




Хранимые в базе данные имеют определенную логическую структуру, те описываются моделью представления данных, поддерживаемой СУБД: иерархические,сетевые и реляционные. Кроме того появились также постреляционная, многомерная, объектно-ориентированная.
Иерархические базы данных
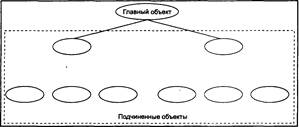 Иерархические базы данных применялись в начале 60-х годов. Они построены в виде обычного дерева. Данные здесь делятся на две категории: главные и подчиненные. Таким образом, один тип объекта является главным, а остальные, находящиеся на более низких ступенях иерархии, — подчиненными (рис. 1.1).
Иерархические базы данных применялись в начале 60-х годов. Они построены в виде обычного дерева. Данные здесь делятся на две категории: главные и подчиненные. Таким образом, один тип объекта является главным, а остальные, находящиеся на более низких ступенях иерархии, — подчиненными (рис. 1.1).
Наивысший в иерархии объект называется корневым, остальные объекты носят название зависимых объектов. БД, организованная по иерархическому принципу, удобна для работы с информацией, которая соответственным образом упорядочена. В остальных случаях работа с такой моделью будет достаточно сложной.
Достоинствами иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Примеры: зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС;
Сетевые базы данных
 Сетевые базы данных начали применяться практически одновременно с иерархическими. В этих базах данных любой объект может быть как главным, так и подчиненным (рис. 1.2).
Сетевые базы данных начали применяться практически одновременно с иерархическими. В этих базах данных любой объект может быть как главным, так и подчиненным (рис. 1.2).
Таким образом, в сетевой модели базы данных каждый объект может иметь сколько угодно связей с другими объектами. Из-за сложности представления данных в таком виде от сетевой модели базы данных в большинстве случаев также пришлось отказаться.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС;
Реляционные базы данных
Именно реляционные базы данных (от англ. relation — отношение) стали широко использоваться в программировании начиная с 70-х годов. В таких базах данных объекты и взаимосвязи между ними представляются в виде прямоугольных таблиц, состоящих из строк и столбцов (рис. 1.3).
 Каждая таблица здесь представляет собой объект базы данных. Такую базу данных легче всего можно реализовать на компьютере. В дальнейшем мы будем рассматривать именно реляционные базы данных.
Каждая таблица здесь представляет собой объект базы данных. Такую базу данных легче всего можно реализовать на компьютере. В дальнейшем мы будем рассматривать именно реляционные базы данных.
Итак, таблицы, которые составляют базу данных, находятся на магнитном диске в отдельной папке. Папка в целом является базой данных, а входящие в нее таблицы хранятся в виде отдельных файлов. С этими файлами можно производить произвольные операции, которые допускаются операционной системой. Большинство приложений Windows при попытке обращения к одному файлу сразу несколькими приложениями выдают сообщение об ошибке совместного доступа. Для таблиц базы данных такое ограничение крайне неудобно, поэтому им свойственна особенность, которая заключается в том, что несколько приложений могут получить доступ к файлу таблицы одновременно. Такой режим доступа называется многопользовательским.
Столбцы таблицы обычно называют полями, а строки — записями. К полям таблицы предъявляются следующие требования:
■ поле должно иметь уникальное имя в пределах одной таблицы;
■ поле должно содержать данные только одного заранее определенного типа;
■ любая таблица должна иметь как минимум одно поле.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IV (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) и Oracle (Oracle).
Постреляционная модель.
Представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. На длину и количество полей не накладывается требование постоянства, те таблица имеет большую гибкость. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Примерами: uniVers, Bubba и Dasdb;
Многомерная.
Узкоспециализированная, предназначена для интерактивной аналитической обработки информации. Агрегатируемость данных означает рассмотрение информации на различных уровнях ее сообщения. Историчность – обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, и обязательность привязки ко времени. Прогнозируемость – задание функции прогнозирования и применение ее к различным временным интервалам. Измерение – множество однотипных данных, играют роль индексов, служащих для идентификации конкретных значений в ячейках. Ячейка – показатель, это поле, значение которого однозначно определяется фиксированным набором измерений. Существуют схемы гиперкуб, поликубическая (несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней) и гиперкубическая (все показатели определяются одним и тем же набором измерений). Достоинства: удобство и эффективность аналитической обработки больших объемов данных, связывание со временем. Недостатки: громоздкость для простейших задач обычной оперативной обработки информации. Примерами являются media multi-matrix (speed ware), oracle express serveк (oracle), cache (intersystem).

