




Сурак
1.Процесс дегеніміз не? Ағындар дегеніміз не? Процесс пен ағын айырмашылығы.
Программы MPI состоят из автономных процессов, выполняющих собственный код, написанный в стиле MIMD. Коды, выполняемые каждым процессом, не обязательно идентичны. Процессы взаимодействуют через вызовы коммуникационных примитивов MPI. Обычно каждый процесс выполняется в его собственном адресном пространстве, хотя возможны реализации MPI с разделяемой памятью. Этот документ описывает поведение параллельной программы в предположении, что для обмена используются только вызовы MPI. MPI не описывает модель исполнения для каждого процесса. Процесс может быть последовательным или многопоточным. В последнем случае необходимо обеспечить `` потоковую безопасность '' (`` thread-safe''). Желаемое взаимодействие MPI с потоками должно состоять в том, чтобы разрешить конкурирующим потокам выполнять вызовы MPI, и вызовы должны быть реентерабельными; блокирующие вызовы MPI должны блокировать только вызываемый поток, не препятствуя планированию другого потока. MPI не обеспечивает механизмы для начального распределения процессов по физическим процессорам. Ожидается, что эти механизмы для этапа загрузки или исполнения обеспечат поставщики. Такие механизмы позволят описывать начальное число требуемых процессов; код, который должен исполняться каждым начальным процессом; размещение процессов по процессорам. Однако, существующее определение MPI не обеспечивает динамического создания или удаления процессов во время исполнения программ (общее число процессов фиксировано), хотя такое расширение предусматривается. Наконец, процесс всегда идентифицируется согласно его относительному номеру в группе, т. е. последовательными целыми числами в диапазоне 0,..., groupsize-1.
2.Декарт топологиясы. Периодтық көршілерді қолдану.
Обобщением линейной и матричной топологий на произвольное число измерений является декартова топология Для создания декартовой топологии (решетки) в MPI предназначена функция: int MPI_Cart_create(MPI_Comm oldcomm, int ndims, int *dims, int *periods, int reorder, MPI_Comm *cartcomm). С помощью этой функции можно создавать топологии с произвольным числом измерений, причем по каждому измерению в отдельности можно накладывать периодические граничные условия. Таким образом, для одномерной топологии мы можем получить или линейную структуру, или кольцо в зависимости от того, какие граничные условия будут наложены. Для двумерной топологии, соответственно, либо прямоугольник, либо цилиндр, либо тор. Здесь periods - массив длины ndims, определяет, является ли решетка периодической вдоль каждого измерения. int dims[2]={0,0}, periods[2]={1,0},coords[2], ndims=2, reorder=0; - далее вызов функции MPI_Cart_create(MPI_COMM_WORLD,ndims,dims,periods,reorder,&cartcomm) – мы получаем цилиндр. Если periods[2]={1,1} – тор.
3. 3 өлшемді Лаплас теңдеуін 2-өлшемді декомпозиция тәсілімен программалау.
MPI_Comm GridComm;
int size,rank,i;
int ix,iy,iz;
int x,y,z,X=10,Y=10,Z=10;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Status status;
y=Y/size+2;
double matrix[X][y][Z],vecUP[X][Z],vecDOWN[X][Z];
if(rank==0)
{
for(ix=1;ix<X-1;ix++)
{
for(iz=1;iz<Z-1;iz++)
{
matrix[ix][1][iz]=1;
}
}
for(ix=1;ix<X-1;ix++)
{
for(iy=2;iy<y-1;iy++)
{
for(iz=1;iz<Z-1;iz++)
{
matrix[ix][iy][iz]=0;
}
}
}
}else
{
for(ix=1;ix<X-1;ix++)
{
for(iy=1;iy<y-1;iy++)
{
for(iz=1;iz<Z-1;iz++)
{
matrix[ix][iy][iz]=0;
}
}
}
}
for(int i=0;i<10;i++)
{
if(rank<size-1)
{
for(ix=0;ix<X;ix++)
{
for(iz=0;iz<Z;iz++)
{
vecUP[ix][iz]=matrix[ix][y-2][iz];
}
}
MPI_Send(vecUP,X*Z,MPI_FLOAT,rank+1,rank,MPI_COMM_WORLD);
MPI_Recv(vecUP,X*Z,MPI_FLOAT,rank+1,rank+1,MPI_COMM_WORLD,&status);
for(ix=0;ix<X;ix++)
{
for(iz=0;iz<Z;iz++)
{
matrix[ix][y-1][iz]=vecUP[ix][iz];
}
}
}
if(rank>0)
{
MPI_Recv(vecDOWN,X*Z,MPI_FLOAT,rank-1,rank-1,MPI_COMM_WORLD,&status);
for(ix=0;ix<X;ix++)
{
for(iz=0;iz<Z;iz++)
{
matrix0[ix][0][iz]=vecDOWN[ix][iz];
vecDOWN[ix][iz]=matrix[ix][1][iz];
}
}
MPI_Send(vecDOWN,X*Z,MPI_FLOAT,rank-1,rank,MPI_COMM_WORLD);
}
for(iz=1;iz<Z-1;iz++)
{
for(iy=1;iy<y-1;iy++)
{
if(rank==0&&iy==1){continue;}
if(rank==size-1&&iy==y-2){break;}
for(ix=1;ix<X-1;ix++)
{
matrix[ix][iy][iz]=matrix[ix+1][iy][iz]+matrix[ix-1][iy][iz]+matrix[ix][iy+1][iz];
matrix[ix][iy][iz]+=matrix[ix][iy-1][iz]+matrix[ix][iy][iz+1]+matrix[ix][iy][iz-1];
matrix[ix][iy][iz]/=6;
}
}
}
}while(stop==0);
MPI_Finalize();
return 0;
}
Сурак
Флинна таксономиясы. МISD, МIMD архитектуралары.
В литературе часто используется та или иная схема классификации компьютерных архитектур и одной из наиболее популярных является таксономия Флинна. В ее основу положено описание работы компьютера с потоком команд и потоком данных. По Флинну принято классифицировать все возможные архитектуры компьютеров на четыре категории:
SISD (Single Instruction Stream - Single Data Stream) – один поток команд и один поток данных;
SIMD (Single Instruction Stream –Multiple Data Stream) – один поток команд и множество потоков данных;
MISD (Multiple Instruction Stream –Single Data Stream) – множество потоков команд и один поток данных;
MIMD (Multiple Instruction Stream –Multiple Data Stream) – множество потоков команд и множество потоков данных
MISD компьютеры
Вычислительных машин такого класса практически нет и трудно привести пример их успешной реализации. Один из немногих – систолический массив процессоров, в котором процессоры находятся в узлах регулярной решетки, роль ребер которой играют межпроцессорные соединения. Все процессорные элементы управляются общим тактовым генератором. В каждом цикле работы каждый процессорный элемент получает данные от своих соседей, выполняет одну команду и передает результат соседям
MIMD компьютеры
Эта категория архитектур вычислительных машин наиболее богата, если иметь в виду примеры ее успешных реализаций. В нее попадают симметричные параллельные вычислительные системы, рабочие станции с несколькими процессорами, кластеры рабочих станций и т.д. Уже довольно давно появились компьютеры с несколькими независимыми процессорами, но вначале на таких компьютерах был реализован только параллелизм заданий, то есть на разных процессорах одновременно выполнялись разные и независимые программы.
2. MPI программасын компиляциялау, жинау және орындау.
Поскольку MPI является библиотекой, то при компиляции программы необходимо соответствующие библиотечные модули. Это можно сделать в командной строке или воспользоваться предусмотренными в большинстве систем командами или скриптами mpicc(для программ на языке СИ), mpic++(для программ на языке С++), и mpif77/mpif90(для программ на языке Фортран 77/90). Опция компилятора «-o name» позволяет задать имя name для получаемого выполнимого файла, по умолчанию выполнимый файл называется a.out, например: mpif77 –o program program.f
После получения выполнимого файла необходимо запустить его на требуемом количестве процессов. Для этого обычно предоставляется команда запуска MPI –приложения mpirun,mpiexec, например:
mpirun –np N <программа с аргументами>
mpiexec –np N <программа с аргументами>
где N-число процессов,которое должно быть не более разрешенного в данной системе числа процессов для одной задачи. После запуска одна и та же программа будет выполняться всеми запущенными процессами, результат выполнения в зависимости от системы будет выдаваться на терминал или записываться в файл предопределенным именем.
3. 2*sin(x) функциясының интегралын [0,1] аймақта параллельді есептеңіз.
double f(double x)
{return 2*sin(x);}
int main(int argc,char **argv)
{
int size,rank;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
float h=0.05,a=0,b=1,s=0.0;
for(int i=rank; a+h*(i+1)<b+h; i+=size)
{ s+=h*f(a+h*(i+1)); }
if(rank!=0)
{ MPI_Send(&s,1,MPI_FLOAT,0,1,MPI_COMM_WORLD); }
if(rank==0)
{ float r;
MPI_Recv(&r,1,MPI_FLOAT,1,1,MPI_COMM_WORLD,&status);
s+=r;
printf("s=%f\n ",s);
}
}
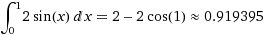
Сурак
1. Жарыс күі. Синхронизация. Философтар есебі.
Состояние гонки — это ошибка, возникающая, когда результат программы зависит от того, какой из двух (или более) потоков первым достигнет определенного блока кода. При многократном запуске программы получаются разные непредсказуемые результаты.
Необходимость синхронизации обуславливается тем обстоятельством, что не все возможные траектории совместно выполняемых потоков являются допустимыми (так, например, при использовании общих ресурсов требуется обеспечить взаимоисключение). В самом общем виде, синхронизация может быть обеспечена при помощи задания необходимых логических условий, которые должны выполняться в соответствующих точках траекторий потоков. Принципиальный момент состоит в определении полного набора синхронизирующих действий, обеспечивающих гарантированное исключение недопустимых траекторий параллельной программы – в этом случае говорят, что программа обладает свойством безопасности. Строгость данного свойства может быть несколько снижена – так, набор синхронизирующих действий можно ограничить требованием обеспечения достижимости допустимых траекторий программы – такое поведение обычно именуется свойством живучести.

