




Цель работы
Освоить метод построения кодов дискретного источника информации используя конструктивный метод, предложенный К.Шенноном и Н.Фано. На примере показать однозначность раскодирования имеющегося сообщения. Освоить метод построения кодов дискретного источника информации используя методику Д.Хаффмана.
Кодирование дискретных источников информации методом Шеннона-Фано.
Основные положения
Уменьшения количества символов, используемых для передачи сообщения по каналу связи, позволяет повысить скорость передачи за счет отсутствия необходимости передачи избыточной информации. Для передачи и хранения информации, используется двоичное кодирование. Сообщения передаются в виде различных комбинаций двух сигналов 0 и 1. Если алфавит A состоит из N символов, то для их двоичного кодирования необходимо слово разрядностью n, которая определяется по формуле
n = élog2 Nù.
Это справедливо при использовании стандартных кодовых таблиц обеспечивающих кодирование до 256 символов. Помимо стандартных можно использовать нестандартные кодовые таблицы, где количество символов меньше, чем в стандартных таблицах. Это обеспечивает сжатие информации. Например, необходимо передать сообщение из 50 символов кириллицы, цифр и символов разделителей. Мы можем воспользоваться следующими способами кодирования:
1. Кодировать каждый символ в соответствии со стандартной кодовой таблицей, по которой каждый символ будет представляться 8 битовым кодовым словом, n1 = 8;
2. Составить и использовать отдельную кодовую таблицу, не учитывающую возможность кодирования символов, которые не входят в сообщение. Тогда необходимый размер кодового слова будет
n2 =élog2 Nù== é log2 50ù=6.
Использование такого кода будет более эффективно, т.к. будет требовать меньшего количества бинарных сигналов при кодировании.
3. Использовать специальный код со словом переменной длины. В этом случае символы, появляющиеся в тексте чаще, получат короткие кодовые комбинации, а те, что реже - длинные кодовые комбинации. Такое кодирование называется эффективным.
Эффективное кодирование базируется на теореме Шеннона, в которой доказано, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины.
Из теоремы следует, что при выборе каждого символа кодовой комбинации необходимо сделать так, чтобы он нес максимальную информацию. Каждый элементарный сигнал должен принимать значения 0 и 1. При отсутствии статистической взаимосвязи между кодируемыми символами конструктивные методы построения эффективных кодов были даны впервые К.Шенноном и Н.Фано. Их методики существенно не различаются, поэтому соответствующий код получил название кода Шеннона-Фано.
Код строится следующим образом: буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним — 0. Каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Рассмотрим алфавит из 50 букв. При обычном кодировании для представления каждой буквы требуется n2 =6 символов. В таблице 1 приведен один из возможных вариантов кодирования по сформулированному выше правилу.

Таблица 1
Для указанных вероятностей можно выбрать другое разбиение на подмножества не нарушая алгоритма Шеннона-Фано (Табл. 2).
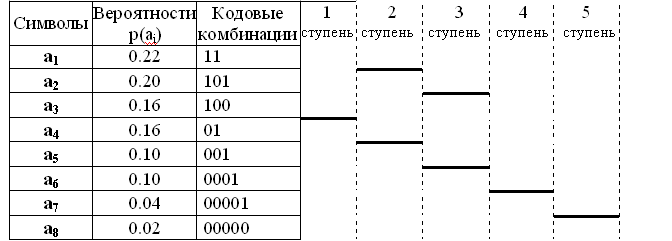
Таблица 2
Если сравнить приведенные таблицы то видно, что по эффективности полученные коды различны. В таблице №2 менее вероятный символ a4 будет закодирован двухразрядным двоичным числом, в то время как a2, вероятность появления которого в сообщении выше, кодируется трехразрядным числом. Рассмотренный алгоритм Шеннона-Фано не всегда приводит к однозначному построению кода: при разбиении на подгруппы можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппу.
Энтропия набора символов в рассматриваемом случае определяется как

Можно вычислить среднее количество двоичных разрядов, используемых при кодировании символов по алгоритму Шеннона-Фано

где: A — размер (или объем) алфавита, используемого для передачи сообщения;
n(ai) — число двоичных разрядов в кодовой комбинации, соответствующей символу ai.
Так мы получим для табл.1 Iср = 4,510152, что ≈ H50 = 4,416280. Они почти одинаковые.
Пример декодирования сообщения
Рассмотрим пример сообщения, созданного из имеющихся символов. Пусть передано сообщение «Она ела дома».
При кодировании, используя табл.1 получим следующую последовательность:
Получив сообщение подобного вида, необходимо её декодировать, чтобы прочитать сообщение. Допустим получатель имеет таблицу кодировки символов идентичную с отправителем.
Возможный способ декодирования представлен на таблице №3:

Таблица 3
Декодирование производиться с наименьшей длины кодового слова — в нашем случае — 3, — получается таблица, с итоговым результатом, который аналогичен закодированному.

