




Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозациси обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время, данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звз^ания реальных музыкальных инструментов.
Основные структуры данных
Работа с большими наборами данных автоматизируется проще, когда дднные упорядочены, то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, иерархическая и табличная. Их можно рассмотреть на примере обычной книги.
Если разобрать книгу на отдельные листы и перемешать их, книга потеряет свое назначение. Она по-прежнему будет представлять набор данных, но подобрать адекватный метод для получения из нее информации весьма непросто. (Еще хуже дело будет обстоять, если из книги вырезать каждую букву отдельно, — в этом слз^ае вряд ли вообще найдется адекватный метод для ее прочтения.)
Если же собрать все листы книги в правильной последовательности, мы получим простейшую структуру данных — линейную. Такую книгу уже можно читать, хотя для поиска нужных данных ее придется прочитать подряд, начиная с самого начала, что не всегда удобно.
Для быстрого поиска данных существует иерархическая структура. Так, например, книги разбивают на части, разделы, главы, параграфы и т. п. Элементы структуры более низкого уровня входят в элементы структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д.
Для больших массивов поиск данных в иерархической структуре намного проще, чем в линейной, однако и здесь необходима навигация, связанная с необходимостью просмотра. На практике задачу упрощают тем, что в большинстве книг есть вспомогательная перекрестная таблица, связывающая элементы иерархической структуры с элементами линейной структуры, то есть связывающая раздель!, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой, рассчитанных на последовательное чтение, эту таблицу принято называть оглавлением, а в книгах со сложной структурой, допускающей выборочное чтение, ее называют -содержанием.
Линейные структуры (списки данных, векторы данных)
Линейные структуры — это хорошо знакомые нам списки. Список — это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Обычный журнал посещаемости занятий, например, имеет структуру списка, поскольку все студенты группы зарегистрированы в нем под своими уникальными номерами. Мы называем номера уникальными потому, что в одной группе не могут быть зарегистрированы два студента с одним и тем же номером.
При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как разыскивать нужные элементы. В журнале посещаемости, например, это решается так: каждый новый элемент списка заносится с новой строки, то есть разделителем является конец строки. Тогда нужный элемент можно разыскать по номеру строки__
N п/п Фамилия, Имя, Отчество
1 Аистов Александр Алексеевич
2 Бобров Борис Борисович
3 Воробьева Валентина Владиславовна
27 Сорокин Сергей Семенович
Разделителем может быть и какой-нибудь специальный символ. Нам хорошо известны разделители между словами — это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ «*». Тогда список выглядел бы так:
Аистов Александр Алексеевич * Бобров Борис Борисович * Воробьева Валентина
Владиславовна *... * Сорокин Сергей Семенович
В этом случае для розыска элемента с номером п надо просмотреть список начиная с самого начала и пересчитать встретившиеся разделители. Когда будет отсчитано n-i разделителей, начнется нужный элемент. Он закончится, когда будет встречен следующий разделитель.
Еще проще можно действовать, если все элементы списка имеют равную длину. В этом случае разделители в списке вообще не нужны. Для розыска элемента с номером п надо просмотреть список с самого начала и отсчитать а{n\) символ, где n — длина одного элемента. Со следующего символа начнется нужный элемент.
Его длина тоже равна n, поэтому его конец определить нетрудно. Такие упрощенные списки, состоящие из элементов равной длины, называют векторами данных. Работать с ними особенно удобно.
Таким об^гзои, линейные структуры данных (списки) — это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
Табличные структуры (таблицы данных, матрицы данных)
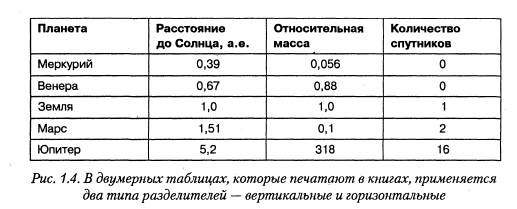
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить всем известную таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, когда таблицы печатают в книгах, строки и столбцы разделяют графическими элементами — линиями вертикальной и горизонтальной разметки (рис. 1.4).
Если нужно сохранить таблицу в виде длинной символьной строки, используют один символ-разделитель между Элементами, принадлежащими одной строке, и
другой разделитель для отделения строк, например так:
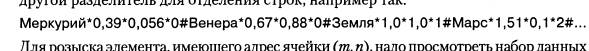
Для розыска элемента, имеющего адрес ячейки (m, n), надо просмотреть набор данных с самого начала и пересчитать внешние разделители. Когда будет отсчитан m-1 разделитель, надо пересчитывать внутренние разделители. После того как будет найден п-\ разделитель, начнется нужный элемент. Он закончится, когда будет встречен любой очередной разделитель.
Еще проще можно действовать, если все элементы таблицы имеют равную длину. Такие таблицы называют матрицами. В данном случае разделители не нужны, поскольку все элементы имеют равную длину и количество их известно. Для розыска элемента с адресом (m, n) в матрице, имеющей М строк и N столбцов, надо просмотреть ее с самого начала и отсчитать
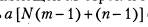 , где а — длина
, где а — длина
одного элемента. Со следующего символа начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить нетрудно.
Таким образом, табличные структуры данных {матрицы) — это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерные таблицы. Выше мы рассмотрели пример таблицы, имеющей два измерения (строка и столбец), но в жизни нередко приходится иметь дело с таблицами, у которых количество измерений больше. Вот пример таблицы, с помощью которой может быть организован учет учащихся.
Номер курса (на факультете): 2
Номер специальности (на курсе): 2
Номер группы в потоке одной специальности: 1
Номер учащегося в группе: 19
Размерность такой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).

