




Данный раздел посвящен проблеме расчета надежности сложных технических систем в процессе их проектирования при нечетко заданных исходных данных. Такая постановка задачи встречается в реальных условиях достаточно часто по двум причинам. Во-первых, надежностные характеристики отдельных блоков системы не всегда можно установить достаточно точно, в ряде случаев техническая документация дает разные значения, а иногда они и вовсе не указаны, и проектировщику приходится руководствоваться собственным опытом. Во-вторых, проектируемая система может работать в неблагоприятных условиях, и тогда реальные надежностные характеристики будут отличаться от тех, которые указаны в документации и справочной литературе.
Расчет надежности систем при нечетко заданных исходных данных практически не освещен в учебно-методической литературе, в отличие от стандартного расчета надежности системы при надежностных характеристиках, заданных детерминированно. Учитывая изложенное, в данном разделе основной упор будет сделан не на методику расчета надежности, а на ее модификацию применительно к нечетко заданным исходным данным [4]. Для упрощения изложения в качестве примера проектируемой системы будет взят самый простой ее вариант, поскольку алгоритм расчета надежности в условиях нечетко заданных исходных данных не зависит от сложности проектируемой системы.
Система может быть собрана из блоков различных типов. Надежностные характеристики блоков, составляющих систему, при этом рассматриваются как известные с определенной вероятностью. Достаточно хорошие возможности для этого предоставляет описание надежностных характеристик блока системы в форме нечеткого множества. Проектировщик (заказчик), задаваясь различными значениями, к примеру, среднего времени наработки на отказ, формулирует степень своей уверенности в реализации каждого из них с помощью показателя, именуемого «степенью принадлежности» и принимающего значения в диапазоне от 0 до 1 [1]. Чем хуже показатель с точки зрения надежности, тем выше степень уверенности в его реализации.
Предполагается, что в проектируемой системе отсутствует аппаратная избыточность, т.е. встроенные технические средства повышения надежности, такие как резервирование или дублирование, а системы встроенного функционального и тестового контроля обладают идеальными характеристиками: надежностью, полнотой контроля и глубиной локализации. В этом случае надежностные показатели блоков и методика расчета системы зависят от того, является она восстанавливаемой или невосстанавливаемой.
Рассматриваемая в настоящем разделе задача проектирования формулируется следующим образом: выбрать из нескольких заданных вариантов построения неизбыточной системы такой вариант, который минимизирует стоимость системы при надежности системы не хуже заданной.
Сформулируем алгоритм выбора (рис. 2.50).

Рис. 2.50. Алгоритм выбора оптимального варианта построения невосстанавливаемой системы в условиях нечеткого задания исходных данных
В соответствии с блоком 1 проектировщик определяет надежностные показатели блоков системы. В процессе определения показателей проектировщик в соответствии с блоком 2 выясняет, будет ли интенсивности отказов задана детерминировано или нет? Если да, то выбор оптимального варианта пойдет по левой ветви, если нет, то по правой. Последовательность шагов по левой и правой ветви в основном одинаковая. В блоках 3 (левая ветвь) и 6 (правая) выбираются возможные варианты построения системы. В блоках 4 (левая ветвь) и 7 (правая) рассчитываются надежностные показатели по каждому варианту построения системы. Далее при нечетко заданных исходных данных в блоке 8 правой ветви по каждому варианту рассчитываются потери от неверного выбора исходных надежностных показателей. И, наконец, в блоках 5 (левая ветвь) и 9 (правая) выбирается оптимальный вариант построения системы. В предыдущем разделе в примерах 2.13 и 2.14 был рассмотрен расчет надежности систем, структура которых уже была зафиксирована. Соответственно, в обоих случаях путь продвижения по алгоритму был: 1 – 2 – 4б.
Рассмотрим более сложные случаи реализации блоков данного алгоритма для невосстанавливаемых и восстанавливаемых систем, когда есть несколько вариантов построения системы.
Выбор оптимального варианта для невосстанавливаемых систем
Для невосстанавливаемых систем основной характеристикой надежности является среднее время наработки на отказ Т или интенсивность отказов l, при этом обе характеристики связаны соотношением (2.16).
В качестве основной надежностной характеристики при формировании исходного нечеткого множества выберем интенсивность отказов l, так как чем выше интенсивность отказов, тем выше уверенность в том, что реальная интенсивность отказов не превысит заданную. Тогда нечеткое множество интенсивности отказов для заданного блока будет выглядеть следующим образом:
l = {(l1 |b1), (l2 |b2), …, (l n |b n)}, (2.127)
где l1, 2, …, n – значение интенсивности отказов; b1,2, …, n – вероятность того, что реальная интенсивность отказов не превысит заданную.
Пример 2.15. При определении интенсивности отказов для заданного блока проектировщик получил следующее множество:
l i = {(1,35 × 10–6|0,8), (2,80 × 10–6|0,9), (4,60 × 10–6|0,95)},
что означает: интенсивность отказа блока не превысит 1,35 × 10–6 со степенью уверенности 0,8, не превысит 2,80 × 10–6 со степенью уверенности 0,9 и не превысит 4,60 × 10–6 со степенью уверенности 0,95.
Совокупность интенсивностей отказов для всех блоков образует массив L.
В случае если проектировщику известна точная интенсивность отказов блока, нечеткое множество переходит в детерминированную характеристику блока системы и вместо правой ветви алгоритма проектировщик пойдет по левой.
Первый блок алгоритма – определение интенсивности отказов блоков системы – был проанализирован выше. Рассмотрим левую ветвь алгоритма – выбор составляющих блоков системы по известным надежностным характеристикам возможных вариантов блоков, заданных детерминировано.
При построении системы имеется возможность выбора между однотипными блоками с различными надежностными характеристиками и различной стоимостью. Сначала рассмотрим пример выбора структуры системы с детерминированно заданными характеристиками.
Пример 2.16. Пусть в вычислительной системе используется центральный процессор и блок ОЗУ (см. рис. 2.25). Выбирать можно между двумя типами процессора, причем интенсивность отказов первого типа процессора 152 × 10–6, стоимость его 60 у.е., а интенсивность отказов второго типа процессора 250 × 10–6, стоимость 40 у.е. Для ОЗУ также имеется выбор из двух типов, интенсивность отказов первого типа ОЗУ 64 × 10–6, стоимость его 10 у.е., а интенсивность отказов второго типа процессора 80 × 10–6, стоимость 8 у.е. Выбрать наименьший по стоимости вариант построения системы с интенсивностью отказов не выше 300 × 10–6.
На первом этапе проводится полный перебор вариантов построения системы. Возможно 4 варианта построения системы:
1) процессор – тип 1; ОЗУ – тип 1;
2) процессор – тип 1; ОЗУ – тип 2;
3) процессор – тип 2; ОЗУ – тип 1;
4) процессор – тип 2; ОЗУ – тип 2.
Просчитаем интенсивность отказов по каждому из четырех вариантов в соответствии с методикой, приведенной в подразд. 2.1.5 (формула (2.26)):
1)l1 = 1 × 152 × 10–6 + 1 × 64 × 10–6 = 216 × 10–6,
2) l2 = 1 × 152 × 10–6 + 1 × 80 × 10–6 = 232 × 10–6,
3) l3 = 1 × 250 × 10–6 + 1 × 64 × 10–6 = 314 × 10–6,
4) l4 = 1 × 250 × 10–6 + 1 × 80 × 10–6 = 330 × 10–6.
Запишем интенсивности отказов и стоимости всех четырех вариантов:
1)l1 = 216 × 10–6, С = 70 у.е.;
2) l2 = 232 × 10–6, С = 68 у.е.;
3) l3 = 314 × 10–6, С = 50 у.е;
4) l4 = 330 × 10–6, С = 48 у.е.
По надежности нас устраивают первый и второй варианты, по стоимости предпочтительным является второй вариант, как более дешевый.
Рассмотрим правую часть алгоритма, показанного рис. 2.50: расчет надежности системы по надежностным характеристикам составляющих ее блоков, заданных в форме нечеткого множества.
Пример 2.17. Рассмотрим систему из примера 2.16. Пусть интенсивность отказов двух вариантов центрального процессора и ОЗУ задана в форме нечеткого множества:
lп1 = (140 × 10–6|0,8; 152 × 10–6|0,85; 160 × 10–6|0,9),
lп2 = (240 × 10–6|0,7; 250 × 10–6|0,85; 270 × 10–6|0,9),
lОЗУ1 = (60 × 10–6|0,8; 64 × 10–6|0,9; 70 × 10–6|0,95),
lОЗУ2 = (75 × 10–6|0,85; 80 × 10–6|0,9; 90 × 10–6|0,95),
где lп1, lп2, lОЗУ1 и lОЗУ2 образуют в совокупности массив L.
Массив L формируем следующим образом. Выписываем все значения вероятности задания исходных данных, входящие в данный массив. Одинаковые значения объединяем, оставшиеся выстраиваем по возрастанию. Получим пять значений:
1) b1 = 0,7; 2) b2 = 0,8; 3) b3 = 0,85; 4) b4 = 0,9; 5) b5 = 0,95.
Произведем разложение массива L на четкие подмножества b-уровня, руководствуясь следующим правилом:
 (2.128)
(2.128)
где b – фиксированное значение вероятности из набора значений массива L. При этом для каждого значения b рассматриваются все возможные варианты построения системы.
Для каждого из пяти вариантов построения системы значения интенсивности отказов берутся по вышеуказанному алгоритму. Рассмотрим подробнее построение четких подмножеств для значения b = 0,7. Для первого варианта (процессор типа 1, ОЗУ типа 1) в качестве интенсивности отказов процессора берется значение lп1 = 140×10–6, имеющее b = 0,8, поскольку это ближайшая большая вероятность в ряду значений интенсивности отказов для процессора типа 1. Для ОЗУ типа 1 берется lОЗУ1 = 60×10–6, по той же самой причине и т.д.
В соответствии с этим алгоритмом четких множеств для b = 0,95 построить не удается, поскольку не для все типов процессора и ОЗУ есть надежностные характеристики с вероятностью, большей или равной 0,95.
Таким образом, четкие множества строятся для четырех значений вероятности:
1) b1 = 0,7; 2) b2 = 0,8; 3) b3 = 0,85; 4) b4 = 0,9.
В результате разбиений массива L получаем:
1) b1 = 0,7: lп1 = 140 × 10–6; lОЗУ1 = 60 × 10–6;
2) lп1 = 140 × 10–6; lОЗУ2 = 75 × 10–6;
3) lп2 = 240 × 10–6; lОЗУ1 = 60 × 10–6;
4) lп2 = 240 × 10–6; lОЗУ2 = 75 × 10–6;
5) b2 = 0,8: lп1 = 140 × 10–6; lОЗУ1 = 60 × 10–6;
6) lп1 = 140 × 10–6; lОЗУ2 = 75 × 10–6;
7) lп2 = 250 × 10–6; lОЗУ1 = 60 × 10–6;
8) lп2 = 250 × 10–6; lОЗУ2 = 75 × 10–6;
9) b3 = 0,85: lп1 = 152 × 10–6; lОЗУ1 = 64 × 10–6;
10) lп1 = 152 × 10–6; lОЗУ2 = 80 × 10–6;
11) lп2 = 250 × 10–6; lОЗУ1 = 64 × 10–6;
12) lп2 = 250 × 10–6; lОЗУ2 = 80 × 10–6;
13) b4 = 0,9: lп1 = 160 × 10–6; lОЗУ1 = 64 × 10–6.
14) lп1 = 160 × 10–6; lОЗУ2 = 80 × 10–6;
15) lп2 = 270 × 10–6; lОЗУ1 = 64 × 10–6;
16) lп2 = 270 × 10–6; lОЗУ2 = 80 × 10–6.
Далее проводим расчет надежности системы по каждому из полученных шестнадцати вариантов исходных данных. Расчет надежности ведем в соответствии с методикой, изложенной в подразд. 2.1.5 (формула (2.26)).
Для шестнадцати вариантов проводим расчет надежности системы. Дополним полученные данные значениями стоимости С для каждого варианта:
1) b = 0,7; l = 200 × 10–6; С = 70 у.е.;
2) b = 0,7; l = 215 × 10–6; С = 68 у.е.;
3) b = 0,7; l = 300 × 10–6; С = 50 у.е.;
4) b = 0,7; l = 315 × 10–6; С = 48 у.е.;
5) b = 0,8; l = 200 × 10–6; С = 70 у.е.;
6) b = 0,8; l = 215 × 10–6; С = 68 у.е.;
7) b = 0,8; l = 310 × 10–6; С = 50 у.е.;
8) b = 0,8; l = 325 × 10–6; С = 48 у.е.;
9) b = 0,85; l = 216 × 10–6; С = 70 у.е.;
10) b = 0,85; l = 232 × 10–6; С = 68 у.е.;
11) b = 0,85; l = 314 × 10–6; С = 50 у.е.;
12) b = 0,85; l = 330 × 10–6; С = 48 у.е.;
13) b = 0,9; l = 224 × 10–6; С = 70 у.е.;
14) b = 0,9; l = 240 × 10–6; С = 68 у.е.;
15) b = 0,9; l = 334 × 10–6; С = 50 у.е.;
16) b = 0,9; l = 350 × 10–6; С = 48 у.е.
Из полученных результатов видно, что четвертые варианты построения системы не обеспечивают заданную надежность ни при одном значении b. Следовательно, их можно исключить из рассмотрения для уменьшения размерности задачи (это строки 4, 8, 12 и 16). Поэтому в дальнейшем мы будем работать с минимизированной таблицей, состоящей из следующих двенадцати вариантов:
1) b = 0,7; l = 200 × 10–6; С = 70 у.е.;
2) b = 0,7; l = 215 × 10–6; С = 68 у.е.;
3) b = 0,7; l = 300 × 10–6; С = 50 у.е.;
4) b = 0,8; l = 200 × 10–6; С = 70 у.е.;
5) b = 0,8; l = 215 × 10–6; С = 68 у.е.;
6) b = 0,8; l = 310 × 10–6; С = 50 у.е.;
7) b = 0,85; l = 216 × 10–6; С = 70 у.е.;
8) b = 0,85; l = 232 × 10–6; С = 68 у.е.;
9) b = 0,85; l = 314 × 10–6; С = 50 у.е.;
10) b = 0,9; l = 224 × 10–6; С = 70 у.е.;
11) b = 0,9; l = 240 × 10–6; С = 68 у.е.;
12) b = 0,9; l = 334 × 10–6; С = 50 у.е.
Определив интенсивность отказов всех вариантов построения системы, их стоимость и вероятность осуществления каждого варианта, можно провести оптимизацию выбора варианта построения системы. Оптимизацию будем проводить в два этапа. На первом этапе воспользуемся методом наименьших потерь [2].
Введем в рассмотрение эталонное решение Э, которое характеризуется минимальным значением интенсивности отказов lЭ и минимальным значением стоимости системы СЭ (при этом минимальное значение интенсивности отказов lЭ должно быть меньше заданного техническими условиями для проектируемой системы).
Для данных из нашего примера эталонное решение будет характеризоваться следующими значениями: lЭ = 200×10–6; СЭ = 50 у.е., где в качестве значения для интенсивности отказов и стоимости взяты минимальные значения из вышеприведенных.
Первое соотношение 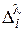 будет характеризовать проигрыш в интенсивности отказов данного варианта Ri по отношению к эталонному:
будет характеризовать проигрыш в интенсивности отказов данного варианта Ri по отношению к эталонному:
 . (2.129)
. (2.129)
Второе соотношение  будет характеризовать проигрыш в стоимости данного варианта Ri по отношению к эталонному:
будет характеризовать проигрыш в стоимости данного варианта Ri по отношению к эталонному:
 . (2.130)
. (2.130)
Проигрыш решения Ri по сравнению с эталонным (D i) оценивается:

или
 . (2.131)
. (2.131)
Очевидно, что все значения потерь будут отрицательными, так как эталонный вариант является наилучшим из всех возможных. Поскольку нас интересует не знак, а абсолютная величина потерь, знак «минус» в дальнейших расчетах будет отброшен и все значения потерь будут рассматриваться по абсолютной величине.
Рассчитаем проигрыш по сравнению с эталонным вариантом для всех решений. Для первых двух вариантов расчет D i покажем подробно, а для остальных просто запишем результаты:
1) b = 0,7; l = 200 × 10–6; С = 70 у.е.;  ,
,  ;
;
D i = |(1 – 1,0) + (1 – 1,47)| = 0,47;
2) b = 0,7; l = 215×10–6; С = 68 у.е.;  ,
,
 ; Di =| (1 – 1,075) + (1 – 1,417)| = 0,49;
; Di =| (1 – 1,075) + (1 – 1,417)| = 0,49;
3) b = 0,7; l = 300 × 10–6; С = 50 у.е.; D i = 0,54;
4) b = 0,8; l = 200 × 10–6; С = 70 у.е.; D i = 0,47;
5) b = 0,8; l = 215 × 10–6; С = 68 у.е.; D i = 0,54;
6) b = 0,8; l = 310 × 10–6; С = 50 у.е.; D i = 0,61;
7) b = 0,85; l = 216 × 10–6; С = 70 у.е.; D i = 0,57;
8) b = 0,85; l = 232 × 10–6; С = 68 у.е.; D i = 0,565;
9) b = 0,85; l = 314 × 10–6; С = 50 у.е.; D i = 0,73;
10) b = 0,9; l = 228 × 10–6; С = 70 у.е.; D i = 0,62;
11) b = 0,9; l = 240 × 10–6; С = 68 у.е.; D i = 0,61;
12) b = 0,9; l = 334 × 10–6; С = 50 у.е.; D i = 0,78.
Рассчитав потери на первом этапе для каждого варианта построения системы, определяем затем потери по сравнению с эталонным вариантом для каждого значения вероятности.
Из полученного списка вариантов видно, что для первых вариантов построения системы (процессор типа 1 и ОЗУ типа 1) потери для всех четырех вероятностей будут иметь следующие значения:
b = 0,7; D i = 0,47;
b = 0,8; D i = 0,47;
b = 0,85; D i = 0,57;
b = 0,9; D i = 0,62.
На втором этапе рассчитывается усредненное значение потерь для каждого варианта по следующей формуле:
 , (2.132)
, (2.132)
где n – количество значений вероятности, на которые был разбит исходный массив L. В качестве оптимального принимается вариант с минимальным значением потерь:
 (2.133)
(2.133)
Просчитаем значения усредненной вероятности по формуле (2.132) для трех вариантов построения системы и значений вероятности, приведенных в примере 2.17.
Для варианта 1
D = 0,7 × 0,47 + 0,8 × 0,47 + 0,85 × 0,57 + 0,9 × 0,62 = 1,7475.
Для варианта 2
D = 0,7 × 0,49 + 0,8 × 0,49 + 0,85 × 0,565 + 0,9 × 0,61 = 1,764.
Для варианта 3
D = 0,7 × 0,54 + 0,8 × 0,61 + 0,85 × 0,73 + 0,9 × 0,78 = 2,189.
В результате данного расчета в качестве оптимального следует принять первый вариант построения системы – процессор типа 1 и ОЗУ типа 1, имеющий минимальные потери по сравнению с эталонным вариантом.
В данном разделе был рассмотрен алгоритм выбора невосстанавливаемой системы, оптимальной по стоимости при надежности не хуже заданной, в условиях нечетко заданных исходных данных. Как было показано, задание исходных данных в виде нечеткого множества позволяет более точно отразить реальность. Расчеты по предложенному алгоритму (см. рис. 2.50) показывают, что оптимальный вариант, выбранный по идеализированным (детерминированно заданным) исходным данным, может отличаться от оптимального варианта, выбранного по более реальным данным, представленным в виде нечеткого множества.
Выбор оптимального варианта для восстанавливаемых систем
Как было указано выше (подразд. 1.1.5), характеристики восстанавливаемых систем отличаются от характеристик невосстанавливаемых систем. Для установившегося режима работы восстанавливаемой системы (а именно этот режим рассматривается в настоящем пособии, см. подразд. 2.3.1.) имеют место пары: интенсивность отказов l/среднее время между отказами Т о и интенсивность потока восстановлений m/среднее время восстановления Т в.
При формировании исходного нечеткого множества будем задаваться интенсивностью отказов lо и средним временем восстановления Т в (величина, обратно пропорциональная интенсивности восстановлений lв), так как чем выше значение интенсивности отказов и среднего времени восстановления, тем выше уверенность в том, что реальные поток отказов и среднее время восстановления не превысят заданные.
Пример 2.18. При определении потока отказов и среднего времени восстановления для заданного блока проектировщик получил следующее множество:
lо i = {(1,35 × 10–6|0,8), (2,80 × 10–6|0,9), (4,60 × 10–6|0,95)},
Т в i = {(2,4|0,7), (2,8|0,8), (3,5|0,9)},
что означает: интенсивность отказа блока не превысит 1,35×10–6 со степенью уверенности 0,8, не превысит 2,80 ×10–6 со степенью уверенности 0,9 и не превысит 4,60 ×10–6 со степенью уверенности 0,95. Аналогично читается и время восстановления.
Совокупность потоков отказов и времени восстановления для всех блоков образует массив L.
В случае если проектировщику известны точные данные об интенсивности потока отказов и времени восстановления блока, нечеткое множество переходит в детерминированную характеристику блока системы.
Таким образом, в зависимости от того, являются ли исходные данные для расчета вероятностными или детерминированными, будут применяться разные способы расчета. Алгоритм же выбора оптимального варианта в целом изменяться не будет.
Первый блок алгоритма – определение интенсивности отказов блоков системы – был проанализирован выше. Рассмотрим левую ветвь алгоритма – выбор составляющих блоков системы по известным надежностным характеристикам возможных вариантов сочетания блоков, заданных детерминированно.
При построении системы имеется возможность выбора между однотипными блоками с различными надежностными характеристиками и различной стоимостью. Перебор всех возможных вариантов построения системы и составляет суть блока 3.
Пример 2.19. Пусть в вычислительной системе используется центральный процессор и блок ОЗУ. Выбирать можно между двумя типами процессора, причем поток отказов первого типа процессора 152×10–6, стоимость его 60 у.е., а поток отказов второго типа процессора 250×10–6, стоимость 40 у.е. Время восстановления для обоих типов процессора одинаково и равно 1 ч. Для ОЗУ также имеется выбор из двух типов, причем поток отказов первого типа ОЗУ 64×10–6, стоимость его 10 у.е., а поток отказов второго типа процессора 80×10–6, стоимость 8 у.е. Время восстановления для обоих типов ОЗУ также одинаково и равно 0,5 ч.
Ставится следующая оптимизационная задача: выбрать наименьший по стоимости вариант построения системы с коэффициентом готовности не ниже 0,97.
На первом этапе проводится полный перебор вариантов построения системы. Возможны 4 варианта построения системы (блок 3):
1) процессор – тип 1; ОЗУ – тип 1;
2) процессор – тип 1; ОЗУ – тип 2;
3) процессор – тип 2; ОЗУ – тип 1;
4) процессор – тип 2; ОЗУ – тип 2.
Исследование надежности восстанавливаемых объектов (блок 4) проводится по методике, описанной в подразд. 2.3.2.
Для приведенных исходных данных просчитаем коэффициент готовности в соответствии с системой (2.108) по каждому из четырех вариантов:
1) K г = 0,98;
2) K г = 0,975;
3) K г = 0,95;
4) K г = 0,945.
Далее среди вариантов, устраивающих нас с точки зрения надежности, выбираем вариант, наименьший по стоимости (блок 5). Запишем коэффициенты готовности и стоимости двух устраивающих по надежности вариантов:
1) K г = 0,98, С = 70 у.е.;
2) K г = 0,975, С = 68 у.е.
С точки зрения стоимости предпочтительным является второй вариант, как более дешевый.
Рассмотрим правую часть алгоритма – расчет надежности системы по надежностным характеристикам составляющих ее блоков, заданных в форме нечеткого множества. Сначала вернемся к блоку 1 алгоритма расчета – определению вероятностных характеристик блоков системы.
Пример 2.20. Рассмотрим систему из примера 2.19. Пусть поток отказов и среднее время восстановления двух вариантов центрального процессора и ОЗУ заданы в форме нечетких множеств:
lп1 = (140 × 10–6|0,8; 152 × 10–6|0,85; 160 × 10–6|0,9),
Т в п1 = (1,5|0,7; 2,0|0,8; 2,5|0,9),
lп2 = (240 × 10–6|0,7; 250 × 10–6|0,85; 270 × 10–6|0,9),
Т в п2 = (1,5|0,7; 2,0|0,8; 2,5|0,9),
lОЗУ1 = (60 × 10–6|0,8; 64 × 10–6|0,9; 70 × 10–6|0,95),
Т в ОЗУ1 = (0,5|0,7; 1,0|0,8; 2,0|0,9),
lОЗУ2 = (75 × 10–6|0,85; 80 × 10–6|0,9; 90 × 10–6|0,95),
Т в ОЗУ2 = (0,5|0,7; 1,0|0,8; 2,0|0,9),
где lп1 , Т в п1, lп2 , Т в п2 , lОЗУ1, Т в ОЗУ1, lОЗУ2 и Т в ОЗУ2 образуют в совокупности массив L. Массив L формируем следующим образом. Выписываем все значения вероятности, входящие в данный массив, одинаковые значения объединяем, оставшиеся выстраиваем по возрастанию. Получаем пять значений:
1) b1 = 0,7; 2) b2 = 0,8; 3) b3 = 0,85; 4) b4 = 0,9; 5) b5 = 0,95.
Произведем разложение массива L на четкие подмножества b-уровня (блок 6), руководствуясь вышеописанным правилом (2.128):

При этом для каждого значения b рассматриваются все возможные варианты построения системы.
Для каждого значения вероятности по каждому варианту построения системы значения потока отказов и времени восстановления берутся по вышеуказанному алгоритму. Рассмотрим подробнее построение четких подмножеств для значения b = 0,7. Для первого варианта (процессор типа 1, ОЗУ типа 1) в качестве потока отказов процессора берется значение lп1 = 140 × 10–6, имеющее b = 0,8, поскольку это ближайшая большая вероятность в ряду значений потока отказов для процессора типа 1. Для ОЗУ типа 1 берется lОЗУ1 = 60 × 10–6, по той же самой причине. Среднее время восстановления для процессора берется равным 1,5, для ОЗУ – 0,5; оба эти значения имеют b = 0,7.
В соответствии с этим алгоритмом разбиения четких множеств для b = 0,95 построить не удается, поскольку не для всех типов процессора имеются надежностные характеристики с вероятностью, большей или равной 0,95.
Таким образом, четкие множества строятся для четырех значений вероятности:
1) b1 = 0,7; 2) b2 = 0,8; 3) b3 = 0,85; 4) b4 = 0,9.
В результате разбиений массива L получаем:
1) b1 = 0,7: lп1 = 140 × 10–6; lОЗУ1 = 60 × 10–6;
Т в п1 = 1,5; Т в ОЗУ1 = 0,5;
2) lп1 = 140 × 10–6; lОЗУ2 = 75 × 10–6;
Т в п1 = 1,5; Т в ОЗУ2 = 0,5;
3) lп2 = 240 × 0–6; lОЗУ1 = 60 × 10–6;
Т в п2 = 1,5; Т в ОЗУ1 = 0,5;
4) lп2 = 240 × 10–6; lОЗУ2 = 75 × 10–6;
Т в п2 = 1,5; Т в ОЗУ2 = 0,5;
5) b2 = 0,8: lп1 = 140 × 10–6; lОЗУ1 = 60 × 10–6;
Т в п1 = 2,0; Т в ОЗУ1 = 1,0;
6) lп1 = 140 × 10–6; lОЗУ2 = 75 × 10–6;
Т в п1 = 2,0; Т в ОЗУ2 = 1,0;
7) lп2 = 250 × 10–6; lОЗУ1 = 60 × 10–6;
Т в п2 = 2,0; Т в ОЗУ1 = 1,0;
8) lп2 = 250 × 10–6; lОЗУ2 = 75 × 10–6;
Т в п2 = 2,0; Т в ОЗУ2 = 1,0;
9) b3 = 0,85: lп1 = 152 10–6; lОЗУ1 = 64 × 10–6;
Т в п1 = 2,5; Т в ОЗУ1 = 1,5;
10) lп1 = 152 × 10–6; lОЗУ2 = 80 × 10–6;
Т в п1 = 2,5; Т в ОЗУ2 = 1,5;
11) lп2 = 250 × 10–6; lОЗУ1 = 64 × 10–6;
Т В П2 = 2,5; Т В ОЗУ1 = 1,5;
12) lп2 = 250 × 10–6; lОЗУ2 = 80 × 10–6;
Т в п2 = 2,5; Т в ОЗУ2 = 1,5;
13) b4 = 0,9: lп1 = 160 × 10–6; lОЗУ1 = 64 × 10–6;
Т в п1 = 2,5; Т в ОЗУ1 = 1,5;
14) lп1 = 160 × 10–6; lОЗУ2 = 80 × 10–6;
Т в п1 = 2,5; Т в ОЗУ2 = 1,5;
15) lп2 = 270 × 10–6; lОЗУ1 = 64 × 10–6;
Т в п2 = 2,5; Т в ОЗУ1 = 1,5;
16) lп2 = 270 × 10–6; lОЗУ2 = 80 × 10–6;
Т в п2 = 2,5; Т в ОЗУ2 = 1,5.
Далее проводим расчет надежности системы по каждому из полученных шестнадцати вариантов исходных данных (блок 7). Расчет надежности ведется в соответствии с методикой расчета надежности восстанавливаемых систем, изложенной при рассмотрении детерминированного задания исходных данных в примере 2.19.
Для шестнадцати представленных вариантов проводим расчет коэффициента готовности системы. Дополним полученные данные значениями стоимости для каждого варианта:
1) b = 0,7; K г = 0,99; С = 70 у.е.,
2) b = 0,7; K г = 0,98; С = 68 у.е.,
3) b = 0,7; K г = 0,96; С = 50 у.е.,
4) b = 0,7; K г = 0,95; С = 48 у.е.,
5) b = 0,8; K г = 0,99; С = 70 у.е.,
6) b = 0,8; K г = 0,98; С = 68 у.е.,
7) b = 0,8; K г = 0,96; С = 50 у.е.,
8) b = 0,8; K г = 0,95; С = 48 у.е.,
9) b = 0,85; K г = 0,98; С = 70 у.е.,
10) b = 0,85; K г = 0,97; С = 68 у.е.,
11) b = 0,85; K г = 0,95; С = 50 у.е.,
12) b = 0,85; K г = 0,94; С = 48 у.е.,
13) b = 0,9; K г = 0,97; С = 70 у.е.,
14) b = 0,9; K г = 0,96; С = 68 у.е.,
15) b = 0,9; K г = 0,90; С = 50 у.е.,
16) b = 0,9; K г = 0,88; С = 48 у.е.
С целью уменьшения размерности задачи проведем минимизацию этих данных: вычеркнем варианты построения системы, для которых при всех вероятностях исходных данных коэффициент готовности получается меньше заданного. В данном случае это варианты 3 и 4. В результате остается восемь вариантов:
1) b = 0,7; K г = 0,99; С = 70 у.е.,
2) b = 0,7; K г = 0,98; С = 68 у.е.,
3) b = 0,8; K г = 0,99; С = 70 у.е.,
4) b = 0,8; K г = 0,98; С = 68 у.е.,
5) b = 0,85; K г = 0,98; С = 70 у.е.,
6) b = 0,85; K г = 0,97; С = 68 у.е.,
7) b = 0,9; K г = 0,97; С = 70 у.е.,
8) b = 0,9; K г = 0,96; С = 68 у.е.
Строка номер восемь остается в системе, поскольку она соответствует второму варианту построения системы, который для других значений b дает коэффициент готовности не хуже 0,97.
Определив интенсивность отказов данного варианта построения системы, его стоимость и вероятность осуществления такого варианта, можно провести оптимизацию выбора варианта построения системы. Оптимизацию будем проводить в два этапа. На первом этапе (блок 8) снова воспользуемся методом наименьших потерь [2].
Как и выше, введем в рассмотрение эталонное решение Э, которое характеризуется максимальным значением коэффициента готовности K г э и минимальным значением стоимости системы Сэ.
Для вариантов нашего примера эталонное решение будет характеризоваться следующими значениями: K э = 0,99; Сэ= 48 у.е.
Первая характеристика  будет характеризовать проигрыш по коэффициенту готовности данного варианта Ri по отношению к эталонному (2.86), вторая характеристика
будет характеризовать проигрыш по коэффициенту готовности данного варианта Ri по отношению к эталонному (2.86), вторая характеристика 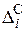 будет характеризовать проигрыш по стоимости данного варианта Ri по отношению к эталонному (2.130).
будет характеризовать проигрыш по стоимости данного варианта Ri по отношению к эталонному (2.130).
Проигрыш решения Ri по сравнению с эталонным – D i – оценивается опять же по соотношению (2.131):

Рассчитаем проигрыш по сравнению с эталонным вариантом для всех решений. Для первых двух вариантов расчет D i покажем подробно, а для остальных просто запишем результаты:
1) b = 0,7; K г = 0,99; С = 70 у.е.,
 ;
;  ,
,
D i = |(1 – 1,0) + (1 – 1,47)| = 0,47;
2) b = 0,7; K г = 0,98; С = 68 у.е.,
 ;
; 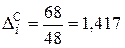 ,
,
D i =|(1 – 0,99) + (1 – 1,417)| = 0,407;
3) b = 0,8; K г = 0,99; С = 70 у.е.; D i = 0,47;
4) b = 0,8; K г = 0,99; С = 68 у.е.; D i = 0,54;
5) b = 0,85; K г = 0,99; С = 70 у.е.; D i = 0,57;
6) b = 0,85; K г = 0,99; С = 68 у.е.; D i = 0,565;
7) b = 0,9; K г = 0,99; С = 70 у.е.; D i = 0,62;
8) b = 0,9; K г = 0,99; С = 68 у.е.; D i = 0,61.
Рассчитав потери на первом этапе для каждого варианта построения системы, можно определить потери по сравнению с эталонным вариантом для каждого значения вероятности.
Из сравнения полученных восьми вариантов видно, что в первом варианте построения системы (процессор типа 1 и ОЗУ типа 1) потери для всех четырех вероятностей будут иметь следующие значения:
b = 0,7; D i = 0,47;
b = 0,8; D i = 0,47;
b = 0,85; D i = 0,57;
b= 0,9; D i = 0,62.
На втором этапе (блок 9) рассчитывается усредненное значение потерь для каждого варианта по формуле (2.132).
В качестве оптимального принимается вариант с минимальным по абсолютной величине значением потерь (2.133):

Просчитаем значения усредненной вероятности для вариантов построения системы и значений вероятности.
Для варианта 1
D = 0,7 × (0,47) + 0,8 × (0,47) + 0,8 × (0,57) + 0,9 × (0,62) = 1,7475.
Для варианта 2
D = 0,7 × (0,407) + 0,8 × (0,54) + 0,85 × (0,565) + 0,9 × (0,61) = 1,763.
В результате данного расчета в качестве оптимального следует принять первый вариант построения системы – процессор типа 1 и ОЗУ типа 1, поскольку усредненные потери для варианта 1 оказываются меньше усредненных потерь для варианта 2.
Таким образом, из приведенного анализа и сравнения примеров видно, что детерминированный подход к решению сформулированной выше задачи и подход к расчету на основе представления данных в виде нечеткого множества дают разные результаты.
Проанализировав методику расчета надежности для простейших невосстанавливаемых и восстанавливаемых систем, можно сделать следующие выводы.
Традиционное детерминированное задание исходных данных является идеализированным и не позволяет учесть при проектировании системы специфику возможного изменения надежностных характеристик отдельных блоков. Задание исходных данных в форме нечеткого множества представляется более приближенным к реальным условиям расчета надежности и выбору оптимального по критерию надежность/стоимость варианта проектируемой системы.
Методика расчета надежности для систем с различной надежностной конфигурацией при точном (детерминированном) задании исходных данных принципиально не изменяется при переходе к заданию исходных данных в форме нечеткого множества. Нами показано, что существенные изменения претерпевают блоки общего алгоритма выбора оптимального варианта построения системы, связанные с определением надежностных характеристик модулей в составе системы, при задании их исходных данных в форме нечеткого множества. В частности, изменяется исходный этап определения надежностных характеристик отдельных блоков (блок 1, см. рис. 2.46), когда приходится выбирать, какие конкретно характеристики являются наиболее подходящими для представления в форме нечеткого множества, как это показано при рассмотрении соответствующих блоков общего алгоритма для невосстанавливаемых и восстанавливаемых систем (соответственно примеры 2.16 и 2.17 и примеры 2.19 и 2.20).

