




В некоторых случаях имитационная модель сложной системы может быть реализована в виде набора отдельных моделей ее подсистем. При проведении экспериментов с такой моделью в целях сокращения затрат времени бывает необходимо заменять моделирование работы одной из подсистем некоторым числовым параметром (вспомните принцип параметризации), либо случайной величиной, распределенной по заданному закону. Чтобы такая замена была выполнена корректно, исследователь должен располагать описанием зависимости данного числового параметра от времени и других факторов, фигурирующих в модели.
При имитационном моделировании подбор законов распределений выполняется на основе статистических данных, полученных в ходе эксперимента. В основе процедуры отыскания закона распределения некоторой величины по экспериментальным данным лежит проверка статистических гипотез. Статистическая гипотеза — это утверждение относительно значений одного или более параметров распределения некоторой величины или о самой форме распределения.
Обычно выбирают две исходные гипотезы: основную — Н0 и альтернативную ей — Н1.
Статистическая проверка гипотезы — это процедура выяснения, следует ли принять основную гипотезу Н0 или отвергнуть ее.
Если в результате проверки гипотеза Н0ошибочно отвергается, то имеет место ошибка первого рода (характеризующаяся более тяжелыми последствиями); если гипотеза Н0 принимается при истинности Н1 — ошибка второго рода. Вероятности ошибок I и II рода  зависят от критерия, на основании которого
зависят от критерия, на основании которого
будет выбираться одна из гипотез.
Очевидно, что вероятности этих двух ошибок взаимосвязаны, то есть чем больше значение a, тем меньше b и наоборот. Обычное решение этой дилеммы состоит в том, что выбирают некоторое фиксированное значение a (как правило, 0.05,0.1,0.001) и надеются, что b будет также мало, фиксированное значение a называется уровнем значимости. Для выбранного значения a определяется так называемая критическая область В, удовлетворяющая условию:

Здесь Z — контрольная величина (критерий), представляющая собой некоторую функцию от выборки (результатов эксперимента).
Проверка гипотезы состоит в следующем. Производится выборка (эксперимент), на основании чего вычисляется z — частное значение критерия Z. Если z e B, то от гипотезы Н0 отказываются. Если z не принадлежит В, то говорят, что полученные наблюдения не противоречат принятой гипотезе.
Разумеется, прежде чем выдвигать гипотезу относительно значений параметров распределения, необходимо определить вид самого закона распределения. Наиболее распространенный на практике и достаточно эффективный метод подбора закона распределения основан на использовании графического представления экспериментальных данных.
Они отображаются в виде так называемой гистограммы относительных частот, которая может быть построена как вручную, так и с помощью соответствующих инструментальных средств, входящих в состав большинства пакетов моделирования. Внешний вид гистограммы показан на рис. 2.20.
Для эффективного использования графических средств пакета МATLAB, которому посвящена большая часть книги, полезно знать методику построения гистограммы относительных частот.
1. Вычисляется величина интервала гистограммы из следующего соотношения:
 — диапазон изменения наблюдаемой переменной, n — число интервалов, выбранных исследователем.
— диапазон изменения наблюдаемой переменной, n — число интервалов, выбранных исследователем.
- По результатам (или в процессе) моделирования определяется число попаданий значений у в i-й интервал.
- Вычисляется относительная частота попаданий наблюдаемой переменной в каждый интервал:
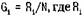 — число попаданий в i -и интервал; N — общее число измерений (объем выборки).
— число попаданий в i -и интервал; N — общее число измерений (объем выборки).
На каждом i-м интервале строится прямоугольник со сторонами dxGi. Сумма
площадей прямоугольников гистограммы равна единице.

Рис. 2.20. Пример гистограммы относительных частот
Для наиболее часто используемых статистических гипотез разработаны критерии, позволяющие проводить их проверку с наибольшей достоверностью. Рассмотрим основные из них.
T-критерий
Этот критерий служит для проверки гипотезы о равенстве средних значений двух нормально распределенных случайных величин X и Y в предположении, что дисперсии их равны (хотя и неизвестны). Сравниваемые выборки могут иметь разный объем. В качестве критерия используют величину Т:

Величина Т подчиняется t-распределению Стьюдента.
Критическое значение для t-критерия определяется по таблице для выбранного значения а и числа степеней свободы k=n1+n2-2.
Если вычисленное по указанной формуле значение Т удовлетворяет неравенству T ³ tKp, то гипотезу Н0 отвергают.
По отношению к предположению о "нормальной распределенности" величин х и у t-критерий не очень чувствителен. Его можно применять, если распределения случайных величин не имеют нескольких вершин и не слишком асимметричны.
F-критерий
Этот критерий служит для проверки гипотезы о равенстве дисперсий Dx и Dy при условии, что х и у распределены нормально.
Гипотезы такого рода имеют большое значение в технике, так как дисперсия есть мера таких характеристик, как погрешности измерительных приборов, точность технологических процессов, точность наведения при стрельбе и так далее. В качестве контрольной величины используется отношение дисперсий  (или DY /Dх — большая дисперсия должна быть в числителе). Величина F подчиняется F-распределению (Фишера) с (m1, m2) степенями свободы
(или DY /Dх — большая дисперсия должна быть в числителе). Величина F подчиняется F-распределению (Фишера) с (m1, m2) степенями свободы  .
.
Проверка гипотезы состоит в следующем.
Для величины  и величин m1, m2 по таблице F-распределения выбирают значения Fa,m1,m2.
и величин m1, m2 по таблице F-распределения выбирают значения Fa,m1,m2.
Если f, вычисленное по выборке, больше этого критического значения, гипотеза должна быть отклонена с вероятностью ошибки a.
ибровку в единый процесс. Именно такая стратегия принята в статистическом методе калибровки, описанном ниже.
Процедура калибровки состоит из трех шагов, каждый из которых является итеративным (рис. 2.19).

Рис. 2.19. Схема процесса калибровки ИМ
- Сравнение выходных распределений. Цель — оценка адекватности ИМ. Критерии сравнения могут быть различны. В частности, может использоваться величина разности между средними значениями откликов модели и системы. Устранение различий на этом шаге основано на внесении глобальных изменений.
- Балансировка модели. Основная задача — оценка устойчивости и чувствительности модели. По его результатам, как правило, производятся локальные изменения (но возможны и глобальные).
- Оптимизация модели. Цель этого этапа — обеспечение требуемой точности результатов. Здесь возможны три основных направления работ:
- дополнительная проверка качества датчиков случайных чисел;
- снижение влияния переходного режима;
- применение специальных методов понижения дисперсии.
Критерии согласия
Критерии согласия используются для проверки того, удовлетворяет ли рассматриваемая случайная величина данному закону распределения.
Критерий согласия Пирсона (х2) служит для проверки гипотезы Н0 о том, что Fy (у)=F0 (у), где Fy (у) — истинное распределение случайной величины у, F0 (у) — гипотетическое распределение.
Проверка производится следующим образом.
- Область значений случайной величины у разбивается (произвольно) на k непересекающихся множеств («классов»).
- В результате n опытов формируется выборка (у1,... уn).
- Вычисляется контрольная величина х2:

Здесь М2i — число значений у, попавших в i-й класс; pi — теоретическая вероятность для F0(y) попадания значения у в i-й класс.
4. По таблице  -распределений находят критическое значение
-распределений находят критическое значение  для уровня значимости а и m=k-1 степеней свободы. Если
для уровня значимости а и m=k-1 степеней свободы. Если  , то гипотеза отвергается.
, то гипотеза отвергается.
При использовании критерия Колмогорова- Смирнова имеющуюся выборку(у1 уn) упорядочивают по возрастанию и строят следующую эмпирическую функцию распределения:

Контрольной величиной является следующая:

Гипотеза Н0: Fy(y)=F0(y) отвергается, если вероятность попадания соответствующего критерия в критическую область оказывается меньше выбранного исследователем уровня значимости а.
Критическое значение критерия, как и в предыдущих случаях, находится по таблице. Разумеется, проведение вручную расчетов, необходимых для проверки статистических гипотез, требует значительных затрат времени и сил. Поэтому многие современные математические пакеты имеют в своем составе средства, позволяющие свести к минимуму число операций, выполняемых пользователем вручную.

