




Для передачи информации между собой люди используют знаки и символы. Начав с простейших условных жестов, человек создал целый мир знаков, где главным средством общения стал язык (т.е. речь и письменность). Слово есть минимальная первичная единица языка, представляющая собой специальный набор символов и служащая для наименования понятий, предметов, действий и т.п. Следующим по сложности элементом языка является предложение — конструкция, выражающая законченную мысль. На основе предложений строится текст. Текст (от лат. textus — ткань, соединение) - высказывание, выходящее за рамки предложения и представляющее собой единое и целое, наделенное внутренней структурой и организацией в соответствии с правилами языка. С появлением вычислительных машин стала задача представления в цифровой форме нечисловых величин, и в первую очередь — символов, слов, предложений и текста.
Символы
Для представления символов в числовой форме был предложен метод кодирования, получивший в дальнейшем широкое распространение и для других видов представления нечисловых данных (звуков, изображений и др.). Кодом называется уникальное беззнаковое целое двоичное число, поставленное в соответствие некоторому символу. Под алфавитом компьютерной системы понимают совокупность вводимых и отображаемых символов. Алфавит компьютерной системы включает в себя арабские цифры, буквы латинского алфавита, знаки препинания, специальные символы и знаки, буквы национального алфавита, символы псевдографики — растры, прямоугольники, одинарные и двойные рамки, стрелки. Первоначально для хранения кода одного символа отвели 1 байт (8 битов), что позволяло закодировать алфавит из 256 различных символов. Система, в которой каждому символу алфавита поставлен в соответствие уникальный код, называется кодовой таблицей. Разные производители средств вычислительной техники создавали для одного и того же алфавита символов свои кодовые таблицы. Это приводило к тому, что символы, набранные с помощью одной таблицы кодов, отображались неверно при использовании другой таблицы. Для решения проблемы многообразия кодовых таблиц в 1981 г. Институт стандартизации США принял стандарт кодовой таблицы, получившей название ASCII (American Standard Code of Information Interchange — американский стандартный код информационного обмена). Эту таблицу использовали программные продукты, работающие под управлением операционной системы MS-DOS, разработанной компанией Microsoft по заказу крупной фирмы — производителя персональных компьютеров IBM (International Business Machine).
Широкое распространение персональных компьютеров фирмы IBM привело к тому, что стандарт ASCII приобрел статус международного.
В таблице ASCII содержится 256 символов и их кодов. Таблица состоит из двух частей: основной и расширенной. Основная часть (символы с кодами от 0 до 127 включительно) является базовой, она в соответствии с принятым стандартом не может быть изменена. В нее вошли: управляющие символы (им соответствуют коды с 1 по 31), арабские цифры, буквы латинского алфавита, знаки препинания, специальные символы.
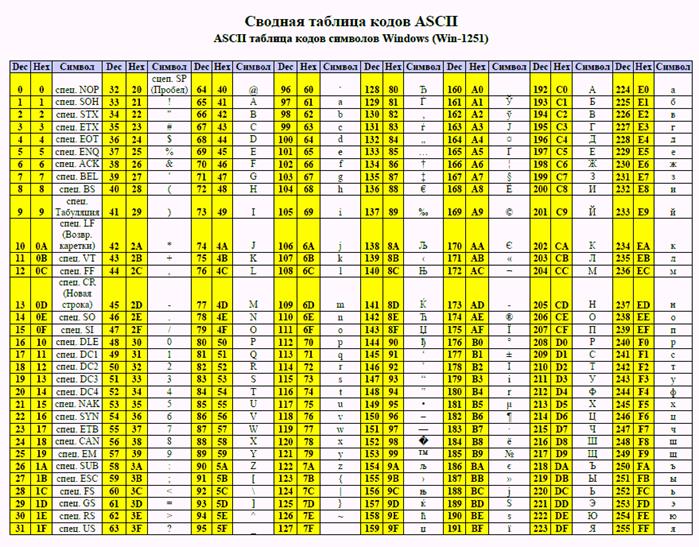
Расширенная часть (символы с кодами от 128 до 255) отдана национальным алфавитам, символам псевдографики и некоторым специальным символам. В соответствии с утвержденными стандартами эта часть таблицы изменяется в зависимости от национального алфавита той страны, где она используется, и способа кодирования. Именно поэтому, при наименовании программ, документов и других объектов желательно использовать латинские буквы, содержащиеся в основной, неизменяемой части таблицы, так как русскоязычные имена при несоответствии таблиц кодирования будут неверно отображаться. Например, операционная система Windows поддерживает большое число расширенных таблиц для различных национальных алфавитов. В России наиболее распространенной кодовой таблицей алфавита русского языка является «латиница Windows 1251».
Во многих странах Азии 256 кодов явно не хватило для кодирования их национальных алфавитов. В 1991 г. производители программных продуктов и организации, утверждающие стандарты, пришли к соглашению о выработке единого стандарта. Этот стандарт построен по 16 битной схеме кодирования и получил название UNICODE. Он позволяет закодировать  символов, которых достаточно для кодирования всех национальных алфавитов в одной таблице. Так как каждый символ этой кодировки занимает два байта (вместо одного, как раньше), все текстовые документы, представленные в UNICODE, стали длиннее в два раза. Современный уровень технических средств нивелирует этот недостаток UNICODE.
символов, которых достаточно для кодирования всех национальных алфавитов в одной таблице. Так как каждый символ этой кодировки занимает два байта (вместо одного, как раньше), все текстовые документы, представленные в UNICODE, стали длиннее в два раза. Современный уровень технических средств нивелирует этот недостаток UNICODE.

Текстовые строки. Текстовая (символьная) строка — это конечная последовательность символов. Это может быть осмысленный текст или произвольный набор, короткое слово или целая книга. Длина символьной строки — это количество символов в ней. Записывается в память символьная строка двумя способами: либо число, обозначающее длину текста, затем текст, либо текст, затем — разделитель строк.
Текстовые документы. Текстовые документы используются для хранения и обмена данными, но сплошной, не разбитый на логические фрагменты текст воспринимается тяжело. Структурирование теста достигается форматированием — специфическим расположением текста при подготовке его к печати. Для анализа структуры текста были разработаны языки разметки, которые устанавливают текстовые метки (маркеры или теги), используемые для обозначения частей документа, записывают вместе с основным текстом в текстовом формате. Программы, анализирующие текст, структурируют его, считывая теги.

