




Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
1 байт = 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена). Таблица кодов ASCII делится на две части. Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
В таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
Билет №18 Кодирование графической информации: векторное и растровое кодирование.
Кодирование - преобразование входной информации в форму, воспринимающую компьютером, т.е. двоичный код.
Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
Информация представлена в
Аналоговой (плавный) Дискретной (Прерывистый)
Дискретизация – преобразование непрерывных изображений в набор дискретных значений – кодов.
Изображения
Растровые –
совокупность точек(пикселей) разных цветов.
Достоинства:
- можно кодировать любые изображения;
- лучше всего подходит для кодирования и обработки фотографий.
Недостатки:
- есть потеря информации
- при увеличении или уменьшении рисунки искажаются
- рисунки занимают много места в памяти
Векторные -
представляют собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависти от прикладной среды.
Достоинства:
· нет потери информации
- при увеличении или уменьшении рисунки не искажаются
- рисунки занимают немного места в памяти
Недостатки:
- очень сложно (и не нужно) кодировать так изображения без четких границ объектов
- не подходит для кодирования и обработки фотографий.
Цветовые модели RGB(во всех устройствах), CMYK (в полиграфии)
На каждую точку в модели RGB отводится 3 байта.
Число цветов, воспроизводимых на экране монитора (N), и число бит, отводимых в видеопамяти на каждый пиксель (I), связаны формулой: 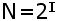
Величину I называют битовой глубиной или глубиной цвета. Чем больше битов используется, тем больше оттенков цветов можно получить.
1. Разрешение экрана- P
2. Глубина цвета (кол-во цветопередачи)-i
3. Объём видеопамяти –V V=P*i*k
Графические файлы(форматы)
§ BMP
§ GIF
§ JPEG
§ TIFF
§ PNG
· Пиксели бывают только трех цветов - зеленого, синего и красного. Другие цвета образовываются при помощи смешения цветов. Из трех цветов можно получить восемь комбинаций. Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.

