




Лабораторная работа № 7 Модель множественной регрессии. Множественная регрессия
Цель: научиться обрабатывать множественную регрессионную модель и обосновывать её значимость и значимость каждого регрессора.
Основные формулы и понятия:
Регрессионная модель в случае двух регрессоров.
 — модель, с двумя регрессорами;
— модель, с двумя регрессорами;
 — уравнение регрессии (плоскость регрессии);
— уравнение регрессии (плоскость регрессии);
Исходными данными для построения модели является выборка вида 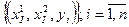 .
.


 — уравнение для параметров регрессии.
— уравнение для параметров регрессии.
Регрессионная модель с произвольным числом регрессоров.
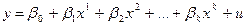 — модель множественной регрессии;
— модель множественной регрессии;
 — уравнение множественной регрессии.
— уравнение множественной регрессии.
Исходные данные значений регрессоров имеют вид
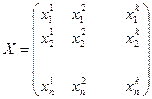 ,
,
где  ,
,  ,
,  — значение j-го регрессора в i-м испытании.
— значение j-го регрессора в i-м испытании.
Исходные данные значений зависимой переменной

 — уравнение для параметров регрессии;
— уравнение для параметров регрессии;
 — стандартное отклонение коэффициентов;
— стандартное отклонение коэффициентов;
 — стандартных ошибок коэффициентов, где
— стандартных ошибок коэффициентов, где  — диагональный элемент матрицы
— диагональный элемент матрицы  ;
;
 — коэффициент детерминации;
— коэффициент детерминации;
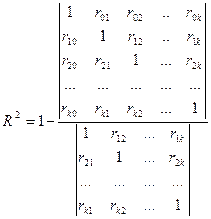 ,
,
где rij — парные коэффициенты корреляции между регрессорами 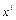 и
и  , a ri0 — парные коэффициенты корреляции между регрессором и y;
, a ri0 — парные коэффициенты корреляции между регрессором и y;
 — скорректированный (нормированный) коэффициент детерминации.
— скорректированный (нормированный) коэффициент детерминации.
Нулевая гипотеза H0:b i = 0.
Альтернативная гипотеза H1: bI ¹ 0.
t-статистика имеет вид:
 ,
,
 — область принятия нулевой гипотезы.
— область принятия нулевой гипотезы.
Если выполняется данное условие, то принимается нулевая гипотеза, и регрессор x i признается незначимым. В противном случае принимается альтернативная гипотеза, и регрессор признаётся значимым.
F-тест (тест Фишера) на значимость всей регрессии.
Нулевая гипотеза H0 :R2 = 0.
Альтернативная гипотеза H1:R2 ¹ 0.
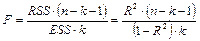 ,
,
 — область принятия нулевой гипотезы.
— область принятия нулевой гипотезы.
Если выполняется данное условие, то принимается нулевая гипотеза, и вся регрессионная модель признается незначимой. В противном случае принимается альтернативная гипотеза, и модель признаётся значимой.
Математический пакет MathCad
Рассмотрение случая двух регрессоров можно опустить, поскольку в этом случае необходимо уметь вычислять средние значения, коэффициент ковариации и дисперсию. Способы получения данных параметров были изучены нами ранее (лабораторная работа № 1). Поэтому рассмотрим случай множественной регрессии.
Математический пакет MathCad содержит большое количество встроенных функций для обработки матриц, которые позволяют получить обратную и транспонированную матрицы, вычислить определителя, собственные значения и собственный вектор матрицы и т. д. Данные функции позволяют вычислить коэффициенты модели множественной регрессии и их стандартные отклонения, используя исходные формулы.
Для получения доступа к матричным функциям необходимо либо используя пункт меню Вид, Панель инструментов активизировать панель Матрицы, либо используя математическую панель инструментов, нажать на кнопку Векторные и матричные операции. В любом случае появится дополнительная панель инструментов (рис. 12).
Рисунок 12 Дополнительная панель инструментов
Нет необходимости описывать каждую из этих кнопок, поэтому рассмотрим только необходимые в нашем случае. Первая кнопка в верхнем ряду позволяет вставить матрицу произвольной размерности, а третья позволяет получить обратную матрицу. Необходимо отметить, что все доступные функции обработки матриц можно получить, используя пункт меню Вставка, Функции и в диалоговом окне выбрать категорию Вектора и Матрицы.
Продемонстрируем возможности пакета по обработки матриц на примере таблицы 1, в которой наряду с данными о спросе (y) и цене (x 1), включены данные о ценах на некоторый подобный товар (x 2, x 3) и средний доход населения (x 4). Обобщённые данные представлены в таблице 12.
Таблица 12 Обобщенные данные
| Номер наблюдения | Цена x 1(т.) | Цена на первый подобный товар x 2 (т.) | Цена на второй подобный товар x 3 (т.) | Средний доход населения x 4 (т. т.) | Спрос y (тыс. шт.) |
| 15,09т. | 24,30т. | 12,85т. | 5,09 | 125,1779 | |
| 15,21т. | 26,65т. | 12,26т. | 5,03 | 123,8094 | |
| 15,28т. | 25,22т. | 13,42т. | 4,80 | 121,175 | |
| 15,49т. | 26,59т. | 12,05т. | 4,95 | 116,9143 | |
| 15,54т. | 26,88т. | 12,70т. | 4,88 | 119,8643 | |
| 15,62т. | 24,74т. | 12,41т. | 4,96 | 118,0681 | |
| 15,70т. | 24,42т. | 13,83т. | 5,10 | 123,5887 | |
| 15,91т. | 25,79т. | 13,10т. | 4,90 | 117,0877 | |
| 15,92т. | 24,14т. | 13,07т. | 4,72 | 116,1699 | |
| 15,95т. | 26,70т. | 12,40т. | 4,81 | 118,3436 | |
| 16,31т. | 24,66т. | 12,82т. | 4,95 | 116,2008 | |
| 16,33т. | 24,04т. | 12,48т. | 4,88 | 111,4565 | |
| 16,60т. | 25,15т. | 13,20т. | 5,02 | 115,1026 | |
| 16,69т. | 24,10т. | 12,40т. | 4,80 | 110,1056 | |
| 16,76т. | 24,49т. | 12,01т. | 4,85 | 110,0231 |
Учитывая, что матрица X должна иметь на один столбец больше, чем число регрессоров, в котором находятся единицы, и вектор-столбец Y содержит значение спроса, документ MathCad может иметь следующий вид:

На основании полученных данных можно записать множественную модель в виде: y = 113,938 – 6,095 x 1 + 0,534 x 2 + 2,588 x 3 + 10,995 x 4.
Сравнивая полученные данные с результатами парного регрессионного анализа (y = 240,14 – 7,7145x), можно сделать следующие выводы:
1. Изменилось влияние цены на спрос. Если в модели парной регрессии увеличение цены на единицу приводило к уменьшению спроса на 7,714 тыс. шт., то при рассмотрении множественной модели увеличение цены на единицу приводит к уменьшению спроса на 6,095 тыс. шт. (Причина данного изменения влияния цены будет рассмотрена нами далее, при изучении проблемы лабораторной работы № 8.)
2. Изменилось значение константы. В парной модели это значение было равно 239,96, во множественной — 113,93. Именно таким должен быть спрос, при условии, что значение всех регрессоров равно нулю. Как и для случая парной регрессии, это значение является во многом теоретическим.
3. На конечный спрос влияет цена на подобные товары. Например, при увеличении на единицу цены на первый подобный товар, спрос увеличивается на 0,534, а для второго подобного товара это значение равно 2,588. То есть можно говорить о том, что второй подобный товар в большей степени влияет на спрос.
4. Кроме цен на спрос также влияет и средний доход населения. При увеличении дохода на единицу спрос увеличивается на 10,995 тыс. шт.
Полученная модель является во многом формальной, поскольку она хоть и получена на основании статистических данных, не были проверены гипотезы о значимости каждого регрессора, да и всей регрессии в целом. Трудность при работе в пакете MathCadзаключается в том, что нет дополнительных встроенных возможностей для проверки гипотез, поэтому все вычисления необходимо производить вручную, создавая необходимый документ. Данная работа часто бывает затруднительна для конечного пользователя. К тому же имеется достаточно сложный механизм передачи данных между MathCad и Excel. Поэтому рассмотрим программные продукты, которые имеют необходимый для анализа множественной регрессии инструментарий.
Электронная таблица Excel
В электронной таблице Excel имеется необходимый набор матричных функций, среди них можно отметить функции: МОБР(), которая выводит обратную матрицу, МУМНОЖ(), вычисляющая произведение двух матриц, ТРАНСП(), выполняющая операцию транспортирования матрицы. Этих функций достаточно для вычисления параметров множественной регрессии, однако они являются матричными, что имеет некоторую специфику при работе с ними. Документ, в котором будут использоваться данные функции, будет выглядеть громоздким, поскольку необходимо отдельно хранить элементы выполнения каждой матричной операции. Поэтому рассмотрим другие возможности Excel.
Как и для случая парной регрессии, для множественной регрессии имеется возможность использовать ту же самую надстройку Регрессия, однако в этом случае количество значений X должно в несколько раз превышать количество Y.
Перенеся таблицу 10 в Excel, в диалоговом окне надстройки Регрессия задав Входной интервал Y в виде G1:G16, а Входной интервал X в виде B1:F16 и установив опцию Метки, будет автоматически сгенерирована таблица 13.
аблица 13 Итоговая таблица
| R-квадрат | 0,928412953 | ||||||
| Нормированный R-квадрат | 0,899778134 | ||||||
| Стандартная ошибка | 1,496311516 | ||||||
| Наблюдения | |||||||
| Дисперсионный анализ | |||||||
| df | SS | MS | F | Значимость F | |||
| Регрессия | 290,3694 | 72,59234 | 32,42252 | 1,06E–05 | |||
| Остаток | 22,38948 | 2,238948 | |||||
| Итого | 312,7588 | ||||||
| Коэффи- циенты | Стандартная ошибка | t-ста тистика | P- значение | Нижние 95 % | Верхние 95 % | ||
| Y-пересечение | 113,1921888 | 36,06499 | 3,138562 | 0,010536 | 32,83438 | 193,55 | |
| Цена x1(т.) | –6,080773549 | 0,900492 | –6,75273 | 5,03E–05 | –8,08719 | –4,07435 | |
| Цена на первый подобный товар x2 (т.) | 0,55174938 | 0,452263 | 1,219975 | 0,250464 | –0,45596 | 1,559454 | |
| Цена на второй подобный товар x3 (т.) | 2,620192945 | 0,85151 | 3,077112 | 0,011698 | 0,722909 | 4,517476 | |
| Средний доход населения x4 (т. т.) | 10,92686031 | 3,846179 | 2,840965 | 0,017519 | 2,357038 | 19,49668 | |
Данная таблица нами рассматривалась уже не раз, поэтому остановимся только на том, что относится к случаю множественной регрессии. Например, в разделе Регрессионная статистика имеется пункт Нормированный R-квадрат, который содержит значение скорректированного коэффициента детерминации. При включении в модель незначимого регрессора данное значение будет уменьшаться.
В разделе Коэффициенты содержатся значения всех коэффициентов, которые совпадают со значениями, полученными посредством MathCad, а кроме этого, стандартные ошибки статистики, значимости и доверительные интервалы для коэффициентов.
На основании данной таблицы можно сделать выводы о значимости каждого регрессора и всей регрессии в целом:
1.Само уравнение регрессии является значимым, поскольку Значимость F равна 1,06E-05, что меньше, чем 0,01. Проверить значимость всей регрессии можно и самостоятельно, поскольку в таблице выдается значение F-статистики, а критический уровень можно, как и в парном случае, найти с помощью функции FРАСПОБТ. Верхнее число степеней свободы в данном случае равно 4, а нижнее10.
2.Коэффициент b 1 является значимым при любом уровне значимости, поскольку его значимость равна 5,03E-0 Следовательно, цена на товар, а в наших обозначениях регрессор x 1, влияет на спрос.
3.Коэффициенты b 3, b 4, можно признать значимыми, поскольку соответствующие значения равны 0,01169 и 0,01752, что несколько превосходит значение 0,01, но все же меньше, чем значение 0,0 Следовательно, на формирование значения спроса также влияет цена на второй подобный товар и средний доход населения.
4. Коэффициент b 2 является незначимым, поскольку соответствующее значение равно 0,25, следовательно, цена на первый подобный товар x 2 не влияет на значение спроса.
Исходя из всего вышесказанного, разумно построить регрессионную модель, в которой отсутствуют незначимые регрессоры. Для этого в электронной таблице Excelнеобходимо удалить тот столбец, в котором находятся значения переменой x 3, и вызвать надстройку Регрессия.
Таблица 1.14 Вывод итогов
| ВЫВОД ИТОГОВ | |||||
| Регрессионная статистика | |||||
| Множественный R | 0,9579 | ||||
| R-квадрат | 0,9177 | ||||
| Нормированный R-квадрат | 0,8953 | ||||
| Стандартная ошибка | 1,5291 | ||||
| Наблюдения | |||||
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 287,037 | 95,67901 | 40,91741 | 2,94E–06 | |
| Остаток | 25,72179 | 2,338345 | |||
| Итого | 312,7588 | ||||
| Коэффи- циенты | Стандартная ошибка | t-ста тистика | P- значение | Нижние 95 % | Верхние 95 % | |
| Y-пересечение | 142,2167 | 27,6999 | 5,134194 | 0,000326 | 81,24956 | 203,1838 |
| Цена x1(т.) | –6,61474 | 0,804244 | –8,2248 | 5,01E–06 | –8,38487 | –4,84461 |
| Цена на второй подобный товар x3 (т.) | 2,240018 | 0,809838 | 2,766008 | 0,018358 | 0,457576 | 4,02246 |
| Средний доход населения x4 (т. т.) | 10,56105 | 3,918663 | 2,695063 | 0,02084 | 1,936122 | 19,18597 |
В данном случае, хотя значения и обычного и скорректированного (нормированного) коэффициента детерминации несколько уменьшилось по сравнению с общим случаем, все равно, модель, в которой не учитывается значения x 2, является лучшей, поскольку в данном случае присутствуют только значимые регрессоры. Итак, наилучшая линейная множественная модель регрессии имеет вид:
y = 142,21 – 6,61 x 1 + 2,24 x 3 + 10,56 x 4.
Проанализировав данную модель, можно сделать выводы о влиянии каждого из регрессоров на значение спроса.
После нахождения значимых регрессоров и определения лучшей линейной модели, разумной является задача поиска лучшей нелинейной модели (логарифмической, степенной, показательной и т. д.). Построение подобных моделей осуществляется аналогично парному случаю (лабораторная работа № 6).

