




Эта связь давно доказана и рассмотрена в специальной литературе для различных классов грамматик и методов разбора. В рамках данной дисциплины можно сослаться на основные источники информации, позволяющие получить фундаментальную подготовку по формальным грамматикам и методам разбора [14, 16]. Однако и в этих книгах рассматриваются только такие грамматики и автоматы, которые могут быть эффективно реализованы. Из всего разнообразия грамматик, используемых для построения распознавателей, нас будут интересовать только КС(1) грамматики, ориентированные на нисходящий левый разбор, при котором входная цепочка просматривается слева направо. Использование данных грамматик позволяет создавать достаточно мощные и понятные языки программирования.
Следует пояснить, почему дальнейшее изучение ограничивается только нисходящими методами разбора. Методы, используемые при нисходящем разборе, достаточно универсальны и разнообразны. Применение восходящего разбора позволяет использовать более мощные KC(1) грамматики, в том числе и грамматики с левой рекурсией, которые при нисходящем разборе использовать невозможно. Возникают проблемы преобразования таких грамматик в грамматики с правой рекурсией, ориентированные на нисходящий разбор. Такое преобразование не всегда очевидно. Однако применение диаграмм Вирта для представления синтаксиса языков программирования позволяет легко заменить все левые рекурсии на итерации и использовать полученные правила для нисходящего разбора. Поэтому при практической разработке трансляторов не имеет особого смысла использовать восходящий разбор.
Для того чтобы рассмотреть зависимость, существующую между КС(1) грамматиками и нисходящими распознавателями с магазинной памятью, обратимся к материалу, изложенному в книге Льюиса, Розенкранца и Стринза [16].
Связь между S-грамматикой и автоматом с магазинной памятью
Не все КС-грамматики пригодны для построения нисходящего детерминированного АМП, так как многие из них могут порождать одну и ту же терминальную цепочку различными левыми выводами. Это говорить об их неоднозначности и невозможности использования для детерминированного разбора. Однако определены и изучены такие классы грамматик, которые поддерживают нисходящий детерминированный разбор. Наиболее простыми из них являются S-грамматики.
КС-грамматика называется S-грамматикой (а также раздельной, или простой) тогда и только тогда, когда выполняются два условия:
1. Правая часть каждого правила начинается терминалом Ti.
2. Если два правила имеют совпадающие левые части, то правые части этих правил должны начинаться различными терминальными символами.
Пример.
Рассмотрим две грамматики, которые задают один и тот же язык.
Грамматика G9.2(S) содержит правила P:
1. S → aT
2. S → TbS
3. T → bT
4. T → ba
Это не S-грамматика, так как правило 2 начинается с нетерминала, что нарушает условие 1, а правила 3 и 4 имеют совпадающие левые части и начинаются с одинаковых терминальных символов.
S-грамматика G9.3(S) для этого же языка может использовать для порождения цепочек следующие правила:
1. S → abR
2. S → bRbS
3. R → a
4. R → bR
Использование данной грамматики позволяет упростить разбор, используя для этого соответствующий АМП.
Обобщенный алгоритм построения нисходящего АМП
Для S - грамматики
Построение нисходящего автомата с магазинной памятью для заданной S-грамматики осуществляется по следующему обобщенному алгоритму.
1. Множество входных символов автомата – это множество терминальных символов грамматики, расширенное концевым маркером.
2. Множество магазинных символов состоит из маркера дна, нетерминальных символов грамматики и терминалов, встречающихся в правых частях правил, за исключением тех, которые занимают только крайнюю левую позицию.
3. В начальном состоянии магазин содержит маркер дна и начальный нетерминал.
4. Устройство управления АМП имеет одно состояние и описывается управляющей таблицей, строки которой помечены магазинными символами, столбцы – входными символами, а элементы таблицы описываются в ниже следующих пунктах.
5. Каждому правилу грамматики ставится в соответствие элемент (клетка) таблицы. Правило должно иметь вид:
A → bα,
где А – нетерминал, b – терминал, α – цепочка из терминалов и нетерминалов. Этому правилу будет соответствовать элемент в строке А и столбце b:
Заменить (αr), Сдвиг,
где αr – цепочка, записанная в обратном порядке (для того, чтобы удовлетворить соглашению, что верхний символ находится справа при принятом способе записи стека, когда его дно располагается слева). Если правило имеет вид
А → b,
то вместо
Заменить e, Сдвиг
используется
Вытолкнуть, Сдвиг.
6. Если магазинным символом является терминал b, то элементом таблицы в строке b и столбце b будет
Вытолкнуть, Сдвиг
7. Элементом таблицы, который находится в строке маркера дна и столбце концевого маркера, является
Допустить
8. Элементы таблицы, не описанные ни в одном из пунктов 5, 6, 7 заполняются операцией
Отвергнуть
Используя данное описание, построим автомат для S-грамматики G9.3(S):
| Магазинные символы | Входные символы | ||
| a | b | ┤ | |
| S | ↕ Rb, → | ↕ SbR, → или ↓ bR, → | Отвергнуть |
| R | ↑, → | ↕ R, → | Отвергнуть |
| b | Отвергнуть | ↑, → | Отвергнуть |
| Ñ | Отвергнуть | Отвергнуть | Допустить |
Каким образом найдена представленная последовательность шагов построения АМП? В основе всего лежат особенности S-грамматики. Рассмотрим левый вывод терминальной цепочки bbababa. Он будет осуществляться следующим образом:
S Þ bRbS Þ bbRbS Þ bbababR Þ bbababa
Процедура построения нисходящего дерева разбора, представленная на Рисунке 9.1, показывает, что на каждом шаге правило для дерева выбирается однозначно и увеличивает количество распознанных символов на один.
Этот выбор определяется грамматикой, которая четко устанавливает соответствие между текущим нетерминалом, входным символом, а также правилом, определяющим текущий нетерминал. Правило задано таким образом, что на первом месте в его правой части стоит символ, совпадающий с текущим символом цепочки. Поэтому, не нужны возвраты назад. Если соответствующего правила не будет найдено, произойдет отказ. При нахождении искомого правила его первый символ нейтрализуется входным символом и отбрасывается (и потому не заносится в стек).
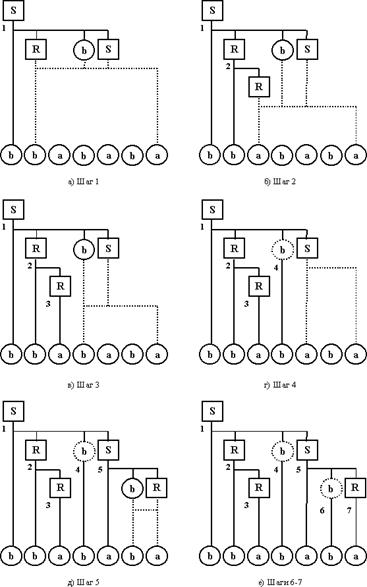
Рисунок 9.1 Нисходящий разбор слева направо
с использованием S-грамматики
Остальные же символы необходимо сохранить, чтобы использовать для формирования новых проверок на последующих шагах. Понятно также, что сохранение должно осуществляться в стеке (нет другой рабочей памяти) и в реверсивном порядке (так как самый левый символ правила должен разбираться первым, чтобы было соответствие с левым выводом). Отсюда также понятно, что терминалы, расположенные в середине правила, будут заноситься в стек и поэтому должны являться магазинными символами. Ясно также, что когда на вершине стека располагается терминал, он не может являться левой частью правила. Поэтому его необходимо просто вытолкнуть из стека, нейтрализуя эквивалентным входным символом.

