэффициенты корреляции характеризуют тесноту линейной зависимости между двумя переменными соответственно на фоне действия и при исключении влияния всех остальных показателей, входящих в модель. Они изменяются в пределах от -1 до +1, причем чем ближе коэффициент корреляции к 1, тем сильнее зависимость между переменными. Если коэффициент корреляции больше нуля, то связь положительная, а если меньше нуля — отрицательная.
Множественный коэффициент корреляции характеризует тесноту, линейной связи между одной переменной (результативной) и остальными, входящими в модель; он изменяется в пределах от 0 до 1.
Квадрат множественного коэффициента корреляции называется множественным коэффициентом детерминации. Он характеризует долю дисперсии одной переменной (результативной), обусловленной влиянием всех остальных переменных (аргументов), входящих в модель.
Исходной для анализа является матрица

размерности п х k, i-я строка которой характеризует i -е наблюдение (объект) по всем k показателям (j = 1, 2,..., k).
В корреляционном анализе матрицу Х рассматривают как выборку объема п из k -мерной генеральной совокупности, подчиняющейся k- мерному нормальному закону распределения.
По выборке определяют оценки параметров генеральной совокупности, а именно: вектор средних  , вектор средних квадратических отклонений s и корреляционную матрицу R порядка k:
, вектор средних квадратических отклонений s и корреляционную матрицу R порядка k:

где
 (53.1)
(53.1)
 (53.2)
(53.2)
xij — значение i -го наблюдения j -го фактора,
ril — выборочный парный коэффициент корреляции, характеризующий тесноту линейной связи между показателями xj и xl. При этом rjl является оценкой генерального парного коэффициента корреляции.
Матрица R является симметричной (rjl = rlj) и положительно определенной.
Кроме того, находятся точечные оценки частных и множественных коэффициентов корреляции любого порядка. Например, частный коэффициент корреляции (k - 2)-го порядка между переменными х1 и х2 равен
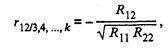 (53.3)
(53.3)
где Rjl — алгебраическое дополнение элемента rjl корреляционной матрицы R. При этом Rjl = (-l) j+l Mjl, где Mjl — минор, т.е. определитель матрицы, получаемой из матрицы R путем вычерчивания j- й строки и l -го столбца.
Множественный коэффициент корреляции (k - 1)-го порядка результативного признака x1 определяется по формуле
 (53.4)
(53.4)
где | R | — определитель матрицы R.
Значимость частных и парных коэффициентов корреляции, т.е. гипотеза H0: ρ = 0, проверяется по t -критерию Стьюдента. Наблюдаемое значение критерия находится по формуле
 (53.5)
(53.5)
где r — соответственно оценка частного или парного коэффициента корреляции ρ; l — порядок частного коэффициента корреляции, т.е. число фиксируемых факторов (для парного коэффициента корреляции l=0).
Напомним, что проверяемый коэффициент корреляции считается значимым, т.е. гипотеза H0: ρ = 0 отвергается с вероятностью ошибки α, если t набл по модулю будет больше, чем значение t кр, определяемое по таблицам t -распределения для заданного α и υ = n – l - 2.
Значимость коэффициентов корреляции можно также проверить с помощью таблиц Фишера — Иейтса.
При определении с надежностью у доверительного интервала для значимого парного или частного коэффициента корреляции р используют Z -преобразование Фишера и предварительно устанавливают интервальную оценку для Z:
 (53.6)
(53.6)
где tγ вычисляют по таблице значений интегральной функции Лапласа из условия

значение Z' определяют по таблице Z -преобразования по найденному значению r. Функция Z' — нечетная, т.е.

Обратный переход от Z к ρ осуществляют также по таблице Z -преобразования, после использования которой получают интервальную оценку для ρ с надежностью γ:

Таким образом, с вероятностью γ гарантируется, что генеральный коэффициент корреляции ρ будет находиться в интервале (r min, r max).
Значимость множественного коэффициента корреляции (или его квадрата — коэффициента детерминации) проверяется по F -критерию. Например, для множественного коэффициента корреляции проверка значимости сводится к проверке гипотезы, что генеральный множественный коэффициент корреляции равен нулю, т.е. H0: ρ1/2,…,k = 0, а наблюдаемое значение статистики находится по формуле
 (53.7)
(53.7)
Множественный коэффициент корреляции считается значимым, т.е. имеет место линейная статистическая зависимость между х1 и остальными факторами х2,..., хk, если F набл > F кр, где F кр определяется по таблице F -распределения для заданных α, υ1 = k - 1, υ2 = n - k.
Регрессионный анализ
Регрессионный анализ — это статистический метод исследования зависимости случайной величины у от переменных (аргументов) хj (j = 1, 2,..., k), рассматриваемых в регрессионном анализе как неслучайные величины независимо от истинного закона распределения xj.
Обычно предполагается, что случайная величина у имеет нормальный закон распределения с условным математическим ожиданием  = φ(x1,..., хk), являющимся функцией от аргументов хj и с постоянной, не зависящей от аргументов дисперсией σ2.
= φ(x1,..., хk), являющимся функцией от аргументов хj и с постоянной, не зависящей от аргументов дисперсией σ2.
Для проведения регрессионного анализа из (k + 1)-мерной генеральной совокупности (у, x1, х2,..., хj,..., хk) берется выборка объемом n, и каждое i -е наблюдение (объект) характеризуется значениями переменных (уi, xi1, хi2,..., хij,..., xik), где хij — значение j -й переменной для i -го наблюдения (i = 1, 2,..., n), уi — значение результативного признака для i -го наблюдения.
Наиболее часто используемая множественная линейная модель регрессионного анализа имеет вид
 (53.8)
(53.8)
где β j — параметры регрессионной модели;
ε j — случайные ошибки наблюдения, не зависимые друг от друга, имеют нулевую среднюю и дисперсию σ2.
Отметим, что модель (53.8) справедлива для всех i = 1,2,..., n, линейна относительно неизвестных параметров β0, β1,…, βj, …, βk и аргументов.
Как следует из (53.8), коэффициент регрессии Bj показывает, на какую величину в среднем изменится результативный признак у, если переменную хj увеличить на единицу измерения, т.е. является нормативным коэффициентом.
В матричной форме регрессионная модель имеет вид
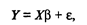 (53.9)
(53.9)
где Y — случайный вектор-столбец размерности п х 1 наблюдаемых значений результативного признака (у1, у2,.... уn); Х— матрица размерности п х (k + 1) наблюдаемых значений аргументов, элемент матрицы х,, рассматривается как неслучайная величина (i = 1, 2,..., n; j= 0,1 ,...,k; x0i, = 1); β — вектор-столбец размерности (k + 1) х 1 неизвестных, подлежащих оценке параметров модели (коэффициентов регрессии); ε — случайный вектор-столбец размерности п х 1 ошибок наблюдений (остатков). Компоненты вектора ε i не зависимы друг от друга, имеют нормальный закон распределения с нулевым математическим ожиданием (M ε i = 0) и неизвестной постоянной σ2 (D ε i = σ2).
На практике рекомендуется, чтобы значение п превышало k неменее чем в три раза.
В модели (53.9)

В первом столбце матрицы Х указываются единицы при наличии свободного члена в модели (53.8). Здесь предполагается, что существует переменная x0, которая во всех наблюдениях принимает значения, равные единице.
Основная задача регрессионного анализа заключается в нахождении по выборке объемом п оценки неизвестных коэффициентов регрессии β0, β1, …, βk модели (53.8) или вектора β в (53.9).
Так как в регрессионном анализе хj рассматриваются как неслучайные величины, a M ε i = 0, то согласно (53.8) уравнение регрессии имеет вид
 (53.10)
(53.10)
длявсех i = 1, 2,..., п, или в матричной форме:
 (53.11)
(53.11)
где  — вектор-столбец с элементами 1 ..., i,..., n.
— вектор-столбец с элементами 1 ..., i,..., n.
Для оценки вектора-столбца β наиболее часто используют метод наименьших квадратов, согласно которому в качестве оценки принимают вектор-столбец b, который минимизирует сумму квадратов отклонений наблюдаемых значений уi от модельных значений i, т.е. квадратичную форму:

где символом «Т» обозначена транспонированная матрица.
Наблюдаемые и модельные значения результативного признака у показаны на рис. 53.1.
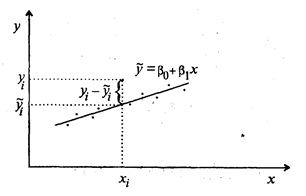
Рис. 53.1. Наблюдаемые и модельные значения результативного признака у
Дифференцируя, с учетом (53.11) и (53.10), квадратичную форму Q по β0, β1, …, βk и приравнивая частные производные к нулю, получим систему нормальных уравнений

решая которую получим вектор-столбец оценок b, где b = (b0, b1,..., bk) T. Согласно методу наименьших квадратов, вектор-столбец оценок коэффициентов регрессии получается по формуле
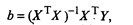 (53.12)
(53.12)

Х T — транспонированная матрица X;
(Х T Х)-1 — матрица, обратная матрице Х T Х.
Зная вектор-столбец b оценок коэффициентов регрессии, найдем оценку  уравнения регрессии
уравнения регрессии
 (53.13)
(53.13)
или в матричном виде:


Оценка ковариационной матрицы вектора коэффициентов регрессии b определяется выражением
 (53.14)
(53.14)
где
 (53.15)
(53.15)
Учитывая, что на главной диагонали ковариационной матрицы находятся дисперсии коэффициентов регрессии, имеем
 (53.16)
(53.16)
Значимость уравнения регрессии, т.е. гипотеза Н0: β = 0 (β0,= β1 = βk = 0), проверяется по F -критерию, наблюдаемое значение которого определяется по формуле
 (53.17)
(53.17)

По таблице F -распределения для заданных α, v 1 = k + l,v2 = n – k - l находят F кр.
Гипотеза H0 отклоняется с вероятностьюα, если F набл > F кр. Из этого следует, что уравнение является значимым, т.е. хотя бы один из коэффициентов регрессии отличен от нуля.
Для проверки значимости отдельных коэффициентов регрессии, т.е. гипотезы Н0: β j = 0, где j = 1, 2, ..., k, используют t -критерий и вычисляют t набл(bj) = bj /  bj. По таблице t -распределения для заданного α и v = п - k - 1 находят t кр.
bj. По таблице t -распределения для заданного α и v = п - k - 1 находят t кр.
Гипотеза H0 отвергается с вероятностью α, если t набл > t кр. Из этого следует, что соответствующий коэффициент регрессии β j значим, т.е. β j ≠ 0. В противном случае коэффициент регрессии незначим и соответствующая переменная в модель не включается. Тогда реализуется алгоритм пошагового регрессионного анализа, состоящий в том, что исключается одна из незначительных переменных, которой соответствует минимальное по абсолютной величине значение t набл. После этого вновь проводят регрессионный анализ с числом факторов, уменьшенным на единицу. Алгоритм заканчивается получением уравнения регрессии со значимыми коэффициентами.
Существуют и другие алгоритмы пошагового регрессионного анализа, например с последовательным включением факторов.
Наряду с точечными оценками bj генеральных коэффициентов регрессии β j регрессионный анализ позволяет получать и интервальные оценки последних с доверительной вероятностью γ.
Интервальная оценка с доверительной вероятностью γ для параметра β j имеет вид
 (53.19)
(53.19)
где tα находят по таблице t -распределения при вероятности α = 1 - γ и числе степеней свободы v = п - k - 1.
Интервальная оценка для уравнения регрессии в точке, определяемой вектором-столбцом начальных условий X0 = (1, x 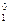 , x
, x  , ,..., x
, ,..., x  )T записывается в виде
)T записывается в виде
 (53.20)
(53.20)
Интервал предсказания n+1 с доверительной вероятностью у определяется как
 (53.21)
(53.21)
где tα определяется по таблице t -распределения при α = 1 - γ и числе степеней свободы v = п - k - 1.
По мере удаления вектора начальных условий х 0 от вектора средних  ширина доверительного интервала при заданном значении γ будет увеличиваться (рис. 53.2), где = (1,
ширина доверительного интервала при заданном значении γ будет увеличиваться (рис. 53.2), где = (1,  ).
).

Рис. 53.2. Точечная  и интервальная
и интервальная  оценки уравнения регрессии
оценки уравнения регрессии  .
.
Мультиколлинеарность
Одним из основных препятствий эффективного применения множественного регрессионного анализа является мультиколлинеарность. Она связана с линейной зависимостью между аргументами х1, х2,..., хk. В результате мультиколлинеарности матрица парных коэффициентов корреляции и матрица (X T X) становятся слабообусловленными, т.е.ихопределители близки к нулю.
Это приводит к неустойчивости оценок коэффициентов регрессии (53.12), завышению дисперсии s 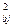 , оценок этих коэффициентов (53.14), так как в их выражения входит обратная матрица (X T X)-1, получение которой связано с делением на определитель матрицы (Х T Х). Отсюда следуют заниженные значения t (bj). Кроме того, мультиколлинеарность приводит к завышению значения множественного коэффициента корреляции.
, оценок этих коэффициентов (53.14), так как в их выражения входит обратная матрица (X T X)-1, получение которой связано с делением на определитель матрицы (Х T Х). Отсюда следуют заниженные значения t (bj). Кроме того, мультиколлинеарность приводит к завышению значения множественного коэффициента корреляции.
На практике о наличии мультиколлинеарности обычно судят по матрице парных коэффициентов корреляции. Если один из элементов матрицы R больше 0,8, т.е. | rjl | > 0,8, то считают, что имеет место мультиколлинеарность, и в уравнение регрессии следует включать один из показателей — хj или xl.
Чтобы избавиться от этого негативного явления, обычно используют алгоритм пошагового регрессионного анализа или строят уравнение регрессии на главных компонентах.
Пример. Построение регрессионного уравнения
Согласно данным двадцати (п = 20) сельскохозяйственных районов, требуется построить регрессионную модель урожайности на основе следующих показателей:
у — урожайность зерновых культур (ц/га);
x1 — число колесных тракторов (приведенной мощности) на 100 га;
х2 — число зерноуборочных комбайнов на 100 га;
х3 — число орудий поверхностной обработки почвы на 100га;
x4 — количество удобрений, расходуемых на гектар;
х5 — количество химических средств оздоровления растений, расходуемых на гектар.
Исходные данные для анализа приведены в табл. 53.1.
Таблица 53.1

