




Условие задачи: три различные группы из шести испытуемых получили списки из десяти слов. Первой группе слова предъявлялись с низкой скоростью - 1 слово в 5 секунд, второй группе со средней скоростью - 1 слово в 2 секунды, и третьей группе с большой скоростью - 1 слово в секунду. Было предсказано, что показатели воспроизведения будут зависеть от скорости предъявления слов. Результаты измерений представлены в таблице 26.
Таблица 26
Результаты запоминания слов, предъявляемых испытуемым
| № испытуемого | Группа 1 (низкая скорость) | Группа 2 (средняя скорость) | Группа 3 (высокая скорость) |
| суммы | |||
| средние | 7,17 | 6,17 | |
| Общая сумма |
Статистическая гипотеза:
- Основная (H0): различия в объеме воспроизведения слов между группами являются не более выраженными, чем случайные различия внутри каждой группы.
- Альтернативная (H1): Различия в объеме воспроизведения слов между группами являются более выраженными, чем случайные различия внутри каждой группы.
Решение: запустите программу Excel, откройте требуемый файл в папке своей учебной группы под именем «Статистика–Фамилии студентов». Создайте НОВЫЙ лист, переименуйте его, обозначив названием «Дисп_анализ». На этом листе введите данные и решение задачи, как показано ниже, сохраните изменения и покажите результат работы преподавателю.
Этапы выполнения дисперсионного анализа.
1. Подсчет SSФакт. - вариативности признака, обусловленную действием исследуемого фактора (межгрупповое разнообразие):
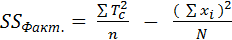 ,
,
где: Тс – сумма индивидуальных значений по каждому из условий. Для нашего примера 43, 37, 24 (см. таблицу);
с – количество условий (градаций) фактора (=3);
n – количество испытуемых в каждой группе (=6);
N – общее количество индивидуальных значений (=18);
 – квадрат общей суммы индивидуальных значений (=1042=10816).
– квадрат общей суммы индивидуальных значений (=1042=10816).
Отметим разницу между  , в которой все индивидуальные значения сначала возводятся в квадрат, а потом суммируются, и , где индивидуальные значения сначала суммируются для получения общей суммы, а потом уже эта сумма возводится в квадрат.
, в которой все индивидуальные значения сначала возводятся в квадрат, а потом суммируются, и , где индивидуальные значения сначала суммируются для получения общей суммы, а потом уже эта сумма возводится в квадрат.
По формуле (1) рассчитав фактическую вариативность признака, получаем:
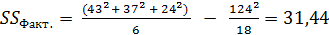 .
.
2. Вычисление SSОбщ. – общей вариативности признака:
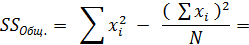
 .
.
3. Вычисление случайной (остаточной) величины дисперсии SSСл., обусловленной неучтенными факторами (внутригрупповое разнообразие):

4. Определение числа степеней свободы dfОбщ. , dfФакт. , dfСл. :
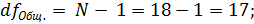


5. Математическое ожидание суммы квадратов или «средний квадрат»,усредненная величина соответствующих сумм квадратов SS равна:


6. Значение статистики критерия F Эмп. вычисляется по формуле:

Для нашего примера имеем: F Эмп .= 7,45
7. Определение F Крит. выполняется по статистическим таблицам для степеней свободы df1 = k1 =2 и df2 = k2 =15 и уровне значимости 0,05. Табличное значение статистики равно F Крит. = 3,68.
В программе Excel критическое значение критерия Фишера определяется функцией =FРАСПОБР(Уровень значимости; df1; df2) =FРАСПОБР(0,05;2;15) = 3,68232034.
8. Если F Эмп. < F Крит., то нулевая гипотеза принимается, в противном случае принимается альтернативная гипотеза. Для нашего примера F Эмп. > F Крит. (7,45>3,68), следовательно, принимается альтернативная гипотеза - влияние существует.
В программе Excel с помощью функции ФТЕСТ можно сразу вычислить вероятность различий двух массивов данных. Вводим в ячейку функцию =ФТЕСТ(Первый диапазон данных; Второй диапазон данных).
Получаем вероятность 0,99999999 > 0,95 (95%).
Аналогичные вычисления выполняются с помощью надстройки «Анализ данных» в модуле «Однофакторный дисперсионный анализ». Результат обработки данных задачи этой командой показан в таблице 27.
Таблица 27
| Однофакторный дисперсионный анализ | ||||||
| ИТОГИ | ||||||
| Группы | Счет | Сумма | Среднее | Дисперсия | ||
| Группа 1 (низкая скорость) | 7,16667 | 2,1666667 | ||||
| Группа 2 (средняя скорость) | 6,16667 | 2,1666667 | ||||
| Группа 3 (высокая скорость) | ||||||
| Дисперсионный анализ | ||||||
| Источник вариации | SS | df | MS | F | P-Значение | F критическое |
| Между группами | 31,444 | 15,7222 | 7,4473684 | 0,00567184 | 3,682320344 | |
| Внутри групп | 31,667 | 2,11111 | ||||
| Итого | 63,111 |
Вывод: различия в объеме воспроизведения слов между группами являются более выраженными, чем случайные различия внутри каждой группы (р<0,05). Таким образом, скорость предъявления слов влияет на объем их воспроизведения.
ЗАДАНИЯ
Запустите программу Excel, откройте файл в папке своей учебной группы под именем «Статистика–Фамилии студентов». На листе «Дисп_анализ», решите требуемый вариант заданий, сохраните изменения и покажите результат работы преподавателю.
Вариант 1
В эксперименте на животных измерено время пробежки мышей по лабиринту на фоне различной концентрации препарата, стимулирующего нервную систему; результаты измерений в секундах указаны в таблице 28.
Таблица 28
Результаты измерения времени пробежки мышей по лабиринту (сек.)
| № животного | Группа 1 (низкая концентрация) | Группа 2 (средняя концентрация) | Группа 3 (высокая концентрация) |
Необходимо подтвердить влияние стимулирующего вещества.
Вариант 2
На предприятии проведено изучение уровня травматизма с учетом фактора стажа работы сотрудников 5-и участков с близкими условиями труда; получены следующие данные (таблица 29).
Таблица 29
Уровень травматизма на 100 работающих
| Участок | Стаж работы | |||||||
| до 5 лет | 6-10 лет | 11-15 лет | 16 лет и более | |||||
Необходимо оценить влияние стажа работы на уровень травматизма.
Вариант 3
Проведено изучение уровня загрязнения водоема в 10 точках с учетом времени года; получены следующие данные (таблица 30).
Таблица 30
Уровень загрязнения водоема
| № точки отбора | Концентрации (мг/м3) по временам года | |||
| зима | весна | лето | осень | |
Требуется определить влияние времени года на уровень загрязнения водоема.
Вариант 4
Проведено обследование 8 пациентов, которые лечились у стоматолога с применением 3-х типов пломбировочного материала, с учетом времени выполнения работы врача; получены следующие данные (таблица 31).
Таблица 31
Время работы врача-стоматолога (мин)
| Пациент | Вид пломбировочного материала | ||
| 1-й тип материала | 2-й тип материала | 3-й тип материала | |
Необходимо подтвердить влияние типа используемого материала на время работы врача.
IX. Метод корреляции
При проведении исследования в биологии или медицине, как правило, регистрируются множество учетных признаков. Представляет интерес вопрос об их взаимном изменении, т.е. обнаружение зависимостей между ними. Выявление наличия таких взаимосвязей является одной из важнейших задач любой науки, в том числе и медицины.
Различают две формы количественных связей между явлениями или процессами: функциональную и корреляционную. Под ФУНКЦИОНАЛЬНОЙ понимают такую связь, при которой любому значению одного из признаков соответствует строго определенное значение другого. В точных науках, таких, как физика, химия и другие, может быть установлена функциональная взаимосвязь. Например, зависимость площади круга от длины окружности в геометрии, или в физике длина пути, пройденной телом в свободном падении, от времени. Наиболее известным видом функциональной зависимости является линейная, которая выражается математической формулой: y = ax+b.
В биологии и медицине установить функциональную зависимость, как правило, не удается. Объекты этих исследований имеют большую изменчивость и зависят от огромного числа факторов, измерить которые просто невозможно. В этом случае определяется наличие КОРРЕЛЯЦИОННОЙ связи, при которой значению каждой средней величины одного признака соответствует несколько значений другого взаимосвязанного с ним признака. Например: связь между ростом и массой тела человека. У группы людей с одинаковым ростом наблюдается различная масса тела, однако она варьирует в определенных пределах вокруг средней величины. Поэтому такую зависимость нужно оценивать с использованием понятия случайной величины с привлечением подходов теории вероятности. Такую форму зависимостей называют «Корреляционной».
При поиске зависимости между признаками может быть обнаружена взаимосвязь, различная по направлению и силе:
- Прямая (при увеличении одного признака увеличивается второй);
- Обратная (при увеличении одного признака второй уменьшается).
Степень взаимосвязи признаков по силе (тесноте) принято обозначать как:
- Отсутствие;
- Слабая;
- Средняя;
- Сильная;
- Полная.
Способами выявления корреляционной взаимосвязи между признаками являются:
- Визуальные (таблицы и графики).
- Статистические (корреляция и регрессия).
Следует подчеркнуть, что обнаружение корреляции между двумя признаками еще не говорит о существовании причинной связи между ними, а лишь указывает на возможность таковой или на наличие фактора, определяющего изменение обеих переменных совместно.
Приёмы визуализации данных позволяют обнаружить корреляционную зависимость лишь при небольшом числе наблюдений и только приблизительно. Для обнаружения корреляционной взаимосвязи с помощью таблицы в ней располагают ранжированные вариационные ряды и затем определяют совместное изменение признаков. График более наглядно демонстрирует такую зависимость и позволяет оценить ее форму: линейная, параболическая, тригонометрическая и др.
Наиболее точным способом обнаружения взаимосвязи между признаками является вычисление коэффициента корреляции. В зависимости от природы обрабатываемых данных применяются параметрические или непараметрические методы вычисления этого коэффициента.
При вычислении коэффициента корреляции исследователь получает возможность судить о силе связи (степени сопряженности) и ее направлении, а также с требуемой долей вероятности делать вывод о проявлении этой связи в генеральной совокупности. Чем больше коэффициент корреляции, тем с большей степенью уверенности можно говорить о наличии корреляционной зависимости между признаками. Если каждому заданному значению одного признака соответствуют близкие друг к другу, тесно расположенные около средней величины значения другого признака, то связь является более тесной. Когда эти значения сильно варьируют, связь менее тесная. Таким образом, мера корреляции указывает, насколько тесно связаны между собой параметры.
Коэффициент корреляции может принимать значения от -1 до +1. Направление обнаруженной взаимосвязи определяют по знаку коэффициента корреляции. При его положительном значении обнаруженная связь является прямой, при отрицательном – обратной. Сила связи оценивается по модулю этого коэффициента. Условно выделяют следующие уровни корреляционной связи: отсутствие – 0; слабая – от 0 до 0,3; средняя – от 0,3 до 0,7; сильная – 0,7 и более; полная – 1. Однако обсуждать наличие корреляции имеет смысл только в тех случаях, когда она статистически значима (p <0,05). Поэтому после вычисления коэффициента корреляции производится определение его ошибки репрезентативности и критерия достоверности.
Наиболее часто применяемыми в настоящее время методами обнаружения корреляции являются параметрический анализ по Пирсону и непараметрический анализ по Спирмену. Этими методами проверяется нулевая гипотеза (H0) об отсутствии связи между параметрами. Если такая гипотеза отклоняется при заданном уровне значимости (p), можно говорить о наличии взаимосвязи между параметрами.
Корреляционный анализ по Пирсону используется при решении задачи исследования линейной связи двух нормально распределенных параметров. Кроме проверки на нормальность распределения каждого параметра, до проведения корреляционного анализа рекомендуется строить график в координатах оцениваемых параметров, чтобы визуально определить характер зависимости.
Коэффициент корреляции Пирсона (rxy) или коэффициент линейной корреляции, был разработан в 90-х годах XIX века Карлом Пирсон, Фрэнсисом Эджуортом и Рафаэлем Уэлдоном в Англии. Он рассчитывается по формуле:

где: rxy – коэффициент линейной корреляции Пирсона;
covXY – ковариация признаков X и Y;
σX – среднее квадратическое отклонение признака X;
σY – среднее квадратическое отклонение признака Y;
 – средняя арифметическая признака X;
– средняя арифметическая признака X;
 – средняя арифметическая признака Y.
– средняя арифметическая признака Y.
В медицинской литературе встречается упрощенная запись этой формулы:
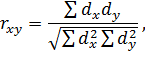
где: rxy – коэффициент линейной корреляции Пирсона;
dx – отклонение каждой варианты признака x от средней этого признака: dx = x - M x,
dy – отклонение каждой варианты признака y от средней этого признака: dy = y - M y.
В программе Excel значение коэффициент линейной корреляции Пирсона может быть вычислено функцией = КОРРЕЛ(Диапазон ячеек 1-го ряда; Диапазон ячеек 2-го ряда).
Для прогнозирования уровня корреляции в генеральной совокупности определяют ошибку репрезентативности этого коэффициента mr. Она вычисляется по формуле:
 ,
,
где: mr – ошибка репрезентативности коэффициента корреляции;
rxy – коэффициент линейной корреляции Пирсона;
n – число парных вариант.
Достоверность коэффициента линейной корреляции оценивается по коэффициенту Стьюдента (tr), который вычисляется с использованием его ошибки:
 ,
,
где: tr – коэффициент достоверности Стьюдента;
rxy – коэффициент линейной корреляции Пирсона;
mr – ошибка репрезентативности коэффициента корреляции.
Если число парных вариант n >30, то при tr >2 связь считается достоверной при уровне значимости p <0,05. Если число парных вариант n <30, то критическое значение tr-Крит. находят по таблице критических значений Стьюдента при степени свободы df = n - 2. В программе Excel это значение вычисляется функцией = СТЬЮДРАСПОБР(Уровень значимости p; Степени свободы df).
С целью уменьшения объема вычислений может применяться функция =КОРРЕЛ(Диапазон1; Диапазон2) или надстройка «Анализ данных» и ее модуль «Корреляционный анализ».
Отсутствие линейной корреляции еще не означает, что параметры полностью независимы. Связь между ними может быть нелинейной, или признаки, используемые в вычислениях, могут не подчиняться нормальному закону распределения. Поэтому, помимо вычисления коэффициента линейной корреляции, прибегают к использованию непараметрических коэффициентов корреляции. К ним относятся:
- Коэффициент ранговой корреляции Спирмена;
- Коэффициент ранговой корреляции Кендалла;
- Коэффициент корреляции знаков Фехнера;
- Коэффициент множественной ранговой корреляции (конкордации).
Корреляционный анализ по Спирмену применяется для обнаружения взаимосвязи двух параметров, если распределение хотя бы одного из них отлично от нормального.
Каждому показателю x и y присваивается ранг. На основе полученных рангов рассчитываются их разности d. Затем вычисляется коэффициент корреляции (ρ) по формуле:

где: r – коэффициент корреляции Спирмена;
d – разность рангов;
n – число парных вариант.
Ошибка репрезентативности коэффициента корреляции Спирмена определяется по формуле:
 ,
,
а коэффициент достоверности Стьюдента:
 ,
,
где: tr – коэффициент достоверности Стьюдента;
r – коэффициент корреляции Спирмена;
mr – ошибка репрезентативности коэффициента корреляции Спирмена.
Оценка коэффициента корреляции Спирмена и его достоверности выполняется так же, как и коэффициента линейной корреляции Пирсона.

