




Задача 1 каждого варианта составлена по теме “Парная регрессия и корреляция”. Введем следующие обозначения:
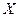 - факторный признак, независимая (объясняющая) переменная,
- факторный признак, независимая (объясняющая) переменная,
 - результативный признак, зависимая переменная,
- результативный признак, зависимая переменная,
x – фактические значения факторного признака,
y – фактические значения результативного признака,
 - расчетные (полученные по уравнению регрессии) значения результативного признака,
- расчетные (полученные по уравнению регрессии) значения результативного признака,
a, b - параметры уравнения регрессии.
В контрольных заданиях используется уравнение парной линейной регрессии вида:

Рассмотрим методику выполнения на условиях конкретной задачи:
American Express Company в течение долгого времени полагала, что владельцы ее кредитных карт предпочитают оплачивать свои расходы во время путешествий при помощи их карт. Для выяснения этого из компьютерной базы компании были случайно выбраны 25 владельцев карточек, которым были заданы вопросы о числе миль, которые они провели в путешествиях. Данные опроса о расходах путешественников и числе миль, проведенных ими в пути, составляют исходную информацию задачи.
| N п/п | Число миль, проведенных в пути, X | Расходы, у.е, Y | N п/п | Число миль, проведенных в пути, X | Расходы, у.е, Y |
| 1 | 1211 | 1802 | 14 | 3209 | 4492 |
| 2 | 1345 | 2405 | 15 | 3466 | 4244 |
| 3 | 1422 | 2005 | 16 | 3643 | 5298 |
| 4 | 1687 | 2511 | 17 | 3852 | 4801 |
| 5 | 1847 | 2332 | 18 | 4033 | 5147 |
| 6 | 2026 | 2305 | 19 | 4267 | 5738 |
| 7 | 2133 | 3016 | 20 | 4498 | 6420 |
| 8 | 2253 | 3385 | 21 | 4533 | 6059 |
| 9 | 2400 | 3090 | 22 | 4804 | 6426 |
| 10 | 2468 | 3694 | 23 | 5090 | 6321 |
| 11 | 2699 | 3371 | 24 | 5233 | 7025 |
| 12 | 2806 | 3998 | 25 | 5439 | 6964 |
| 13 | 3082 | 3555 |
Пункт 1. Построение поля корреляции результата и фактора производится по исходным данным о парах значений факторного и результативного признаков с соблюдением масштаба. На основе поля корреляции делаются выводы о направлении и возможной функциональной форме связи между факторным и результативным признаками (прямая - обратная, линейная - нелинейная).
 |
Для условий рассматриваемой задачи поле корреляции выглядит следующим образом:
Связь между факторным и результативным признаками прямая, линейная.
Пункт 2. Оценка параметров уравнения парной линейной регрессии производится обычным методом наименьших квадратов (МНК):  , где
, где
a и b –оценки параметров модели.
Величины, минимизирующие суммы квадратов отклонений  от для случая парной линейной регрессии, находятся как:
от для случая парной линейной регрессии, находятся как:
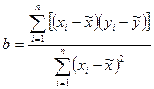 ;
;
 .
.
Значения ошибок, называемые обычно остатками, рассчитываются как  .
.
Проведите интерпретацию полученных результатов.
Расчет необходимых данных лучше всего организовать в таблице. Для нашего примера таблица будет выглядеть следующим образом:
Таблица 1
| N/N | х | у | 
| 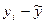
| 
| 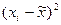
| 
| 
|
| -1966,84 | -2454,16 | 1787,652 | 14,34756 | |||||
| -1832,84 | -1851,16 | 1955,831 | 449,1692 | |||||
| -1755,84 | -2251,16 | 2052,471 | -47,4707 | |||||
| -1490,84 | -1745,16 | 2385,062 | 125,9377 | |||||
| -1330,84 | -1924,16 | 2585,872 | -253,872 | |||||
| -1151,84 | -1951,16 | 2810,529 | -505,529 | |||||
| -1044,84 | -1240,16 | 2944,82 | 71,17973 | |||||
| -924,84 | -871,16 | 805683,6 | 3095,428 | 289,5722 | ||||
| -777,84 | -1166,16 | 907085,9 | 605035,1 | 3279,922 | -189,922 | |||
| -709,84 | -562,16 | 399043,7 | 503872,8 | 3365,266 | 328,7337 | |||
| -478,84 | -885,16 | 229287,7 | 3655,186 | -284,186 | ||||
| -371,84 | -258,16 | 95994,21 | 3789,477 | 208,5225 | ||||
| -95,84 | -701,16 | 67199,17 | 9185,306 | 4135,875 | -580,875 | |||
| Продолжение таблицы 1 | ||||||||
| N/N | х | у |
|
|
|
|
|
|
| 31,16 | 235,84 | 7348,774 | 970,9456 | 4295,268 | 196,7322 | |||
| 288,16 | -12,16 | -3504,03 | 83036,19 | 4617,819 | -373,819 | |||
| 465,16 | 1041,84 | 484622,3 | 216373,8 | 4839,965 | 458,035 | |||
| 674,16 | 544,84 | 367309,3 | 454491,7 | 5102,273 | -301,273 | |||
| 855,16 | 890,84 | 761810,7 | 731298,6 | 5329,439 | -182,439 | |||
| 1089,16 | 1481,84 | 5623,124 | 114,8759 | |||||
| 1320,16 | 2163,84 | 5913,044 | 506,9564 | |||||
| 1355,16 | 1802,84 | 5956,971 | 102,0292 | |||||
| 1626,16 | 2169,84 | 6297,093 | 128,9072 | |||||
| 1912,16 | 2064,84 | 6656,041 | -335,041 | |||||
| 2055,16 | 2768,84 | 6835,515 | 189,4853 | |||||
| 2261,16 | 2707,84 | 7094,058 | -130,058 | |||||
| сумма | ||||||||
| Средн. | 3177,84 | 4256,16 |
В соответствии с расчетами, представленными в таблице 1, а= 267,7715; b=1,2551
Соответственно уравнение регрессии может быть записано как:

Коэффициент регрессии линейной функции (b) есть абсолютный показатель силы связи, характеризующий среднее абсолютное изменение результата при изменении факторного признака на единицу своего измерения.
Полученное уравнение может быть объяснено следующим образом: с увеличением расстояния на 1 милю расходы путешественника в среднем увеличиваются на 1,2551 условных денежных единиц. Свободный член уравнения равен 267,7715, что может трактоваться как влияние на величину расходов других, неучтенных в модели факторов.
Пункт 3. Линейный коэффициент корреляции характеризует тесноту линейной связи между изучаемыми признаками. Его можно определить по следующей формуле: 
 .
.
Значения линейного коэффициента корреляции принадлежит промежутку [-1;1].
Чем ближе его абсолютное значение к 1, тем теснее связь между признаками. Положительная величина свидетельствует о прямой связи между изучаемыми признаками, отрицательная - о наличии обратной связи между признаками.
Для нашей задачи r=0,98329, что подтверждает вывод, сделанный в пункте 1, что связь между признаками прямая, а также указывает на очень сильную взаимосвязь между количеством миль, проведенных в пути и расходами.
Квадрат коэффициента (индекса) корреляции называется коэффициентом детерминации и показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах. Например: 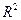 =0,8 означает, что доля колеблемости результативного признака, объясненная вариацией фактора
=0,8 означает, что доля колеблемости результативного признака, объясненная вариацией фактора  , включенного в уравнение регрессии, равна 80%. Остальные 20% приходятся на долю прочих факторов, не учтенных в уравнении регрессии.
, включенного в уравнение регрессии, равна 80%. Остальные 20% приходятся на долю прочих факторов, не учтенных в уравнении регрессии.
Для нашей задачи коэффициент детерминации равен 0,9669, то есть 96,69% вариации результативного признака (расходов путешественников) объясняется вариацией факторного признака (количеством миль, проведенных в пути)
Пункт 4 связан с темой “Проверка статистических гипотез”. Рекомендуется использовать следующую общую процедуру проверки гипотез:
1. Сформулируйте нулевую гипотезу о том, что коэффициент регрессии статистически незначим:  (линейной зависимости нет)
(линейной зависимости нет)
при конкурирующей:  (линейная зависимость есть)
(линейная зависимость есть)
или о том, что уравнение в целом статистически незначимо:  .
.
2. Определите фактическое значение соответствующего критерия.
3. Сравните полученное фактическое значение с табличным.
4. Если фактическое значение используемого критерия превышает табличное, нулевая гипотеза отклоняется, и с вероятностью (1-  ) принимается альтернативная гипотеза о статистической значимости коэффициента регрессии. Если фактическое значение t - критерия меньше табличного, оснований отклонять нулевую гипотезу - нет.
) принимается альтернативная гипотеза о статистической значимости коэффициента регрессии. Если фактическое значение t - критерия меньше табличного, оснований отклонять нулевую гипотезу - нет.
Статистическая значимость коэффициента регрессии  проверяется с помощью t - критерия Стьюдента:
проверяется с помощью t - критерия Стьюдента:
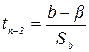 ,
,
где
 ,
,
 - стандартная ошибка оценки, рассчитываемая по формуле
- стандартная ошибка оценки, рассчитываемая по формуле
 .
.
Так как нулевая гипотеза предполагает, что =0, то tнабл. рассчитывается как:
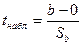 .
.
Для определения табличного значения воспользуйтесь таблицами распределения Стьюдента для заданного уровня значимости α, принимая во внимание, что число степеней свободы для распределения Стьюдента равно (k = n - 2).
Для нашего примера  , а
, а  = 2,07, следовательно нулевая гипотеза отвергается в пользу альтернативной и коэффициент регрессии статистически значим, то есть наличие существенной линейной зависимости между количеством миль, проведенных в путешествии и величиной расходов статистически подтверждается.
= 2,07, следовательно нулевая гипотеза отвергается в пользу альтернативной и коэффициент регрессии статистически значим, то есть наличие существенной линейной зависимости между количеством миль, проведенных в путешествии и величиной расходов статистически подтверждается.
Оценка статистической значимости построенной модели регрессии в целом производится с помощью F- критерия Фишера. Фактическое значение F-критерия качества оценивания регрессии, который представляет собой отношение объясненной суммы квадратов SSR (в расчете на одну независимую переменную) к остаточной сумме квадратов SSE (в расчете на одну степень свободы), определяется как:
 ,
,
где SSR = 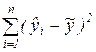 - факторная, или объясненная моделью регрессии, сумма квадратов,
- факторная, или объясненная моделью регрессии, сумма квадратов,
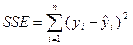 - остаточная, или необъясненная моделью сумма квадратов
- остаточная, или необъясненная моделью сумма квадратов
k - число независимых переменных.
F - критерий можно выразить через коэффициент детерминации:
 .
.
Для определения табличного значения воспользуйтесь таблицами распределения Фишера-Снедекора для заданного уровня значимости α, принимая во внимание, что в случае парной регрессии число степеней свободы большей дисперсии равно 1, а число степеней свободы меньшей дисперсии равно n - 2.
Для нашего примера  =671, 137, а
=671, 137, а  =4,45. Так как
=4,45. Так как 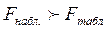 построенная модель регрессии в целом значима и может в дальнейшем использоваться нами для прогнозов.
построенная модель регрессии в целом значима и может в дальнейшем использоваться нами для прогнозов.
Для выполнения пункта 5 необходимо изучить вопрос об интервальном оценивании в регрессионном анализе, уяснить смысл понятий “точечный прогноз” и “интервальный прогноз”. Для расчета точечного прогноза  подставьте в уравнение регрессии заданное значение факторного признака
подставьте в уравнение регрессии заданное значение факторного признака  .
.
Так, например, если необходимо оценить расходы путешественника, преодолевшего (собирающегося преодолеть) 4500 миль, следует использовать уравнение регрессии записанное нами в пункте 2:
 , то есть в среднем путешественник, преодолевший 4500 миль израсходует 5915,7215 условных денежных единиц.
, то есть в среднем путешественник, преодолевший 4500 миль израсходует 5915,7215 условных денежных единиц.
Доверительный интервал для значений  , лежащих на линии регрессии, имеет вид:
, лежащих на линии регрессии, имеет вид:
 ,
,
где

- прогнозное значение зависимой переменной;
 - стандартная ошибка оценки;
- стандартная ошибка оценки;
n - объем выборки;
 - заданное значение
- заданное значение  .
.
Полученный интервал будет характеризовать значения результативного признака при заданном значении факторного признака  для отдельной наблюдаемой единицы.
для отдельной наблюдаемой единицы.
Так, для нашего примера этот доверительный интервал будет выглядеть как 5247,8367  6582,9665, то есть с вероятностью 0,95 можно утверждать, что расходы одного путешественника, преодолевшего 4500 миль составят от 5247,8367 до 6582,9665 условных денежных единиц.
6582,9665, то есть с вероятностью 0,95 можно утверждать, что расходы одного путешественника, преодолевшего 4500 миль составят от 5247,8367 до 6582,9665 условных денежных единиц.
Если же необходимо сделать вывод об интервале значений результативного признака для всех наблюдаемых единиц при среднем значении факторного признака , расчет будет производиться по формуле доверительного интервала генерального значения  :
:
 .
.
В соответствии с условиями рассматриваемого примера доверительный интервал, характеризующий расходы всех путешественников, преодолевших 4500 миль будет выглядеть как 5730,918 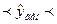 6099,885, то есть расходы всех путешественников, преодолевших расстояние в 4500 миль составят от 5730,918 до 6099,885 условных денежных единиц.
6099,885, то есть расходы всех путешественников, преодолевших расстояние в 4500 миль составят от 5730,918 до 6099,885 условных денежных единиц.
Сделайте выводы по задаче в целом.
Задача 2 составлена по теме “Множественная регрессия и корреляция” и предполагает построение и анализ двухфакторного уравнения линейной регрессии вида:
 .
.
Рассмотрим методику решения задачи такого типа на примере:
Компания, производящая моющие средства, предприняла рекламную акцию в магазинах с демонстрацией антисептических свойств нового моющего средства. В этот же период компания использовала обычную теле- и радиорекламу. Через 20 недель компания решила проанализировать сравнительную эффективность различных видов рекламных расходов. Аналитик компании, исходя из гипотезы о линейной регрессионной взаимосвязи, оценил параметры модели следующего вида:
 ,
,
где
 – объем продаж моющего средства,
– объем продаж моющего средства,
 – расходы на теле и радио рекламу,
– расходы на теле и радио рекламу,
 – расходы на демонстрацию товара в магазинах.
– расходы на демонстрацию товара в магазинах.
Расходы приведены в условных денежных единицах.
Таблица 1. Исходные данные
| Номера наблюдений |
|
|
|
| 1 | 72 | 12 | 5 |
| 2 | 76 | 11 | 7 |
| 3 | 78 | 15 | 6 |
| 4 | 70 | 10 | 5 |
| 5 | 68 | 11 | 3 |
| 6 | 80 | 16 | 7 |
| 7 | 82 | 14 | 3 |
| 8 | 65 | 8 | 4 |
| 9 | 62 | 8 | 3 |
| 10 | 90 | 18 | 5 |
Пункт 1 посвящен анализу показателей тесноты связи в уравнении множественной регрессии.
Но прежде чем приступить к анализу показателей тесноты связи необходимо рассмотреть дискриптивные (описательные статистики), которые подробно изучались в курсах математической статистики с элементами теории вероятностей и общей теории статистики
Таблица 2. Дискриптивные статистики
| y | x1 | x2 | |
| Размер выборки, n | 10 | 10 | 10 |
| Средняя арифметическая | 74,3 | 12,3 | 4,8 |
| Среднее квадратическое (стандартное) отклонение, S | 8,54 | 3,37 | 1,55 |
| Коэффициент вариации, V | 0,12 | 0,27 | 0,32 |
| Коэффициент асимметрии, As | 0,35 | 0,31 | 0,19 |
| Коэффициент эксцесса, Ex | -0,32 | -0,91 | -1,28 |
Сравнивая значения средних величин и стандартных отклонений, находим коэффициент вариации, значения которого свидетельствуют о том, что уровень варьирования признаков находится в допустимых пределах (< 0,35). Значения коэффициентов асимметрии и эксцесса указывают на отсутствие значимой скошенности и остро-(плоско-) вершинности фактического распределения признаков по сравнению с их нормальным распределением. [1] По результатам анализа дискриптивных статистик можно сделать вывод, что совокупность признаков – однородна и для её изучения можно использовать метод наименьших квадратов (МНК) и вероятностные методы оценки статистических гипотез.
Парный коэффициент корреляции - это линейный коэффициент корреляции, характеризующий степень тесноты линейной связи между результативным и факторным признаками. Методика его расчета и интерпретация была изложена в пункте 3 задачи 1. При выполнении задания необходимо выписать матрицу парных коэффициентов корреляции и сделать выводы о наличии (отсутствии) в построенной модели мультиколлинеарности факторов.
Значения линейных коэффициентов парной корреляции представлены в матрице парных коэффициентов (таблица 3). Они определяют тесноту парных зависимостей между анализируемыми переменными.
Таблица 3.Парные коэффициенты линейной корреляции Пирсона
|
|
|
| |
|
| 1,0000 (0,0) | 0,9393 (0,0001) | 0,4167 (0,2310) |
|
| 0,9393 (0,0001) | 1,0000 (0,0) | 0,4174 (0,2301) |
|
| 0,4167 (0,2310) | 0,4174 (0,2301) | 1,0000 (0,0) |
В скобках: P (
|
Коэффициент корреляции между и свидетельствует о значительной и статистически существенной линейной связи между объемом продаж моющего средства и расходами на радио и теле рекламу. Увеличение расходов на рекламу поднимает объем продаж. Связь между и не является статистически значимой. Кроме того, степень тесноты связи между и выше, чем между и . Таким образом, можно сделать предварительное заключение, что расходы на демонстрацию моющего средства в магазинах, существенно не влияют на рост объема продаж нового моющего средства.
Частные коэффициенты корреляции характеризуют тесноту связи между результативным и факторным признаками при фиксированном воздействии других факторов, включенных в уравнение регрессии. Их можно определить, используя парные коэффициенты корреляции по следующим рабочим формулам:
 ,
,
где
 - частный коэффициент корреляции между результативным и первым факторным признаками при фиксированном воздействии второго факторного признака,
- частный коэффициент корреляции между результативным и первым факторным признаками при фиксированном воздействии второго факторного признака,
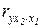 - частный коэффициент корреляции между результативным и вторым факторным признаками при фиксированном воздействии первого факторного признака,
- частный коэффициент корреляции между результативным и вторым факторным признаками при фиксированном воздействии первого факторного признака,
 ,
, 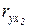 ,
,  - парные коэффициенты корреляции.
- парные коэффициенты корреляции.
Интерпретируйте полученные значения частных коэффициентов корреляции и поясните причины различий между значениями частных и парных коэффициентов корреляции.
Приведенные в таблице 4 линейные коэффициенты частной корреляции оценивают тесноту связи значений двух переменных, исключая влияние всех других переменных, представленных в уравнении множественной регрессии.
Таблица 4. Коэффициенты частной корреляции
|
|
|
| |
|
| 1,0000 (0,0) | 0,9265 (0,0003) | 0,0790 (0,8399) |
|
| 0,9265 (0,0003) | 1,0000 (0,0) | 0,0834 (0,8311) |
|
| 0,0790 (0,8399) | 0,0834 (0,8311) | 1,0000 (0,0) |
| В скобках: P (
|
Коэффициенты частной корреляции дают более точную характеристику тесноты зависимости двух признаков, чем коэффициенты парной корреляции, так как «очищают» парную зависимость от взаимодействия данной пары переменных с другими переменными, представленными в модели. Наиболее тесно связаны и , 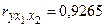 . Другие взаимосвязи существенно слабее. При сравнении коэффициентов парной и частной корреляции видно, что из-за влияния межфакторной зависимости между и происходит некоторое завышение оценки тесноты связи между переменными.
. Другие взаимосвязи существенно слабее. При сравнении коэффициентов парной и частной корреляции видно, что из-за влияния межфакторной зависимости между и происходит некоторое завышение оценки тесноты связи между переменными.
По этой причине рекомендуется при наличии сильной коллинеарности (взаимосвязи) факторов исключать из исследования тот фактор, у которого теснота парной зависимости меньше, чем теснота межфакторной связи.
Пункт 2. Расчет параметров линейного уравнения множественной регрессии осуществляется обычным МНК путем решения системы нормальных уравнений. Для уравнения с двумя объясняющими переменными система примет вид:

Поясните экономический смысл коэффициентов регрессии 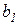 и
и  : это показатели, характеризующие абсолютное (в натуральных единицах измерения) изменение результативного признака при изменении факторного признака на единицу своего измерения при фиксированном влиянии второго фактора.
: это показатели, характеризующие абсолютное (в натуральных единицах измерения) изменение результативного признака при изменении факторного признака на единицу своего измерения при фиксированном влиянии второго фактора.
Результаты построения уравнения множественной регрессии представлены в таблице 5.
Таблица 5. Результаты построения модели множественной регрессии
| Независимые переменные | Коэффициенты | Стандартные ошибки коэффициентов | t - статистики | Вероятность случайного значения | ||
| Константа | 44,61 | 4,58 | 9,73 | 0,0001 | ||
| x1 | 2,35 | 0,36 | 6,51 | 0,0003 | ||
| x2 | 0,16 | 0,78 | 0,21 | 0,8399 | ||
| R2 = 0,88 | ||||||
| R2adj=0,85 | ||||||
| F = 26,402 | Prob > F = 0,0005 | |||||
Уравнение имеет вид:
y = 44,61 + 2,35x1 + 0,16x2
Значения стандартной ошибки параметров представлены в графе 3 таблицы 5:  Они показывают, какое значение данной характеристики сформировалось под влиянием случайных факторов. Их значения используются для расчета t-критерия Стьюдента (графа 4)
Они показывают, какое значение данной характеристики сформировалось под влиянием случайных факторов. Их значения используются для расчета t-критерия Стьюдента (графа 4)
 9,73;
9,73;  =6,51;
=6,51; 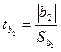 =0,21.
=0,21.
В нашем примере параметр является статистически значимым, а - нет. [2] На это же указывает значение вероятности случайных значений параметров регрессии (графа 5), если вероятность меньше принятого за стандарт уровня a = 0,05, то делается вывод о неслучайной природе данного значения параметра, то есть о том, что он статистически значим и надежен. В противном случае принимается нулевая гипотеза (H0) о случайной природе значения коэффициентов уравнения. В нашем примере для переменной х2 a > 0,05 (aх2=0,84), что свидетельствует о малой информативности (значимости) этой переменной.
Интерпретация коэффициентов регрессии следующая:
а - оценивает агрегированное влияние прочих (кроме учтенных в модели х1 и х2) факторов на результат y;
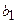 и
и  указывают, что с увеличением х1 и х2 на единицу их значений объем продаж нового моющего средства увеличивается, соответственно, на 2,35 и 0,16 условных денежных единиц.
указывают, что с увеличением х1 и х2 на единицу их значений объем продаж нового моющего средства увеличивается, соответственно, на 2,35 и 0,16 условных денежных единиц.
Пункт 3 связан с расчетом и анализом относительных показателей силы связи в уравнении множественной регрессии - частных коэффициентов эластичности. Частные коэффициенты эластичности рассчитывают, как правило, для средних значений факторного и результативного признака:
 ,
, 
где  - коэффициент условно-чистой регрессии при j-м факторе,
- коэффициент условно-чистой регрессии при j-м факторе,
 - среднее значение j-го факторного признака;
- среднее значение j-го факторного признака;
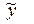 - среднее значение результативного признака,
- среднее значение результативного признака,
m - число факторных признаков в уравнении множественной регрессии.
Зачастую интерпретация результатов регрессии более наглядна, если произведен расчет частных коэффициентов эластичности. Частные коэффициенты эластичности 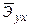 показывают, на сколько процентов от значения своей средней
показывают, на сколько процентов от значения своей средней  изменяется результат при изменении фактора xj на 1% от своей средней
изменяется результат при изменении фактора xj на 1% от своей средней 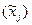 и при фиксированном воздействии на y прочих факторов, включенных в уравнение регрессии. Здесь
и при фиксированном воздействии на y прочих факторов, включенных в уравнение регрессии. Здесь
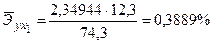
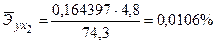
По значениям частных коэффициентов эластичности можно сделать вывод о более сильном влиянии на результат у (объем продаж моющего средства) рекламной компании по радио и телевидению, нежели демонстрации товара в магазинах.
Пункт 4 предполагает оценку совокупного влияния факторных переменных на результативный признак.
Оцените долю вариации результативного признака, объясненную совокупным влиянием факторных признаков, рассчитав совокупный (нескорректированный) множественный коэффициент детерминации:
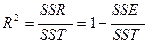 ,
,
где SSR = - факторная, или объясненная моделью регрессии, сумма квадратов,
SST =  - общая сумма квадратов,
- общая сумма квадратов,
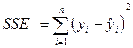 - остаточная, или не объясненная моделью регрессии сумма квадратов.
- остаточная, или не объясненная моделью регрессии сумма квадратов.
В нашем примере эта доля составляет 88,29% и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов. Иными словами, на весьма тесную связь факторов с результатом.
Скорректированный множественный коэффициент детерминации

(где n – число наблюдений, m – число объясняющих переменных) определяет тесноту связи с учетом степеней свободы общей и остаточной дисперсий. Он дает такую оценку тесноты связи, которая не зависит от числа факторов в модели и поэтому может сравниваться по разным моделям с разным числом факторов. Оба коэффициента указывают на весьма высокую детерминированность результата y в модели факторами x1 и x2.
Охарактеризуйте степень тесноты связи между результативным признаком и всеми факторными, включенными в уравнение регрессии, определив множественный коэффициент корреляции:
 .
.
Пункт 5 предполагает ознакомление с методикой дисперсионного анализа по модели множественной регрессии.
Проверьте статистическую значимость модели регрессии в целом с помощью F-критерия Фишера. Для этого воспользуйтесь алгоритмом проверки гипотез, изложенном в указаниях к пункту 4 задачи 1, учитывая, что фактическое значение F – критерия для уравнения множественной регрессии определяется по формуле:
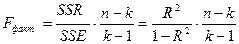 ,
,
где k - общее число параметров в уравнении множественной регрессии (в случае двухфакторной линейной регрессии k = 3).
Для проведения дисперсионного анализа и расчета фактического значения F - критерия рекомендуется также заполнить таблицу результатов дисперсионного анализа:
| Колеблемость результативного признака | Сумма квадратов | Число степеней свободы | Дисперсия | F-критерий |
| За счет регрессии | Сфакт. (SSR) | k |   (MSR) (MSR)
| 
|
| Остаточная | Сост. (SSE) | n-(k+1) |  (MSE) (MSE)
| |
| Общая | Собщ. (SST) | n-1 |
Для нашего примера:
Таблица 6. Дисперсионный анализ модели множественной регрессии
| Колеблемость результативного признака | Сумма квадратов | Число степеней свободы | Дисперсия | F-критерий |
| За счет регрессии | 579,303 | 2 | 289,651 | 26,402 |
| Остаточная | 76,797 | 7 | 10,971 | |
| Общая | 656,100 | 9 |
Оценку надежности уравнения регрессии в целом, его параметров и показателя тесноты связи  дает F-критерий Фишера:
дает F-критерий Фишера:

Вероятность случайного значения F - критерия = 24,402 составляет 0,0005, что значительно меньше 0,05. Следовательно, полученное значение неслучайно, оно сформировалось под влиянием существенных факторов. То есть подтверждается статистическая значимость всего уравнения, его параметров и показателя тесноты связи – коэффициента множественной корреляции.
Общий вывод по построенной регрессионной модели состоит в том, что на увеличение объёма продаж нового моющего средства значимо повлияла реклама на радио и телевидении: при увеличении расходов на рекламу – возрастал объем продаж. Затраты же на демонстрацию моющего средства в магазинах не оказали существенного влияния на рост объёма продаж.
Прогноз по модели множественной регрессии осуществляется по тому же принципу, что и для парной регрессии. Для получения прогнозных значений мы подставляем значения хi в уравнение для получения значения  . Предположим, что мы хотим узнать ожидаемый объем продаж моющего средства, при условии, что затраты на теле и радио рекламу составят 10 условных денежных единиц, а на демонстрацию в магазинах – 5 денежных единиц.
. Предположим, что мы хотим узнать ожидаемый объем продаж моющего средства, при условии, что затраты на теле и радио рекламу составят 10 условных денежных единиц, а на демонстрацию в магазинах – 5 денежных единиц.
 (денежных единиц).
(денежных единиц).
Качество прогноза – неплохое, поскольку в исходных данных таким значениям независимых переменных соответствует значение равное 70 денежных единиц.
Мы так же можем вычислить интервал прогноза как  - доверительный интервал для ожидаемого значения при заданных значениях независимых переменных:
- доверительный интервал для ожидаемого значения при заданных значениях независимых переменных:
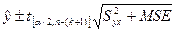 ,
,
где MSE – остаточная дисперсия, а стандартная ошибка 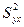 для случая нескольких независимых переменных имеет достаточно сложное выражение, которое мы здесь не приводим. доверительный интервал для значения при средних значениях независимых переменных имеет вид:
для случая нескольких независимых переменных имеет достаточно сложное выражение, которое мы здесь не приводим. доверительный интервал для значения при средних значениях независимых переменных имеет вид:  Большинство пакетов программ рассчитывают доверительные интервалы автоматически.
Большинство пакетов программ рассчитывают доверительные интервалы автоматически.
Задачи 3, 4 и 5 посвящены теме “Временные ряды в эконометрических исследованиях”, и, прежде всего проблеме автокорреляции уровней временного ряда и ее последствиям, а также наличию во временном ряде тенденции.
Задача 3.
Рассмотрим методику решения задачи на практическом примере:
Имеются следующие данные о расходах семьи на товар "А" в 1994-1999 гг.:
| Годы | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 |
| Расходы на товар "А", руб. | 30 | 35 | 39 | 44 | 50 | 53 |
Приступая к выполнению пункта 1, изучите вопрос об измерении автокорреляции уровней временного ряда.
Коэффициент автокорреляции первого порядка есть линейный коэффициент корреляции между уровнями исходного временного ряда и уровнями того же ряда сдвинутыми на один момент времени.
Его расчет производится по стандартным формулам для расчета линейного коэффициента корреляции:
 ,
,
где yt - 1 - уровни, сдвинутые по отношению к уровням исходного ряда на 1 год.
Заметим, что расчет должен быть осуществлен для пар наблюдений ( ,
,  , причем общее число пар наблюдений, по которым производится расчет, равно (n - 1). Близкое по абсолютной величине к единице значение коэффициента автокорреляции первого порядка свидетельствует о высокой тесноте связи между текущими и непосредственно предшествующими уровнями временного ряда или, иными словами, о наличии во временном ряде тенденции.
, причем общее число пар наблюдений, по которым производится расчет, равно (n - 1). Близкое по абсолютной величине к единице значение коэффициента автокорреляции первого порядка свидетельствует о высокой тесноте связи между текущими и непосредственно предшествующими уровнями временного ряда или, иными словами, о наличии во временном ряде тенденции.
В соответствии с условиями нашей задачи проведем расчеты
| yt | yt+1 | ytyt+1 | yt2 | yt+12 | |
| 1994 | 30 | 35 | 1050 | 900 | 1225 |
| 1995 | 35 | 39 | 1365 | 1225 | 1521 |
| 1996 | 39 | 44 | 1716 | 1521 | 1936 |
| 1997 | 44 | 50 | 2200 | 1936 | 2500 |
| 1998 | 50 | 53 | 2650 | 2500 | 2809 |
| Суммы | 198 | 221 | 8981 | 8082 | 9991 |

Коэффициент автокорреляции первого порядка равен 0,9896, что свидетельствует о тесной прямой связи между текущими и непосредственно предшествующими уровнями временного ряда.
В пункте 2 требуется определить функциональную форму и найти параметры уравнения, наилучшим образом описывающего тенденцию (тренд). Для определения вида тренда рассчитайте следующие показатели динамики:
а) цепные абсолютные приросты:  ;
;
б) абсолютные ускорения уровней ряда, или вторые разности: 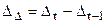 ;
;
в) цепные коэффициенты роста:  .
.
Проанализируйте полученные результаты.
Если приблизительно одинаковы цепные абсолютные приросты, то для описания тенденции временного ряда следует выбрать линейный тренд:  .
.
Если примерно постоянны абсолютные ускорения уровней ряда, следует выбрать параболу второго порядка: 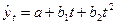 .
.
Если примерно одинаковы цепные коэффициенты роста, моделирование тенденции следует проводить с использованием экспоненциальной кривой:  .
.
Для расчета параметров уравнения тренда примените обычный МНК. В случае нелинейных зависимостей проведите линеаризацию исходной функции.
Дайте интерпретацию параметров тренда.
Коэффициент регрессии b в линейном тренде есть средний за период цепной абсолютный прирост уровней ряда.
В экспоненциальной функции величина  представляет собой средний за период цепной темп роста уровней ряда.
представляет собой средний за период цепной темп роста уровней ряда.
Начальный уровень ряда в момент (период времени) t = 0 в линейном тренде выражается параметром а, в экспоненциальном тренде - величиной  .
.
Для нашей задачи проведем следующие расчеты:.
| yt | 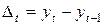
|
| 
| |
| 1994 | 30 | |||
| 1995 | 35 | 5 | 1,1667 | |
| 1996 | 39 | 4 | -1 | 1,1143 |
| 1997 | 44 | 5 | 1 | 1,1282 |
| 1998 | 50 | 6 | 1 | 1,1364 |
| 1999 | 53 | 3 | -3 | 1,0600 |
Очевидно, в данном случае для описания тренда можно выбрать линейную модель: 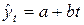 .
.
Для расчета параметров уравнения тренда применим обычный МНК.
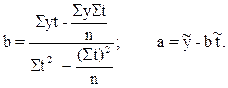
Если периоды или моменты времени пронумеровать так, чтобы получилось St =0, то вышеприведенные алгоритмы существенно упростятся и превратятся в

Расчеты проведем в следующей рабочей таблице.
| t | yt | t2 | ytt | |
| 1994 | -2,5 | 30 | 6,25 | -75 |
| 1995 | -1,5 | 35 | 2,25 | -52,5 |
| 1996 | -0,5 | 39 | 0,25 | -19,5 |
| 1997 | 0,5 | 44 | 0,25 | 22 |
| 1998 | 1,5 | 50 | 2,25 | 75 |
| 1999 | 2,5 | 53 | 6,25 | 132,5 |
| Суммы | 0,00 | 251 | 17,5 | 82,5 |

Таким образом, трендовое линейное уравнение регрессии имеет вид:
 .
.
Дадим интерпретацию параметров тренда.
Коэффициент регрессии (b) в линейном тренде показывает средний за период цепной абсолютный прирост уровней ряда. В нашем примере b = 4,7143, следовательно расходы на товар "А" в среднем за год увеличиваются на 4,7143 руб. Свободный член (а) в линейном тренде выражает начальный уровень ряда в момент (период времени) t = 0. В нашей нумерации t = 0 приходится на период времени между 1996 и 1997 гг., что несколько затрудняет его интерпретацию. В нашем случае а = 41,8333 руб. – это расходы семьи на товар "А" за вторую половину 1996 и первую половину 1997 гг.
В случае нелинейных зависимостей необходимо провести линеаризацию исходной функции.
Пункт 3. Точечный прогноз по уравнению тренда - это расчетное значение переменной , полученное путем подстановки в уравнение тренда соответствующих значений t. Интервальный прогноз рассчитывается в соответствии с методикой, изложенной для уравнения парной линейной регрессии (см. указания к пункту 5 задачи 1).
Дадим прогноз расходов на товар "А" на 2000 год.
В нашей нумерации 2000 год соответствует моменту времени t = 3,5. Отсюда,

Следовательно, точечная оценка расходов семьи на товар "А" на 2000 год составляет 58,3333 руб.
Определим границы доверительного интервала, в котором с заданной надежностью γ будут находится расходы семьи на товар "А" в 2000 году. Общепринятый в экономике уровень надежности γ = 1 - α = 1 - 0,05 = 0,95.
 ,
,
где  -прогноз значения переменной y на момент (период) времени t;
-прогноз значения переменной y на момент (период) времени t;
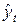 - точечная оценка значения переменной y на момент (период) времени t;
- точечная оценка значения переменной y на момент (период) времени t;
 - предельная ошибка прогноза.
- предельная ошибка прогноза.
Для того, чтобы получить интервальную оценку, определим величину предельной ошибки прогноза.
Она рассчитывается по формуле:
 ,
,
где 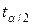 - табличное значение t - критерия Стьюдента для уровня значимости α и числа степеней свободы (k = n - 2);
- табличное значение t - критерия Стьюдента для уровня значимости α и числа степеней свободы (k = n - 2);
 - стандартная ошибка точечного прогноза, которая, в свою очередь, рассчитывается по формуле:
- стандартная ошибка точечного прогноза, которая, в свою очередь, рассчитывается по формуле:
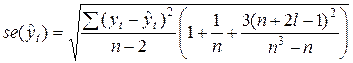 ,
,
где

