




2.3.1 Пакетная и оперативная обработка данных
В пору машин второго и третьего поколений основными машинными носителями программ были перфокарты (картонные бланки). Программы набивались на перфокарты, образуя, так на-
зываемую, колоду. Колоды собирались в некоторую их совокупность – пакет (колода). При этом формировалась смесь задач таким обра-зом, чтобы обеспечить наиболее эффективное использование ресурсов системы. Задачи – колоды с программами в выбранном порядке через считывающие устройства компьютеров вводились в память машины. В то время это был основной режим решения задач, при котором пользователь вообще не имел общения с машиной. Программы, как правило, были отлажены и требовали минимального внимания со стороны персонала, следящего за процессом их выполнения. Таким образом, режим пакетной обработки данных оказался наиболее экономичным за счет эффективного использования ресурсов. Правда, время ответа оказывалось значительным – десятки минут или даже десятки часов.
Пакетная обработка характеризуется:
- большим объемом вводимых и выводимых данных и вычислений, приходящихся на одно взаимодействие с машиной (на одну задачу);
- низкой интенсивностью взаимодействия и допустимостью большого времени ответа.
Пакетная обработка была типична для вычислительных центров научно-технического профиля, систем обработки учетно-статистических данных, результатов геофизических измерений, расчетов, связанных с различными областями использования ядерной энергии, расчетами в космонавтике и т.д.
Оперативная обработка возникла тогда, когда пользователь получил тем или иным способом непосредственный доступ к машине. Этот вид обработки характеризуется:
- малым объемом вводимых - выводимых данных и вычислений, приходящихся на одно взаимодействие пользователя с системой (на одну задачу);
- высокой интенсивностью взаимодействия и вытекающим отсюда требованием уменьшения времени ответа.
Необходимость в оперативной обработке имеется в системах банковских расчетов, различного рода справочных систем, в системах резервирования транспортных билетов и многих других областях жизненной деятельности людей.
Выделяют два режима оперативной обработки: запрос-ответ и диалоговый. Типичным примером режима запрос-ответ является справочная служба на базе ЭВМ. Пользователь формирует запрос в виде вопроса, который передается в ЭВМ, и ждет ответа. Ответ может быть получен в течение нескольких секунд или в пределах минут.
Диалоговый режим предполагает очень кратковременный «личный» контакт пользователя с системой, при котором реакция системы на действия пользователя составляет доли секунды или несколько секунд. Например, система практически мгновенно
должна реагировать на нажатие клавиши клавиатуры – время ответа не должно превышать 0,1 секунды. Менее жестким будет ре-жим, когда реакция должна возникать по окончании набора строк. Быстрота реакции системы на действия пользователя является непременным требованием к ней при реализации диалогового режима.
Положительным свойством диалогового режима являются:
- возможность постоянного контроля пользователем за вводом программ и данных;
- возможность оперативного вмешательства в процесс решения задачи, в случае непредвиденного поведения программ;
- возможность оперативного доступа к системе.
Однако за любую услугу приходится расплачиваться. Этого обстоятельства «не избежал» и диалоговый режим. Для его реализации необходима аппаратура достаточно высокой производительности и большая, например, по сравнению с пакетным режимом, усложненность системного программного обеспечения. В итоге удорожается стоимость обработки единицы информации и всей обработки в целом.
2.3.2 Мультипрограммная обработка
Этот режим обработки стал возможен, когда появились аппаратное и программное обеспечения, позволяющие подключение к ЭВМ многочисленных пользователей. То есть пользователи смогли инициализировать (запускать) свои программы со своих рабочих мест. Этот режим обработки стал возможен, когда появились аппаратное и программное обеспечения, позволяющие подключение к ЭВМ многочисленных пользователей. То есть, пользователи смогли инициализировать свои программы со своих рабочих мест. Известно, что задача (программа) в каждый конкретный момент времени обрабатывается одним устройством машины, другие устройства простаивают до завершения текущей  операции и, следовательно, могут использоваться для обработки других программ. Создаются условия, при которых в системе обрабатывается сразу несколько программ одновременно, но разные программы обрабатываются разными устройствами, работающими параллель-
операции и, следовательно, могут использоваться для обработки других программ. Создаются условия, при которых в системе обрабатывается сразу несколько программ одновременно, но разные программы обрабатываются разными устройствами, работающими параллель-
но и независимо. Такой вид обработки назвали мультипрограммной обработкой, или, кратко, мультипрограммированием. По-другому, этот режим называют иногда мультизадачным. Цель использования такого режима - увеличение производительности и одновременно повышение эффективности использования ресурсов машины за счет распределения их между многочисленными пользователями.
Число задач, находящихся в вычислительной системе, называется уровнем мультипрограммирования, обозначаемым символом М. На рисунке 2.6 приведены функциональные зависимости: производительности, и времени ответа от уровня мультипрограммирования - λ=f(M) и U = f(M).
На графике, для упрощения представления, кривые зависимостей аппроксимированы ломаными линиями.
В однопрограммном режиме M = 1 и время ответа U = U1 = T отв (см. формулу). При этом производительность равна λ = λ 1 = 1/ U1. С увеличением числа задач, поступающих в систему (M), все большее число устройств становятся занятыми выполнением этих задач. Но в то же время вероятность одновременных обращений задач к одному и тому же ресурсу еще мала, и мало время ответа. Иногда может возникнуть ситуация, когда число задач M станет равным M * (M = M*), - это свидетельствует о том, что теперь, по крайней мере, хотя бы одно устройство оказывается полностью загруженным. Значение M * называется точкой насыщения мультипрограммной смеси или точкой насыщения системы. Дальней-шее увеличение числа задач не приводит к росту производительности λ, которая теперь принимает значение λ *. Значение M * может смещаться по графику вправо, что свидетельствует о большем числе ресурсов - устройств в системе. Но, значение M * может быть смещено и влево, если задачи используют преимущественно одно устройство и может принимать значение, равное единице. Работа системы при уровне мультипрограммирования равном M > M * неэффективна, так как нет выигрыша в производительности и велико время ответа.
Производительность оценивают по формуле Литтла, отражающей фундаментальный закон теории массового обслуживания:
 . (2.11)
. (2.11)
Существует зависимость, по которой можно определить среднее число задач, выполняемых одновременно в мультипрограммном режиме через загрузку  каждого из
каждого из  устройств системы:
устройств системы:
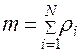 . (2.12)
. (2.12)
Величина m называется коэффициентом мультипрограммирования и характеризуется отношением производительности системы в мультипрограммном режиме  к производительности в однопрограммном режиме
к производительности в однопрограммном режиме  , если затраты ресурсов возрастают пропорционально числу одновременно выполняемых задач: m = λ / λ 1.
, если затраты ресурсов возрастают пропорционально числу одновременно выполняемых задач: m = λ / λ 1.
Разность M – m определяет число задач в системе, находящихся в состоянии ожидания выполнения. Из формулы (2.12) следует, что численное значение m находится в интервале 
 , где N - число устройств системы, способных функционировать с каждым из N – 1 остальных устройств.
, где N - число устройств системы, способных функционировать с каждым из N – 1 остальных устройств.
2.3.3 Обработка данных в реальном масштабе времени
Наступило время, когда ЭВМ начали использовать в системах управления реально действующих физических объектов. Процесс управления такими объектами характеризуется тем, что в нем используется фиксированный набор программ. Каждая программ работает либо периодически, либо по мере возникновения каких-то определенных ситуаций в системе. Время начала работы каждой программы, и получения результатов определяется технологическим процессом в устройствах управляемого объекта (системы), то есть подчиняется темпу вне системы обработки данных. Такой режим обработки данных назвали обработкой в реальном масштабе времени. Требования к ЭВМ таких систем сводится к ограничению времени ответа, которое не должно превышать некоторого предельно допустимого значения для данной системы, то есть  , где u 1, …, u M - время ответа, а
, где u 1, …, u M - время ответа, а  - предельно допустимое значение времени ответа для каждой из А1, …, АМ задач, соответственно.
- предельно допустимое значение времени ответа для каждой из А1, …, АМ задач, соответственно.
Обеспечить обработку данных в реальном масштабе времени можно:
- выбором структуры системы обработки данных, обеспечивающей решение задач, связанных с управляющей системой;
- организацией процессов обработки обеспечивающих требуемое время ответа от управляющей ЭВМ.
2.3.4 Режим телеобработки данных
Режим связан с удаленностью пользователей от ЭВМ и взаимодействием их с системой обработки через те или иные виды ли-ний связи. Это, во-первых, требует специальных действий пользо-
вателей при организации доступа к системе и завершению сеанса. Во-вторых, накладывает ограничения на форму и время обмена данными между пользователем и системой обработки данных, приводит к необходимости использования специальных способов организации данных и доступа к ним как со стороны пользователя, так и со стороны системы. Эти специфические особенности отражаются на структуре прикладных программ, эксплуатируемых в этом режиме. Пользователи в системах телеобработки могут работать в пакетном, диалоговом или «запрос-ответ» режимах. Каждый способ имеет свою специфику, не зная которую пользователь просто не сможет работать в такой системе.
2.3.5 Параллельная обработка данных
Обсуждение вопросов увеличения производительности систем обработки данных, непременно связывается с теми или иными способами их параллельной обработки. Параллельная обработка данных, это вероятно «столбовая дорога» к достижению целей, связанных с наивысшими значениями характеристики – производительности.
При этом выбирают одно из трех основных направлений:
- совмещение во времени различных этапов разных задач;
- одновременное решение различных задач или частей одной задачи;
- конвейерную обработку данных.
Совмещение во времени этапов решения различных задач, - это не что иное, как режим мультипрограммной обработки. Одна программа обрабатывается процессором, части других программ обрабатываются другими устройствами машины или внешними устройствами. Мы уже знаем, что такую обработку можно выполнять и на однопроцессорной машине, и это реализуется в наиболее массовом порядке.
Второе направление требует обязательного наличия нескольких обрабатывающих устройств – машин или процессоров. При этом в зависимости от особенностей задач, можно реализовать тот или иной тип (или вид) параллельной обработки. Выделяют несколько типов параллелизма:
- естественный параллелизм независимых задач;
- параллелизм независимых ветвей;
- параллелизм объектов или данных.
Естественный параллелизм заключается в том, что в вычислительный комплекс или в вычислительную систему поступает поток не связанных между собой задач, таких, решение которых не зависит от результатов решения других задач потока. При этом за счет параллельного (одновременного) решения нескольких задач
сразу явно проявляется эффект увеличения производительности обработки информации.
Суть параллелизма независимых ветвей заключается в том, что программу большой задачи можно разработать в виде отдельных независимых частей - ветвей программы. Эти ветви, при наличии нескольких обрабатывающих, допустим процессоров, могут обрабатываться параллельно и независимо друг от друга. Независимыми ветвями (частями программы) считают такие, для которых выполняются следующие условия:
- входные данные для любой ветви, не являются выходными результатами работы другой программы;
- данные различных ветвей не записываются в одни и те же ячейки памяти;
- условия выполнения одной ветви не зависят от результатов, полученных в другой ветви, если ветви находятся на одном уровне.
Рисунок 2.7 иллюстрирует принцип программы, организованной в виде совокупности ветвей, расположенных в нескольких уровнях (ярусах). Прокомментировать этот рисунок – граф можно следующим образом. Программа составлена из четырнадцати «кусков» - ветвей, номера которых указаны в кружках.
Ветви расположены в виде ярусов (уровней). Каждая ветвь – часть программы, выполняется за определенное время - t, представленное здесь цифрами, стоящими около кружков. Стрелками обозначены входные данные и выходные результаты обработки. Входные данные обозначены символом x, выходные результаты символом y. Символы x имеют только нижние индексы, означающие порядок и величины входных данных. Символы y имеют двой-ные индексы, из которых верхний указывает номер ветви, а нижний – порядковый номер результата. Символы y имеют двойные индексы, из которых верхний указывает номер ветви, а нижний – порядковый номер результата. Граф иллюстрирует, каким образом можно «отработать» программу, организовать процесс ее реализации и получить эффект сокращения времени решения, применив параллельную, с помощью двух процессоров обработку.
Нетрудно подсчитать, что при обычном последовательном способе решения задачи потребуется  = 375 единиц времени. Если решать ее двумя независимыми процессорами по указанной схеме, то видно, что задача разделяется на два потока, время решения в каждом потоке будет меньше времени последовательного решения и наибольшее из них и будет временем решения всей задачи. Меньшее время будет «поглощено» большим. В результате, части задачи, решаемые процессором 1, займут 135 единиц времени, а части задачи, решаемые вторым процессором – 245
= 375 единиц времени. Если решать ее двумя независимыми процессорами по указанной схеме, то видно, что задача разделяется на два потока, время решения в каждом потоке будет меньше времени последовательного решения и наибольшее из них и будет временем решения всей задачи. Меньшее время будет «поглощено» большим. В результате, части задачи, решаемые процессором 1, займут 135 единиц времени, а части задачи, решаемые вторым процессором – 245
единиц времени. Следовательно, в итоге будет затрачено времени в 1,5 раза меньше, чем при решении традиционным способом. Выигрыш во времени очевиден. Попробуйте, проверьте сами.
 |
Выигрыш во времени для различных последовательностей ветвей будет отличаться, но тенденция результата останется прежней. Сложность заключается в том, что не всегда известна, тем более точно, длина ветвей, порой трудно выделить параллельные ветви и некоторые другие. Вместе с тем только программирование с выделением параллельных ветвей позволяет существенно сократить время решения задачи. Хорошо поддаются параллельной об-
работке задачи матричной алгебры, спектральной обработке сигналов, преобразования Фурье и др.
Параллелизм объектов или данных. Такой режим реализуется, когда однотипные данные поступают от многочисленных объектов, расположенных в различных местах и обрабатываются по одной и той же программе. Например, данные поступают от температурных датчиков, установленных на однотипных объектах. Это могут быть данные радиолокационных измерений, также обрабатываемые по одной программе. Это могут быть и математические задачи, например, операции над векторами и матрицами. Задача сводится к выполнению одинаковых операций над парами чисел. Все эти операции могут выполняться параллельно, независимо друг от друга несколькими обрабатывающими устройствами.
2.4 Классификация систем параллельной обработки
Процесс решения задачи представляет собой воздействие программы в виде последовательности команд на соответствующую последовательность данных. Последовательность команд программы можно представить в виде потока, аналогично можно интерпретировать и последовательность данных. Получается, что один поток воздействует (обрабатывает) другой поток. При другой организации параллельной обработки информации один поток команд может воздействовать на несколько потоков данных и наобо-рот. В связи с многообразием организаций систем параллельной обработки данных представляется естественным как-то их классифицировать. Что и было сделано.
Классификация вычислительных систем по указанным признакам получила название классификации Флина.
При классифицировании систем параллельной обработки данных оказалось полезным ввести понятие множественности команд и множественности данных. Под множеством надо понимать наличие нескольких последовательностей команд (программ или частей программ), находящихся одновременно в стадии выполнения, или последовательностей данных, подвергающихся обработке. Исходя из выше приведенных условий, все параллельные системы разбили на четыре больших класса:
- системы с одиночным потоком команд и одиночным потоком данных – ОКОД, - английская аббревиатура – SISD – Single Instruction Single Data;
- системы с множественным потоком команд и одиночным потоком данных – МКОД, - английская аббревиатура - MISD – Multiple Instruction Single Data;
- системы с одиночным потоком команд и множественным потоком данных – ОКМД, - английская аббревиатура - SIMD – Single Instruction Multiple Data;
- системы с множественным потоком команд и множественным потоком данных – МКМД, - английская аббревиатура - MIMD – Multiple Instruction Multiple Data;
Рассмотрим кратко особенности каждого класса.
 Системы ОКОД. Схематически такую систему можно представить так, как показано на рисунке 2.8. Системы этого класса – обычные однопроцессорные ЭВМ. Как мы уже обсуждали, в таких системах организация параллельной обработки заключается в совмещении во времени различных этапов разных задач, при одновременной обработке их разными устройствами. Например, одновременно работают печатающие устройства по нескольким каналам, вводятся данные с накопителей на магнитных дисках, работает процессор и т.д., и все это делается по различным программам.
Системы ОКОД. Схематически такую систему можно представить так, как показано на рисунке 2.8. Системы этого класса – обычные однопроцессорные ЭВМ. Как мы уже обсуждали, в таких системах организация параллельной обработки заключается в совмещении во времени различных этапов разных задач, при одновременной обработке их разными устройствами. Например, одновременно работают печатающие устройства по нескольким каналам, вводятся данные с накопителей на магнитных дисках, работает процессор и т.д., и все это делается по различным программам.
Конструирование оперативных запоминающих устройств (ОЗУ) в виде многомодульной структуры обеспечивает каждому модулю независимое функционирование и дает определенный, ощутимый эффект увеличения производительности. При этом уменьшается количество конфликтов при обращении к ОЗУ нескольких устройств ввода-вывода сразу.
Конфликты разрешаются так же путем введения приоритетов устройств, которые определяют очередность их обращений к ОЗУ. При возникновении очередей возможны простои оборудования.
Более всего простои отражаются на работе процессора, который может ожидать в очереди сколь угодно долго, в то время как, например, электромеханические устройства ждать долго не могут, ибо это приведет к недопустимо большим потерям времени, а в конечном итоге - производительности. Если во время не считать данные с магнитного диска, то придется потерять несколько мил-лисекунд (один оборот диска) до следующего момента, когда возможно будет считать информацию.
Конвейер команд также можно рассматривать как совмещение во времени работы нескольких устройств – блоков, выполняющих отдельные части операции.
 Если к этому еще добавить использование многомодульных ОЗУ можно добиться существенного увеличения производительности системы. При этом программы и данные можно разместить в разных модулях и совмещать во времени выборку команд и операндов. Кроме того, можно сократить время доступа к памяти, если применить способ чередования адресов (расслоение обращений) памяти – один модуль будет иметь четные адреса, другой нечетные и начало цикла памяти смещено на половину цикла. Если память содержит N модулей, то среднее время обращения к ней составит 1/ N-ю часть цикла памяти.
Если к этому еще добавить использование многомодульных ОЗУ можно добиться существенного увеличения производительности системы. При этом программы и данные можно разместить в разных модулях и совмещать во времени выборку команд и операндов. Кроме того, можно сократить время доступа к памяти, если применить способ чередования адресов (расслоение обращений) памяти – один модуль будет иметь четные адреса, другой нечетные и начало цикла памяти смещено на половину цикла. Если память содержит N модулей, то среднее время обращения к ней составит 1/ N-ю часть цикла памяти.
Системы класса МКОД. По определению такая система должна была бы выглядеть так, как представлено на рисунке 2.9, однако, не существует таких задач, в которых одна и та же последовательность данных обрабатывалась бы различными программа-ми. По этой причине на практике реализована система, представленная рисунком 2.10.
 Фактический, одиночный поток команд устройством управления разделяется на несколько потоков микрокоманд (микроопераций). Каждая из микроопераций реализуется специализированным, настроенным на выполнение именно данной микрооперации устройством.
Фактический, одиночный поток команд устройством управления разделяется на несколько потоков микрокоманд (микроопераций). Каждая из микроопераций реализуется специализированным, настроенным на выполнение именно данной микрооперации устройством.
Поток данных последовательно проходит через все или часть этих специализированных АЛУ. Именно такие системы называют конвейерными или системами с магистральной обработкой информации. Определяющим признаком таких систем является наличие конвейера арифметических или логических операций. Напомним, что такие системы максимально производительны для определенных типов задач, имеющих длинные последовательности (цепочки) однотипных операций при длинной последовательности данных (например, координаты, выдаваемые радиолокационной
станцией), то есть когда имеет место параллелизм объектов и данных.
 |
Системы класса ОКМД. Системы, относящиеся к этому классу также как и предыдущие, ориентированы на параллелизм объектов и данных. В таких системах по одной программе обрабатываются сразу несколько потоков данных, каждый из которых обрабатывается своим процессором, но работающим под общим управлением - по одной команде разные процессоры выполняют одну и ту же операцию над различными данными. Схематически такие системы можно иллюстрировать рисунком 2.11. В архитектуре систем, представленных на рисунке управление может быть реализовано и с помощью отдельной ЭВМ, имеющей свою память команд. Используются и другие виды параллельной обработки, например, с помощью матричных или ассоциативных систем.
 Системы класса МКМД. В вычислительных системах этого класса, обработка данных может быть организована либо на многомашинных комплексах, либо на многопроцессорных комплексах.
Системы класса МКМД. В вычислительных системах этого класса, обработка данных может быть организована либо на многомашинных комплексах, либо на многопроцессорных комплексах.
Такие комплексы можно построить и на базе отдельных ЭВМ со своей памятью команд и данных, со своей операционной системой, вообще со всеми особенностями им присущими (рисунок 1.1).
Объединенные в систему с помощью тех или иных видов связи вычислительные машины, наиболее приспособлены для решения потока независимых задач, но при этом существенно увеличивают производительность вычислительных работ за счет большего количества решаемых задач. Многопроцессорные системы (комплексы) повышают производительность при использовании всех видов параллелизма, но, наибольший эффект достигается на задачах, запрограммированных по типу параллелизма независимых ветвей.
Архитектура систем, показанная на рисунке 2.12, является наиболее универсальной в отношении решаемых задач. Программное обеспечение таких систем не ориентируется на решение определенного класса задач, и поэтому они строятся как универсальные вычислительные комплексы, имеющие наиболее широкое распространение.
В 70 – 80-х годах прошлого столетия, вычислительные центры организовывали обработку данных по приведенной архитектрурной схеме, стараясь обеспечить вычислительными мощностями как можно большее число пользователей, работающих в то время в режиме телеобработки данных.
2.5 Конвейерная обработка данных
Конвейерная обработка преследует цель повышения скорости выполнения команд, а точнее увеличение количества операций, выполняемых за секунду.
Конвейер представляет собой цепочку асинхронных процессов, в которой выходные данные одного процесса являются входными данными другого процесса. В ходе совершенствования процессоров машин первыми, естественно, появились конвейеры команд. Конвейер может быть реализован и в однопроцессорной системе, когда выполнение операции разделено на некоторое количество шагов - процессов, выполняемых в строгой последовательности отдельными операционными блоками.
 |
Например, процесс обработки команды разбит на четыре шага:
- выборка (Fetch) – чтение команды из оперативной памяти;
- декодирование (Decode) – декодирование (расшифровка) команды и выборка ее исходных операндов;
- выполнение (Execute) – выполнение заданной в команде операции;
- запись результатов (Write) – сохранение результатов выполнения команды в каком-либо регистре процессора или в оперативной памяти.
Аппаратная организация выполнения команды может быть структурно представлена рисунком 2.13. Процесс выполнения ко-манды управляется тактовым сигналом с такой частотой, при которой каждый шаг выполняется за один такт - представлен следующим рисунком 2.14.
Вкратце поясним, как работает такой конвейер. На первом такте команда I1 (Instruction) извлекается из оперативной памяти устройством выборки (F) и помещается в промежуточный буфер B1, необходимый для того, чтобы блок декодирования, выполнивший декодирование предыдущей команды, мог ее оттуда забрать для обработки.
На втором такте команда извлекается из буфера B1, декодируется и помещается в буфер B2. Информация в буфере B2 заменяется только после того, как будет выполнена последующая опе-рация. На этом же такте 2 устройством выборки извлекается из памяти вторая команда (I2) и помещается в буфер B1.
 |
На третьем такте блоком Е команда извлекается из буфера B2, выполняется и помещается в буфер B3. Одновременно из буфера B1 блок декодирования извлекает команду I2, декодирует ее и помещает в буфер B2, в то же время блок выборки выбирает команду I3 и помещает ее в буфер B1. На очередном четвертом такте блок W извлекает результат обработки первой команды и сохраняет его по целевому адресу, обрабатывающее устройство E выполняет вторую команду и перемещает результаты в буфер B3. Пока выполняется I2, декодируется команда I3 и выбирается команда I4 и т.д. В результате все блоки заняты, а скорость выполнения команд в четыре раза больше, чем при последовательной обработке. Вы видите, что, начиная с четвертого такта, вся команда выполняется за один такт, то есть происходит совмещение во времени выполнения k этапов, на которые разбито выполнение команды.
Следует отметить, что описанный порядок поддерживать не удается, так как возникают конфликты – задержки в работе кон-вейера по причинам промахов при выборке команд из кэш-памяти, при выборке команд из оперативной памяти, при отсутствии данных, над которыми должна выполняться очередная операция и наличия в программах условных переходов. При возникновении условного перехода, программа переходит не к выполнению очередной команды, а совершенно другой, по выработанному в предыдущей команде признаку. В современных ЭВМ применяются различные приемы, позволяющие предсказать возможность перехода как можно раньше, однако совсем исключить влияние условных пере-ходов не удается. Тем не менее, для определенных задач, в программах которых имеются «ощутимые» последовательности без- условных переходов, выигрыш в производительности конвейерного процессора команд получается значительным.
Конвейеры операций или данных представляют собой последовательности операционных блоков, каждый из которых выполняет строго определенную часть операции. Например, операцию сложения элементов матриц, представленных числами с плавающей точкой, можно разделить на четыре последовательно выполняемых этапа:
- сравнение порядков - СП;

