




В совокупности управляющие программы названы Supervisor – «надсмотрщик». К ядру операционной системы обычно относят следующие программы:
- образующие задачи;
- программы, управляющие ресурсами, допускающими их параллельное и последовательное использование;
- программы, организующие службу времени на базе машинного таймера;
- программы, осуществляющие анализ прерываний с целью определения вида обработки, необходимой для задачи;
- организующие загрузку и учет наличия и состояния программ, загруженных в оперативную память;
- программы учета и распределения оперативной памяти в динамической области (в области задач) и области системных очередей;
- программы инициирования и завершения процедур ввода-вывода, а также контролирования состояния средств ввода-вывода;
- программы, управляющие страничным обменом данных между внешней памятью на магнитных дисках и оперативной памятью;
- осуществляющие управление процессами и обменом с физическими устройствами, а также контроль использо-
вания ресурсов сети, при наличии сетевой части в операционной системе, и другие операции.
Чтобы обеспечить возможность работы нескольким процессорам с одной и той же операционной системой супервизорные программы, как говорят, должны обладать повторной входимостью, или, по-простому говоря, возможностью создания копий, без нарушения общей организации вычислительного процесса. Это и позволяет организовать независимость выполнения заданий каждым процессором.
Ниже приведен еще один пример процессора с более распространенным в литературе представлением архитектуры, - приведена на рисунке 5.2.
 |
Американской корпорацией Sun Microsystems, занимающейся разработкой больших машин, в последнее время разработано значительное число процессоров.
Niagara I, Niagara II – 65 нм технология, с обещаемой мощностью рассеивания в 130 Вт.
Наиболее известными процессорами этой фирмы стали процессоры Ultra SPARC T1 и Ultra SPARC 64. Аббревиатура названия процессора расшифровывается ангийским словосочетанием Scalalable Processor ARChitecture, означающим возможность наращивания архитектуры процессора (возможность масштабирования). Процессоры Ultra SPARC T1 рассеивают мощность в 72 Вт, поддерживают высокое число вычислительных потоков. Каждый процессор имеет кэш-память команд – 64 кб и данных – 16 кб. Общая кэш всех ядер – 3Мб. Разработчики обещают, что вероятным преемником процессоров SPARC станет процессор Rock также 65 нм технологии, но имеющий большее число ядер, чем у Ultra SPARC T1.
Имеется семейство процессоров Pebble и Boulder, а также процессор Cell, разработанных совместно фирмами Sony, Toshiba и IBM.
А теперь попробуйте мысленно сравнить схему этого процессора с классической схемой, представленной на рисунке 3.2.
Очень наглядной и выразительной является схема конвейера процессора SPARC T1, «привязанная» к его структурной схеме (см. рис. 5.1).
Конвейер 9-ти ступенчатый, затрачивающий 9 тактов на команду. Одновременно может выполняться до 9 команд (см. рис. 5.3).
 |
На схеме, рисунок 5.3, обозначены:
1 – блок выборки команд;
2 – декодер (дешифратор) команд;
B - буфер команд;
3 – устройство группировки и распределения команд по функциональным исполнительным устройствам процессора;
4 – устройство выполнения целочисленных операций, формирование виртуальных адресов обращения к памяти, окончательное декодирование команд для операций с плавающей точкой и обращение к регистрам с плавающей точкой;
5 – обращение к кэш-данным;
6 – функциональное устройство выполнения операций с плавающей точкой и графических операций;
7 – анализ возникших исключений;
8 – запись в регистровый файл;
9 – изъятие команд из обработки.
А теперь взгляните на рисунок 5.4, на котором представлена другая интерпретация того же самого конвейера и сравните его с рисунком 5.3. Раскраска (оттенки) цветов выбраны одинаково, именование блоков и их нумерация тоже одинаковы. А в чем заключается разница? В том, что рисунок 5.4 ближе привязывает конвейеры к структуре процессора, к его функциональным составляющим устройствам.
Давайте проследим работу конвейера.
Блок выборки и диспетчеризации – PDU (Prefetch and Dispatch Unit) – выбирает из внешнего кэша четыре и менее команды, помещает в I-кэш, где выполняется их частичная дешифрация с целью выявления команд перехода, а затем загружает в буфер команд. Максимальное количество команд в буфере достигает 12. Из буфера команд, по четыре за раз, они передаются в файловые регистры и операционные устройства, в которых и выполняются.
    |
В PDU реализована схема динамического прогнозирования направлений ветвей программы, основанная на 2-х битовой истории переходов, обеспечивающая ускоренную обработку команд условных переходов. Хранится информация о направлениях 2048 переходов. Схема эффективно работает при обработке программных циклов. С каждыми четырьмя командами связано поле, указы-
вающее строку кэш-памяти, которая должна выбираться вслед за данной. Такая схема, как отмечают авторы, обеспечила 188% переходов по условиям целочисленных операций и 94% переходов по условиям операций с плавающей точкой.
На третьей ступени конвейера блок логики группировки (блок G на рис.5.4) также выбирает группу из четырех или менее команд и направляет их в порядке следования в программе в блоки операционных устройств целочисленной группы операций и операций с плавающей запятой. Одновременно с этим, выполняется доступ к операндам целочисленных операций, помещенных в целочисленный регистровый файл. Таким образом, к концу такта ступени G одна или две целочисленные команды готовы к ступени выполнения, которая реализуется на ступени E (4 – Executive). На ступенях N1 и N2 никаких операций не выполняется, эти пропущенные такты обеспечивают задержку, необходимую для выравнивания с конвейером с плавающей запятой.
Доступ к операндам в регистровом файле с плавающей запятой выполняется на ступени R конвейера после пересылки команды в операционное устройство с плавающей запятой. Операции над ними (ступень 6) занимают до трех ступеней конвейера от X1 до X3.
На ступени N3 процессор анализирует различные условия исключений, чтобы выяснить, не требуется ли прерывание. Наконец, на ступени W (Write – запись) результаты выполнения команд сохраняются либо в регистрах, либо в кэше данных. В любой момент до этой ступени команда может быть снята с выполнения, а результаты работы аннулированы, но на этой ступени останов уже невозможен. На девятой ступени в процессоре уничтожаются «все следы» пребывания команды внутри процессора.
5.2.2 Многоядерные процессоры
Развитие компьютерных систем настоящего времени отмечено появлением действительно параллельных платформ на базе архитектур многоядерных процессоров. Такие компании, как Intel, IBM, Sun и AMD, представили микропроцессоры, имеющие несколько исполнительных ядер на одном кристалле. Что же это за «явление» многоядерный процессор? Ядро процессора представляет собой сочетание функциональных блоков, непосредственно участвующих в выполнении команд.
Комбинация транзисторов, реализующих какую-то логическую операцию, формирует логический блок, а набор логических блоков образует функциональный блок. Примерами функциональ-ных блоков в процессоре являются: арифметико-логическое уст-
ройство (АЛУ) – Arithmetic Logic Unit (ALU), блоки предварительной выборки команд из памяти, блоки управления и др. Они и
формируют микропроцессор или по-другому – центральное процессорное устройство (ЦПУ) – Central Processing Unit (CPU).
В случае многоядерных процессоров на кристалле находятся несколько ядер, но не процессоров. Схематически кристалл двухядерного процессора представлен на рисунке 5.5.
 Кристалл формируется в результате выполнения многочисленных технологических процессов на полупроводниковом материале (пластине) типа германия или кремния. В результате этих процессов и создаются функциональные блоки. После упаковки в корпус кристалл превращается в процессор (микропроцессор).
Кристалл формируется в результате выполнения многочисленных технологических процессов на полупроводниковом материале (пластине) типа германия или кремния. В результате этих процессов и создаются функциональные блоки. После упаковки в корпус кристалл превращается в процессор (микропроцессор).
На кристалле, как правило, в едином технологическом цикле создаются буферы быстродействующей памяти (кэши), обычно подразделяемые по уровням: L1, L2 и L3. Кэш L1 – самый маленький, а L3 – самый большой. А также: локальный программируемый контроллер прерываний (Advanced Programmable Interrupt Controller); интерфейсный блок, соединяющий процессор с системной шиной (находящейся вне процессора); массив регистров; исполнительные устройства (целочисленное АЛУ, блок операций с плавающей точкой); блоки организации переходов и др.
Каждое ядро процессора выполняет аппаратные потоки независимо, а общая память помогает поддерживать обмен между потоками. Количество ядер может различаться, но ядра остаются симметричными; поэтому вы видите появление новых процессоров с двумя, четырьмя, восемью и более ядрами.
Как несколько ядер обмениваются информацией и как эти ядра располагаются на кристалле? Соединение может быть шинное, кольцевое, матричное и т.д. Например, компания Intel выполняет соединения по схеме системной шины, поддерживая принципы функционирования, унаследованные от прежних времен. Ядро многоядерного процессора делает все то же, что и одноядерного, с учетом того, что у многоядерного процессора ядра должны работать согласованно.
Что происходит с приложением пользователя при использовании нескольких ядер? Чем больше ядер, тем большее количество потоков может использоваться. При этом программным обеспечением должна быть реализована какая-то методология синхронизации их работы. Необходимо понимать какие операционные системы поддерживают многоядерные процессоры и какие компиляторы (трансляторы программ на машинный язык) генерируют наилучший код для работы с таким количеством аппаратных потоков.
Чем отличается многопроцессорная система от многоядерной? Как было отмечено, многоядерный процессор – это несколько ядер в одном физическом процессоре, в то время как многопроцессорная система представляет собой несколько физических процессоров. Это означает, что многопроцессорная система может быть построена из нескольких многоядерных процессоров, установленных в нескольких сокетах (разъемах), а многоядерному процессору требуется один сокет.
5.3 Симметричные системы (SMP) - системы с общим полем памяти
Компания «Т-Платформы» выпускает симметричную вычислительную систему T – Edge SMP на базе 32-х четырехядерных процессоров 5300/E5479 Intel Xeon с производительностью 1,5 Tflops/s, ОЗУ – 1 Тбайт типа DDR2 – 667 в виде модулей с габаритными размерами 48,2 х 26,6 х 76,2 мм. (высота, ширина, длина) в стойке 6U. Накопитель на магнитном диске емкостью 16 Тбайт одновременно обслуживает 12 процессоров со скоростью передачи данных равной 35 Гбайт/с.
Система работает с операционными системами RedHat Interprise Linux, Fedora Core, SUSE Lim Enterprise Server или Open SUSE.
Фирмой Silicon Graphics разработаны компьютеры среднего класса CHALLENGE DM/L/XL коммерческого применения и POWER CHALLENGE L/XL – для обработки данных в форме с плавающей точкой на базе суперскалярных процессоров MIPS R8000 этой же фирмы. ОЗУ процессоров до 16 Гб – в 2 раза больше, чем у процессоров систем Cray T90/C90/J90, при 64-разрядной архитектуре. Отмечается бинарная совместимость для этой системы со всем семейством компьютеров SCI, включая рабочие станции Indy.
POWER CHALLENGE XLможет содержать от 1 до 18 процессоров, производительностью 0,36 – 6,5 Гфлопс, память RAM – 0,064 – 16 Гб, скорость обмена данными через ввод-вывод до 1,2 Гб/с. Объем дисковой памяти до 6,3 Гб.
POWER CHALLENGEarray содержит до 144 процессоров, RAM до 128 Гб, пиковая производительность до 51,8 Гфлопс. Скорость ввода-вывода – 4 Гб/с, емкость дисков до 63 Гб.
5.4 Семейство массивно-параллельных машин (MPP)
Системы этого семейства машин разрабатывались для решения прикладных задач таких направлений, как:
- решение задач аэродинамики летательных аппаратов, в том числе явлений интерференции при групповом движении;
- расчет трехмерных нестационарных течений вязкосжимаемого газа;
- расчет течений с локальными тепловыми неоднородностями в потке;
- разработка квантовой статистики моделей поведения вещества при экстремальных условиях. Расчет баз данных по уровням, - соблюден в широком диапазоне температур и плотностей;
- расчет структурообразования биологических макромолекул.
- моделирование динамики молекул и биомолекулярных систем;
- линейная дифференциация игр, динамических задач конфликтов управления;
- решение задач механики деформируемых твердых тел, в том числе процессов разрушения.
В качестве иллюстраций примеров систем данного типа мы выбрали массивно-параллельные вычислительные системы МВС-100 и МВС – 1000. Это отечественные мультипроцессорные системы. Программирование для систем предусмотрено на языках FORTRAN, С (С++). Имеются дополнительные средства описания параллельных процессов – программные средства PVM и MPI – общепринятые для систем параллельной обработки. Системы снабжены средствами реализации многопользовательского режима и удаленного доступа.
МВС-100 называют системой второго поколения, собранной на базе типовых конструктивных модулей, содержащих 32, 64 или 128 микропроцессоров Intel 860 с производительностью в 100 Мфлоп/с. Для получения результатов вычислений двойной точности используются 64-разрядные слова. Объем ОЗУ -8-32 Мб. С внешними устройствами связь реализуется транспьютером (см. далее) с общей пропускной способностью по четырем каналам 20 Мбит/с.
Многопроцессорная вычислительная система МВС-1000. Система 3-го поколения, созданная на базе RISK-процессоров Alpha 21164 фирмы DEC – Compag (выпускаются также фирмами Intel и Samsung) с производительностью 2,4 Tflops (2,4 миллиарда операций в секунду). ОЗУ – 0,1 –2 Гбайтов. Процессоры располагаются в стойке с размерами: 550 х 650 х 2200 мм (ширина, глуби-
 на, высота), оборудованной блоками питания и вентиляторами, весом 220 кГ. Всего имеется 8 стоек, содержащих 512 узлов. Узлы представляют собой блоки, содержащие по 32, 64 или 128 (см рис. 5.7 и 5.8) процессоров. Потребляемая системой мощность - до 4 кВт.
на, высота), оборудованной блоками питания и вентиляторами, весом 220 кГ. Всего имеется 8 стоек, содержащих 512 узлов. Узлы представляют собой блоки, содержащие по 32, 64 или 128 (см рис. 5.7 и 5.8) процессоров. Потребляемая системой мощность - до 4 кВт.
Подход к разработке системы – вероятно специфичный для современности – закупка новейших комплектующих и создание на их основе суперкомпьютеров, интегрируемых в вычислительные сети. Комплексы МВС –1000 эксплуатируются в Российской академии наук (РАН), в Москве, Екатеринбурге, Новосибирске, Владивостоке и в ряде отраслевых ВЦ. Система имеет программные и аппаратные средства распараллеливания вычислений и обрабатываемых данных для широкого перечня промышленных и научных направлений. В качестве примеров таких направлений можно назвать: аэродинамику, самолетостроение, создание реактивных двигателей, ядерную физику, управление динамическими системами распознавания изображений (образов) движущихся объектов, сейсмогеологоразведку, нефтедобычу, метеорологию, биосферу и т.д.
Основой системы является структурная решетка 4 х 4, состоящая из 16 вычислительных модулей – транспьютерных линков.
Под транспьютерным линком имеется ввиду оборудование в виде линий связи (проводов), специального микропроцессора (транспьютера) и программы, обеспечивающих взаимодействие между различными частями системы.
 Транспьютеры снабжены своей оперативной памятью (ОЗУ), памятью на жестком магнитном диске, емкостью 2-9 Гбайт и портами ввода-вывода.
Транспьютеры снабжены своей оперативной памятью (ОЗУ), памятью на жестком магнитном диске, емкостью 2-9 Гбайт и портами ввода-вывода.
Четыре угловых элемента соединяются по диагонали попарно (связи вделены жирными линиями). Оставшиеся 12 линков (модулей), предназначены для подсоединения внешних устройств: накопителей на магнитных дисках (НМД) и лентах (НМЛ), других устройств ввода-вывода. Максимальная длина пути в таком модуле равна 3, против 6 в исходной матрице 4 х 4. Для межпроцессорного обмена используется коммутационная сеть MYRINET (фирма Mirycom, США) с пропускной способностью канала в дуплексном режиме 2 х 160 Мб/с. В стандартной стойке располагаются до 64 процессоров системы МВС-1000 или 24 процессора системы МВС-1000К. Предусмотрена система объединения стоек.
На рис. 5.6 представлена топология базового блока системы МВС-1000.
Для управления массивом процессоров и внешними устройствами (ВУ), а также для доступа к системе извне используется хост-компьютер (управляющая машина). Обычно это рабочая станция Alpha Station с процессором Alpha и ОС Digital Unix (Tru 64 Unix) или персональный компьютер на базе процессоров Intel с ОС Linux.
Начиная с 1999 г., все вновь выпускаемые системы МВС-1000 строятся как кластеры выделенных рабочих станций. Это значит, что в качестве вычислительных модулей используются не специализированные ЭВМ, применяемые в качестве комплектующих су-
перкомпьютерной установки, а обычные персональные компьютеры «из магазина». В качестве коммуникационной аппаратуры ис-пользуются не специализированные «транспьютероподобные» процессоры, а обычные сетевые платы и коммутаторы, применяемые для, так называемых, офисных локальных сетей.
В качестве ОС используется Linux, что является общепринятым мировым стандартом для построения систем такого класса – большие и сверхбольшие системы МВС-1000М.
 |
На рисунке 5.8 приведена архитектура 64-процессорной системы МВС-1000. Здесь отчетливо выделяются массивы процессоров и параллельность этих массивов. Данные рисунки приведены, чтобы обратить внимание читателя на организацию связей между вычислительными модулями (процессорами) в блоке. «Свободные» связи (неподключенные стрелки) могут использоваться для под-
ключения периферийных устройств ввода-вывода или других сателитных устройств.
5.5 Суперкомпьютер СКИФ МГУ-«Ломоносов»
Было бы неправильно обойти вниманием еще одну архитектуру, в полной мере использующую технологию применения в вычислительных системах высокоскоростных вычислительных сетей. Технология применена в разработке самого высокопроизводительного суперкомпьютера России СКИФ МГУ – «Ломоносов». В нем все коммуникации между вычислительными узлами, системами управления передачей данных, системами хранения и архивирования данных реализованы на базе трех независимых высокоскоростных вычислительных сетей:
- системной сети - QDR InfiniBand (Quadrangle Data Rathe InfiniBand – высокоскоростная сеть передачи данных с помощью четырех скрученных жил проводов – множественная связка) с пропускной способностью 40 Гбит/сек;
- сервисной сети Ethernet с пропускной способностью: 10 Гбит/сек, 1 Гбит/сек и 100 Мбит/сек;
- управляющей сети – Ethernet с пропускной способностью: 10 Гбит/сек и 1 Гбит/сек.
Имеется еще и дополнительная сеть, обеспечивающая слежение (синхронизацию) и разрешение ситуаций, возникающих на пути распространения информации при посредстве использования передачи глобальных прерываний.
Первая сеть (представлена на рисунке 5.9) обеспечивает вычислительный процесс путем распределения и передачи команд программ между вычислительными узлами. Система имеет 5130 вычислительных узлов, собранных на базе трех типов многоядерных процессоров Intel Xeon 5570 Nehalem (4 ядра) – основной, «массовый» тип, Intel Xeon 5670 (6 ядер) и Power x Ctll 8i (8 ядер). Операционные блоки организованы в виде вычислительных узлов, собранных на печатных платах, названных T-Blade. На плате установлено по два процессора одного типа, оперативная память и другие устройства, необходимые при работе процессоров и для связи с другими вычислительными узлами. Вычислительные узлы (платы) устанавливаются на шасси, также являющимся печатной платой.
Коммутация всех вычислительных узлов обеспеивается 18 (восемнадцатью) многопортовыми коммутаторами типа Mellanox MTS 3610. Системная сеть обеспечивает в последовательном формате передачу информации со скоростью, как уже было указано, – 40 Гбит/сек, что и позволило достичь высокой реальной произво-
дительности на реальных тестовых программах – Linpack - 397 Тфлопс (397 х 1012 операций/сек). В составе компьютера СКИФ таких шасси порядка 86.
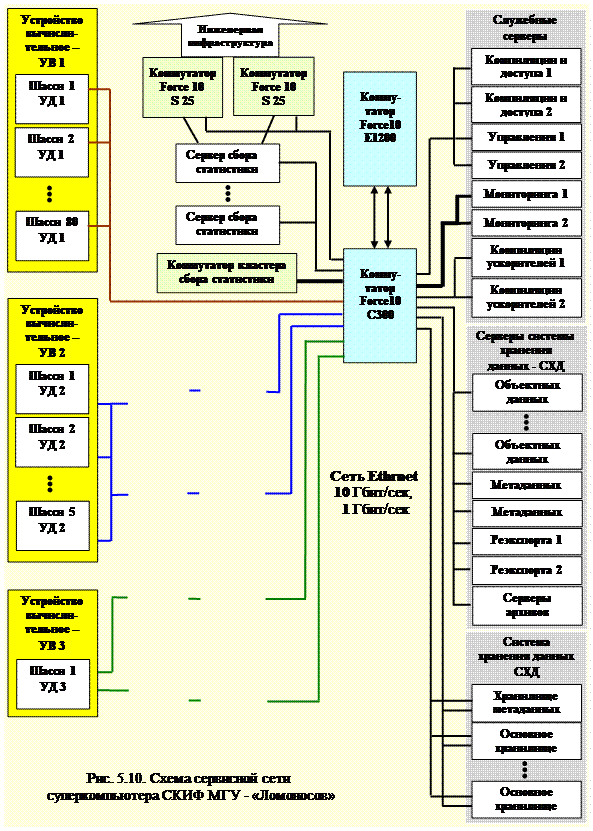
Сервисная сеть, рисунок 5.10, обеспечивает передачу и управление передачей, хранением и архивированием данных, пересылаемых по сети также в последовательном формате. Сеть является разделяемым ресурсом между всеми ее пользователями. Разделяемая среда представлена коммутатором типа Force 10 C300 и серверами, управляющими вычислительными узлами, обеспечивающими передачу данных между памятью, вычислителями, управляющими серверами и устройствами ввода-вывода. Различные сегменты сети имеют различную пропускную способность, от 100 Мбит/сек, до 10 Гбит/сек.
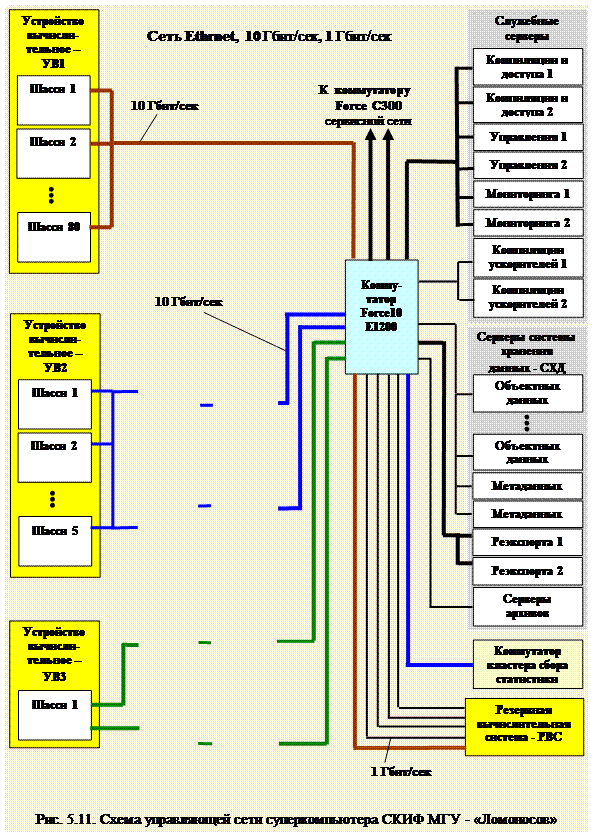
Третья, управляющая сеть, рисунок 5.11, обеспечивает передачу общей управляющей информации, синхронизирующей согласованную работу всех устройств системы. Архитектура этой сети, аналогично описанной выше сервисной сети, с той лишь разницей, что большинство сегментов сети, соединяющих управляющие структуры и вычислительные узлы, имеют высокую пропускную способность, скорось передачи управляющей информации, 10 Гбит/сек.
Рассматривая рисунки, можно сделать вывод о том, насколько сложной оказывается организация связей между всеми взаимодействующими узлами компьютера. Связи должны обеспечить передачу и распределение команд и данных между вычислительными узлами, синхронизацию обработки данных, мониторинг процесса обработки и функционирования компьютера в целом, доставку данных от устройств памяти и результатов к местам назначения или хранения, взаимодействие с многочисленными внешними устройствами и пользователями. Поэтому, даже слишком «облегченные» изображения схем связей дают представление о сложности их реализации.
Конструктивно, практически все типы больших машин, выполняются по следующей технологии. Активные элементы вычислительных систем – процессоры размещаются на печатных платах, подходящих размеров. Названия таким конструктивным сборкам с активными элементами (процессорами) разработчики придумывают самые различные, например, - вычислительный узел. Затем, такие платы-узлы устанавливаются на объединительную плату, которую, чаще всего, называют шасси. Шасси, таким образом, представляют собой некоторую завершенную конструкцию, обычно помещенную в металлическую коробку, являющуюся одновременно и корпусом и экраном.
Некоторое количество металлических коробок-шасси «упаковывают» в металлический каркас, закрытый сверху также металлическим кожухом (корпусом). Такую конструкцию называют
обычно модулем, конструктивное оформление которого показано на рисунке 5.12.



 И, наконец, модули, до 8 штук, встраивают в металлический
И, наконец, модули, до 8 штук, встраивают в металлический
шкаф, называемый компьютерной стойкой (высотой порядка 2 м). Полторы – две сотни стоек и составляют компьютер.







         |
Суперкомпьютер СКИФ МГУ, например, занимает общую площадь равную примерно 800 м2: вычислитель – 252 м2, система
бесперебойного питания – 246 м2, главный распределительный щит – 85 м2 и ситема обеспечения климата – 216 м2.
 Вы видите, что в компьютере имеются стойки самого различного назначения, в совокупности представляющие весьма внушительное сооружение, поражающее воображение обычного человека.
Вы видите, что в компьютере имеются стойки самого различного назначения, в совокупности представляющие весьма внушительное сооружение, поражающее воображение обычного человека.
Этот, можно сказать «компьютерный монстр», потребляет 3,05 Мвт электроэнергии, большая часть которой превращается в тепло, которое очень мешает работе и его надо отводить от системы.

 Все стойки компьютера (рисунок 5.13) охвачены (связаны) сетевыми соединениями, самые важные из которых представленые рисунками, обеспечивают успех реализации стратегической цели его изготовления.
Все стойки компьютера (рисунок 5.13) охвачены (связаны) сетевыми соединениями, самые важные из которых представленые рисунками, обеспечивают успех реализации стратегической цели его изготовления.

 В заключение этого раздела приведем еще несколько данных по следующим характеристикам:
В заключение этого раздела приведем еще несколько данных по следующим характеристикам:
- число процессоров / ядер – 10260 / 44000;
- оперативная память основного типа вычислительных узлов – 12 или 24 Мбайт, максимальная память вычислительного узла – 48 Гбайт;
- емкость оперативной памяти (ОЗУ) – 73920 Гбайт;
- общий объем дисковой памяти вычислителя – 166400 Гбайт;
- операционная система – Clustrx T-Platforms Edition;
- языки программирования: C / C++, FORTRAN 77/90/95.
Суперкомпьютер снабжен мощной системой хранения и архи-
вирования данных (см. рисунки 5.8, 5.9, 5,10) – ReadyStorage San 7998/Lustre, разработки организации T-Platforms.
Объем системы хранения данных обозначается внушительным числом – 1350 Тбайт и обеспечивает параллельный доступ всех вычислительных узлов к данным, устраняя, таким образом, узкие места традиционных сетевых хранидищ. Как отмечается разработчиками, система позволяет практически неограниченно наращивать объем хранилищ, не создавая дополнительных сложностей в ее управлении. При этом, за счет резервного копирования обеспечивается высокая отказоустойчивость, а вместе с этим и надежность всей системы.
 5.6 Гибридные технологии.
5.6 Гибридные технологии.
В качестве примера этой технологии мы выбрали компьютер кластерно-параллельной архитектуры. Вы поймете, почему выбрана эта структура.
Из общих сведений о 500 суперкомпьютерах, возглавляющих список (TOP500) самых мощных компьютеров мира, первым суперкомпьютером, преодолевшим на тесте Linpack рубеж производительности в 1 Pflop/s (петофлоп), стал - RoadRunner компании IBM. Начиная с 31 редакции (июнь 2008 г.) этот компьютер возглавляет список TOP500. Суперкомпьютер был создан для Министерства Энергетики США и установлен в Лос-Аламосской лаборатории (штат Нью-Мексико, США).

