Одним из наиболее распространенных способов классификации ЭВМ является систематика Флинна (Flynn), в рамках которой основное внимание при анализе архитектуры вычислительных систем уделяется способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных. В результате такого подхода различают следующие основные типы систем [9, 22, 29, 31]:
· SISD (Single Instruction, Single Data) - системы, в которых существует одиночный поток команд и одиночный поток данных; к данному типу систем можно отнести обычные последовательные ЭВМ;
· SIMD (Single Instruction, Multiple Data) - системы c одиночным потоком команд и множественным потоком данных; подобный класс систем составляют МВС, в которых в каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов;
· MISD (Multiple Instruction, Single Data) - системы, в которых существует множественный поток команд и одиночный поток данных; примеров конкретных ЭВМ, соответствующих данному типу вычислительных систем, не существует; введение подобного класса предпринимается для полноты системы классификации;
· MIMD (Multiple Instruction, Multiple Data) - системы c множественным потоком команд и множественным потоком данных; к подобному классу систем относится большинство параллельных многопроцессорных вычислительных систем.
Следует отметить, что хотя систематика Флинна широко используется при конкретизации типов компьютерных систем, такая классификация приводит к тому, что практически все виды параллельных систем (несмотря на их существенную разнородность) относятся к одной группе MIMD. Как результат, многими исследователями предпринимались неоднократные попытки детализации систематики Флинна. Так, например, для класса MIMD предложена практически общепризнанная структурная схема [29, 31], в которой дальнейшее разделение типов многопроцессорных систем основывается на используемых способах организации оперативной памяти в этих системах (см. рис. 1.1). Данный поход позволяет различать два важных типа многопроцессорных систем - multiprocessors (мультипроцессоры или системы с общей разделяемой памятью) и multicomputers(мультикомпьютеры или системы с распределенной памятью).
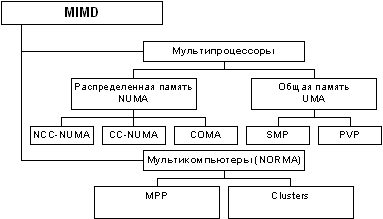
Рис. 1.1. Структура класса многопроцессорных вычислительных систем
Далее для мультипроцессоров учитывается способ построения общей памяти. Возможный подход - использование единой (централизованной) общей памяти. Такой подход обеспечивает однородный доступ к памяти (uniform memory access or UMA) и служит основой для построения векторных суперкомпьютеров (parallel vector processor, PVP) и симметричныхмультипроцессоров (symmetric multiprocessor or SMP). Среди примеров первой группы суперкомпьютер Cray T90, ко второй группе относятся IBM eServer p690, Sun Fire E15K, HP Superdome, SGI Origin 300 и др.
1.3. Характеристика типовых схем коммуникации в многопроцессорных вычислительных системах
При организации параллельных вычислений в МВС для организации взаимодействия, синхронизации и взаимоисключения параллельно выполняемых процессов используется передача данных между процессорами вычислительной среды. Временные задержки при передаче данных по линиям связи могут оказаться существенными (по сравнению с быстродействием процессоров) и, как результат, коммуникационная трудоемкость алгоритма оказывает существенное влияние на выбор параллельных способов решения задач.
Структура линий коммутации между процессорами вычислительной системы (топология сети передачи данных) определяется, как правило, с учетом возможностей эффективной технической реализации; немаловажную роль при выборе структуры сети играет и анализ интенсивности информационных потоков при параллельном решении наиболее распространенных вычислительных задач. К числу типовых топологий обычно относят следующие схемы коммуникации процессоров (см. рис. 1.1):
· полный граф (completely-connected graph or clique)- система, в которой между любой парой процессоров существует прямая линия связи; как результат, данная топология обеспечивает минимальные затраты при передаче данных, однако является сложно реализуемой при большом количестве процессоров;
· линейка (linear array or farm) - система, в которой каждый процессор имеет линии связи только с двумя соседними (с предыдущим и последующим) процессорами; такая схема является, с одной стороны, просто реализуемой, а с другой стороны, соответствует структуре передачи данных при решении многих вычислительных задач (например, при организации конвейерных вычислений);
· кольцо (ring) - данная топология получается из линейки процессоров соединением первого и последнего процессоров линейки;
· звезда (star) - система, в которой все процессоры имеют линии связи с некоторым управляющим процессором; данная топология является эффективной, например, при организации централизованных схем параллельных вычислений;
· решетка (mesh) - система, в которой граф линий связи образует прямоугольную сетку (обычно двух- или трех- мерную); подобная топология может быть достаточно просто реализована и, кроме того, может быть эффективно используема при параллельном выполнении многих численных алгоритмов (например, при реализации методов анализа математических моделей, описываемых дифференциальными уравнениями в частных производных);
· гиперкуб (hypercube) - данная топология представляет частный случай структуры решетки, когда по каждой размерности сетки имеется только два процессора (т.е. гиперкуб содержит 2N процессоров при размерностиN); данный вариант организации сети передачи данных достаточно широко распространен в практике и характеризуется следующим рядом отличительных признаков:
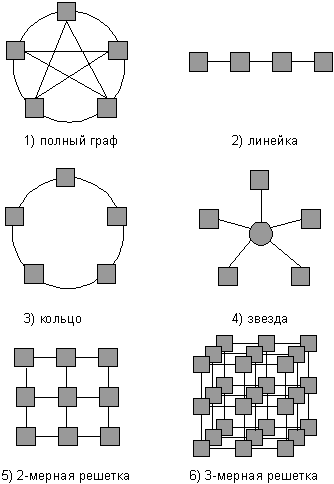
Рис. 1.2. Примеры топологий многопроцессорных вычислительных систем
o два процессора имеют соединение, если двоичное представление их номеров имеет только одну различающуюся позицию;
o в N-мерном гиперкубе каждый процессор связан ровно с N соседями;
o N-мерный гиперкуб может быть разделен на два (N – 1)-мерных гиперкуба (всего возможно N различных таких разбиений);
o кратчайший путь между двумя любыми процессорами имеет длину, совпадающую с количеством различающихся битовых значений в номерах процессоров (данная величина известна как расстояние Хэмминга).
Разработчикам систем необходимо, прежде всего, проанализировать следующие связанные между собой вопросы:
· отношение "стоимость/производительность";
· надежность и отказоустойчивость системы;
· масштабируемость системы;
· совместимость программного обеспечения.
Требования к надежности и отказоустойчивости системы рассматриваются в другой лекции.
Отношение "стоимость/производительность"
Добиться дополнительного повышения производительности в МВС сложнее, чем произвести масштабирование внутри узла. Основным барьером является трудность организации эффективных межузловых связей. Коммуникации, которые существуют между узлами, должны быть устойчивы к задержкам программно поддерживаемой когерентности. Приложения с большим количеством взаимодействующих процессов работают лучше на основе SMP-узлов, в которых коммуникационные связи более быстрые. В кластерах, как и в МРР-системах, масштабирование приложений более эффективно при уменьшении объема коммуникаций между процессами, работающими в разных узлах. Это обычно достигается путем разбиения данных.
Именно такой подход используется в наиболее известном приложении на основе кластеров OPS (Oracle Parallel Server).
Появление любого нового направления в вычислительной технике определяется требованиями компьютерного рынка. Поэтому у разработчиков компьютеров нет единственной цели. Большая универсальная вычислительная машина (мейнфрейм) илисуперкомпьютер стоят дорого. Для достижения поставленных целей при проектировании высокопроизводительных конструкций приходится игнорировать стоимостные характеристики.
Суперкомпьютеры фирм Cray Inc., NEC и высокопроизводительные мэйнфреймы компании IBM, суперкластеры фирмы SGI относятся именно к этой категории компьютеров. Другим противоположным примером может служить сравнительно недорогая конструкция, где производительность принесена в жертву для достижения низкой стоимости. К этому направлению относятся персональные компьютеры IBM PC. Между этими двумя крайними направлениями находятся конструкции, основанные на отношении "стоимость/производительность", в которых разработчики находят баланс между стоимостью и производительностью. Типичными примерами такого рода компьютеров являются миникомпьютеры и рабочие станции.
Для сравнения различных компьютеров между собой обычно используются стандартные методики измерения производительности. Эти методики позволяют разработчикам и пользователям задействовать полученные в результате испытаний количественные показатели для оценки тех или иных технических решений, и, в конце концов, именно производительность и стоимость дают пользователю рациональную основу для решения вопроса, какой компьютер выбрать.
Например, в качестве критерия измерения производительности используется тест LINPACK. Данный тест был выбран из-за его доступности почти для всех рассматриваемых систем. Тест LINPACK был введен Джеком Донгаррой (Jack Dongarra) в 1976 г. Данный тест основан на решении плотной системы линейных уравнений. Как один из вариантов LINPACK используется версия теста, которая позволяет пользователю менять размерность задачи и оптимизировать программное обеспечение для достижения наилучшей производительности для данной машины. Такая производительность не отражает общую производительность этой системы. Однако она отражает ее производительность при решении плотной системы линейных уравнений.
Для оценки производительности вычислительных систем используются также тесты SPECfp_rate_base2000: SPEC, SPECfp и SPECrate, которые являются зарегистрированными торговыми марками Standard Performance Evaluation Corporation. Для оценки скорости работы памяти системы используется тест STREAM Triad.
Масштабируемость представляет собой возможность наращивания числа и мощности процессоров, объемов оперативной и внешней памяти и других ресурсов вычислительной системы. Масштабируемость должна обеспечиваться архитектурой и конструкцией компьютера, а также соответствующими средствами программного обеспечения.
Так, например, возможность масштабирования кластера ограничена значением отношения скорости процессора к скорости связи, которое не должно быть слишком большим (реально это отношение для больших систем не может быть более 3-4, в противном случае не удается даже реализовать режим единого образа операционной системы). С другой стороны, последние 10 лет истории развития процессоров и коммуникаторов показывают, что разрыв в скорости между ними все увеличивается. Добавление каждого нового процессора в действительно масштабируемой системе должно давать прогнозируемое увеличение производительности и пропускной способности при приемлемых затратах. Одной из основных задач при построении масштабируемых систем являетсяминимизация стоимости расширения компьютера и упрощение планирования. В идеале добавление процессоров к системе должно приводить к линейному росту ее производительности. Однако это не всегда так. Потери производительности могут возникать, например, при недостаточной пропускной способности шин из-за возрастания трафика между процессорами и основной памятью, а также между памятью и устройствами ввода/вывода. В действительности реальное увеличение производительности трудно оценить заранее, поскольку оно в значительной степени зависит от динамики поведения прикладных задач.
Возможность масштабирования системы определяется не только архитектурой аппаратных средств, но зависит от свойств программного обеспечения. Масштабируемость программного обеспечения затрагивает все его уровни, от простых механизмов передачи сообщений до работы с такими сложными объектами как мониторы транзакций и вся среда прикладной системы. В частности, программное обеспечение должно минимизировать трафик межпроцессорного обмена, который может препятствовать линейному росту производительности системы. Аппаратные средства (процессоры, шины и устройства ввода/вывода) являются только частью масштабируемой архитектуры, на которой программное обеспечение может обеспечить предсказуемый рост производительности. Важно понимать, что, например, простой переход на более мощный процессор может привести к перегрузке других компонентов системы. Это означает, что действительно масштабируемая система должна быть сбалансирована по всем параметрам.
23. Методы повышения производительности многопроцессорных и многоядерных систем.
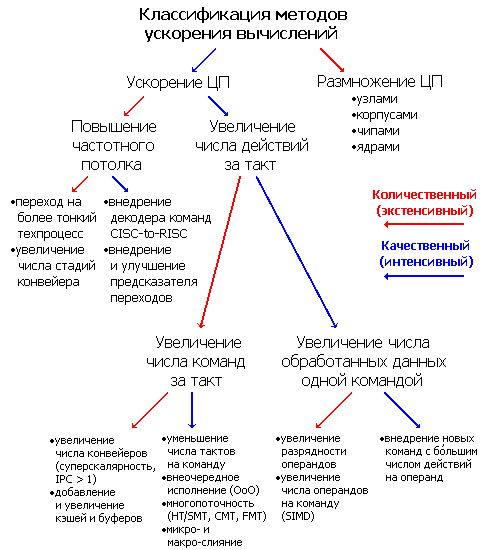
Всё время существования вычислительных машин, начиная ещё с арифмометров, создатели всегда хотели их ускорить. Какими способами у них это получалось и получается? Разумеется, никакого основного метода увеличить скорость вычислений нет, одновременно применяются почти все из до сих пор найденных. Поэтому для классификации потребуется разделение на качественные (интенсивные) и количественные (экстенсивные) ускорения. Разделение весьма условное — чёткой границы между методами повышения производительности нет, да и внутри себя они тоже делятся на разные подклассы. Т.к. за обработку данных отвечает один или несколько центральных процессоров (ЦП), а производительность является его/их главной характеристикой — большинство способов так или иначе касаются именно этой части системы. Заранее предупредим, что под процессором мы понимаем микросхему с корпусом и выводами, вставленную в разъём (сокет).
Первое разделение относится к числу процессоров: качественные методы предполагают ускорение работы ЦП при неизменном его/их количестве, количественные — наращивание числа ЦП с целью сложить их усилия. Многопроцессорные архитектуры применяются, когда другие способы уже внедрены и более не эффективны, и при должном умении инженеров и программистов дают отличный результат (если, конечно, задача хорошо распараллеливается) — совокупная производительность системы растёт почти линейно числу процессоров благодаря тщательно слаженной синхронизации взаимодействий вычислительных узлов. В последних выпусках рейтинга самых быстрых суперкомпьютеров планеты Top500 почти все машины используют кластерную архитектуру, основанную на концепции массового параллелизма (MPP, massively parallel processing). В этих вычислительных монстрах, занимающих целые залы, одновременно работают десятки, а скоро, возможно, и сотни тысяч процессоров.
Для ускорения таких систем применяется два способа — численно увеличить число узлов (вплоть до десятков тысяч) и ускорять сами узлы. Уже по цифрам видно, что для суперкомпьютеров первый способ — основной, но жрущие мегаватты и шумящие вентиляторами шкафы домашнему пользователю не подойдут. Так что не менее важной задачей будет ускорение системы, не приводящее к линейному увеличению её физических размеров. Самый очевидный (количественный) способ — нарастить число ЦП в пределах системного блока и платы. Качественно же (потому что это сложнее) требуется наращивать число вычислительных ядер внутри одного ЦП — что активно происходит и в персональных компьютерах. Наращивать можно, устанавливая несколько 1-ядерных чипов в один корпус, или делая чип с несколькими ядрами. Возможны и комбинации — 4-ядерные ЦП Intel Core 2 Quad имеют два 2-ядерных чипа. Более тесное расположение ядер имеет плюсы и минусы.
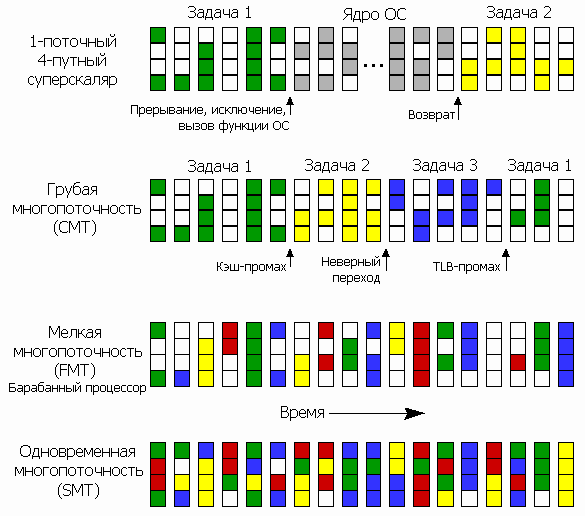
Но и эти методы недостаточны, когда происходят такие рушащие производительность события, как неверно предсказанный переход, кэш-промах (запрошенная информация не закэширована), долго исполняющаяся команда и т.п. — при заторе в одной стадии остальные ждут, пока нужный ресурс станет доступным. Тогда между стадиями добавляют многочисленные буферы и очереди, сглаживающие разницу в производительности отдельных этапов и поддерживающие на плаву весь конвейер первые несколько тактов после фатального затора. А дальше всё равно надо откуда-то брать команды и данные. И если с текущей программой мы ничего сделать не сможем, пока не рассосётся затор, — может, переключимся на другую, раз уж все процессоры многозадачные?
Единственный качественный способ ускорить обработку данных при фиксированном числе команд — внедрять новые команды, исполняющие над данными больше действий, заменяя несколько (иногда даже десятков) простых инструкций. Это не только уменьшает размер кода, но и ускоряет его, т.к. исполнение новой команды будет скорее аппаратное, а не микропрограммное. Вот примеры:
· операции над всеми регистрами сразу (сохранение всего РФ в стеке и восстановление из него);
· непосредственные операнды в командах (где они были недоступны);
· операции с битами и битовыми полями (поиск, выборка, вставка и замена);
· операции с изменением формата на лету (расширение нулём и знаком, перевод из вещественных в целые или обратно, изменение точности, маскированная запись);
· условные операции (копирование, запись константы);
· многоразрядные операции с переносом (для наращивания размера обрабатываемых данных, если они не умещаются в одном регистре);
· команды с регулировкой точности (умножение с получением только старшей или младшей половины результата, приближённые вещественные вычисления и увеличение их точности аппроксимацией);
· слитые команды (умножение-сложение, сложение-вычитание, сравнение-обмен, синус-косинус, перетасовка компонентов вектора, минимум, максимум, среднее, модуль, знак);
· горизонтальная арифметика (источники и приёмник являются компонентами одного вектора);
· недеструктивные операции (приёмник не перезаписывает источники — не требуется предварительная команда копирования одного из операндов в новый регистр);
· программно-специфичные команды (подсчёт контрольной суммы и битовой населённости, поиск подстроки, сумма модулей разностей, индекс и значение минимума в векторе, скалярное произведение).
По числу пунктов выше видно, что добавление дополнительных наборов команд — один из основных методов увеличения скорости ЦП. Уже сейчас общее число команд в архитектуре x86 перевалило за 1000, что привело к исключительному усложнению декодеров и ФУ, а также к сильному затруднению программирования и оптимизации на ассемблере. Тем не менее, Intel (а именно она ввела подавляющее большинство таких наборов) продолжает снабжать новые процессоры очередными видами инструкций, заставляя то же самое делать и конкурента.