




Классификацию современных СУБД можно выполнить по различным признакам.
По назначению различают три основных вида СУБД: промышленные универсального назначения, промышленные специального назначения и разрабатываемые для конкретного заказчика. Специализированные СУБД создаются для управления БД конкретного назначения — бухгалтерские, складские и т.д. Универсальные СУБД не имеют четко обозначенных границ применения, рассчитаны на произвольные задачи. Поэтому они достаточно сложны и требуют от пользователя специальных знаний.
По размещению отдельных частей БД различают локальные и сетевые СУБД.
Все части локальных СУБД размещены на одном компьютере. Если с локальной БД должны работать несколько пользователей одновременно, то на их компьютерах должны храниться точные копии этой БД. Существенной проблемой при этом является синхронизация копий данных. Если один пользователь внес изменения в свою копию БД, то они станут доступными на других компьютерах только после их копирования. Сегодня применение локальных БД ограничено.
Сетевые СУБД делятся на файл-серверные, клиент-серверные и распределенные. Обязательным атрибутом сетевых СУБД является сеть, обеспечивающая аппаратную и программную связь компьютеров и позволяющая корпоративно работать множеству пользователей с одними и теми же данными.
В файл-серверных СУБД данные размещаются на одном достаточно мощном компьютере, постоянно подключенном к сети. Такой компьютер называется файл-сервером. Достоинством такой СУБД является относительная простота ее создания, обслуживания и настройки. Заметим, что между локальной и файл-серверной СУБД практически нет различий, т.к. все фрагменты программного обеспечения СУБД (за исключением данных) находятся на всех компьютерах сети. Отличие между ними состоит в том, что программы обращаются к данным через сеть. Для многих вариантов архитектуры сети на уровне прикладного программного обеспечения это различие «скрыто» от программиста. Из этого вытекает основной недостаток файл-серверных СУБД. Он связан со значительной нагрузкой на сеть, т.к. любое обращение к данным, их корректировка вызывает пересылку значительных объемов информации по сети. Например, если пользователю требуется выбрать несколько фамилий из списка персонала по определенному признаку, то на его компьютер вначале пересылается весь список, и затем поиск производится на пользовательском компьютере. При увеличении числа пользователей СУБД пропускной способности сети становится недостаточно для объемов пересылаемой информации, что приводит к существенному замедлению скорости работы, а иногда и к системным сбоям.
В клиент-серверных БД нагрузка на сеть существенно снижена. Клиентская программа работает с данными через специализированное программное обеспечение (посредника) – сервер базы данных. Сервер размещается на машине с данными. Клиентская программа посылает серверу запрос, сервер принимает его, отыскивает в данных нужные записи и передает их клиенту. Поэтому через сеть передаются только сравнительно короткие запросы и только ограниченное количество найденных записей, а не вся таблица. Запрос к серверу формируется на специализированном языке структурированных запросов — SQL. Поэтому часто серверы БД называют SQL-серверами. Серверные программы являются достаточно сложными, производятся различными фирмами.
Разновидностью клиент-серверных БД являются трехзвенные системы. В них используется промежуточное программное обеспечение между клиентом и сервером, которое называется сервером приложений. Назначение сервера приложений состоит в том, чтобы избавить клиента от многих рутинных аспектов работы с данными, в результате клиентские программы становятся более компактными и содержат в основном код смысловой обработки данных (такие клиентские программы называют тонкие клиенты).
Распределенные БД включают большое количество серверов, а число клиентских мест может достигать сотен тысяч. Обычно такие БД работают в организациях государственного масштаба, данные разделены между серверными компьютерами по территориальному признаку. Информация на отдельных серверах может дублироваться для снижения вероятности отказов и сбоев и максимального обеспечения сохранности наиболее важной информации.
Задание 3
Описание структуры базы данных о работниках универсама
| Столбец | Наименование поля | Тип данных |
| A | Фамилия | Текстовый |
| B | Имя | Текстовый |
| C | Отчество | Текстовый |
| D | Пол | Текстовый |
| E | Дата рождения | Дата/время |
| F | Должность | Текстовый |
| G | Оклад | Денежный |
| H | Семейное положение | Текстовый |
| I | Количество детей | Числовой |
Диапазон ячеек, занимаемых БД – A1:I80.
Число полей в БД -9
Число записей в БД -80
Задание 4
Проведем двухуровневую сортировку по критериям, рисунок 1.
| Критерии сортировки | |
| Первичный | Вторичный |
| По алфавиту наименований должностей | Вначале женщины, а затем мужчины |
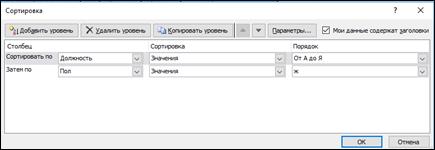 |
Рисунок 1 - Двухуровневая сортировка
Итоговый фрагмент сортировки представлен на рисунке 2.
 |
Рисунок 2- Фрагмент сортировки
Задание 5
Используя операцию автофильтра, проведем выборку записей из БД согласно приведенным критериям фильтрации.
| Критерии фильтрации |
| Имеющие отчества «Александрович» или «Александровна» |
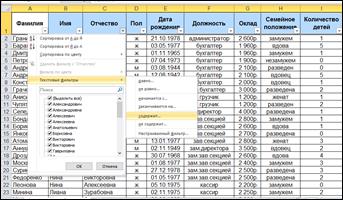 |
Выбираем операцию настройки текстового фильтра по полю Отчество, рисунок 3.
Рисунок 3- Настройка автофильтра
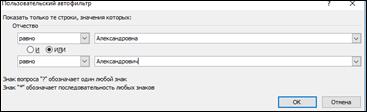 |
Настраиваем пользовательский автофильтр для отбора нужных полей, рисунок 4.
Рисунок 4-Ввод критерий отбора
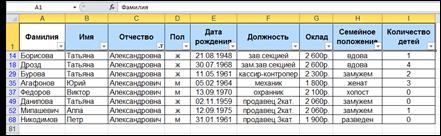 |
Итоговая выборка представлена на рисунке 5.
Рисунок 5-Итоговая выборка
Задание 6
Используя многошаговую операцию автофильтра, провести выборку записей из БД согласно приведенным критериям фильтрации:
| Критерии фильтрации |
| Вдовы и вдовцы с окладом ниже 2500 р. |
 |
Настаиваем первое условие, рисунок 6.
Рисунок 6 -Первое условие критерия
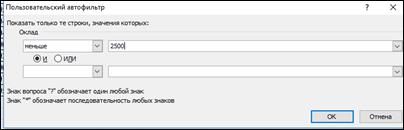 |
Настаиваем второе условие, рисунок 7
Рисунок 7- Настройка второго условия критерия
Итоговая выборка представлена на рисунке 8.
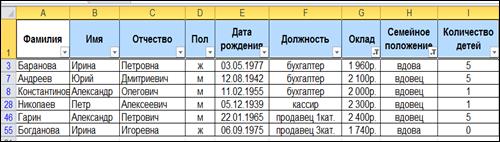 |
Рисунок 8- Итоговая выборка
Задание 7
Используя операцию расширенного фильтра, выполним одношаговую фильтрацию согласно критериям:
| Критерии фильтрации |
| Вдовы и вдовцы с окладом ниже 2500 р. |
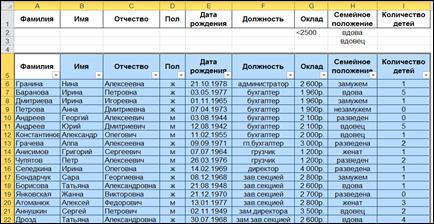 |
Резервируем диапазона ячеек для размещения блока критериев посредством вставки четырех строк над таблицей исходной БД, рисунок 9.
Рисунок 9- Настройка блока критерия
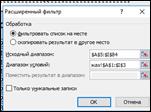 |
Заполняем окно Расширенного фильтра, рисунок 10.
Рисунок 10- Заполнение окна Расширенного фильтра
 |
Итоговая выборка представлена на рисунке 11.
Рисунок 11- Итоговая выборка
Задание 8
Реализуем запрос к БД, используя функции категории Работа с базой данных.
| Запрос к базе данных |
| Общее количество детей у разведенных |
Заполняем блок критерия, рисунок 12.
 |
Рисунок 12- Настройка критерия
Вводим функцию для расчета Общего количества детей у разведенных, рисунок 13.
 |
Рисунок 13-Ввод функции
 |
Заполняем аргументы функции, рисунок 14.
Рисунок 14-Аргументы функции
Итоговый подсчет значений представлен на рисунке 15.
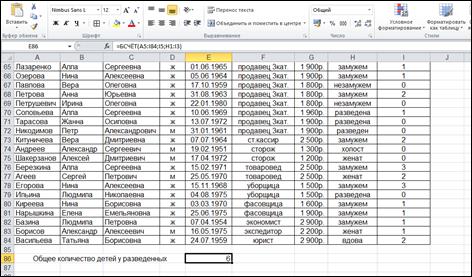 |
Рисунок 15- Итоговый подсчет
Задание 9
Реализовать перекрестный запрос к БД, используя операцию построения сводной таблицы.
| Запрос к БД |
| Средний оклад работников для различных групп семейного положения отдельно для женщин и мужчин |
Создаем сводную таблицу на новом листе и настраиваем, рисунок 16.
 |
Рисунок 16-Настройка списка полей
 |
Итоговый вид перекрестного запроса представлен на рисунке 17.
Рисунок 17-Итоговый вид запроса
Используемые источники
1. Губкина Г. Е., Смирнова И. И. Использование табличных процессов в экономических и финансовых расчетах: Учебное пособие. – СПб.: ТЭИ, 2007.
2. Информатика: Практикум по технологии работы на компьютере / Под ред. проф. Н. В. Макаровой. – М.: Финансы и статистика, 2009.
3. Информационные системы [Электронный ресурс] http://fb.ru/article/165434/informatsionnyie-sistemyi-vidyi-klassifikatsiya-i-vidyi-informatsionnyih-sistem

