




Между производителями МП идет острая конкурентная борьба, особенно обострившаяся в связи с тем, что большое количество транзисторов в этих микропроцессорах позволяет исчерпывающе реализовать в них структурно-функциональные решения, характерные для векторно-конвейерных супер-ЭВМ с одним потоком команд, для мощных рабочих станций и больших ЭВМ с многокристальными процессорами. Это коснулось организации мультипрограммных режимов работы под операционными системами типа UNIX и средств ввода, обработки и отображения мультимедийных данных.
В настоящее время в семействе процессоров с архитектурой х86 есть процессоры с ММХ расширением системы команд для мультимедийных приложений. Для аналогичных целей введены расширения системы команд микропроцессоров с архитектурой SPARC и Alpha.
Фактически все, что может изобрести инженерная мысль в рамках однопроцессорного подхода, может быть сделано в одной БИС. В этом смысле термины «процессор» и «микропроцессор» стали синонимами. Поэтому одни и те же микропроцессоры используются в персональных ЭВМ, рабочих станциях и супер-ЭВМ. В двух последних случаях доминируют симметричные мультипроцессоры и вычислительные системы с массовым параллелизмом.
Исторически микропроцессоры с архитектурой х86 доминировали в персональных ЭВМ, а RISC-процессоры в совокупности с графическими процессорами и умощненными системами ввода/вывода образовывали процессоры рабочих станций. В настоящее время процессоры с архитектурой х86 продвинулись на рынок рабочих станций, и некоторые производители рабочих станций, такие, как SUN, DEC, пытаются выйти со своими процессорами на рынок персональных ЭВМ [4-7].
В рамках Ускоренной стратегической компьютерной инициативы (ASCI) в США реализуются проекты построения суперкомпьютеров с производительностью на уровне 10 триллионов оп./с. на базе микропроцессоров Pentium Pro, Power PC, Alpha, R-10000 [4-7].
Конечно, субъективно можно выражать сожаление по поводу ограничений, накладываемых элементной базой на изощренность архитектурно-структурных построений супер-ЭВМ, но стоимость разработки и изготовления сверхбольших интегральных схем такова, что при создании конкурентоспособных систем надо обходиться малым числом типов БИС большой тиражности. И даже программируемые логические схемы, как альтернатива жесткой логике микропроцессоров, ничего не изменят в силу ограничений по числу выводов БИС.
На сегодняшний день основные производители микропроцессоров обладают примерно равными технологическими возможностями, поэтому в «борьбе за скорость» на первое место выходит фактор архитектуры. Архитектура микропроцессоров развивается в настоящее время по двум магистральным направлениям. В рамках каждого направления в той или иной степени используются ранее рассмотренные архитектурные приемы повышения производительности, но имеются и собственные приоритеты. Первое направление получило условное название Speed Daemon. Оно характеризуется стремлением к достижению высокой производительности главным образом за счет высокой тактовой частоты. Второе направление -Brainiac - связано с достижением высокой производительности за счет усложнения логики планирования вычислений и внутренней структуры процессора. Каждое из направлений имеет собственных противников и сторонников и, по-видимому, право на существование.
В настоящее время на рынке присутствуют следующие высокопроизводительные универсальные микропроцессоры [4-7]:
· Архитектура х86
- Компания Intel: линия Pentium (Р5, Р6, P-II, Celeron, P-III и т.д.);
- Компания AMD (NexGen): К5, К6, K6-II; K7-К10;
- Компания Cyrix: M1, М2.
· Архитектура Power PC
- Компании IBM, Motorola: Power PC 603, 604, 620, 750, G3, G4.
· Архитектура PA
- Компания HP: PA-8000, 8200, 8500.
· Архитектура Alpha
- Компания DEC: линия Alpha (21064, 21164, 21164A, 21264, 21364).
· Архитектура SPARC
- Компания SUN: линия SPARC.
· Архитектура MIPS
-Компания Silicon Graphics: линия MIPS R-x (R10000, R12000).
Каждое поколение этих микропроцессоров в чем-то развивает архитектурные решения, характерные для суперскалярных процессоров и VLIW-процессоров.
Микропроцессор Pentium. Семейство микропроцессоров Pentium [38, 39] включает в себя высокопроизводительные процессоры Intel, работающие на тактовых частотах от 60 до 1000 МГц. Процессор Pentium полностью программно совместим с предыдущими микропроцессорами Intel и позволяет применять ранее разработанное программное обеспечение для персональных компьютеров.
Первые представители семейства Pentium [5, 7, 8], работавшие на частотах 60 и 66 МГц, изготовлялись по технологии БиКМОП 0,8 микрон с напряжением 5 вольт и содержали 3,1 млн. транзисторов, а процессоры, представители более позднего поколения - Pentium 90 и 100 МГц – используют технологию БиКМОП 0,6 микрон с напряжением 3,3 вольта и содержат 3,3 млн. транзисторов. Начиная с Pentium 120 МГц используется технология КМОП 0,35 микрон, и напряжение питания снижено до 2,8 В.
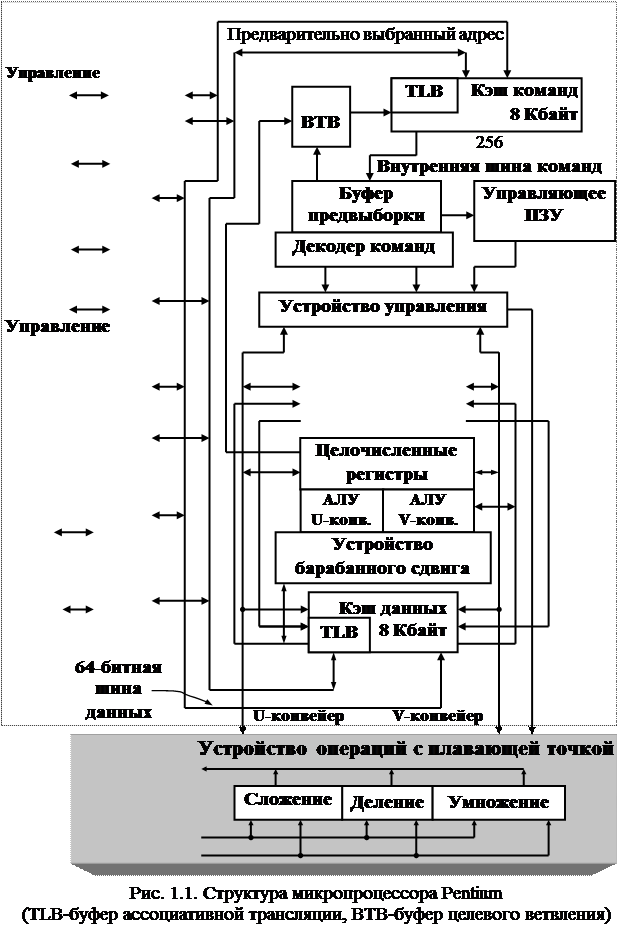
В отличие от предыдущих микропроцессоров с системой команд х86, процессоры семейства Pentium (рис. 1.1) обладают целым рядом технических новшеств, к числу которых относятся:
· близкая к суперскалярной архитектура;
· раздельные кэш-памяти для команд и данных;
· предсказание переходов;
· высокопроизводительные операции с плавающей точкой;
· усовершенствованная 64-разрядная шина данных;
· средства обеспечения целостности данных;
· SL-технология со средствами управления энергопотреблением;
· поддержка многопроцессорности;
· мониторинг производительности;
· поддержка различных размеров страницы памяти.
Суперскалярная архитектура. Суперскалярная реализация процессора Pentium - это естественное развитие предыдущих поколений процессоров Intel с 32-разрядной архитектурой (выполнять несколько команд за один такт мог уже процессор Intel 486).
Два конвейера процессора Pentium могут выполнять две команды одновременно. Как и в случае единственного конвейера процессора Intel 486, двойной конвейер процессора Pentium выполняет целочисленные команды в 5 этапов [5]:
1) предвыборка команд (PF - Prefetch);
2) декодирование команд (D1-Instruction Decode);
      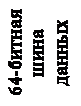       |
3) формирование адреса (D2-Address Generate);
4) выполнение команды в АЛУ и доступ к кэш-памяти (EX-Execute);
5) обратная запись результатов (WB-Write Back)
При этом несколько команд могут находиться на разных этапах выполнения.
Однако два конвейера не являются независимыми. При остановке одного останавливается и другой. Блок арифметики с плавающей точкой использует блок арифметики с фиксированной точкой. Следовательно, эти операции не могут выполняться параллельно. Это ограничивает суперскалярность процессора.
В процессоре Pentium многие команды микрокода, применяемые в предыдущих поколениях микропроцессоров, заменены внутренними командами. Это часто используемые и простые команды, которые микропроцессор может выполнять, не прибегая к микрокоду. Что касается более сложных команд, то усовершенствованный микрокод процессора Pentium увеличивает производительность, применяя для выполнения команд два целочисленных конвейера.
Раздельные кэш-памяти команд и данных. Каждая кэш-память процессора Pentium имеет размер 8 Кбайт. Кэш-памяти являются частично-ассоциативными. Поиск требуемой информации выполняется в стандартных 32-байтовых строках.
Буфер трансляции адресов (TLB) преобразует адрес ячейки внешней памяти в соответствующий адрес данных в кэш-памяти.
Кэш данных процессора Pentium использует метод «обратной записи» (write-back) и протокол MESI (Midified, Exclusive, Shared, Invalid). Метод обратной записи позволяет модифицировать данные в кэше без обращения к оперативной памяти.
Поддержка в процессоре Pentium протокола MESI позволяет обеспечивать согласованность данных в кэшах процессоров и в основной памяти при работе в мультипроцессорном режиме.
Микропроцессор Pentium MMX [5,7,8]. Концепция NSP - естественной обработки сигналов, выдвинутая в 1995 году компанией Intel, - возлагает на микропроцессор ряд задач, ранее выполняемых отдельными специализированными устройствами, и тем самым упрощает конструкцию компьютера и удешевляет его производство. К числу этих задач относятся синтез звука и музыки, распознавание речи, обработка видео- и графической информации, выполнение коммуникационных функций и многое другое. Однако количество разнообразных приложений, выполнение которых должно быть возложено на процессор в соответствии с последовательным соблюдением принципов NSP, существенно превысило вычислительные возможности далекой от совершенства архитектуры семейства х86 и потребовало внесения в нее соответствующих изменений. Результатом воплощения концепции NSP в «металле» явился выпущенный в январе 1997г. микропроцессор Pentium MMX (кодовое обозначение Р55С), система команд которого расширена 57 дополнительными командами, ориентированными на эффективное выполнение типичных мультимедийных алгоритмов, к числу которых относятся и многие алгоритмы, характерные для цифровой обработки сигналов (операции над векторами, свертка, преобразование Фурье и т.п.). Это первое существенное изменение в системе команд микропроцессоров семейства х86, начиная с выхода в свет микропроцессора lntel80386 в 1985 году, имевшего 220 команд.
  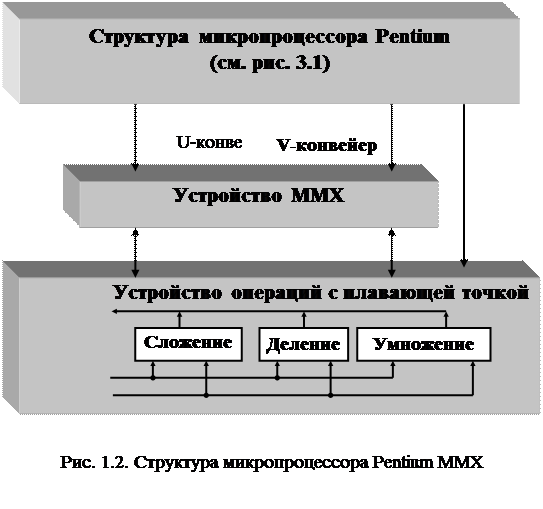 |
Процессор Pentium MMX [38, 39] наследует и расширяет особенности архитектуры Intel (рис. 1.2):
• суперскалярное ядро процессора;
• динамическое предсказание переходов;
• конвейеризированное устройство вычислений в формате с плавающей точкой;
• поддержка протокола MESI в кэш-памяти данных;
• 64-разрядная шина данных;
• конвейеризация циклов обращения к шине;
• контроль эффективности;
• поддержка двухпроцессорной обработки.
В дополнение к перечисленным возможностям, свойственным всем представителям семейства Pentium, новые микропроцессоры обеспечивают:
• поддержку выполнения мультимедийного набора команд;
• удвоенные объемы кэш-памятей данных и команд (по 16 Кбайт каждый);
• улучшенную логику предсказания переходов;
• расширенную конвейеризацию;
• более глубокую буферизацию записи.
Вместе с тем процессор Pentium MMX лишился некоторых возможностей, свойственных предыдущим представителям семейства:
• функционального контроля по избыточности;
•поддержки набора микросхем управления кэшированием (Intel 82498/82493 и 82497/82492);
• разделяемой линии обращения к кэш-памяти команд.
Микропроцессор Pentium MMX содержит 4,5 млн. транзисторов и производится по технологии КМОП 0,35 микрон (в дальнейшем планируется переход на технологию 0,25 мкм). Особенностью процессора также является использование двух напряжений питания 3,3 В и 2,8 В. Рассеиваемая мощность процессора составляет 15,7 Вт.
Структурная схема микропроцессора Pentium MMX приведена на рис. 1.2. Процессор содержит два командных конвейера (U pipeline, V pipeline). Конвейер U может выполнять все целочисленные команды и команды с плавающей точкой. Конвейер V - простые целочисленные команды и команду с плавающей точкой FXCH.
На рис. 1.2 показаны раздельные кэш-памяти команд и данных процессора. Каждый кэш имеет объем 16 Кбайт и содержит два порта, по одному для каждого исполнительного конвейера. Кэш данных снабжен буфером трансляции адресов (TLB). Разрешение или запрещение кэширования страниц памяти может задаваться индивидуально с помощью программных или аппаратных средств.
Кэш команд, буфер адресов переходов и буфер предварительной выборки обеспечивают подачу команд к исполнительным модулям процессора. Программируемый внутренний контроллер прерываний (АР1С) совместим с контроллером 8259А и обеспечивает обслуживание как внутренних, так и внешних прерываний.
В Pentium ММХ улучшена система предсказания переходов. В обыкновенном процессоре Pentium для предсказания переходов используют два буфера (по 32 байта) предварительной выборки - один для линейной выборки команд, а другой - для выборки в соответствии с содержанием буфера адресов перехода (ВТВ) (таким образом, команда, прежде чем она потребуется для исполнения, почти всегда оказывается предварительно выбранной). В Pentium ММХ количество буферов предварительной выборки команд увеличено до 4-х (по 16 байт), что позволяет осуществлять предвыборку по 4-м независимым направлениям, а также повышена точность предсказания переходов.
Увеличена до 6 длина исполнительного конвейера за счет добавления стадии выборки (F) между стадиями предвыборки (PF) и декодирования команды (DI). На стадии выборки выполняется декодирование длины команды, которое в предыдущих моделях Pentium выполнялся на стадии DI. Процесс выполнения команд на Pentium и Pentium ММХ показан на рис. 1.3. Увеличение длины конвейера позволило сократить в среднем длительность выполнения команд и увеличить производительность процессора.
| CLK0 | CLK1 | CLK2 | CLK3 | CLK4 | CLK5 | CLK6 | CLK7 | |
| I1 | I3 | I5 | I7 | Pf | ||||
| I2 | I4 | I6 | I8 | |||||
| I1 | I3 | I5 | I7 | D1 | ||||
| I2 | I4 | I6 | I8 | |||||
| I1 | I3 | I5 | I7 | D2 | ||||
| I2 | I4 | I6 | I8 | |||||
| I1 | I3 | I5 | I7 | Ex | ||||
| I2 | I4 | I6 | I8 | |||||
| I1 | I3 | I5 | I7 | Wb | ||||
| I2 | I4 | I6 | I8 |
А)
| CLK0 | CLK1 | CLK2 | CLK3 | CLK4 | CLK5 | CLK6 | CLK7 | CLK8 | |||||
| I1 | I3 | I5 | I7 | Pf | |||||||||
| I2 | I4 | I6 | I8 | ||||||||||
| I1 | I3 | I5 | I7 | f | |||||||||
| I2 | I4 | I6 | I8 | ||||||||||
| I1 | I3 | I5 | I7 | D1 | |||||||||
| I2 | I4 | I6 | I8 | ||||||||||
| I1 | I3 | I5 | I7 | D2 | |||||||||
| I2 | I4 | I6 | I8 | ||||||||||
| I1 | I3 | I5 | I7 | Ex | |||||||||
| I2 | I4 | I6 | I8 | ||||||||||
| I1 | I3 | I5 | I7 | Wb | |||||||||
| I2 | I4 | I6 | I8 | ||||||||||
Б)
Рис. 1.3. Выполнение команд:
а) - в Pentium; 6) в Pentium ММХ
На рис. 1.3. обозначены: Il, I2,... последовательность выполняемых команд; Clk0, Clk1,... - последовательность процессорных тактов; pf, f, d1, d2, ex, wb - стадии выполнения команд - предвыборка, выборка, декодирование инструкции, генерация адреса, выполнение и запись результата соответственно.
Наряду с перечисленными улучшениями главным отличием нового микропроцессора явилась поддержка дополнительного мультимедийного набора команд, для выполнения которых используется ММХ - устройство и блок регистров с плавающей точкой. Технология ММХ внесла следующие изменения в архитектуру микропроцессоров Intel:
• добавлены 8 ММХ - регистров (ММ0 - ММ7). Регистры ММХ физически совмещены с 64-разрядными регистрами с плавающей точкой и могут быть использованы только для выполнения действий над ММХ - данными;
• добавлены 57 новых команд. Команды подразделяются на следующие группы - обмена данными, арифметические, сравнения, преобразования, логические, сдвига и команду отмены режима ММХ;
• добавлены 4 новых типа данных - упакованные байты (8 байт в 64-битовом пакете), упакованные слова (четыре 16-битовых слова в 64-битовом пакете), упакованные двойные слова (два 32-битовых двойных слова в 64-битовом пакете) и учетверенное слово (64 бита). Арифметические или логические операции выполняются параллельно над каждым байтом слова или двойного слова, содержащегося в 64-разрядном ММХ-регистре (SIMD-модель обработки).
SIMD обработка существенно ускоряет выполнение мультимедийных алгоритмов, для которых характерно выполнение идентичных операций над большими массивами однотипных данных (например, 16-битовые отсчеты оцифрованного звука, 8-битовые коды цвета пикселя и т.п.). Для сравнения. Выполнение умножения с накоплением 4-х 16-разрядных слов на другие 4 слова с использованием трехММХ-команд. Аналогичные вычисления на процессоре Pentium потребуют 4-кратного выполнения последовательности команд: FILD, FMUL, FADD (всего 12 команд).
Применение ММХ-команд позволяет увеличить скорость выполнения мультимедийных приложений на 60% по сравнению с обыкновенным процессором Pentium, при одинаковых тактовых частотах (данные мультимедийного теста Intel Media Benchmark).
Физическое совмещение ММХ-регистров и регистров с плавающей точкой обеспечивает совместимость с предшествующей архитектурой и, следовательно, позволяет использовать ранее разработанное программное обеспечение. Для переключения из режима ММХ в режим вычислений с плавающей точкой процессору требуется 50 тактов.
Выполнение ММХ-команды в исполнительном конвейере (U или V) может осуществляться одновременно с выполнением другой ММХ-команды или команды с фиксированной точкой (но не команды с плавающей точкой). К 6 обычным стадиям выполнения для ММХ-команды добавляются еще 6 - в устройстве ММХ.
Расширенная конвейеризация существенно повышает производительность процессора и на немультимедийных приложениях. Сравнительные данные по результатам испытания на тестах SPECint 95 и SPECfp 95 процессоров Pentium и Pentium ММХ сведены в таблицу 3.1.
Микропроцессор компании Intel шестого поколения - P6 получил наименование Pentium Pro [4,8]. Он ориентирован на применение, главным образом, в старших моделях рабочих станций и мультипроцессорных системах. P6, как и предыдущие представители семейства, поддерживает систему команд х86. Однако архитектурные особенности процессора обусловливают его эффективность для 32-разрядных приложений, тогда как для 16-разрядных программ скорость выполнения может оказаться существенно меньшей, чем для Р5 с той же тактовой частотой.
Микропроцессор Pentium 4.
Pentium 4- новая ступень развития микропроцессорной техники. В 2000 году состоялась презентация Pentium 4 - новой модели 32-разрядных микропроцессоров компании Intel [9]. В связи с появлением в 2000 году нового семейства высокопроизводительных 64-разрядных процессоров Itanium, многие специалисты считали, что долгий век семейства процессоров 80x86-Pentium, начатого в 1978 году моделью 8086 и представляемого в настоящее время последними моделями Pentium III, Pentium III Xeon, Celeron, близится к окончанию. Однако, представленная разработка, являющаяся результатом трёхлетнего труда ведущих специалистов компании Intel, во многих отношениях является новым этапом в развитии микропроцессорной техники. На презентации были отмечены основные особенности микропроцессоров Pentium 4:
-новая микроархитектура процессора NetBurst (пакетно-сетевая), ориентированная на эффективную работу с Интернет-приложениями;
-новая системная шина FSB, обеспечивающая обмен со скоростью 3,2 Гбайт/c при частоте передачи данных 400 МГц;
-значительное расширение системы команд путём введения обработки 128-разрядных данных по SIMD-технологии, когда одна команда одновременно выполняется над несколькими операндами.
В процессоре Pentium 4 сохраняется архитектура IA-32 (Intel Architеcture – 32), характерная для всех 32-разрядных микропроцессоров Intel, начиная с i386. Поэтому пользователь будет иметь дело с хорошо знакомым набором регистров и способов адресации, работать с базовой системой команд и известными вариантами реализации прерываний и исключений. Однако внутренняя структура (микроархитектура) процессора Pentuim 4 значительно отличается от предшествующей микроархитектуры семейства P6, к которому относятся Pentium II, Pentium III и Celeron. Кратко укажем эти отличия.
В Pentuim 4 используется гиперконвейерная технология выполнения команд, при которой число ступеней конвейера достигает 20 (в Pentium - 5 ступеней, в Pentium III - 11 ступеней). Таким образом, одновременно в процессе выполнения может находиться до 20 простых команд, находящихся на разных стадиях (ступенях) реализации. Так как эффективность конвейера резко снижается из-за необходимости его перезагрузки при выполнении условных ветвлений, то в Pentuim 4 используется усовершенствованный блок предсказания ветвления, обеспечивающий 90-% вероятность правильного предсказания, что резко уменьшает число перезагрузок конвейера при неправильном предсказании направления ветвления.
Специальный блок ускоренного выполнения арифметических и логических операций работает с удвоенной тактовой частотой процессора, что позволяет за один такт получить результаты для двух команд.
Кэш-память 2-го уровня ёмкостью 256 Кбайт размещается непосредственно на кристалле процессора, что позволяет сократить время выборки по сравнению с Pentuim III, где эта кэш-память располагается на отдельном кристалле в общем корпусе (картридже) с процессором. Кэш-память данных 1-го уровня имеет ёмкость 8 Кбайт. Вместо кэш-памяти команд 1-го уровня в Pentuim 4 используется кэш-память для декодированных команд (микрокоманд), в которой содержатся микрокоманды для 100 поступивших команд, готовых к выполнению или находящихся на разных ступенях выполнения. Команды выполняются по мере готовности необходимых операндов, при этом исходный порядок их следования может нарушаться. В результате процессор имеет возможность выполнять последующие команды раньше предыдущих, если для них ещё не получены требуемые операнды. На выходе процессора полученные результаты накапливаются, сортируются и выдаются в соответствии с порядком поступления команд, то есть восстанавливается необходимая последовательность их вывода.
Для ускорения обмена с памятью используется новая реализация системной шины, обеспечивающая обмен с частотой 400 МГц. Такая скорость обеспечивается путём применения нового типа сверхбыстродействующей двухканальной памяти типа RDRAM [9] и специальной микросхемы MCH (Memory Controller Hub), реализующей 4 канала передачи данных. При тактовой частоте каждого канала 100 МГц обеспечивается общая частота обмена, эквивалентная 400 МГц, что в 3 раза выше, чем для наиболее быстродействующих современных системных плат, работающих на частоте 133 МГц.
Набор реализуемых команд расширен путём введения 144 новых команд, обеспечивающих одновременное выполнение одной операции над несколькими операндами. Такая SIMD-технология (Single Instruction - Multiple Data) была реализована в предыдущих моделях микропроцессоров Pentium, которые содержали блоки для выполнения MMX (Multi-Media Extension) - операций над целочисленными данными и SSE (Streaming SIMD Extesion) - операций над данными в формате с плавающей точкой. В Pentium 4 набор таких операций, названных SSE-2, значительно увеличен. При целочисленных (MMX) операциях одновременно обрабатываются 128 бит (было 64 бит), а при операциях с плавающей точкой (SSE) возможна обработка чисел с двойной точностью (было только с одинарной точностью). В результате производительность процессора при выполнении таких операций повышается вдвое.
Следует отметить, что операции SSE-2 позволяют существенно повысить эффективность применения микропроцессора при реализации трёхмерной графики и современных Интернет-приложений, обеспечении сжатия и кодирования аудио- и видеоданных и ряда других применений.
С 2001 года после переход к технологии изготовления с разрешающей способностью 0,13 мкм с использованием 6-слойной системы медных соединений было обеспечено повышение тактовой частоты микропроцессоров Pentium 4 до 2 ГГц и выше [4].
Мультиядерная технология. фирмы Intel [10-12]. Существует два подхода к увеличению производительности процессора. Первый - увеличение тактовой частоты процессора, второй – увеличение количества инструкций программного кода, выполняемых за один такт процессора. Увеличение тактовой частоты не может быть бесконечным и определяется технологией изготовления процессора. При этом рост производительности не является прямо пропорциональным росту тактовой частоты, то есть наблюдается тенденция насыщаемости, когда дальнейшее увеличение тактовой частоты становится нерентабельным. Разработка более совершенных архитектур процессоров, содержащих большее число функциональных исполнительных устройств, с целью повышения количества команд, одновременно исполняемых за один такт, - традиционный альтернативный росту тактовой частоты путь повышения производительности. Но такие разработки очень сложны и дороги. Сложность разработки возрастает с ростом сложности логики экспоненциально.
Одно из решений данной проблемы связано с реализацией концепции «параллелизма на уровне тредов (потоков)» - TLP (Thread Level Parallelism). Если программные коды не в состоянии загрузить работой все или даже большинство функциональных устройств, то можно разрешить процессору выполнять более чем одну задачу (тред или поток), чтобы дополнительные потоки загрузили простаивающие устройства. Здесь нетрудно усмотреть аналогию с многозадачной операционной системой: чтобы процессор не простаивал, когда задача оказывается в состоянии ожидания (например, завершения ввода-вывода), операционная система переключает процессор на выполнение другой задачи. Более того, некоторые механизмы диспетчеризации в операционной системе (например, квантование) имеют аналоги в многопотоковой архитектуре (MTA - MultiThreading Architecture). Очевидно, архитектура, поддерживающая параллелизм на уровне потоков (TLP), должна гарантировать, что треды не будут использовать одновременно одни и те же ресурсы, для чего требуются дополнительные аппаратные средства (например, дублирование регистровых файлов). Однако оказалось, что можно реализовать МТА на базе современных суперскалярных процессоров, и это требует лишь относительно небольших аппаратных доработок, что резко повышает привлекательность МТА в глазах проектировщиков.
При использовании базового типа параллелизма на уровне потоков (TLP) в микропроцессоре необходимо иметь не менее двух аппаратных расширений для потоков. Это регистры общего назначения, счетчик команд, слово состояния процесса и т. п. В любой момент времени работает только один поток (тред). Он выполняется до возникновения определенной ситуации (например, выполнения команды загрузки регистра при отсутствии данных в кэш-памяти). В этом случае процессор переключается на выполнение другого потока. Поскольку при непопадании в кэш-память операции с памятью могут потребовать до сотни тактов процессора, его простои по причине ожидания данных могли бы быть весьма значительными. Современные процессоры, имеющие возможности спекулятивного внеочередного выполнения команд, в подобной ситуации могут продолжить выполнение других команд, но на практике число независимых команд быстро исчерпывается и процессор останавливается.
Архитектура с одновременным выполнением тредов - SMT (Simultaneous Multi-Threading) допускает одновременное выполнение нескольких потоков. В этом случае на каждом новом такте на выполнение в какое-либо исполнительное устройство может направляться команда любого потока. По сравнению с суперскалярными процессорами, поддерживающими внеочередное спекулятивное выполнение команд и использующими механизм переименования регистров, для SMT необходимы, в частности, следующие аппаратные средства:
- несколько счетчиков команд (по одному на поток) с возможностью выбора любого из них на каждом такте;
- средства, ассоциирующие команды с потоком, которому они принадлежат (необходимы, в частности, для работы механизмов предсказания переходов и переименования регистров);
- несколько стеков адресов возврата (по одному на поток) для предсказания адресов возврата из подпрограмм;
- специальная дополнительная память в процессоре (в расчете на каждый поток) для процедуры удаления из буфера выполненных вне очереди команд.
Одна из основных особенностей SMT у многих современных процессоров - переименование регистров, когда логические (архитектурные) регистры отображаются в физические, с которыми и ведется реальная работа. Техника переименования регистров может, очевидно, применяться для того, чтобы избежать прямого дублирования файлов регистров, как аппаратной принадлежности потока.
Технология Hyper-Threading. Анонсированная в 2002 году компанией Intel технология Hyper-Threading – пример многопоточной обработки команд. Данная технология является чем-то средним между многопоточной обработкой, реализованной в мультипроцессорных системах, и параллелизмом на уровне инструкций, реализованном в однопроцессорных системах. Фактически технология Hyper-Threading позволяет организовать два логических процессора в одном физическом. Таким образом, с точки зрения операционной системы и запущенного приложения в системе существует два процессора, что дает возможность распределять загрузку задач между ними.
Посредством реализованного в технологии Hyper-Threading принципа параллельности можно обрабатывать инструкции в параллельном (а не в последовательном) режиме, то есть для обработки все инструкции разделяются на два параллельных потока. Это позволяет одновременно обрабатывать два различных приложения или два различных потока одного приложения и тем самым увеличить количество инструкций, выполняемых процессором в секунду, что сказывается на росте его производительности.
В конструктивном плане процессор с поддержкой технологии Hyper-Threading состоит из двух логических процессоров, каждый из которых имеет свои регистры и контроллер прерываний (Architecture State, AS). А значит, две параллельно исполняемые задачи работают со своими собственными независимыми регистрами и прерываниями, но при этом используют одни и те же ресурсы процессора для выполнения своих задач. После активизации каждый из логических процессоров может самостоятельно и независимо от другого процессора выполнять свою задачу, обрабатывать прерывания либо блокироваться. Таким образом, от реальной двухпроцессорной конфигурации новая технология отличается только тем, что оба логических процессора используют одни и те же исполняющие ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и одну и ту же системную шину. Использование двух логических процессоров позволяет усилить процесс параллелизма на уровне потока, реализованный в современных операционных системах и высокоэффективных приложениях. Команды от исполняемых параллельно потоков одновременно посылаются для обработки ядру процессора. Используя технологию out-of-order (исполнение командных инструкций не в порядке их поступления), ядро процессора способно параллельно обрабатывать оба потока за счет использования нескольких исполнительных модулей.
Идея технологии Hyper-Threading тесно связана с микроархитектурой NetBurst процессора Pentium 4 и является в каком-то смысле ее логическим продолжением.
Микроархитектура Intel NetBurst позволяет получить максимальный выигрыш производительности при выполнении одиночного потока инструкций, то есть при выполнении одной задачи. Однако, даже в случае специальной оптимизации программы, не все исполнительные модули процессора оказываются задействованными на протяжении каждого тактового цикла. В среднем, при выполнении кода, типичного для набора команд IA-32, реально используется только 35% исполнительных ресурсов процессора, а 65% исполнительных ресурсов процессора простаивают, что означает неэффективное использование возможностей процессора. Было бы логично реализовать работу процессора таким образом, чтобы в каждом тактовом цикле максимально использовать его возможности. Именно эту идею и реализует технология Hyper-Threading, подключая незадействованные ресурсы процессора к выполнению параллельной задачи.
В современных приложениях в любой момент времени, как правило, выполняется не одна, а несколько задач или несколько потоков (тредов - threads) одной задачи, называемых также нитями. В качестве примера рассмотрим работу двух потоков. При одновременном исполнении обоих потоков процессор будет постоянно переключаться между потоками, за один такт процессора выполняются только инструкции какого-либо одного из потоков. На каждом такте процессора используются далеко не все исполнительные блоки процессора, поэтому имеется возможность частично совместить выполнение инструкций отдельных потоков на каждом такте процессора. Например, выполнение двух арифметических операций с целыми числами первого потока можно совместить с загрузкой данных из памяти второго потока и выполнить все три операции за один такт процессора. Аналогично на втором такте процессора можно совместить операцию сохранения результатов первого потока с двумя операциями второго потока и т.д. Собственно, в таком параллельном выполнении двух потоков и заключается основная идея технологии Hyper-Threading. Hyper-Threading - это виртуальная многопроцессорность, так как процессор на самом деле один, а операционная система видит два процессора. Классическому одноядерному процессору добавили еще один логический блок управления AS (Architectural State) технологии IA-32.
Architectural State отслеживает состояние регистров (общего назначения, управляющих, прерываний - APIC, служебных), используя единственное физическое ядро (блоки предсказания ветвлений, ALU, FPU, SIMD-блоки и пр.) AS1 представляет из себя один логический процессор (LP1), AS2 - второй логический процессор (LP2). У каждого логического процессора есть свой собственный контроллер прерываний (APIC - Advanced Programmable Interrupt Controller) и набор регистров. Для корректного использования общих регистров двумя логическими процессорами существует специальная таблица - RAT (Register Alias Table), согласно которой можно установить соответствие между регистрами общего назначения общего процессорного ядра. Таблица использования регистров RAT у каждого логического процессора своя. В результате получается схема, при которой на одном и том же ядре могут свободно выполняться два независимых потока программного кода.
В ноябре 2002 года, компания Intel официально анонсировала свой очередной процессор в семействе Pentium 4, Intel Pentium 4 3.06 ГГц. Этот процессор являлся первым CPU в семействе, поддерживающем технологию Hyper-Threading.
Идея построения многоядерных микропроцессоров является развитием идеи кластеров, но в данном случае дублируется целиком процессорное ядро. Многоядерный процессор имеет два или больше «исполнительных ядер». Ядром процессора можно назвать его систему исполнительных устройств (набор арифметико-логических устройств), предназначенных для обработки данных. Операционная система рассматривает каждое из исполнительных ядер, как отдельный процессор со всеми необходимыми вычислительными ресурсами. Поэтому многоядерная архитектура процессора, при поддержке соответствующего программного обеспечения, осуществляет полностью параллельное выполнение нескольких программных потоков.
О выпуске двуядерных процессоров с архитектурой х86 фирмы Intel и AMD объявили почти одновременно в 2005г., а в 2006 году все ведущие разработчики микропроцессоров создали двуядерные процессоры. Так, появились двуядерные RISC-процессоры Sun Microsystems (UltraSPARC IV), IBM (Power4, Power5) и HP (PA-8800 и PA-8900).
Архитектурные особенности процессора Pentium D. С 2005 года был начат выпуск двуядерных процессоров Pentium D [10-12]. Двуядерные процессоры Pentium D содержат два независимых ядра на одной кремниевой пластине (рис. 1.4). Каждое ядро имеет собственный кэш второго уровня L2 объемом 1 Мб.
Ядра процессоров базируются на архитектуре NetBurst процессоров Pentium 4. Ядра объединены общей процессорной шиной, работающей на частоте 800 МГц.
Ядра процессоров Pentium D не поддерживают технологию Hyper-Threading. Для двуядерных процессоров она присутствует только в Pentium Extreme Edition, который благодаря этому виден в системе как четырехядерный.
Процессоры Pentium D поддерживают 64-битные расширения команд EM64T и технологию XD - защита от атак типа «переполнение буфера». Некоторые модели дополнительно поддерживают технологию SpeedStep, при которой возможно динамическое регулирование частоты и напряжения питания ядер процессора.
Выпуск процессоров Pentium D был налажен по 90-нанометровому техпроцессу, при этом на кристалле площадью 206 кв. мм. размещалось 230 млн. транзисторов. Кроме двух независимых ядер микропроцессор включает арбитр, позволяющий двум процессорам разделять между собой процессорную шину. То есть, фактически, всѐ взаимодействие между ядрами происходит только на уровне системной шины.
Суммарный размер кэш памяти второго уровня составляет 2 Мбайта. Кэш память разделяется пополам между двумя ядрами таким образом, что каждое из них оперирует с собственной кэш памятью второго уровня (L2) емкостью 1 мегабайт.
Но эксплуатация двуядерных процессоров на тех же частотах, что и одиночных ядер, невозможна. Вызвано это в первую очередь ограничениями по тепловыделению и энергопотреблению процессоров, поскольку объединение двух ядер на одном кристалле приводит к значительному росту этих характеристик. Поэтому двуядерные процессоры имеют гораздо более низкую тактовую частоту, чем их одноядерные "прародители". 23
Двуядерный процессор Pentium Extreme Edition был выпущен с тактовой частотой 3,2 ГГц, частотой системной шины 800 МГц и 2 Мб кэш-памяти второго уровня (по 1 Мб на каждое ядро).
Каждое ядро поддерживает Hyper-Threading, поэтому в системе видны четыре процессора.

