




Аннотация
Данный документ является методическим пособием по курсу «SQL. Выборка данных». В нем рассматривается основные понятия о СУБД, реляционных базах данных, SQL и его стандартах.
Методический материал ориентирован на сотрудников, ранее не работавших с SQL. Приводится значительное количество примеров для закрепления практического навыка написания запросов.
Содержание
Введение. 3
Реляционная модель данных. 3
Structured Query Language. 5
SQL и его стандарты.. 5
Построение SQL-запроса. 5
Имена. 6
Имена таблиц. 7
Имена столбцов. 7
Типы данных SQL. 7
Оператор SELECT. 12
Простая выборка данных. 13
Выборка данных с использованием WHERE. 14
Неопределенное значение (NULL-значения) 16
Использование агрегатных функций в запросе. 17
Группировка результатов запроса с помощью GROUP BY. 18
Упорядочивание результатов запроса с помощью ORDER BY. 19
Создание запроса по нескольким таблицам. 20
Использование псевдонимов. 21
Вставка одного подзапроса внутрь другого. 22
Объединение результатов выборки UNION.. 24
Индексация таблиц. 25
Требования на SQL-запросы к базе данных 5NT. 25
Введение
Современные авторы часто употребляют термины «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД:
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистемы складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Реляционная модель данных
Реляционные базы данных – базы данных, основанные на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение). Для работы с реляционными БД используют Реляционные СУБД.
Теория реляционных баз данных была разработана доктором Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц, которые, как правило, связаны друг с другом, откуда и произошло название реляционные. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
· Данные хранятся в таблицах, состоящих из столбцов и строк;
· На пересечении каждого столбца и строчки стоит в точности одно значение;
· У каждого столбца есть своё имя, которое служит его названием, и все значения в одном столбце имеют один тип.
· Столбцы располагаются в определённом порядке, который определяется при создании таблицы, в отличие от строк, которые располагаются в произвольном порядке. В таблице может не быть ни одной строчки, но обязательно должен быть хотя бы один столбец;
· Запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов.
· Строки в реляционной базе данных неупорядочены - упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных является язык SQL.
| |||
| |||
| Номер клиента | Наименование |
| ООО «Фирма» | |
| ОАО «Промысел» | |
| … | … |
| Номер счета | Счет | Клиент |
| 40702810………8657 | ||
| 40702810………3325 |  1 1
| |
| 40702840………4546 |   2 2
| |
| 40702810………4424 | ||
| … | … | … |
Рис. 1. Организация данных в реляционной БД
Рассмотрим пример (рис. 1). В данном примере в базе данных существует две таблицы: «Счета» и «Клиенты». В каждой из них содержаться соответствующие данные. Допустим, была поставлена задача – определить, какие счета принадлежат определенной фирме, либо какой фирме принадлежит данный счет. Для решения подобной задачи понадобится больше, чем просто наличие таблиц, а именно – необходимо знать о связях между ними. На рисунке стрелочками указано, каким клиентам, какие счета принадлежат. Связи в реляционной базе данных организуются следующим образом.
В правильно построенной реляционной базе данных в каждой таблице есть один или несколько столбцов, который однозначно идентифицирует запись. Этот столбец (столбцы) называется первичным ключом таблицы. Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. На рисунке данными столбцами являются «Номер клиента» и «Номер счета» соответствующих таблиц. Данный номер никогда не повториться, так как он с каждой записью увеличивается на 1. Располагая значением первичного ключа таблицы, можно найти в ней любую запись.
В таблицах базы данных системы 5NT(e) первичные ключи являются числовыми. Обычно – это первое поле используемой таблицы, название которого заканчивается на ID, например, InstitutionID в таблице tInstitution («Справочник финансовых институтов»).
Столбец одной таблицы, который содержит значения первичного ключа той таблицы, на которую он ссылается, называется внешним ключом. На рис. 1 столбец «Клиент» таблицы «Счета» представляет собой внешний ключ для таблицы «Счета». Значения, содержащиеся в этом столбце, представляют собой идентификаторы клиентов. Эти значения соответствуют значениям в столбце «Номер клиента», который является первичным ключом таблицы «Клиенты».
Внешний ключ, как и первичный, тоже может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Наличие правил Кода, учитываемых при проектировании реляционных баз данных, позволило софтверным компаниям разрабатывать свои реляционные СУБД. В результате, в настоящий момент на рынке реляционных СУБД существуют продукты от разных производителей. Наиболее используемыми являются СУБД компаний Oracle, Microsoft, Sybase, Informix, IBM, Borland.
Structured Query Language
SQL и его стандарты
SQL (Structured Query Language) — Структурированный Язык Запросов — стандартный язык запросов по работе с реляционными БД. Язык SQL появился после реляционной алгебры, и его прототип был разработан в конце 70-х годов в компании IBM Research. Он был реализован в первом прототипе реляционной СУБД фирмы IBM System R. В дальнейшем этот язык применялся во многих коммерческих СУБД и в силу своего широкого распространения постепенно стал стандартом «де-факто» для языков манипулирования данными в реляционных СУБД.
Первый международный стандарт языка SQL был принят в 1989 г. (далее – SQL/89 или SQL1). Иногда стандарт SQL1 также называют стандартом ANSI/ISO, и подавляющее большинство доступных на рынке СУБД поддерживают этот стандарт полностью. Однако развитие информационных технологий, связанных с базами данных, и необходимость реализации переносимых приложений потребовали в скором времени доработки и расширения первого стандарта SQL.
В конце 1992 г. был принят новый международный стандарт языка SQL, который в дальнейшим будем называть SQL/92 или SQL2. И он не лишен недостатков, но в то же время является существенно более точным и полным, чем SQL/89. В настоящий момент большинство производителей СУБД внесли изменения в свои продукты так, чтобы они в большей степени удовлетворяли стандарту SQL2.
В 1999 году появился новый стандарт, названный SQL3. Если отличия между стандартами SQL1 и SQL2 во многом были количественными, то стандарт SQL3 соответствует качественным серьезным преобразованиям. SQL3 характеризуется как "объектно-ориентированный SQL" и является основой нескольких объектно-реляционных систем управления базами данных. Для поставщиков СУБД стандарт — это путеводная звезда, которая гарантирует правильное направление работ. А вот эффективность реализации стандарта – это гарантия успеха.
Язык SQL нельзя в полной мере отнести к традиционным языкам программирования, он не содержит традиционные операторы, управляющие ходом выполнения программы, операторы описания типов и многое другое, он содержит только набор стандартных операторов доступа к данным, хранящимся в базе данных. Операторы SQL могут быть встроены в базовый язык программирования, которым может быть любой стандартный язык типа C++, PL, COBOL и т. д. Кроме того, операторы SQL могут выполняться непосредственно в интерактивном режиме.
Построение SQL-запроса
SQL-запрос – это совокупность команд SQL, которая передается серверу СУБД для выполнения. Результатом запроса может быть информация, которая выводится либо на экран монитора, либо в файл, либо на принтер и т. д. (рис. 2). Большинство современных СУБД поддерживают SQL стандарты, в том числе и набор команд, указанный в этих стандартах. В настоящее время наиболее используемым стандартом в СУБД является стандарт ANSI SQL92.
СУБД выполняет SQL команды в том порядке, в котором они написаны в SQL-запросе. Запрос может выполняться, как из приложения, поставляемого в комплекте с СУБД (например, Query Analyzer для MS SQL Server), так и из приложений сторонних производителей, подключенных к данной СУБД (например, Toad, DBArtisan и др.).
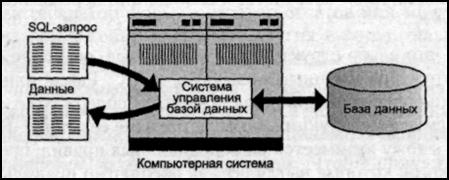
Рис. 2. Получение данных с использованием SQL-запроса
Каждая из команд выполняет в СУБД определенное действие, например, извлечь данные, создать таблицу или добавить в таблицу новые данные. Все команды SQL имеют одинаковую структуру, которая изображена на рис. 3.

Рис. 3. Структура SQL команды
Имена
У каждого объекта в базе данных есть уникальное имя. Имена используются в инструкциях(командах) SQL и указывают, над каким объектом базы данных инструкция должна выполнить действие. В стандарте SQL92 максимальное число символов в имени –128 символов латинского алфавита. На практике поддержка имен в различных СУБД реализована по-разному. В DB2, к примеру, имена пользователей не могут превышать 8 символов, но имена таблиц и столбцов могут быть более длинными. Зачастую более строгие ограничения налагаются на имена, связанные с программным обеспечением вне базы данных (например, имена пользователей, которые могут соответствовать регистрационным именам, использующимся операционной системой), а менее строгие — на имена, относящиеся к самой базе данных. Кроме того, в различных СУБД существуют разные подходы к использованию в именах таблиц специальных символов. Поэтому для повышения переносимости лучше делать имена сравнительно короткими и избегать употребления в них специальных символов.
Имена таблиц
Если в инструкции указано имя таблицы, СУБД предполагает, что происходит обращение к одной из собственных таблиц пользователя, выполняющего эту инструкцию, например, пользователя diasoft. При обращении к таблицам, которые были созданы другими пользователями, в имени таблицы так же указывается имя пользователя-владельца таблицы, например, dbo.tResource – где dbo – пользователь базы данных с именем dbo.
Обычно таблицам присваиваются короткие, но информативные имена. В небольших базах данных, предназначенных для личного или группового использования, выбор имен зависит от разработчика базы данных. В более крупных, корпоративных базах данных могут существовать определенные корпоративные стандарты именования таблиц, позволяющие избежать конфликтов имен.
Имена столбцов
Если в инструкции задается имя столбца, СУБД сама определяет, в какой и указанных в этой же инструкции таблиц содержится данный столбец. Однако если в инструкцию требуется включить два столбца из различных таблиц, но с одинаковыми именами, необходимо указать полные имена столбцов, которые однозначно определяют их местонахождение. Полное имя столбца состоит из имени таблицы, содержащей столбец, и имени столбца {короткого имени), разделенных точкой. Например, полное имя столбца BRIEF (собственная часть номера) из таблицы tRESOURCE («План счетов») имеет следующий вид: tRESOURCE.BRIEF.
Если столбец находится в таблице, владельцем которой является другой пользователь, то в полном имени столбца следует указывать полное имя таблицы. Например, полное имя столбца BIRTH_DATE в таблице BIRTHDAYS, владельцем которой является пользователь SAM, имеет следующий вид: SAM.BIRTHDAYS.BIRTH_DATE
Типы данных SQL
Современные СУБД позволяют обрабатывать данные самых разнообразных типов, среди которых наиболее распространенными являются:
Целые числа. В столбцах, имеющих этот тип данных, обычно хранятся данные о ценах, количестве, возрасте сотрудников и т. д. Целочисленные столбцы часто используются также для хранения идентификаторов, таких как идентификатор клиента, служащего или заказа.
Десятичные числа. В столбцах данного типа хранятся числа, имеющие дробную часть, но которые необходимо вычислять точно, например курсы валют и проценты. Кроме того, в таких столбцах часто хранятся денежные величины.
Числа с плавающей запятой. Столбцы этого типа используются для хранения величин, которые можно вычислять приблизительно, например значения весов и расстояний. Числа с плавающей запятой могут представлять больший диапазон значений, чем десятичные числа, однако при вычислениях возможны погрешности округления.
Строки символов постоянной длины. В столбцах, имеющих этот тип данных, обычно хранятся имена людей и компаний, адреса и т. и.
Строки символов переменной длины. Столбцы этого типа позволяют хранить строки символов, длина которых изменяется в некотором диапазоне.
Денежные величины. Во многих СУБД поддерживается тип данных MONEY или CURRENCY, который обычно хранится в виде десятичного числа или числа с плавающей запятой. Наличие отдельного типа данных для представления денежных величин позволяет правильно форматировать их при выводе на экран.
Дата и время. Поддержка значений даты/времени также широко распространена в различных СУБД, хотя способы ее реализации довольно сильно отличаются друг от друга. Как правило, над значениями этого типа данных можно выполнять различные операции. Стандарт SQL2 включает определение типов данных DATE, TIME, TIMESTAMP и INTERVAL, а также поддержку часовых поясов и возможность указания точности представления времени (например, десятые или сотые доли секунды).
Булевы величины. Некоторые СУБД, например Informix Universal Server, явным образом поддерживают логические значения (TRUE или FALSE), а другие СУБД разрешают выполнять в инструкциях SQL логические операции (сравнение, логическое И/ИЛИ и др.) над данными.
Длинный текст. Многие СУБД поддерживают столбцы, в которых хранятся длинные текстовые строки (обычно длиной до 32000 или 65000 символов, а в некоторых случаях и больше). Это позволяет хранить в базе данных целые документы. Как правило, СУБД запрещает использовать эти столбцы в интерактивных запросах.
Неструктурированные потоки байтов. Современные СУБД позволяют хранить и извлекать неструктурированные потоки байтов переменной длины. Столбцы, имеющие этот тип данных, обычно используются для хранения графических и видеоизображений, исполняемых файлов и других неструктурированных данных. К примеру, тип данных IMAGE в MS SQL Server позволяет хранить потоки данных размером до 2 миллиардов байтов.
Нелатинские символы. В последнее время все больше поставщиков СУБД стали включать в свои продукты поддержку строк переменной и постоянной длины, содержащих символы азиатских и арабских алфавитов. Современные базы данных позволяют сохранять и извлекать такие символы (часто для и представления используется кодировку UNICODE), но степень поддержки их поиска и сортировки сильно отличается в различных СУБД.
Стандарт SQL92 поддерживаются следующие типы данных:
CHARACTER(n) или CHAR(n) – символьные строки постоянной длины в n символов. При задании данного типа под каждое значение всегда отводится n символов, и если реальное значение занимает менее чем n символов, то СУБД автоматически дополняет недостающие символы пробелами.
NUMERIC[(n,m)], DECIMAL[(n,m)] или DEC[(n,m)] – точные числа, здесь n – общее количество цифр в числе, m – количество цифр слева от десятичной точки.
INTEGER или INT – целые числа.
SMALLINT – целые числа меньшего диапазона.
Несмотря на то, что в стандарте SQL1 не определяется точно, что подразумевается под типом INT и SMALLINT (это отдано на откуп реализации), указано только соотношение между этими типами данных, в большинстве реализаций. Тип данных INTEGER соответствует целым числам, хранимым в четырех байтах, a SMALLINT — соответствует целым числам, хранимым в двух байтах. Выбор одного из этих типов определяется размером числа.
FLOAT[(n)] – числа большой точности, хранимые в форме с плавающей точкой. Здесь n – число байтов, резервируемое под хранение одного числа. Диапазон чисел определяется конкретной реализацией.
REAL – вещественный тип чисел, который соответствует числам с плавающей точкой, меньшей точности, чем FLOAT.
DOUBLE PRECISION – специфицирует тип данных с определенной в реализации точностью большей, чем определенная в реализации точность для REAL.
VARCHAR(n) – строки символов переменной длины.
NCHAR(n) – строки локализованных символов постоянной длины.
NCHAR VARYING(n) – строки локализованных символов переменной длины. I
ВIТ(n) – строка битов постоянной длины.
BIT VARYING(n) – строка битов переменной длины.
DATE – календарная дата.
TIMESTAMP(точность) – дата и время.
INTERVAL – временной интервал.
Большинство коммерческих СУБД поддерживают еще дополнительные типы данных, которые не специфицированы в стандарте. Так, например, практически все СУБД в том или ином виде поддерживают тип данных для представления неструктурированного текста большого объема. Этот тип аналогичен типу MEMO в настольных СУБД. Называются эти типы по-разному, например в ORACLE этот тип называется LONG, в DB2 - LONG VARCHAR, в SYBASE и MS SQL Server — TEXT.
Однако следует отметить, что специфика реализации отдельных типов данных серьезным образом влияет на результаты запросов к БД. Особенно это касается реализации типов данных DATE и TIMESTAMP – на разных платформах они могут работать по-разному, и одной из причин может быть различие в интерпретации типов данных.
При выполнении сравнений в операциях фильтрации могут использоваться константы заданных типов. В стандарте определены следующие константы.
Для числовых типов данных определены константы в виде последовательности цифр с необязательным заданием знака числа и десятичной точкой. То есть правильными будут константы:
314 -612.716 + 551.702
В числовых константах нельзя ставить символы разделения разрядов между цифрами, и не все диалекты SQL разрешают ставить перед числом знак плюс, так что лучше избегать этого.
Константы с плавающей запятой задаются, как и в большинстве языков программирования, путем задания мантиссы и порядка, разделенных символом Е, например:
2.9Е-4 -134.235Е7 0.54267Е18
Символ Е читается как «умножить на десять в степени», так что первая константа представляет число «2,9 умножить па десять в степени -4», или 0,00029.
Строковые константы должны быть заключены в одинарные кавычки:
'Крылов Ю.Д.' 'Санкт-Петербург'
Если необходимо включить в строковую константу одинарную кавычку, вместо нее следует поставить две одинарные кавычки. Таким образом, следующая константа:
'I can''t' представляет строку I can't.
В некоторых реализациях, например MS SQL Server и Informix, допустимы двойные кавычки в строковых константах:
"Москва" "New York"
Однако следует отметить, что использование двойных кавычек может вызвать дополнительные проблемы при переносе приложений на другую платформу, поэтому мы рекомендуем по возможности избегать такого представления символьных констант. В стандарте SQL2 имеется возможность определять строковые константы на основе различных национальных алфавитов (например, французского или немецкого) или пользовательских наборов символов. Но средства многоязыковой поддержки еще не в полной мере внедрены в ведущие СУБД.
Константы даты, времени и временного интервала в реляционных СУБД представляются в виде строковых констант. Форматы этих констант отличаются в различных СУБД. Кроме того, формат представления даты различен в разных странах:
Американский mm/dd/yyyy 5/19/2006 hh:mm am/pm 2:18 PM
Европейский dd.mm.yyyy 19.5.2006 hh.mm.ss 14.18.08
Японский yyyy-mm-dd 2006-5-19 hh:mm:ss 14:18:08
ISO yyyy-mm-dd 2006-5-19 hh.mm.ss 14.18.08
Формат значений типа TIMESTAMP yyyy-mm-dd-hhmm.ss.nnnnnn
Пример значения типа TIMESTAMP 2006-05-19-14.18.08.048632
В стандарте SQL2 определен формат констант даты и времени, совпадающий с форматом ISO, за исключением того, что в константах времени для разделения часов, минут и секунд используются двоеточия. Выбор формата осуществляется при инсталляции системы. В большинстве СУБД реализованы способы настройки форматов представления дат или специальные функции преобразования форматов дат, как сделано, например, в СУБД ORACLE. Приведем примеры констант в MS SQL Server:
March 15, 2006 Маг 15 2006 3/15/2006 3-15-06 2006 MAR 15
А вот примеры допустимых в этой СУБД констант времени:
15:30:25 3:30:25 РМ 3:30:25 рт 3 РМ
В СУБД ORACLE та же константа даты запишется как 15-MAR-06
В операторах SQL могут использоваться выражения, которые строятся по стандартным правилам применения знаков арифметических операций сложения (+), вычитания (-), умножения (*) и деления (/). Однако в ряде СУБД операция деления (/) интерпретируется как деление нацело, поэтому при построении сложных выражений вы можете получить результат, не соответствующий традиционной интерпретации выражения.
Кроме пользовательских констант, в SQL существуют специальные именованные константы, возвращающие значения, хранимые в самой СУБД. Например, значение константы CURRENT_DATE, реализованной в ряде СУБД, всегда равно текущей дате. В общем случае именованную константу можно применять в любом месте инструкции SQL, в котором разрешается применять обычную пользовательскую константу того же типа. В стандарт SQL2 вошли наиболее полезные именованные константы из СУБД, в частности константы CURRENT_DATE, CURREN_TIME, CURREN_TIMESTAMP, а также USER, SESSION_USER и SYSTEM_USER.
В системе 5NT(е) используются следующие основные типы данных:
· DSIDENTIFIER – базовый тип numeric(15,0) по умолчанию значение 0. Используется для первичного и внешнего ключей;
· DSCOMMENT – базовый тип varchar(255);
· DSACC_SWIFT – базовый тип char(35);
· DSVARFULLNAME40 – varchar(40) и т.д.
Оператор SELECT
На рис. 4 приведена синтаксическая диаграмма команды SELECT. Команда состоит из шести предложений. Предложения SELECT и FROM являются обязательными. Четыре остальных включаются в команду только при необходимости. Ниже перечислены функции каждого из предложений.
В предложении SELECT указывается список столбцов, которые должны быть возвращены командой SELECT. Возвращаемые столбцы могут содержать значения, извлекаемые из столбцов таблиц базы данных, или значения, вычисляемые во время выполнения запроса.
В предложении FROM указывается список таблиц, которые содержат элементы данных, извлекаемые запросом.
Предложение WHERE показывает, что в результаты запроса следует включать только некоторые строки. Для отбора строк, включаемых в результаты запроса, используется условие отбора.
Предложение GROUP BY позволяет создать итоговый запрос. Обычный запрос включает в результаты запроса по одной записи для каждой строки из таблицы. Итоговый запрос, напротив, вначале группирует строки базы данных по определенному признаку, а затем включает в результаты запроса одну итоговую строку для каждой группы.
Предложение HAVING показывает, что в результаты запроса следует включать только некоторые из групп, созданных с помощью предложения GROUP BY. В этом предложении, как и в предложении WHERE, для отбора включаемых групп используется условие отбора.
Предложение ORDER BY определяет упорядочивание (сортировку) записей. Если это предложение не указано, результаты запроса не будут отсортированы. Можно указывать только поля, фигурирующие в списке отобранных (в списке после ключевого слова SELECT ). Причем эти поля могут быть и вычисляемыми.

Рис. 4. Схема обработки команды SELECT интерпретатором СУБД
Далее будут рассмотрены варианты написания запроса с использованием команды SELECT и примеры.
Простая выборка данных
Для простой выборки данных из таблиц вариант записи оператора select выглядит следующим образом (данные запросы не рекомендуется использовать на рабочей базе данных банка, так как они могут отнять значительную часть ресурсов на обработку):
Select < какие столбцы выборки будут выводится >
From < какие таблицы используются для выборки данных >
Примеры:
1. Вывести все столбцы таблицы «Справочник финансовых институтов» (tInstitution).
Select *
From tInstitution
Символ * означает, что необходимо сделать выборку всех полей таблицы.
2. Вывести наименования клиентов, хранящихся в таблице «Справочник финансовых институтов» (tInstitution).
Select Name
From tInstitution
3. Вывести наименования клиентов, хранящихся в таблице «Справочник финансовых институтов» (tInstitution), исключив повторение.
После ключевого слова SELECT в оператор могут вставляться ключевые слова DISTINCT ( ОТЛИЧИЕ ) или ALL ( ВСЕ ). Первое из них означает, что в результирующий набор данных не включаются повторяющиеся записи. Повторяющимися считаются те записи, в которых совпадают значения полей, перечисленных в списке оператора SELECT. Ключевое слово ALL означает включение всех записей. Оно подразумевается по умолчанию, так что вставлять его в оператор не имеет смысла.
Select DISTINCT Name
From tInstitution
3. Вывести наименования клиентов, их фактические адреса и телефоны из таблицы «Справочник финансовых институтов» (tInstitution). Необходимо вывести все данные заданных столбцов.
Select Name, Address3, Phone1
From tInstitution
4. Вывести наименования клиентов, их фактические адреса и телефоны, переименовав при этом наименования столбцов результата выборки, из таблицы «Справочник финансовых институтов» (tInstitution). Необходимо вывести все данные заданных столбцов, при этом указав новые названия столбцов. Для этого используется служебное слово as после которого необходимо указать новое название столбца.
Select Name as Klient, Address3 as Address, Phone1 as Phone
From tInstitution
Выборка данных с использованием WHERE
Вывод всех данных из таблицы используется редко. В большинстве случаев выбираются определенные данные с использованием условия выборки. Данное условие позволяет ограничить набор данных выводимых на экран. Структура записи оператора select с использованием условия выглядит следующим образом:
Select < какие столбцы выборки будут выводится >
From < какие таблицы используются для выборки данных >
Where < какому условию должны соответствовать выводимые данные >
Для задания условия используются операторы сравнения:
= (равно),
<> (не равно),
< (меньше),
<= (меньше или равно),
> (больше),
>= (больше или равно)
При написании условий необходимо учитывать тип данных столбца, на который накладываются условия отбора данных.
В следующих примерах будет использоваться таблица tOperPart – «Проводки». В ней хранится вся необходимая информация о проводках. Основные поля таблицы приведены на рисунке 5.
tOperPart – «Проводки»
| Ключ | Наименование | Тип | Описание |
| ПК | OperationID | DSIDENTIFIER | Идентификатор полупроводки |
| ВК | ResorceID | DSIDENTIFIER | Идентификатор счета (tResource) |
| ВК | OperSetID | DSIDENTIFIER | Идентификации набора шаблонов генерации отчетов (tOperSet) |
| ВК | OperTypeID | DSIDENTIFIER | Идентификатор типа операции (tPropertyUsr) |
| ВК | BalanceID | DSIDENTIFIER | Идентификатор области учета (tResource) |
| OperDate | DSOPERDAY | Дата проводки | |
| QtyBs | DSBIGMONEY | Сумма проводки, приведенная к национальной валюте |
Примеры:
1. Вывести всю информацию по проводкам за 06.06.2006.
Select *
From tOperPart
Where OperDate = '20060606'
2. Вывести всю информацию по проводкам, сумма которых не более 5000 руб.
Select *
From tOperPart
Where QtyBs <= 5000
3. Вывести всю информацию по клиенту АКБ "НЕФТЕПРОМБАНК".
Select *
From tInstitution
Where Name = 'АКБ "НЕФТЕПРОМБАНК"'
При описании условий в большинстве случаев используются Булевы операторы. Выражения Буля - являются верными или неверными. Булевы операторы связывают одно или более верных/неверных значений и производят единственное верное/неверное значение. Стандартными операторами Буля распознаваемыми в SQL являются: AND, OR, и NOT:
· AND берет выражения (в форме A AND B) как аргументы и оценивает их по отношению к истине, верны ли они оба. Для выборки это означает, что получаемые данные должны соответствовать всем описанным условиям.
4. Вывести всю информацию по проводкам за 06.06.2006 и сумма которых не более 1000 руб.
Select *
From tOperPart
Where OperDate = '20060606'
and QtyBs <= 1000
· OR берет два выражения (в форме A OR B) как аргументы и оценивает на правильность, верен ли один из них. Для выборки это означает, что получаемые данные должны соответствовать хотя бы одному из заданных условий.
5. Вывести всю информацию по проводкам за 06.06.2006 или сумма которых не более 1000 руб.
Select *
From tOperPart
Where OperDate = '20060606'
or QtyBs <= 1000
· NOT берет выражение (в форме NOT A) как аргумент и заменяет его значение на противоположное – с неверного на верное или верное на неверное. Для выборки это означает, что получаемые данные будут соответствовать противоположному условию.
6. Вывести всю информацию по проводкам, сумма которых более 5000 руб.
Select *
From tOperPart
Where NOT QtyBs <= 5000
При описании условий можно так же воспользоваться специальными операторами:
Условие отбора данных можно так же задать с помощью множества. Заданное множество задается с помощью оператора IN (принадлежит), отбирает записи, в которых значение указанного поля является одним из элементов указанного множества.
<поле> in (<множество>)
7. Вывести всю информацию по проводкам за 06.06.2006, 08.06.2006, 09.06.2006.
Select *
From tOperPart
Where OperDate IN ('20060606', '20060608', '20060609')
Данное условие аналогично – Where OperDate = '20060606' or OperDate = '20060608' or OperDate = '20060609'
Можно задать и NOT IN (не принадлежит множеству).
Операция BETWEEN (между) ... AND... (находится в интервале от... до...) задает для указанного поля диапазон отбираемых значений.
<поле> between <значение> and <значение>
8. Вывести всю информацию по проводкам, сумма которых находится в интервале от 5000 руб. до 10000 руб.
Select *
From tOperPart
Where QtyBs BETWEEN 5000 AND 10000
Данное условие аналогично - Where QtyBs >= 5000 and QtyBs <= 10000
Можно задать и NOT BETWEEN (не принадлежит диапазону между).
В ситуациях, когда данные надо сравнить с некоторым прототипом, можно воспользоваться оператором LIKE (похоже на).
Обычная форма <поле> LIKE ‘<последовательность символов>’ для столбца текстового типа позволяет отыскать все значения указанного столбца, соответствующие образцу, заданному как <последовательность символов>. Символы этой константы интерпретируются следующим образом:
- символ _ (подчеркивание) – заменяет любой одиночный символ;
- символ % (процент) – любое количество любых символов;
- все другие символы означают просто сами себя.
9. Вывести всю информацию о коммерческих банках, наименование которых начинается с буква «А».
Select *
From tInstitution
Where Name like 'АКБ "А%'
Неопределенное значение (NULL-значения)
Если при загрузке данных не введено значение в какое-либо поле таблицы, то СУБД может поместить в него NULL-значение. Данный факт обозначает, что значение в ячейке таблицы не задано. Аналогичное значение можно ввести в поле таблицы, выполняя операцию изменения данных, тогда там будет храниться код NULL-значения, а не 0, 0. или пробел. (Отметим, что в распечатке таблицы в этих местах расположен пробел, установленный в СУБД для представления NULL-значения при выводе на печать). Для сравнения данных с NULL следует использовать
<столбец> IS NULL или <столбец> IS NOT NULL
вместо, например,
<столбец> = NULL и <столбец> <> NULL
связано с тем, что синтаксис в первом случае – стандарт SQL92, который обязан поддерживаться всеми производителями СУБД, а поддержка синтаксиса во втором – отдана на откуп производителям. По стандарту SQL92 ничто - и даже само NULL-значение - не считается равным другому NULL-значению, хотя некоторые СУБД можно настроить на возможность сравнения этих значений (несмотря на это, два неопределенных значения рассматриваются, однако, как дубликаты друг друга при исключении дубликатов, и предложение SELECT DISTINCT даст в результате не более одного NULL-значения.) В разных СУБД существуют различные функции для обработки результата, содержащего значения NULL.

