




Описание шаблона ПО
Описание шаблона ПО построено в виде ряда занятий, поясняющих исходный код шаблона и особенности требуемой реализации.
Разработку программного обеспечения, как правило, следует начинать с определения требований к системе, а также внутренней архитектуры решения и взаимодействия с внешней средой (которые часто могут следовать из требований). Под архитектурой понимается совокупность основных (системообразующих) компонентов и описание взаимодействия между ними. Взаимодействие с внешней средой определяет набор интерфейсов системы (доступ извне) и набор внешних систем, с которыми возможно взаимодействие, включая описание способов доступа к ним.
В данной курсовой работе к конечному программному продукту предъявляются минимальные требования: корректность выполнения, полнота реализации выбранной функциональности, использование объектно-ориентированного подхода, лаконичность исходного кода. При этом основное внимание уделяется процессу его создания.
В данном разделе будут описаны основные объекты системы, их взаимодействие и отношения между ними, а также файловый ввод-вывод.
Исходные положения
Данные для выбранной предметной области хранятся в файле. Обращение к файлу происходит при начале работы и при сохранении измененных данных в конце работы или по требованию пользователя. В остальное время вся работа ведется в оперативной памяти. Предполагается, что пользователь может открывать и закрывать различные файлы в течение работы без завершения программы.
При загрузке данных из файла формируются и заполняются списковые структуры, содержащие полную информацию о базе данных. Принцип организации данных в оперативной памяти показан на рис. 1. Данная организация выбрана исходя из предположения, что исходно нет информации ни о количестве таблиц, ни о количестве и типе полей в каждой таблице.

рис. 1. Организация данных после загрузки в оперативную память
В списке таблиц присутствуют все существующие в базе данных таблицы. С точки зрения программы таблица – это объект, оперирующий с набором однотипных записей. Например, таблица «Сотрудники» могла бы содержать записи, каждая из которых содержит информацию об одном из сотрудников. Таблица содержит указатель на список записей.
Таблица также должна содержать информацию о полях. Каждая запись содержит те и только те поля, которые описаны в таблице. Например, таблица «Сотрудники» может содержать поля: ФИО, номер паспорта, адрес, коэффициент зарплаты и т.п. Таблица содержит указатель на список полей.
Каждая таблица предоставляет набор функций, позволяющих оперировать с записями и полями:
- добавить/удалить/редактировать запись/поле;
- получить следующую/предыдущую/первую/последнюю запись;
- сортировать записи;
- др.
Дополнительно в данной работе каждая таблица должна уметь считывать свое содержимое из файла и записывать в файл.
Список полей содержит все поля для данной таблицы. С точки зрения программы поле – это объект, описывающий тип поля таблицы (целое число, строка и т.п.), его имя, служебные данные.
Каждая запись в списке записей содержит указатель на массив данных. Это фактические данные, ради которых создается база данных. Например, в таблице «Сотрудники» это информация о конкретном сотруднике – его имя, номер паспорта и т.д. Массив данных выделяется динамически при создании объекта записи.
Задание 1. Вариантный тип данных. Класс CVariant
При работе с реальными базами данных появляется необходимость в работе с полями таблиц различных типов. Очевидным удобством было бы однотипное обращение к данным разного типа.
Одним из подходов обеспечения подобной функциональности является использование вариантного типа данных. Термин «вариантный тип» (калька с английского Variant type) обозначает тип, позволяющий работать с различными типами данных. Вариантные типы широко используются и своей популярностью в частности обязаны модели COM.
В следующем примере проиллюстрирована работа с вариантными типом на примере языка Object Pascal (IDE Delphi):
procedure VariantTest();
Var
v: Variant;
Begin
v:=5; // переменная v содержит целое число 5
v:='abc'; // переменная v содержит строку ‘abc’
v:=6.1; // переменная v содержит число с плавающей точкой 6.1
end;
Целью задания является разработка подходов для реализации типа обеспечивающего подобную функциональность.
Определим множество типов, для которых будет разрабатываться вариантный тип – целое число, число с плавающей точкой, символ (1 байт), строка:
enum VarType {vtNone, vtInt, vtFloat, vtChar, vtStr};
Первое значение обозначает пустой, неопределенный тип вариантной переменной.
Создадим класс CVariant позволяющей работать с этими типами:
class CVariant
{protected:
VarType type;
union VariantData
{ int i;
float f;
char c;
char* pc;
} datum;
void StrDealloc()
{ if(type==vtStr) delete [] datum.pc; };
public:
CVariant& operator=(const CVariant& v);
CVariant() { type=vtNone; };
CVariant& operator=(float f);
CVariant& operator=(int i);
CVariant& operator=(char c);
CVariant& operator=(char* pc);
virtual ~CVariant() { StrDealloc(); };
VarType GetType() { return type; };
operator int();
operator float();
operator char();
operator char*();
};
В защищенной части класса (protected) содержится информация о типе (переменная VarType type) и данные (переменная VariantData datum, тип VariantData определен непосредственно в классе).
При этом если объект CVariant содержит строковый тип, то datum.pc указывает на строку (массив символов) в оперативной памяти. Функция StrDealloc() позволяет освободить память, выделенную под эту строку при уничтожении объекта или при смене типа/значения.
| Функция StrDealloc() определена непосредственно при объявлении в классе, что делает ее встроенной (inline) функцией-членом. Это означает, что компилятор будет пытаться в месте вызова функции вместо вызова встроить непосредственно ее код. Такой подход годится только для небольших часто вызываемых функций и позволяет сэкономить время на этапе выполнения программы. Пример «идеальной» встроенной функции: inline int Get5() { return 5; } Для этой функции в место ее вызова компилятор просто вставит константу 5. |
В открытой части класса (public) содержится конструктор, деструктор, две группы операторов и функция GetType(), возвращающая текущий фактический тип содержимого вариантной переменной.
| Конструктор по умолчанию реализуемый компилятором не инициализирует члены класса встроенных типов. Поэтому, во избежание ошибок необходимо определить конструктор по умолчанию – в данном случае это единственный способ провести инициализацию пустым (vtNone) типом. |
Первая группа операторов перегружает оператор присваивания (‘=’) для целевых типов, что позволяет записывать выражения вида:
CVariant v;
int i=5;
v=i;
Например, реализацию перегрузки оператора ‘=’ для целого типа можно определить так:
CVariant& CVariant::operator =(int i)
{ StrDealloc(); // если ранее объект содержал строковый тип необходимо освободить память
type=vtInt; // устанавливаем информацию о типе
datum.i=i; // присваиваем значение
return *this; // возвращаем ссылку на объект
};
Перегруженный оператор ‘=’ обязан возвращать ссылку на объект класса, в котором он перегружен. Это необходимо для сохранения корректности записи цепочки присваиваний. Например:
CVariant v;
int i=5, j;
j=v=i; // результат выполения: j==5, v==5, v.type==vtInt
Вторая группа операторов перегружает операторы преобразования типов, что позволяет записывать выражения вида:
CVariant v=5;
int i;
i=v;
Например, реализацию перегрузки оператора преобразования типа ‘int’ можно определить так:
CVariant::operator int()
{ switch(type) // возвращаемое значение будет зависеть от текущего типа вариантной переменной
{case vtChar:
return datum.c; // код символа
case vtInt:
return datum.i; // тип вариантной переменной и возвращаемого значения совпадают
case vtFloat:
return static_cast<int>(datum.f); // явное преобразование убирает предупреждение компилятора
case vtStr:
return *datum.pc; // код первого символа строки
}
return 0; // при неопределенном типе возвращаем 0 – значение по умолчанию
};
Для операторов преобразования типа не указывается возвращаемый тип, т.к. он предопределен. В этом смысле операторы преобразования подобны конструкторам.
При неопределенности типа вариантной переменной (это возникает в случае, когда переменная не была проинициализирована) может быть полезным сообщить об этом пользователю, например, при помощи генерации исключения.
| Вместо набора перегруженных операторов ‘=’ можно использовать набор конструкторов, принимающих в качестве единственного аргумента переменную типа, для которого определяется преобразование. Использование конструкторов для преобразования типов (conversion constructors) требуют понимания механизма их работы. Рассмотрим фрагмент кода: CVariant v; v=”abcd”; // создается временный объект, выполняется операция присваивания char* pc=v; // pc указывает туда же, куда и v.datum.pc std::cout<<pc; // обращение к памяти по указателю pc Во второй строке кода выполняются следующие действия: - неявно создается временный объект - вызывается конструктор CVariant(char*) со значением параметра “abcd”; - выполняется операция присваивания объекту v временного объекта; - уничтожается временный объект. По умолчанию операция присваивания осуществляется как почленное копирование. Поэтому для объектов содержащих указатели на динамически выделенные объекты необходимо определение операции присваивания, учитывающей динамическую природу данных: CVariant& CVariant::operator=(const CVariant &v) { StrDealloc(); type=v.type; if(type!=vtStr) datum=v.datum; else { datum.pc=new char[strlen(v.datum.pc)+1]; strcpy(datum.pc,v.datum.pc); } return *this; } Если данное условие не выполнено, то приведенный выше код приведет к непредсказуемым результатам, возможно катастрофичным. Действительно, после того как во второй строке уничтожается временный объект, v.datum.pc указывает на освобожденный участок памяти. После этого выполнение третьей строки свяжет указатель рс с освобожденным участком памяти, и результат выполнения четвертой строки непредсказуем. В частности программа может завершиться по исключению. Кроме этого будет осуществлена повторная попытка освободить участок памяти при вызове деструктора для v. Вообще, использование конструкторов для преобразования увеличивает накладные расходы по сравнению с оператором копирования, т.к. создается временный объект. В исходном коде шаблона приведены оба варианта – с использованием операторов присваивания и с набором конструкторов для преобразования. В исходном коде они разделены директивами препроцессора: #ifdef ConversionByConstructor … #else … #endif |
Задания.
- Изучить исходный текст реализации класса: файлы CVariant.h, CVariant.cpp.
- Реализовать операторы сравнения для класса CVariant.
Дополнительные задания.
- Какие изменения необходимо внести в реализацию, чтобы добавить обработку классом CVariant еще одного типа данных?
- Укажите недостающую, по вашему мнению, функциональность приведенной реализации класса CVariant.
Задание 2. Списковые структуры
Под термином «списковая структура» (далее – список) обычно понимается такая организация данных, при которой объекты (данные) связаны в последовательную цепочку посредством указателей. Данное определение подразумевает динамическую природу списка – т.е. не заданное заранее количество и, иногда, тип элементов.
Различают одно- и двунаправленные, одно- и многосвязные списки. Списки легко обобщаются до понятия графа.
Существуют различные подходы к реализации списка. Наиболее очевидной является следующая реализация:
- каждый элемент списка кроме полезных данных содержит информацию о связи с другими элементами;
- функции для работы со списком, являются внешними по отношению к объекту-элементу списка.
Как правило, набор таких функций и общих данных для списка (например, указатель на первый элемент) выделяются в отдельный класс, реализующий интерфейс списка – функции добавления, удаления, сортировки и т.п. Данная схема проиллюстрирована на рис. 2.

рис. 2. Интерфейсный объект списка и элементы списка
Возможен другой подход, при котором каждый элемент списка будет представлять набор функций для работы со всем списком. При этом общие данные для списка помещаются в отдельный объект. Данная схема проиллюстрирована на рис. 3.
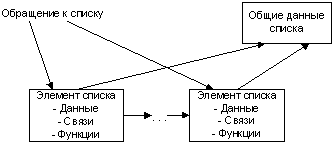
рис. 3. Элементы списка и объект, содержащий общие данные
| Во втором случае первое приходящее на ум решение - хранение общих данных в статических (static) членах данных класса элемента списка. Данное решение возможно только в том случае, когда планируется создание только одного списка, т.к. иначе данные для различных списков в одной программе будут конфликтовать. |
Разработаем классы, реализующие список по второму варианту.
Вначале создадим вспомогательный класс CListInfo, содержащий общие данные для списка:
class CListInfo
{ int RefCount;
bool Sorted;
int SortCriterion;
CSimpList* FirstElement;
CSimpList* LastElement;
void Inc() { RefCount++; };
void Dec() { RefCount--; if(RefCount<=0) delete this; }; // при обнулении счетчика - самоуничтожение
CListInfo(CSimpList* List) { RefCount=SortCriterion=0;
Sorted=false;
FirstElement=LastElement=List;
};
friend CSimpList;
};
Класс CListInfo содержит следующую информацию:
- RefCount – подсчет ссылок на объект (количество элементов в списке).
- Sorted, SortCriterion – информация о том, отсортирован ли список а также критерий сортировки. Критерий сортировки – это дополнительная информация, которая зависит от данных, содержащихся в списке. Например, если в списке содержатся записи таблицы базы данных, то критерий может содержать поле и направление сортировки.
- FirstElement, LastElement – указатели на первый и последний элементы списка.
При добавлении/удалении элементов списка вызываются функции Inc() и Dec(), причем при обнулении счетчика ссылок RefCount (т.е. список пуст) объект самоуничтожается. (См. также реализацию конструктора и деструктора класса CSimpList).
| Сходную модель управления временем жизни имеют объекты в модели COM (Component Object Model). На COM в частности основана технология ActiveX. |
Класс CListInfo объявляет все члены как личные (private – значение по умолчанию), т.е. недоступные извне класса. Единственным исключением является класс CSimpList, который объявляется как дружественный (friend), что позволяет ему получить доступ ко всем членам. Таким образом, класс CListInfo получается полностью изолированным от внешних воздействий.
Создадим класс CSimpList, реализующий интерфейс списка и служащий контейнером для данных каждого элемента списка:
class CSimpList
{protected:
CSimpList* next; // указатель на следующий элемент
CSimpList* prev; // указатель на предыдущий элемент
CListInfo* ListInfo; // указатель на объект с общими данными списка
void BubbleUp(); // обмен местами элемента списка со следующим за ним элементом.
// Используется, например, в алгоритме пузырьковой сортировки
public:
CSimpList(CSimpList *List = NULL); // конструктор
virtual ~CSimpList(); // деструктор
// чисто виртуальные операторы сравнения:
virtual bool operator==(CSimpList &List) = 0;
virtual bool operator>(CSimpList &List) = 0;
virtual bool operator<(CSimpList &List) = 0;
// набор функций для доступа к элементам списка:
virtual CSimpList* Next() { return next; };
virtual CSimpList* Prev() { return prev; };
virtual CSimpList* First() { return ListInfo->FirstElement; };
virtual CSimpList* Last() { return ListInfo->LastElement; };
int Count() { return ListInfo->RefCount; }; // количество элементов списка
// добавление и удаление элемента списка:
virtual bool Add(CSimpList* Elem);
virtual CSimpList* Remove();
virtual CSimpList* Sort(int Criterion = 0); // сортировка списка в соответствии с критерием
int SortCriterion() { return ListInfo->SortCriterion; }; // критерий сортировки
};
Описанный набор функций, хотя и является достаточно общим для списковых структур, написан с учетом специфики области применения – работа с записями базы данных.
Рассмотрим подробнее члены данные и функции.
Каждый элемент списка имеет указатели на предыдущий и следующий элементы списка (prev и next), а также на объект, содержащий общие данные для списка (ListInfo). Данные указатели объявлены как protected, и, следовательно, доступны в классах-потомках. Будем считать, что если указатели prev и/или next имеют нулевое значение, то данный элемент является первым и/или последним в списке.
Конструктор класса имеет параметр List*, который, если не равен нулю, указывает на список (элемент списка), к которому необходимо добавить создаваемый объект. Поскольку параметр имеет значение по умолчанию, конструктор может использоваться как конструктор по умолчанию.
Исходный код конструктора:
CSimpList::CSimpList(CSimpList *List)
{ next=prev=NULL; // инициализация указателей на предыдущий/следующий элементы
if(List) // если List не равен нулю (т.е. содержит указатель на список, к которому надо добавить создаваемый элемент)
{ ListInfo=NULL;
List->Add(this); // добавляем создаваемый объект к указанному списку
}
else // если List равен нулю или не задан
{ ListInfo=new CListInfo(this); // создаем объект с общими данными для списка
ListInfo->Inc(); // увеличиваем счетчик элементов списка
}
};
Деструктор класса уменьшает счетчик элементов списка:
CSimpList::~CSimpList()
{
ListInfo->Dec();
};
Деструктор класса CSimpList объявлен как виртуальный. В большинстве случаев, когда в программе используются различные потомки одного базового класса, имеет смысл определять деструктор как виртуальный, чтобы гарантировать правильное уничтожение объектов. В качестве примера некорректного уничтожения объекта с невиртуальным деструктором можно привести следующий фрагмент кода (класс В является потомком класса А):
A *a;
B *b;
b=new B;
a=b;
delete a;
При определении виртуального деструктора приведенный код был бы выполнен гарантированно корректно.
Дополнительно необходимо учесть, что деструкторы классов-потомков CSimpList должны будут явно вызывать деструктор ~CSimpList() для обеспечения корректного подсчета элементов списка.
Группа операторов сравнения объявлена как чисто виртуальная (pure virtual), операторы не имеют определений. Таким образом, данный класс является абстрактным – он может использоваться только как базовый класс, для которого невозможно создать самостоятельный объект. С этим же связано отсутствие реальных данных для элемента списка – наполнение содержанием является обязанностью потомков.
| Чисто виртуальные функции должны быть реализованы в классах-потомках. Данный подход используется для обеспечения совместимости и унификации поведения классов. Например, в классе CSimpList невозможно определить осмысленные операторы сравнения, т.к. в классе не определены фактические данные. Однако, реализацию функции сортировки, использующую сравнение элементов, имеет смысл поместить в базовый класс. Механизм чисто виртуальных функций обеспечивает явное описание данной ситуации. |
Набор функций для доступа к элементам списка позволяет получить доступ к первому/последнему или к предыдущему/следующему элементу списка.
Функция Count, возвращающая количество элементов в списке, не ведет их подсчета, а возвращает значения RefCount из объекта с общими данными списка. Эта переменная означает количество ссылок на объект с общими данными и автоматически обновляется при добавлении/удалении элементов.
Приведем код функций добавления и удаления элемента.
Функция удаления элемента:
CSimpList* CSimpList::Remove()
{ if(next || prev) // если это не единственный элемент в списке
{ if(!next) // если это последний элемент
{ // предпоследний элемент, если существует, будет последним:
ListInfo->LastElement=prev;
prev->next=NULL;
}
else if(!prev) // если это первый элемент
{ // второй элемент, если существует, будет первым:
ListInfo->FirstElement=next;
next->prev=NULL;
}
else //это не был ни первый, ни последний элемент
{ // связываем предыдущий и следующий элементы между собой:
next->prev=prev;
prev->next=next;
}
CListInfo *tmpListInfo=ListInfo;
ListInfo->Dec(); // уменьшаем количество элементов в списке
prev=next=NULL; // сжигаем мосты
ListInfo=new CListInfo(this); // удаленный элемент становится самостоятельным списком
ListInfo->Inc();
return tmpListInfo->FirstElement; // возвращаем указатель на первый элемент списка, откуда был удален элемент
}
return NULL;
}
Особенностью функции удаления элемента из списка является то, что удаленный элемент становится самостоятельным списком, состоящим из одного элемента. Функция возвращает указатель на первый элемент списка, из которого был удален элемент. Если список исходно состоял из одного элемента – возвращается нулевой указатель.
Функция добавления элемента:
bool CSimpList::Add(CSimpList* Elem)
{ if(Elem && Elem->ListInfo!=ListInfo) // если Elem не равен нулю и еще не находится в списке
{ if(Elem->Count()>1) // Элемент сначала должен быть удален из своего списка
return false;
// добавляем Elem в конец списка:
ListInfo->LastElement->next=Elem;
Elem->prev=ListInfo->LastElement;
Elem->next=NULL;
Elem->ListInfo=ListInfo;
ListInfo->LastElement=Elem;
ListInfo->Inc(); // увеличивает количество элементов
ListInfo->Sorted=false; // сортировка могла нарушиться
return true;
}
return false;
}
Для перемещения элемента из одного списка в другой необходимо последовательно вызвать функции Remove() для перемещаемого элемента, а затем Add() для любого элемента списка, к которому происходит добавление, при этом в качестве параметра необходимо передать указатель на добавляемый элемент:
CSimpList *a,*b;
… // созданеие списков a и b
CSimpList *c=a; // с указывает на элемент а, который необходимо удалить из списка (1)
a=c->Remove(); // элемент с удаляется из списка а (2)
b.Add(&c); // элемент с добавляется к списку b
В данном примере очень наглядно показана двоякость поведения указателя на элемент списка. С одной стороны, он указывает непосредственно на элемент списка (как a в строке (1)). С другой стороны, он олицетворяет собой весь список (как a в строке (2) – после выполнения указывает на первый элемент списка, из которого было произведено удаление).
Функция сортировки реализована в абстрактном классе CSimpList и зависит только от реализации в классах-потомках оператора ‘>’.
Для функции сортировки определена вспомогательная функция BubbleUp(), продвигающая элемент на следующее место в списке (перестановка со следующим элементом):
void CSimpList::BubbleUp()
{ if(next) // если существует следующий элемент в списке
{ if(prev) // если это не первый элемент
prev->next=next; // связываем предыдущий элемент со следующим
else
ListInfo->FirstElement=next; // следующий элемент станет первым
next->prev=prev; // связываем следующий элемент с предыдущим
if(next->next) // если это не предпоследний элемент
next->next->prev=this; // связываем элемент после следующего с текущим
else
ListInfo->LastElement=this; // продвигаемый элемент станет последним
prev=next; // кто был следующим станет предыдущим
next=next->next; // пора запутаться
prev->next=this; // все, хватит
}
ListInfo->Sorted=false; // перестановка может нарушить сортировку
}
Для упорядочивания списка используется алгоритм пузырьковой сортировки. Данный алгоритм является одним из наиболее простых и наименее эффективных алгоритмов.
Функция Sort(), реализующая сортировку, принимает параметр – критерий сортировки. Например, критерий может определять, нужно ли сортировать список по возрастанию или убыванию, или обозначать индекс поля, по которому необходимо отсортировать записи в списке с табличными данными. Функция Sort() не использует напрямую параметр Criterion – это задача решается в определении операторов сравнения.
CSimpList* CSimpList::Sort(int Criterion)
{ if(ListInfo->SortCriterion!=Criterion ||!ListInfo->Sorted) // если не отсортирован по заданному критерию
{ ListInfo->SortCriterion=Criterion; // устанавливаем критерий сортировки списка
CSimpList* le; // временный указатель на элемент списка
bool swapped; // флаг – устанавливается, если была хотя бы одна перестановка
do
{ le=ListInfo->FirstElement; // начнем с первого элемента
swapped=false; // начинаем проход по списку – перестановок пока не было
// внутренний цикл по элементам списка:
while(le->next) // пока не дойдем до последнего элемента
{ if(*le>*le->next) // если le «больше» следующего элемента
{ le->BubbleUp(); // продвигаем le вперед по списку
swapped=true; // и запоминаем, что была перестановка
}
else // иначе
le=le->next; // переходим к следующему элементу
}
} while(swapped); // внешний цикл завершается, если перестановок не было
ListInfo->Sorted=true; // список отсортирован
}
return ListInfo->FirstElement; // первый элемент мог измениться
};
Приведем пример реализации списка на основе класса CSimpList:
class CSomeList: public CSimpList
{public:
int i,j; // данные, хранящиеся в списке
CSomeList(CSomeList* List=NULL): CSimpList(List) {} // конструктор
bool operator==(CSimpList &List) { … }; // реализация оператора равенства
bool operator<(CSimpList &List) { … }; // реализация оператора ‘<’
bool operator>(CSimpList &List) // реализация оператора ‘>’
{ if(SortCriterion()==0) // если критерий сортировки равен нулю сортируем по полю i
return i > (static_cast<CSomeList&>(List).i);
else // иначе сортируем по полю j
return j > (static_cast<CSomeList&>(List).j);
};
CSomeList* Sort(int Criterion = 0) // функция сортировки
{ return static_cast<CSomeList*>(CSimpList::Sort(Criterion)); };
void Show(); // вывод списка на экран
… // набор дополнительных функций
};
Оператор ‘>’ реализован таким образом, что если критерий сортировки равен нулю, то идет сравнение полей i, иначе – полей j объектов. Преобразование static_cast<CSomeList&> используется для приведения типа параметра.
Реализация функции Sort() в данном классе имеет возвращаемый тип отличный от определенного в базовом классе. Это является допустимым ослаблением типа для виртуальных функций, избавляющее пользователя класса от необходимости делать явные преобразования в тексте программы. Таким образом, преобразование можно сделать один раз при определении функции производного класса (это единственное действие функции CSomeClass::Sort()).
Аналогично можно определить и другие функции класса CSimpList, возвращающие значение типа CSimpList*. Это является одной из причин, почему функции, возвращающие указатели/ссылки на собственный класс желательно объявлять виртуальными.
Задания.
- Изучить исходный текст реализации класса: файлы CSimpList.h, CSimpList.cpp.
- В приведенной реализации отсутствует функция уничтожения списка – каждый объект должен будет уничтожаться независимо. Разработать функцию-член, позволяющую уничтожить весь список.
Дополнительные задания.
- Для сортировки списка достаточно определить операторы ‘>’ (и, возможно, ‘<’). Дополнительно передаваемый критерий сортировки в случае работы с таблицами базы данных позволяет определить, целевое поле и направление сортировки. При этом реализация операторов должна учитывать этот критерий. Оператор равенства (т.е. выборки элемента списка, ‘==’) имеет более сложную реализацию. В качестве примера можно привести задачу выборки элементов, в которых строковое поле содержит одну из подстрок “СПб” или “Санкт-Петербург” или “С-Петербург” без учета регистра, а числовое поле содержит значение не менее заданного числа. Какие возможны подходы к решению данной задачи?
- На практике часто возникает необходимость работать только с частью списка – например, выводить на экран только элементы, удовлетворяющие заданному критерию (см. предыдущий пункт). Как нужно изменить класс CSimpList для реализации данной функциональности?
Задание 3. Структура базового файла.
Рассмотрим, в каком формате данные будут храниться на жестком диске.
Файловый ввод-вывод обычно может рассматриваться как взаимодействие с внешней средой, при этом особую роль начинает играть формат, в котором передаются данные. В процессе выполнения программы данные могут быть «размазаны», разделены между объектами, в то время как при записи в файл они должны быть собраны в единую последовательность байт.
В данной работе для хранения данных между запусками программы предлагается использовать некоторые идеи промышленного стандарта обмена данными XML (eXtensible Markup Language – расширяемый язык разметки). Это решение не является допустимым для хранения на диске реальных баз данных, работающих с большими объемами данных. В приложении 1 кратко описано назначение стандарта.
Не будем придерживаться требований стандарта в полной мере, используем лишь механизм тэгов для явного задания структуры хранения данных. Так, например, таблицу и ее данные можно описать следующим образом:
<table Name=Сотрудник >
<fields>
<field ID=1 type=Integer>
Идентификатор
</field>
<field name=2 type=String length=32>
ФИО
</field>
</fields>
<records>
<record>
<value field=1>
56234
</value>
<value field=2>
Иванов И.И.
</value>
</record>
<record>
<value field=1>
56233
</value>
<value field=2>
Петров П.П.
</value>
</record>
</records>
</table>
Термин тэг (tag – ярлык, этикетка, англ.) используется для обозначения служебных меток в теле документа, позволяющих описать дополнительные свойства данных. Стандартом де-факто стало использование записи тэгов в угловых скобках. Как правило, тэги записываются в виде пары открывающего и закрывающего тэга:
<TagName>
…
</TagName>,
где многоточием отображены данные, с которыми связан тэг.
Открывающий тэг может иметь ряд атрибутов (параметров):
<TagName attrib1=value1 attrib2=value2>,
где attribXX имя атрибута, valueXX –значение.
Тэги должны быть строго вложенными, т.е. следующая запись будет ошибочной:
<Tag1> <Tag2> </Tag1> </Tag2>.
В примере с таблицей тэги <table>-</table> ограничивают описание таблицы, <fields>-</fields> - полей таблицы, <field>-</field> - описание каждого поля таблицы и т.п.
Выбор набора тэгов, атрибутов и смысл значения тела тэгов лежит на разработчике. Набор тэгов должен быть семантически полон и непротиворечив. При этом необходимо стремиться к достижению двух противоречащих критериев:
- достаточный уровень структурированности данных, позволяющий минимизировать затраты на анализ значений тел тэгов и параметров. Например, для таблицы базы данных было бы в большинстве случаев недостаточно тэгов начала и конца таблицы.
- минимизация «накладных расходов» на долю тэгов в объеме документа и на их обработку. Это можно рассматривать как вопрос минимизации общего количества тэгов в документах, а также количества типов тэгов. Так, в ряде случаев можно выбирать между реализацией с атрибутом или вложенным тэгом. Первый вариант, как правило, экономичнее.
Для чтения файла с данными разработаем класс CFileParser, позволяющий последовательно считывать тэги и получать доступ к значениям атрибутов и данных:
using namespace std; // использование пространства имен стандартной библиотеки
class CFileParser
{ // служебные данные:
string FileName; // имя файла (см. конструктор). Исп. тип string стандартной библиотеки
string CurTagName; // имя текущего прочтенного тэга
string ParamString; // считанная для тэга строка атрибутов
bool TagCached; // флаг, устанавливаемый при наличии кэшированного тэга (прочитанного из файла, но не запрошенного)
fstream SourceFile; // доступ к файлу через потоковые классы стандартной библиотеки
void FormatParamString(); // приведение строки атрибутов к стандартному виду
public:
explicit CFileParser(const char *FileName); // конструктор, в нем открывается файл c данными
bool GetStartTag(const char* TagName); // чтение открывающего тэга
bool GetStopTag(const char* TagName); // чтение закрывающего тэга
bool GetTagBody(const char* TagName, char* Dest, int &DestLen); // чтение данных тэга
// чтение заданного атрибута тэга:
bool GetTagParam(const char* TagName, const char* ParamName, char* Dest, int &DestLen);
fstream &PrepareWriting(); // создает резервную копию файла и открывает файл на запись
};
Класс предполагается использовать следующим образом:
- создается объект класса, и при помощи функций чтения считываются данные из файла;
- для выполнения записи в файл необходимо вызвать функцию PrepareWriting(), которая возвращает ссылку на потоковый класс стандартной библиотеки fstream. При этом создается резервная копия исходного файла и файл очищается. После вызова PrepareWriting() чтение данных невозможно.
Конструктор принимает в качестве параметра единственный аргумент – имя файла, в котором хранятся данные. Ключевое слово explicit указывает на то, что данный конструктор нельзя использовать для неявного преобразования типов.
Функция GetStartTag() пытается считать открывающий тэг в виде <TagName …>. Истинное значение возвращается, если операция чтения прошла успешно и при этом указанное в параметре имя тэга совпало с прочитанным. Если тэг был считан, однако его имя не совпало с указанным, то возвращается ложное значение, а считанные данные сохраняются (кэшируются).
Функция GetStopTag() проверяет наличие закрывающего тэга указанного в качестве параметра и возвращает истинное значение в случае успеха. Функции GetStartTag(“Tag”) должна соответствовать функция GetStopTag(“Tag”).
Функция GetTagBody() копирует по адресу Dest не более DestLen байт, прочитанных c текущего места в файле до следующего символа ‘<’. В параметр DestLen записывается фактическое количество скопированных байт. Функция возвращает истинное значение в случае успеха (если первым параметром указано имя текущего тэга).
Функция GetTagParam() копирует по адресу Dest значение указанного атрибута (длина не более DestLen байт). В параметр DestLen записывается фактическое количество скопированных байт. Истинное значение возвращается в случае успеха (если указано имя текущего тэга и у него есть атрибут с указанным именем).
Функция GetTagParam() использует вспомогательную защищенную функцию FormatParamString(), проводящую синтаксический разбор считанной строки параметров и приводящую ее к виду удобному для поиска атрибутов.
Функция PrepareWriting() закрывает файл, создает его резервную копию и открывает на запись. Функция возвращает ссылку на объект класса стандартной библиотеки fstream, предоставляющий исходный файл на запись. Таким образом, процедура записи данных полностью вынесена из класса.
Задания.
1. Изучить исходный текст реализации класса: файлы CFileParser.h, CFileParser.cpp.
2. Разработать структуру базового файла: определить набор тэгов, атрибутов и правил, по которым будет формироваться файл.
3. Разработать механизм, позволяющий указывать следующие свойства полей: автогенерируемое поле (значение генерируется автоматически при создании новой записи); ключевое поле (значение должно быть уникальным для данной таблицы).
Дополнительные задания.
1. Указанная реализация класса имеет как минимум один существенный недостаток – не предоставлен стандартный механизм записи тэгов в файл, аналогичный механизму чтения. Наличие такого механизма могло бы оградить пользователя класса от необходимости думать о формате записи в файл, закрыв потенциальную «дыру» для ошибок. Разработать симметричный чтению механизм записи тэгов в файл.
Задание 4. Поля таблицы: класс CField
Создадим класс, описывающий поля таблицы, CField. Т.к. список полей будет храниться в памяти в виде списковой структуры, произведем класс CField от класса CSimpList.
Зададим для класса CField следующие свойства:
- Хранение имени поля;
- Хранение данных о типе поля;
- Обеспечение механизма автоматической генерации значения;
- Обеспечение механизма загрузки и сохранения в файл информации о поле;
- Хранение параметров отображения: порядка вывода поля на экран, необходимости отображения поля, ширины поля в символах при выводе.
Объявим класс CField:
#define vtAuto vtNone; // синоним для значения vtNone (см. тип VarType из CVariant.h - variant type)
class CField: public CSimpList
{ CField* GetByOffsetIndex(int OffsetIndex) // возвращает элемент списка, отстоящий от данного на OffsetIndex позиций
{ if(!OffsetIndex) return this;
if(!next) return NULL;
return static_cast<CField*>(next)->GetByOffsetIndex(OffsetIndex-1);
}
public:
VarType FieldType; // vtAuto (т.е. vtNone) означает, что значение генерируется автоматически
char FieldName[32]; // имя поля таблицы
static unsigned int AutoNextVal; // следующее автоматически генерируемое значение
int OutputOrder; // порядок вывода на экран
int FieldLen; // длина поля (ширина столбца) при выводе на экран
bool Visible; // указание на отображение поля
int GetIndexByOrder(int OrderNum); // возвращает позицию элемента в списке по номеру вывода на экран
bool SetNewOrd(int OldOrd, int NewOrd); // меняет номер вывода на экран с OldOrd на NewOrd
CField* operator[](int index) // реализует обращение к элементам списка как к элементам массива
{ return static_cast<CField*>(First())->GetByOffsetIndex(index);
};
bool LoadFromFile(CFileParser &DataFile); // загружает данные из файла
bool SaveToFile(fstream &DataFile); // сохраняет данные в файл
// В данной реализации сортировка не предполагается:
bool operator==(CSimpList &List) { return true;}
bool operator< (CSimpList &List) { return false;}
bool operator> (CSimpList &List) { return false;}
virtual bool Add(CField* Elem);
virtual CField* Remove();
CField(CField *List = NULL);
~CField(void);
};
Для задания типа поля FieldType используется перечисление VarType, определенное для задания текущего типа вариантной переменной (CVariant). Это обеспечивает их совместимость. Единственным исключением является возможность использования поля с неопределенным (vtNone) типом, для которого определен синоним vtAuto. В этом случае поле считается генерируемым автоматически – значение поля для каждой записи генерируется при создании записи и не может меняться пользователем базы данных. Это может служить основой обеспечения уникальности значения поля. Для этой же цели предназначен член класса AutoNextVal, определенный как статический.
При разработке важно разделить понятие поля и записи таблицы. Класс CField позволяет описать одно поле таблицы. Список объектов CField для каждой таблицы будет определять набор полей. При этом, каждая запись (строка) таблицы (см. класс CRecord ниже) будет содержать значения соответствующие всем полям данной таблицы.
Имя поля хранится в переменной FieldName. Для задания основных параметров вывода на экран служат следующие переменные (могут меняться пользователем базы данных):
- OutputOrder – определяет порядковый номер вывода поля на экран. Порядок вывода поля на экран может не совпадать с порядком элементов в списке, т.к. первый может произвольно меняться пользователем, а второй связан с порядком данных в записях таблицы (см. класс CRecord). Таким образом, порядок следования элементов в списке полей менять нельзя;
- FieldLen – определяет ширину столбца при выводе в символах;
- Visible – определяет необходимость отображения поля (столбца) при выводе данных на экран. Например, при выводе можно не выводить идентификатор записи.
Для работы с порядком вывода полей на экран предусмотрены следующие функции:
- GetIndexByOrder –возвращает позицию элемента в списке (индекс) по порядковому номеру вывода на экран;
- SetNewOrd – меняет номер порядка вывода на экран. Для элемента с номером, указанном в первом параметре, устанавливается номер, указанный во втором параметре. Остальные номера изменяются соответственно. Например, вызов SetNewOrd(0,2) переставляет первый столбец на третью позицию;
- Add, Remove – поддерживают корректное изменение порядка вывода на экран при добавлении и удалении элементов. Данные функции должны обращаться к CSimpList::Add() и CSimpList::Remove() для реализации непосредственно добавления элементов в список.
Для доступа к элементам по позиции в списке предусмотрены следующие функции:
- operator[] – реализует обращение к элементам списка по индексу, подобно обращению к элементу массива;
- GetByOffsetIndex – защищенная функция, позволяющая получить элемент, отстоящий от текущего на указанное число позиций. Отсчет ведется только в направлении к концу списка.
Для загрузки/сохранения информации в файл предусмотрены следующие функции:
- LoadFromFile – загружает описание поля из файла;
- SaveToFile – сохраняет описание поля в файл.
Группа операторов сравнения обязана быть реализована, т.к. в противном случае класс будет считаться абстрактным. Но, поскольку порядок элементов списка связан с порядком данных в каждой записи, необходимо определить их таким образом, чтобы функция сортировки Sort() не повлияла на порядок элементов в списке. Приведенная в классе реализация задает равенство всех элементов, т.е. функция Sort() всегда будет считать список отсортированным.
Задания.
- Изучить исходный текст реализации класса: файлы CField.h, CField.cpp.
Дополнительные задания.
1. Часто имеет смысл задавать поля уникальные для таблицы и неуникальные глобально. Продумать реализацию таких полей в классе CField.
Задание 5. Запись: класс CRecord
Разработка класса, реализующего понятие записи таблицы, CRecord, полностью производится во время выполнения курсовой работы.
Опишем основные свойства класса.
Класс CRecord должен быть согласован с классом CField, т.к. каждая запись должна быть связана со списком, описывающим поля таблицы.
Для хранения данных будет использоваться массив CVariant, длина массива должна быть равна длине списка описания полей.
При заполнении каждого элемента массива должна осуществляться проверка типа соответствующего поля, и, при необходимости, производиться преобразование типов или генерироваться сообщение об ошибке.
Предположительно, класс CRecord будет отвечать за формирование текстового представления каждого поля для вывода на экран. Эта функциональность может быть перераспределена между классами по желанию разработчика.
Подобно реализации в классе CField, в классе CRecord должны быть определены функции загрузки и сохранения в файл.
Для записей особую роль играют функции поиска элемента, сортировки и выборки подмножества. Для их реализации необходимо определить операторы сравнения.
Функция Sort() в классе CSimpList определена с целочисленным параметром, значение которого задается пользователем. Этот параметр позволяет указать критерий сортировки. Например, абсолютное значение может быть равно номеру поля, по которому осуществляется сортировка, знак – направление сортировки.
Однако, функция Sort() не использует непосредственно критерий сортировки, она лишь сохраняет его в объекте с общими данными списка в поле SortCriterion. Значение должно использоваться в определении операторов сравнения. Например, если критерий сортировки равен единице, то сравниваться должны первые элементы массива с данными и т.п. Пример реализации приведен в п. 4.2 для класса CSomeList.
Задания.
- Разработать класс CRecord.
Задание 6. Таблица: класс CSimpTable
Разработаем основу класса, реализующего таблицу базы данных. Произведем класс от класса CSimpList, чтобы объединить таблицы базы данных в список.
class CSimpTable: public CSimpList
{ CField *Fields; // Список полей таблицы
// CRecord *Records; // Список записей таблицы
char TableName[32]; // Имя таблицы
public:
CSimpTable(CSimpTable *List = NULL);
~CSimpTable(void);
// Функции чтения и записи в файл:
bool LoadFromFile(CFileParser &DataFile);
bool SaveToFile(fstream &DataFile);
// В данной реализации сортировка не предполагается:
bool operator==(CSimpList &List) { return true;}
bool operator< (CSimpList &List) { return false;}
bool operator> (CSimpList &List) { return false;}
};
Обязательными компонентами класса будут указатели на списки полей и записей таблицы.
Для класса реализована минимальная функциональность: загрузка и запись в файл таблицы, содержащей только описание полей. Операции, касающиеся работы с записями не реализованы, однако ключевые места отмечены в тексте исходного кода.
Для существующей реализации будет работоспособной следующая программа:
#include <iostream>
#include "CFileParser.h"
#include "csimptable.h"
int _tmain(int argc, _TCHAR* argv[])
{ CSimpTable table; // таблица
CFileParser file("infile.txt"); // файл, содержащий базу данных
table.LoadFromFile(file); // загрузка из файла первой таблицы
fstream& outfile=file.PrepareWriting(); // настройка на запись
table.SaveToFile(outfile); // сохранение таблицы в файл
}
Файл infile.txt может иметь следующий вид:
<table>
testTable
<field ID=1 length=31 type=I>
fieldname1
</field>
<field ID=2>
fieldname2
</field>
<field ID=3>
fieldname3
</field>
</table>
При сохранении таблицы в файл данные в файле будут перезаписаны. Если бы исходно файл содержал более одной таблицы, то при выполнении приведенного кода данные по остальным таблицам в файле были бы потеряны. При вызове функции PrepareWriting() создается копия старого файла, при этом к расширению файла добавляется символ ‘~’.
Задания.
- Изучить исходный текст реализации класса: файлы CSimpTable.h, CSimpTable.cpp. Добавить необходимую функциональность.
ПРИЛОЖЕНИЕ 1. Взгляд на XML
С ростом масштабов взаимодействия вычислительных систем одним из острых вопросов встала задача разработки формата передачи данных отвечающего ряду требований, среди которых были независимость от платформы и структурное представление данных.
Одним из первых больших шагов на этом пути был стандартизованный обобщенный язык разметки данных (Standardized Generalized Markup Language - SGML), который не стал «всеобщим» стандартом в силу своей сложности и появления до того момента, когда все его возможности могли быть востребованы мировым информационным сообществом. Широкое распространение получил произведенный от него язык разметки гипертекста (HyperText Markup Language – HTML), который стал одной из основ сети интернет. Однако, HTML нельзя считать полноценным форматом представления данных, т.к. он предназначен для описания отображения информации, а не для описания данных и их структуры. Кроме того, HTML не является расширяемым – нельзя создать новый HTML-документ с набором новых тэгов (элементов разметки), т.к. это приведет к невозможности интерпретации документа при помощи интернет-браузера.
Развитием SGML стал расширяемый язык разметки (eXtensible Markup Language - XML), разработанный консорциумом по глобальным сетям (W3C – World Wide Web Consortium, [. 2]). Если попытаться сравнить XML с HTML, то первыми отличиями будут возможность определять новые элементы разметки и задавать структуру и правила создания документа, т.н. схему (schema). Фактически, язык разметки гипертекста стал задаваться схемой XML[1][1].
Полная информация по XML доступна на сайте [. 1]. Существует ряд русскоязычных ресурсов и статей по XML, например [. 3], [. 4].
Ограничимся рассмотрением простого примера XML-документа:
<?xml version="1.0"?><message><to>A.B.C.</to><toaddress>abc@mail.ru</toaddress><from>D.E.F.</from><fromaddress>def@mail.ru</fromaddress><subj>:)</subj><body>:) LOL</body></message>Данный документ является экземпляром (instance) документа, т.е. описывает готовые для «употребления» данные. Для документа, приведенного в примере, определены тэги <message>, <to> и т.п., позволяющие описать содержание электронного письма.

