




Найприроднішою для людини формою представлення, накопичення та розповсюдження знань є текст. За текстового представлення дані є неструктурованими або слабо структурованими. Такі дані становлять до 90 % обсягу електронної інформації, з якою доводиться мати справу кінцевому користувачу [57]. Обробка таких даних вимагає розв’язання різноманітних класів задач, зокрема, задач здійснення машинного перекладу та машинного реферування документів, спілкування людини із комп'ютером, синтезу мови, пошуку текстової інформації, класифікації та кластеризації документів, побудови тезаурусів, вираження семантики документів на формальній мові, прийняття рішень, генерації нових знань. Відповідно для роботи зі слабо структурованими даними у текстовому вигляді було розроблено ряд інтелектуальних ІТ: гіпертекстові інформаційні технології; технології автоматизованого анотування та реферування; технології машинного перекладу; технології автоматизованого інтелектуального пошуку та видобування знань з тексту.
Автоматизоване видобування знань з тексту є одним з найважливіших завдань та застосувань інтелектуальних технологій, актуальність якого зростає в міру збільшення обсягу накопиченої у текстовому вигляді електронної інформації. Початок сучасної теорії і практики обробки текстової інформації із орієнтацією на використання простих технічних засобів (карт з крайовою перфорацією, рахунково-перфораційних машин тощо) був покладений в 50-х рр. минулого століття. До кінця 1970-х рр. розвиток інформаційних систем ґрунтувався переважно на технологічних удосконаленнях процедур пошуку, а задачам логіко-семантичного характеру, тобто розумінню текстової інформації на природній мові, приділялося мало уваги. У 1980-х рр. стало очевидним, що подальше підвищення ефективності інформаційних систем у рамках «технологічного» етапу становлення теорії пошуку неможливе, досягнута межа за сумарним показником «повнота + точність» в розмірі до 20 % обсягу знаходження релевантних документів у випадку їх неспеціалізованості та 5–6% - у разі спеціалізованості [54]. Поява нових технічних і програмних засобів (оптичні диски, широкосмугові мережі передачі даних, програмні мультисередовища) створили підґрунтя для активізації досліджень з інтелектуалізації інформаційних систем на основі нових інформаційних технологій представлення і переробки знань. Іншою передумовою інтелектуалізації стала поява повнотекстових баз даних, які є електронними аналогами друкованих документів. Постійно зростав обсяг публікацій, які видавалися лише в машиночитальній формі без паралельного друку на папері, що дозволило знизити вартість доставки інформації споживачеві на 40 – 60 % [84].
Прагнення до підвищення ефективності інформаційних систем та існування електронних видань висунули нову мету інтелектуалізації – можливість роботи з повнотекстовими базами даних без посередників-індексаторів, зокрема обробки текстів на різних мовах з інтерфейсом на мові користувача. Комп’ютерна лінгвістика, як галузь штучного інтелекту починає активно розвиватися з 60-х років ХХ сторіччя. Об’єктом дослідження у цій галузі стає проблема розуміння тексту на природній (ПМ) чи обмежено природній мові (ОПМ), яку тлумачать як професійно-орієнтовану підмножину природної мови кінцевого користувача. Цій мові притаманна більшість обмежень природної мови, що не дає змоги переходом від ПМ до ОПМ суттєво спростити процес обробки тексту і видобування з нього знань. Специфіка текстового представлення призводить до необхідності проведення ряду аналітичних процедур для видобування з такої інформації її змісту з підтримкою цих процедур відповідними програмними засобами. Їх реалізація неможлива без моделювання, формалізації і автоматизації процесів аналізу вхідних речень тексту і синтезу вихідних текстів, генерації стратегій інформаційного пошуку і навігаційних маршрутів в гіпертексті, процесів створення і актуалізації баз даних і знань, які становлять основу інтелектуалізації. Вище перелічені інформаційні процеси вважаються інваріантними довільної інтелектуальної інформаційної системи. Моделювання інтелектуальних процесів в інформаційних системах звелося до вирішення сукупності задач і підзадач інтелектуалізації інформаційних процесів (рис. 9.3) [54].

Рис. 9.3. Моделювання інтелектуальних процесів у інтелектуальних інформаційних технологіях обробки текстів, за [54]
Моделювання даних та знань у таких системах базується на формалізації базових для лінгвістики семантичних відношень, до яких належать відношення парадигматичного підпорядкування, парадигматичної еквівалентності, або синонімії, і синтаксичного підпорядкування [59]. Парадигматичні відношення існують між словами і фразами мови незалежно від контексту і об'єднують поняття, між якими є стійкий зв'язок; синтагматичні відношення виникають в тексті, тобто між словами і словосполуками кожного конкретного речення.
Змістовно відношення парадигматичного підпорядкування відповідає родовидовому відношенню між словами і фразами мови (наприклад, фраза «інструмент для обробки отворів» і слово «свердло» парадигматично підпорядковані слову «інструмент»). Формально воно визначене як бінарне відношення рефлексії і транзитивності на множині всіх непорожніх ланцюжків в словнику мови. При цьому воно має задовольняти наступній умові: якщо деякий ланцюжок δ парадигматично підпорядкований ланцюжкам β і γ, то існує ланцюжок α, якому парадигматично підпорядковані ланцюжки β і γ [54]. На основі відношення парадигматичного підпорядкування, формально визначається поняття категорії як класу слів і словосполук, об'єднаних певними спільними ознаками. Елементами однієї і тієї ж категорії є ланцюжки (слова, синтаксичні конструкції), смислові значення яких збігаються незалежно від контексту (наприклад, «мовознавство – лінгвістика – мовознавство», «страйк – страйк»). Для таких ланцюжків введено визначення відношення парадигматичної еквівалентності, або синонімії.
При моделюванні синтаксичної структури речень основним є відношення синтаксичного підпорядкування. У природних мовах розрізняють два види такого підпорядкування – предикативність і атрибутивність. Прикладом предикативності є відношення між присудком і підметом, атрибутивності – між присудком і обставиною, підметом і визначенням. Для визначення відношення синтаксичного підпорядкування використовується спеціальна формальна граматика, що породжує проектні речення мови. Її основне призначення полягає в розпізнаванні синтаксичної структури речень при аналізі тексту і формуванні словників синтагм.
Програмні комплекси, які здійснюють у інтелектуальних системах (ІС) аналіз та тлумачення текстів на ОПМ, називають лінгвістичними трансляторами, чи лінгвістичними процесорами. У їх структурі виділяють блоки попереднього редагування, морфологічного та синтаксичного аналізів, семантичної інтерпретації та проблемного аналізу, які виконують однойменні процедури та передають їх результати блокам наступних рівнів, а також лінгвістичну базу знань.
Інформація, яку безпосередньо використовують користувачі системи, має вигляд даних. Дані можуть бути організовані у файли фактографічної, документальної та службової інформації. Фактографічна інформація представлена неформалізованими (неструктурованими або слабоструктурованими) текстами, гіпертекстами і таблицями фактографічних даних, як наперед введеними у систему, так і отриманими в результаті обробки текстових документів. Документальна інформація – це текстові і графічні документи, а також різні аудіо- та відеодані. До службової інформації відносять наявні у системі файли пошукових образів документів та описів аудіо-, відео- і табличних даних.
Лінгвістична база знань системи включає лінгвістичні синтаксичні та семантичні знання, лінгвістичні енциклопедичні знання та керуючі знання, детальніше склад яких відбито на рис. 9.4.

Рис. 9.4. Структура лінгвістичної бази знань
До складу лінгвістичних знань входять синтаксичні і семантичні дерева, словники синтагм, використовувані при синтаксичному аналізі вхідних речень, впорядковані синтаксичні дерева, двомовні словники для перекладу речень з вхідних мов на внутрішню і назад, а також словник семантичних відношень, що включає відношення синонімії і родовидове відношення.
Синтаксичне дерево речення представлене [59] орієнтованим графом звуження відношення синтаксичного підпорядкування на множину всіх слів речення (рис.9.5, а).
Семантичне дерево характеризує внутрішнє представлення вхідного речення в інформаційній системі. Вершинами семантичного дерева представлені слова внутрішньої мови, а дугами – семантичні зв'язки між ними. Кожна дуга цього дерева позначена парою семантичних ознак (рис.9.5, б). Впорядковане синтаксичне дерево аналогічно синтаксичному дереву і відрізняється від нього впорядкованістю дуг. Впорядковані дерева використовуються при синтезі вихідних речень в системі.

а) б)
Рис. 9.5. Синтаксичне (а) та отримане з нього з використанням двомовного словника семантичне (б) дерева речення «Інформаційні технології вдосконалюються швидкими темпами»
Словник синтагм включає пари слів вигляду «пароплав ® пливе», «синій горизонт», де стрілками вказаний напрямок синтаксичному зв'язку. У цих ланцюжках слова «пароплав» і «горизонт» є визначуваними членами відповідних синтагм, а слова «пливе» і «синій» – такими, що визначають [54].
Кожен запис одного з пари двомовних словників включає два поля: у першому представлений синтаксичний граф певного вхідного речення, в другому – граф синонімічного йому речення внутрішньої мови. Записами другого двомовного словника є інвертовані записи першого словника пари.
Словник семантичних відношень складається із записів, кожна з яких включає три поля: у першому міститься семантичне дерево певного речення; у другому – семантичні дерева речень, що перебувають з цим реченням у певному семантичному зв'язку; у третьому полі вказується тип цього зв'язку.
Енциклопедичні знання представлені мережею семантичних структур, що включає семантичні елементи, семантичні сцени, семантичні епізоди і семантичні сценарії [54]. Семантичний елемент – це семантичний граф (дерево), коренем якого служить слово внутрішньої мови або семантична змінна (слот), а решта всіх вершин (також слова або слоти) є суміжними кореню. Слоти семантичного елемента можуть бути заповнені словами або іншими семантичними елементами. У останньому випадку в слот семантичного елемента поміщається вершина семантичного дерева, що представляє заповнюючий семантичний елемент.
При заповненні одного чи кількох слотів семантичного елементу семантичними елементами, отримується семантична структура, яку називають семантичною сценою. Слоти семантичної сцени, своєю чергою, можуть заповнюватися семантичними елементами або сценами. Семантичний епізод – це семантична сцена, слотам якої парадигматично підпорядковані певний семантичний елемент або сцена.
Керуючі знання – це сукупності правил продукції вигляду «якщо…, то…». У позицію «якщо…» поміщаються адреси (ідентифікатори) текстів гіпертексту, які тематично передують текстам (адресам, ідентифікаторам) в позиції «то…». Ці знання необхідні для реалізації процесу навігації в гіпертексті: на їх основі моделюються і досліджуються процеси побудови навігаційних маршрутів.
Структура і порядок роботи лінгвістичного транслятора схематично представлені на рис. 9.6.
Попереднє редагування, реалізоване відповідним блоком, полягає у виділенні у вихідному тексті слів і фраз та перевірці останніх на відповідність певним закладеним у базу обмежень інтелектуальної системи обмеженням, наприклад, на відсутність складнопідрядних речень тощо.
Блок морфологічного аналізу виділяє в словах незмінні частини (основи), визначає частину мови, якою є слово, та граматичні ознаки цієї частини мови (наприклад, рід, число, відмінок, відміна для іменника, рід, число, відмінок для прикметника тощо), ідентифікує слово у словнику лінгвістичної бази ІС. Переважно такий словник містить основи слів і словоформи з їх граматичними ознаками залежно від афіксів[10] і закінчень; відповідно у ході морфологічного аналізу, який проводиться поза зв'язком з контекстом, виділяють основи та флексії[11] вихідної словоформи. За основою визначають основні характеристики даної лексеми [12], а за виглядом флексії – граматичні характеристики словоформи за словником. Застосовують два методи морфологічного аналізу – декларативний, який передбачає запис в словник всіх граматичних форм слова, та процедурний, заснований на записі в словник тільки основ слів і виділенні при аналізі власне цих основ з відкиданням афіксів і зіставленням саме основи з вмістом словника. Перший метод трудомісткіший при створенні словника, але простіший при його використанні. Загалом програмна реалізація блоку морфологічного аналізу, хоча і вимагає значних витрат часу на створення словників, породжує помітні проблеми лише у випадку порушення обмежень, передбачених базою обмежень, та за наявності омонімів[13]. Такі проблеми усуваються на етапі синтаксичного аналізу [6, 8, 73].
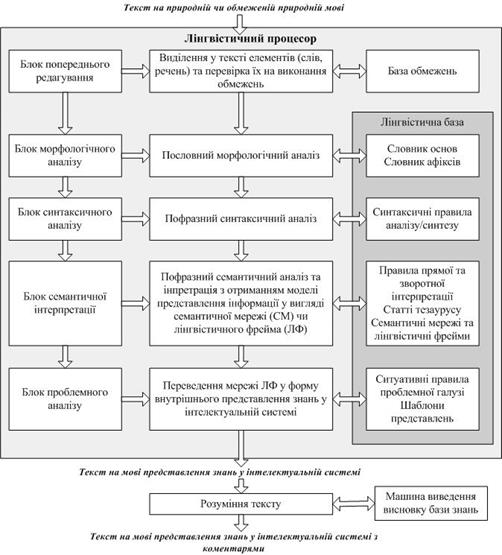
Рис. 9.6. Структурна схема лінгвістичного транслятора, за [6, 8]
Блок синтаксичного аналізу [14] будує деревоподібну модель синтаксичної структури фрагментів тексту – вихідних речень, використовуючи базу синтаксичних правил. Синтаксичні правила визначають ознаки елементів синтаксичної структури речення, наприклад: «Підмет у реченні – це або іменник в називному відмінку, або займенник в називному відмінку або ім'я власне в називному відмінку. Присудок в реченні - це дієслово, пов'язане з підметом і узгоджене із ним за числом та особою тощо». Для речення «На млин надходять різні сорти жита» результат синтаксичного аналізу матиме вигляд: «(На млин: обставина місця, 1) (надходять: присудок, 2) (різні: визначення, 3) (сорти: підмет, 4) (жита: доповнення, 5)».
Блок семантичної інтерпретації (семантичного аналізу) формує семантичне представлення кожного речення з побудовою моделі останнього у вигляді лінгвістичного фрейму (ЛФ) чи семантичної мережі для відображення відношень між об'єктами речення. Семантичний аналіз забезпечує однозначне відбиття змісту речення у відомих для інтелектуальної системи внутрішніх поняттях, відношеннях та фактах з виділенням понять «нової» декларативної інформації (елементу-наказу чи елементу-запитання для відповідних типів речень). Протягом семантичного аналізу для кожного слова, словосполучення та речення загалом визначають певні змістовні (семантичні) характеристики; семантичну неоднозначність знімають за допомогою взаємопов’язаних у межах семантичної мережі статей тезаурусу. Аналіз відношень у цій мережі дає змогу отримати необхідну для адекватного розуміння фрази інформацію, відсутню у фразі в явному вигляді. Складності, що виникають внаслідок семантичної неоднозначності, знімаються завдяки виділенню додаткових зв'язків поміж групами іменників, використанню певних евристичних правил усунення неоднозначності самих зв'язків (принципи близькості, пріоритетності предикату тощо) та зверненню до пов’язаних у семантичну мережу статей тезаурусу бази знань інтелектуальної системи.
Семантичний аналіз дає змогу проводити контекстно-вільний пошук документів за запитом у вигляді слова чи фрази у великих документальних базах, хоча більшість сьогодні існуючих систем ґрунтується виключно на морфологічному аналізі слів і не залучає складніших схем аналізу
Результат семантичної інтерпретації надходить в блок проблемного аналізу, що здійснює переведення аналізованого тексту у формі мережі лінгвістичних фреймів у внутрішнє представлення знань в інтелектуальній системі у вигляді семантичної мережі проблемних фреймів. Зміст тексту на природній мові відбивається у фрагмент семантичної мережі, зв'язаний дугами відповідного типу із тією семантичною мережею, яка вже зберігається в системі. Для кожної предметної області розробляють власну базу знань, що містить абстрактну мережу проблемних фреймів. «Верхні рівні» проблемних фреймів фіксовані і містять факти, завжди істинні в передбачуваній ситуації. Нижні рівні містять багато «комірок», які треба заповнити конкретними даними відповідно до перерахованих у комірці умов, яким значення цих даних мають задовольняти. Наприклад, при аналізі зорових сцен різні фрейми в системі відповідають різним точкам зору на неї, а переходи від одного фрейму до іншого відбивають ефект переміщення спостерігача з одного місця до іншого.
Внутрішнє представлення служить основою для реалізації феномену розуміння природно-мовного тексту на тому або іншому рівні. Основні проблеми пов'язані тут з розумінням тексту на вищих рівнях. Загалом розрізняють п'ять рівнів розуміння. На першому, найпримітивнішому рівні всі відомості щодо змісту тексту отримують у результаті його аналізу без залучення додаткових знань, відомих системі. На другому рівні за допомогою процедур логічного поповнення інформації довизначають часову, просторову і причинно-наслідкової структуру подій; на третьому додають відому системі інформацію, релевантну сформованому змісту тексту. На четвертому рівні до сформованого представлення змісту тексту приєднують відомості, що витягують з бази знань інтелектуальної системи, які пов'язані з аналізованим текстом лише стосунками асоціації. На п'ятому рівні розуміння з аналізованого тексту видобувається його прагматичний зміст. При цьому інтелектуальна система виконує всі обумовлені ним дії, наприклад, вирішує задачу, дані для якої відбиті вихідним текстом, за допомогою певної готової або генерованої програми.
Лінгвістичні транслятори є необхідною частиною всіх інтелектуальних систем, у яких передбачена інтелектуальна обробка текстової інформації, і активно використовуються для розв’язання задач пошуку інформації та видобування знань, класифікування та кластеризації документів, побудови тезаурусів, автоматизованого анотування, реферування та машинного перекладу.

