




Задача детектирования заключается в следующем: необходимо найти на изображении все объекты заданных классов и вычислить их положение в координатах пикселей данного изображения.
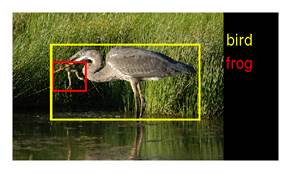

рис.4 Пример работы детектора
Большинство возможных решений задачи детектирования объектов состоят из 3 этапов:
1) Сгенерировать по изображению прямоугольники, в которых возможно будут находиться объекты [35] [36] [37].
2) Классифицировать объекты в найденных прямоугольниках.
3) Агрегировать полученную информацию и выделить наиболее значимые результаты.
Обзор существующих подходов к задаче
В качестве известных подходов к задаче детектирования рассматриваются:
1) R-CNN [20],
2) Multi-Box [21],
3) Fast R-CNN [22].
Все подходы основываются на применении глубоких сверточных нейронных сетей. Наиболее чаще встречающиеся архитектуры нейронных сетей: GoogLeNet [23], Network in Network [24], AlexNet [8].
R-CNN подход
R-CNN подход был предложен Ross Girshick в 2012 году [20]. Суть данного подхода заключается в следующем:
· На первом этапе используется алгоритм генерации возможных объектов-кандидатов Selective Search [25]
· С помощью глубокой нейронной сети для каждого из кандидатов извлекаются высокоуровневые признаки (выходы с последних сверточных слоев)
· Затем тренируется N классификаторов, используя машину опорных векторов (Support Vector Machine).
· После классификации всех окон-кандидатов результаты уточняются в том смысле, что если некоторые окна перекрываются и при этом классы объектов внутри окон совпадают, то они заменяются одним усредненным окном.
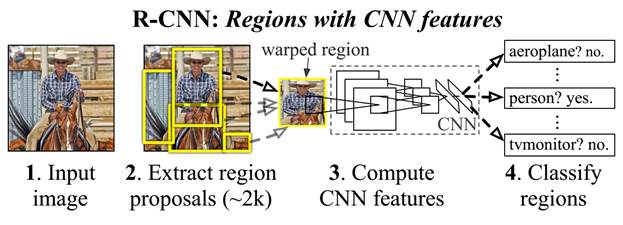
рис.5. R-CNN детектор
Главный недостаток данного метода заключается в том, что для каждого окна-кандидата необходимо делать прямой проход сети, что занимает значительное время, учитывая, что в среднем для 1 картинки алгоритм Selective Search возвращает 2 000 окон-кандидатов.
Multi-Box подход
Multi-Box подход был предложен в 2013 году исследователями из компании Google: Dumitru Erhan, Christian Szegedy, Alexander Toshev и Dragomir Anguelov. [21] [26]
Суть данного метода заключается в том, что вместо Selective Search алгоритма используется нейронная сеть, которая должна возвращать координаты окон-кандидатов и значение c ϵ [0,1], которое интерпретируется как вероятность того, что в окне содержится какой-либо объект (любой из заданных категорий).
Для создания полноценного детектора затем используется нейронная сеть GoogLeNet, показавшая отличные результаты в задаче классификации [23].
Данный подход работает значительно быстрее, чем R-CNN, но требует значительных инженерных усилий в реализации.
Fast R-CNN подход
Данный метод был предложен в 2015 году Ross Girshick [22]. По большому счету, данный подход является преемником обычного R-CNN. Основное достоинство этого метода заключается в том, что в сравнении с R-CNN удалось достичь значительного ускорения в тестовом режиме. Данный успех обусловлен тем, что вместо множественных проходов по сети (для каждого окна-кандидата), делается всего 1 проход [27].
Аналогично подходу Multi-Box сеть пытается получить на выходе координаты окаймляющего прямоугольника и значение вероятности. Но также имеется существенное различие между данными подходами. Если в Multi-Box подходе c ϵ [0,1] – вероятность того, что внутри прямоугольника находится какой-то из существующих классов, то в данном методе c ϵ [0,1] вычисляется для каждого их классов.
Скорость обучения Fast – RCNN для PASCAL VOC 2012 по сравнению с обычным R-CNN возросла ~ 9x раз. Скорость работы детектора в тестовом режиме возросла примерно в 213 раз.
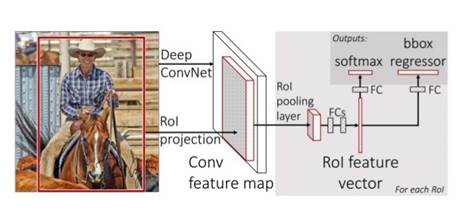
рис.6 Fast R-CNN
По сравнению двумя первыми перечисленными детекторами данный подход был применен только к базе данных PASCAL VOC 2012 & PASCAL VOC 2007 с 20 категориями объектов.
Главная цель настоящей работы заключается в адаптации данного метода для базы данных ImageNet 2014. Адаптация включает: выбор по возможности наилучшего количества слоев, типов функций активации, параметров оптимизационного алгоритма и т.д. Напрямую данный подход не может быть использован, в частности, потому, что количество классов в ImageNet & PASCAL VOC существенно различается (200 и 20 соответственно).
Обзор наборов данных
ImageNet 2014
ImageNet – наиболее известное соревнование в области компьютерного зрения [28] [39]. Набор данных включает в себя 200 категорий объектов среди 516840 изображений. 60658 изображений были собраны с сервиса Flickr. Изображения подобраны с учетом множества различных факторов, таких как размер объекта на изображении, уровень шума и др. Некоторые изображения не содержат объекты ни одной из 200 категорий.
Таблица 1. Описание базы данных ImageNet 2014
| Вид выборки | Количество изображений |
| ImageNet2014 train | |
| ImageNet2014 validation | |
| ImageNet2014 test |

рис.7 Изображение из выборки ImageNet 2014

рис.8 Изображение из выборки ImageNet 2014
Pascal VOC 2012
База данных Pascal VOC 2012 [29]. Выборка включается в себя 20 категорий объектов. Всего содержит 22531 изображения.
Таблица 2. Описание базы данных Pascal VOC 2012
| Вид выборки | Количество изображений |
| PASCAL VOC 2012 train | |
| PASCAL VOC 2012 validation | |
| PASCAL VOC 2012 test |


рис.9 Изображение из PASCAL VOC 2012
Используемые инструменты
Для реализации поставленной задачи были использованы следующие инструменты:
1) Caffe
2) C++
3) Python
4) Matlab R2014b
5) QT Creator
Caffe [30] – известная open-source (BSD-2) библиотека глубинного обучения. Caffe разрабатывается и поддерживается BVLC (Berkeley Vision and Learning Center), написан на языке С++ в 2013 году, также имеет обертки для использования из Python, atlab. бертки для использования из спользовался известный фреймворк глубинного обучения Matlab.
Преимущества Caffe над другими фреймворками:
1) Удобная архитектура
2) Повторное использование натренированных моделей
3) Быстрая реализация алгоритмов тренировки с помощью технологии CUDA
4) Поддержка со стороны сообщества и разработчиков
Caffe позволяет создавать многослойные нейронные сети состоящие из следующих основных слоев:
· CONVOLUTION – базовый сверточный слой. Обязательными параметрами являются количество фильтров, и размер ядра (высота и ширина каждого из фильтров). Дополнительными параметрами задаются начальная инициализация весов, сдвиг для каждого из фильтров, параметры дополнения изображения.
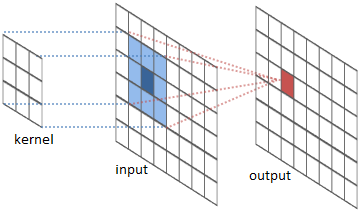
Рис. 10 Свертка
· POOLING – cубдискретизирующий слой или слой подвыборки, уменьшающий размерность карт признаков.

Рис. 11 Субдескритизация
· INNER PRODUCT – полносвязный слой, в котором каждый нейрон текущего слоя соединен с каждым нейроном из предыдущего слоя.
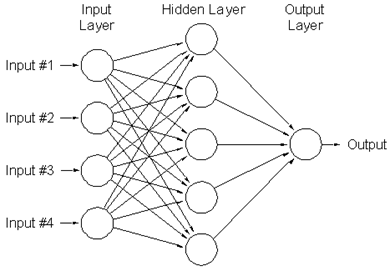
Рис. 12 Полносвязный слой
· ReLU – Rectified-Linear Unit (активационный слой).
Функция активации данного слоя:
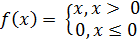
· TANH – гиперболический тангенс (активационный слой).
Функция активации данного слоя:
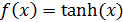
· SIGMOID – логистическая функция активации.
Функция активации данного слоя:
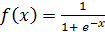
· EUCLIDEAN LOSS – квадратичная функция потерь.
Реализация квадратичной функции потерь:
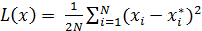
· SIGMOID CROSS-ENTROPY LOSS

· ACCURACY – чаще всего используется в классификации. Считает точность как отношение правильно классифицированных объектов к числу всех объектов в выборке.
· SOFTMAX – активационный слой. Иногда может быть использован для приведения данных к промежутку [0,1].
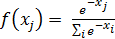
· LOCAL RESPONSE NORMALIZATION – локально нормализующий слой.
Значения каждого пикселя из локальной окрестности преобразуются следующим образом:
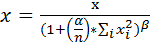
· DROPOUT – слой регуляризации. Значение, заданное параметром d (обычно 0.4, 0.5), используется для игнорирования на стадии тренировки количества связей INNER PRODUCT слоя.
Caffe также позволяет использовать другие слои, так как модульная архитектура самого фреймворка рассчитана на то, что каждый исследователь может дописать нестандартные слои нейронных сетей и легко подключить их к уже доступным.
В качестве алгоритмов оптимизации разработчики Caffe предлагают:
1) Стохастический градиентный спуск [31],
2) Градиентный спуск Нестерова [32] [34],
3) Адаптивный градиентный спуск [33].

