




Современные методы обработки результатов наблюдений
При измерениях
При обработке результатов наблюдений, прежде всего, используют основные уравнения измерений вида (1.1 – 1.4):
Прямые измерения Q=сХ, (1.1)
где с - заданный коэффициент.
Косвенные Величина Q является известной функцией от непосредственно измеряемых аргументов Х1, Х2, …, Хm: Q =f(Х1, Х2, …, Хm) (1.2)
При совместных измерениях находят функциональную зависимость Y=f(X) между (переменными) физическими величинами X и Y, путем измерений ряда значений Х1, …, Хm и соответствующих им величин Y1, …, Ym:
Yi=f(Xi) (1.3)
При совокупных измерениях значения набора одноименных величин Q1, …, Qm находят, как правило, путем измерений сумм или разностей этих величин в различных сочетаниях. Уравнения измерений имеют вид:
 (1.4)
(1.4)
где коэффициенты сij принимают значения ±1 или 0.
Однако, если попытаться непосредственно подставить полученные экспериментальные данные в эти уравнения, то получится несовместная система. Это обусловлено тем, что уравнения измерений связывают истинные значения величин, а полученные результаты наблюдений неизбежно содержат погрешности. Поэтому для нахождения искомого результата измерения уравнения (1.1 -1.4) необходимо дополнить выражениями для результатов наблюдений.
Например, при прямых измерениях с многократными наблюдениями (когда Q=X) результаты наблюдений х1, …, хn можно представить в виде:
хi=Q+ζ(xi), i=1…n, (1)
где ζ(xi) - погрешности наблюдений.
По этим данным необходимо найти приближенное значение  , близкое к истинному значению Q, и оценить его погрешность ζ()= -Q. В зависимости от предположений относительно погрешностей и критерия качества оценки, могут быть использованы различные оценки . В частности, если погрешности наблюдений ζ(xi) являются случайными, то задача сводится к классической задаче статистики — оценить среднее значение Q по выборке х1, …, хn вида (1). Как правило, присутствуют также систематические погрешности, которые необходимо учитывать и оценивать.
, близкое к истинному значению Q, и оценить его погрешность ζ()= -Q. В зависимости от предположений относительно погрешностей и критерия качества оценки, могут быть использованы различные оценки . В частности, если погрешности наблюдений ζ(xi) являются случайными, то задача сводится к классической задаче статистики — оценить среднее значение Q по выборке х1, …, хn вида (1). Как правило, присутствуют также систематические погрешности, которые необходимо учитывать и оценивать.
Отметим, что из полученной системы (1) необходимо найти только результат измерения и оценить характеристики (например, СКО) его погрешности.
Аналогично формируются системы уравнений для других категорий измерений. При косвенных измерениях уравнение (1.2) следует дополнить выражениями для результатов наблюдений аргументов:
xi=Xi+ζ(xi) (2)
yi=Yi+ζ(yi) (3)
При совокупных или совместных измерениях — к уравнениям (1.3) или (1.4) добавляют соотношения (3). Если также измеряют значения Xi, то добавляют соотношения (2).
После того, как сформирована система уравнений, для определения результата измерения может быть использовано несколько алгоритмов вычислений, в зависимости от предположений относительно погрешностей наблюдений и критерия качества оценки . Алгоритм обработки данных представляет собой последовательность алгебраических и логических операций, в результате применения которых к экспериментальным данным xi, yi,… будет получен искомый результат измерения и характеристики его погрешности.
Многочисленные и разнообразные алгоритмы обработки данных можно разделить на группы по нескольким признакам. Прежде всего, по виду исходной системы уравнений они делятся на группы, соответствующие прямым, косвенным, совместным и совокупным измерениям. Математическую основу для них составляют различные статистические методы. В частности, при прямых измерениях используют методы оценивания среднего значения по выборке, а при косвенных — кроме того, методы приближения функций. При совместных и совокупных измерениях используют, прежде всего, метод наименьших квадратов.
Методы обработки данных также можно разделить согласно видам моделей, используемых для описания погрешностей. Наиболее многочисленными являются статистические методы, основанные на моделях погрешностей как случайных величин. Среди статистических методов, в свою очередь, выделяются классические параметрические методы, непараметрические методы и современные устойчивые методы.
Важным признаком классификации методов обработки является также критерий качества оценки и способ его использования при построении алгоритма. Прежде всего, выделяются методы, которые оптимальны согласно определенному критерию в рамках точной математической модели данных. Однако для них требуется значительная априорная информация; например, что случайные погрешности имеют гауссовское распределение. Типичными являются алгоритм усреднения данных и метод наименьших квадратов. Если погрешности результатов наблюдений имеют гауссовские распределения, то эти методы являются оптимальными: первый - для прямых, второй - для совместных измерений. Их можно использовать и в более широком круге задач, не вводя требования гауссовского распределения. При этом они весьма удобны в вычислительном плане, хотя и не всегда высоко эффективны. К сожалению, формальное отбрасывание ограничений в оптимальном методе часто приводит к неустойчивости, мало эффективному методу. Целесообразно так модифицировать оптимальный метод, чтобы он оставался эффективным для широкого круга случаев; именно это достигается в современных устойчивых (робастных) методах.
Наконец, обширную группу образуют так называемые эвристические методы, которые не имеют формального обоснования. Обычно они просты и устойчивы по отношению к помехам и отклонениям от моделей; поэтому их часто используют на начальном этапе обработки, чтобы получить исходные приближения для применения более сложных и точных методов. Однако они менее точны и для них труднее оценивать точность получаемых результатов.
Кроме статистических методов, при обработке данных используют численные методы, необходимые для преобразований исходных соотношений, а также для численной реализации статистических методов.
Обработка данных при прямых измерениях с однократными наблюдениями
Прямые измерения с однократными наблюдениями являются наиболее распространенными на производстве и в научных исследованиях. Если выполняется одно только наблюдение, то за результат измерения принимают единственное полученное значение. С целью дополнительного контроля отсутствия промахов и грубых погрешностей часто выполняют 2—3 наблюдения; тогда за результат измерения принимают среднее арифметическое их результатов. Таким образом, получение результата измерения в этом случае очевидно.
Обработка данных сводится, главным образом, к оцениванию погрешности измерения на основе априорной информации, роль которой в этом случае особенно велика. Она существенно различается для трех групп измерений в соответствии со степенью полноты априорной информации.
Изложим более подробно оценивание погрешностей технических измерений. При этом погрешности оценивают априорно на основе нормативных данных о свойствах используемых средств измерений и с учетом возможных значений влияющих величин; для этого необходимо также определить диапазон возможных значений измеряемой величины.
Погрешность измерения представляется в виде суммы составляющих (ζ(Q)= ζм + ζи + ζл, (1.7)
где ζм — методическая погрешность, ζи — инструментальная погрешность, ζл — личная погрешность); при этом каждая из них может содержать систематические и случайные составляющие. Инструментальная погрешность ζи складывается из основных ζ0i и дополнительных ζij погрешностей используемых средств измерений (i=l,..., n — номера средств измерений, j — номера влияющих величин).
Характеристики основных погрешностей содержатся в технической документации на средства измерений. Дополнительные погрешности оценивают на основе характеристик, приведенных в документации, и заданных диапазонов возможных значений влияющих величин.
Кроме того, при выполнении измерений в динамическом режиме необходимо учитывать также динамические погрешности. Для их оценивания необходимо знать динамические характеристики средств измерений (которые должны быть указаны в технической документации), а также свойства (в простейшем случае — частотные) входных сигналов.
Анализ и оценивание методической погрешности ζм выполняется при разработке методики выполнения измерения.
После того, как получены границы для отдельных составляющих, необходимо выполнить их суммирование и найти границы общей погрешности.
Подчеркнем, что при априорном оценивании приходится рассчитывать погрешность в наименее благоприятной точке диапазона возможных значений измеряемой величины. При этом, если есть информация о возможном распределении измеряемых величин, можно ее использовать чтобы дать не столь завышенную оценку погрешности.
Наиболее тщательно, очевидно, выполняют оценивание погрешности при апостериорном оценивании с учетом индивидуальных свойств средств измерений и значений влияющих величин. Данный случай выделяется тем, что можно вычислить поправки на некоторые систематические погрешности и внести их в результат измерения (тем самым, повысив точность результата измерения). Здесь также используется исходное разложение (1.7); поэтому вносимая поправка имеет вид:

где  - оценки систематических составляющих;
- оценки систематических составляющих;

После введения поправки погрешность исправленного результата  =х+с имеет вид
=х+с имеет вид
ξ= ξМ + ξИ + ξЛ (8)
где ξМ = ζМ - ΰМ - обусловлена неточностью оценивания методической погрешности;  - обусловлена погрешностью поверки (аттестации) средства измерений, случайной составляющей основной погрешности средства измерений, неточностью определения функций влияния и погрешностями измерений влияющих величин;
- обусловлена погрешностью поверки (аттестации) средства измерений, случайной составляющей основной погрешности средства измерений, неточностью определения функций влияния и погрешностями измерений влияющих величин;
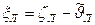 - обусловлена неточностью оценивания личной погрешности.
- обусловлена неточностью оценивания личной погрешности.
В выражении (8) каждое слагаемое состоит из ряда составляющих, при этом систематические составляющие обычно характеризуют границами, а случайные - СКО. В итоге основная задача сводится к суммированию составляющих и нахождению границ погрешности (8).
Измерения с приближенным апостериорным оцениванием погрешностей составляют, в некотором смысле, промежуточную группу в отношении оценивания погрешностей. Обработку данных выполняют на основе априорных сведений об условиях измерений и методических погрешностях, а также взятых из документации сведений о метрологических характеристиках средств измерений. Кроме того, иногда приближенно оценивают (но не измеряют) наиболее существенные влияющие величины. Отметим, что в данном случае нельзя внести поправку в результат измерения; можно лишь оценить его погрешность. Однако при апостериорном оценивании все же известен результат измерения, а также более определенные границы значений влияющих величин, поэтому можно получить уточненные оценки погрешностей (по сравнению с априорным оцениванием).
Пример. Выполнено однократное измерение напряжения U на участке электрической цепи сопротивлением R=(10±0,1) Ом с помощью вольтметра класса 0,5 по ГОСТ 8711—78 (верхний предел диапазона 1,5 В, приведенная погрешность 0,5%). Показание вольтметра 0,975 В. Измерение выполнено при температуре примерно 25° С, при возможном магнитном поле, имеющем напряженность до 300 А/м.
Методическая погрешность измерения определяется соотношением между сопротивлением участка цепи R и сопротивлением вольтметра RV = 900 Ом (которое известно с погрешностью 1%). Показание вольтметра свидетельствует о падении напряжения на вольтметре, определяемом как
UV= URV / (R + RV) ≈ 0,975 В;
поэтому методическая погрешность здесь равна
ζМ = UV - U = - UR/(R + RV)≈ 0,011B
После введения поправки получим:
 0,975+0,011 = 0,986 В.
0,975+0,011 = 0,986 В.
Неисключенная методическая погрешность (т. е. погрешность определения поправки) определяется погрешностями измерений сопротивлений цепи и вольтметра, которые имеют границы 1%. Поэтому погрешность поправки оценивается границами 0,04%, т. е. пренебрежимо мала.
Инструментальная составляющая погрешности определяется основной и дополнительной погрешностями. Основная погрешность оценивается по приведенной погрешности и результату измерения:

Дополнительная погрешность от влияния магнитного поля лежит в границах θн=±0,5%. Дополнительная температурная погрешность, обусловленная отклонением температуры на 5°С (от нормальной 20°С), лежит в границах θТ=±0,5%. Доверительные границы инструментальной погрешности (при Р=0,95) находят по формуле θо  .
.
В абсолютной форме граница θ = 0,011 В. После округления результат принимает вид: U = (0,99±0,01) В; Р = 0,95.

