Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации = 1 байту (1 байт = 8 битов).
Для кодирования одного символа требуется один байт информации.
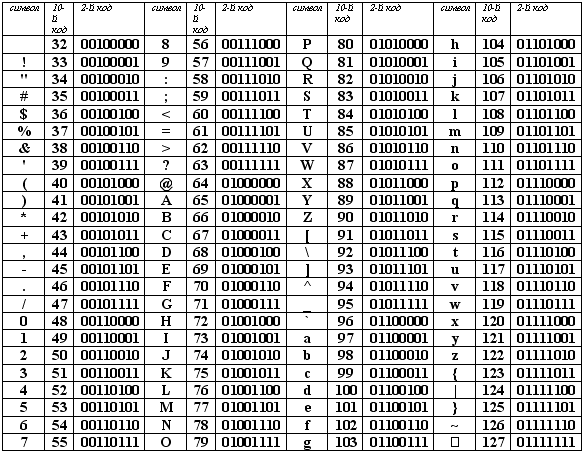
Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28 = 256)
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255).
Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды), называется таблицей кодировки.
Для разных типов ЭВМ используются различные кодировки. С распространением IBM PC международным стандартом стала таблица кодировки ASCII (A merican S tandard C ode for I nformation I nterchange) – Американский стандартный код для информационного обмена.
Стандартной в этой таблице является только первая половина, т.е. символы с номерами от 0 (00000000) до 127 (0111111). Сюда входят буква латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы.
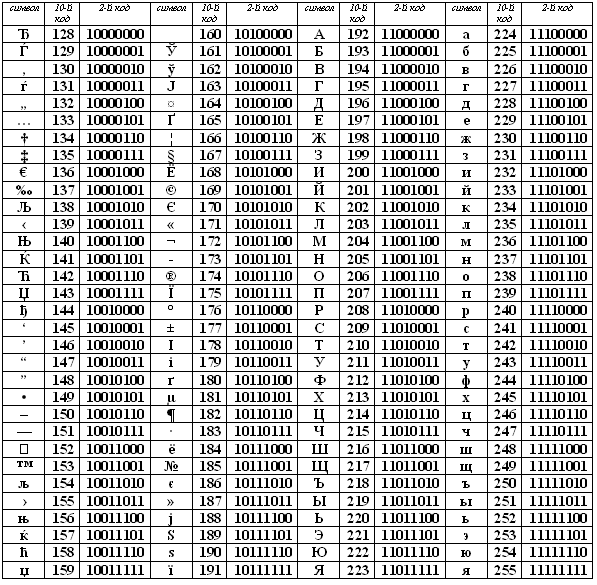
Остальные 128 кодов используются в разных вариантах. В русских кодировках размещаются символы русского алфавита.
В настоящее время существует 5 разных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO).
В настоящее время получил широкое распространение новый международный стандарт Unicode, который отводит на каждый символ два байта. С его помощью можно закодировать 65536 (216= 65536) различных символов.
Таблица стандартной части ASCII