




Ћексичний анал≥з
–оль лексичних анал≥затор≥в
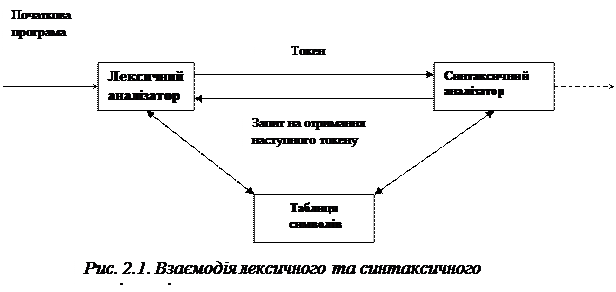
Ћексичний анал≥затор €вл€Ї собою першу фазу комп≥л€тора. …ого основне завданн€ пол€гаЇ в читанн≥ нових символ≥в ≥ видач≥ посл≥довност≥ токен≥в, використовуваних синтаксичним анал≥затором у своњй робот≥. Ќа рис. 2.1 схематично показана взаЇмод≥€ лексичного й синтаксичного анал≥затор≥в, що звичайно реал≥зуЇтьс€ шл€хом створенн€ лексичного анал≥затора €к п≥дпрограма синтаксичного анал≥затора (або п≥дпрограми, викликуваноњ ним). ѕри одержанн≥ запиту на наступний токен лексичний анал≥затор зчитуЇ вх≥дний пот≥к символ≥в до точноњ ≥дентиф≥кац≥њ наступного токена.
 |
ќск≥льки лексичний анал≥затор Ї частиною комп≥л€тора, що зчитуЇ вх≥дний текст, в≥н може також виконувати де€к≥ вторинн≥ завданн€ ≥нтерфейсу. ƒо них, наприклад, в≥днос€тьс€ видаленн€ з тексту вх≥дноњ програми коментар≥в ≥ не несучих значеннЇвого навантаженн€ пром≥жк≥в (а також символ≥в табул€ц≥њ й нового р€дка). ўе одна завданн€ пол€гаЇ в узгодженн≥ пов≥домлень про помилки комп≥л€ц≥њ й тексту вх≥дноњ програми. Ќаприклад, лексичний анал≥затор може п≥драхувати к≥льк≥сть л≥чених р€дк≥в ≥ вказати р€док, що викликав помилку. Ќа жаль, особливо в складних програмах ≥ складних мовах програмуванн€ така вказ≥вка помилки не завжди Ї в≥рною Ч ≥нод≥ помилка може бути розп≥знана т≥льки п≥сл€ зчитуванн€ дек≥лькох р€дк≥в. “ак≥ ситуац≥њ можуть зустр≥чатис€ й у комерц≥йних комп≥л€торах, хоча в цьому випадку вони досить р≥дк≥.
” де€ких комп≥л€торах лексичний анал≥затор створюЇ коп≥ю тексту вх≥дноњ програми ≥з вказ≥вкою помилок. якщо вх≥дна мова п≥дтримуЇ макроси й директиви препроцесора, то вони також можуть бути реал≥зован≥ лексичним анал≥затором.
Ќайчаст≥ше робота лексичного анал≥затора складаЇтьс€ ≥з двох фаз - скануванн€ й лексичного анал≥зу. ‘аза скануванн€ в≥дпов≥даЇ за виконанн€ найпрост≥ших завдань, у той час €к на фазу лексичного анал≥зу покладають б≥льш складн≥ завданн€. “ак, наприклад, комп≥л€тор може використати сканер дл€ видаленн€ ≥з вх≥дного тексту зайвих пром≥жк≥в.
«авданн€ лексичного анал≥зу
™ р€д причин, по €ких фаза анал≥зу комп≥л€ц≥њ розд≥л€Їтьс€ на лексичний ≥ синтаксичний анал≥зи.
1. ћабуть, найб≥льш важливою причиною Ї спрощенн€ розробки. ¬≥дд≥ленн€
лексичного анал≥затора в≥д синтаксичного часто дозвол€Ї спростити одну з фаз анал≥зу. Ќаприклад, включенн€ в синтаксичний анал≥затор коментар≥в ≥ пром≥жк≥в ≥стотно складн≥ше, н≥ж видаленн€ њх лексичним анал≥затором, ѕри створенн≥ новоњ мови под≥л лексичних ≥ синтаксичних правил може привести до б≥льше ч≥ткоњ ≥ €сноњ побудови мови.
2. «б≥льшуЇтьс€ ефективн≥сть комп≥л€тора. ќкремий лексичний анал≥затор дозвол€Ї створити спец≥ал≥зований ≥ потенц≥йно б≥льш ефективний процесор
дл€ р≥шенн€ поставленого завданн€. ќск≥льки на читанн€ вих≥дноњ програми й розб≥р њњ на токени витрачаЇтьс€ багато часу, спец≥ал≥зован≥ технолог≥њ буферизац≥њ йобробки токен≥в можуть ≥стотно п≥двищити продуктивн≥сть комп≥л€тора.
3. «б≥льшуЇтьс€ переносн≥сть (моб≥льн≥сть) комп≥л€тора. ќсобливост≥ вх≥дного алфавиту та ≥нш≥ специф≥чн≥ характеристики використовуваних пристроњв можуть обмежувати можливост≥ лексичного анал≥затора. Ќаприклад, у такий спос≥б може бути вир≥шена проблема спец≥альних нестандартних символ≥в, таких €к ↑ в Pascal.
|
|
|
≤снуЇ р€д спец≥ал≥зованих ≥нструмент≥в, призначених дл€ автоматизац≥њ побудови лексичних та синтаксичних анал≥затор≥в, нав≥ть ≥ у тому випадку, коли вони розд≥лен≥.
“окени, шаблони, лексеми
√овор€чи про лексичний анал≥з, ми використаЇмо терм≥ни "токен", "шаблон" й "лексема" кожний у своЇму власному визначенн≥. ѕриклади њхнього використанн€ наведен≥ на рис. 2.2. «агалом кажучи, у вх≥дному потоц≥ ≥снуЇ наб≥р р€дк≥в, дл€ €ких €к вих≥д отримуЇмо один ≥ той самий токен. ÷ей наб≥р р€дк≥в описуЇтьс€ правилом, ≥менованим шаблоном (pattern), пов'€заним з токеном. ѕро шаблон говор€ть, що в≥н в≥дпов≥даЇ (match) певному р€дку в набор≥. Ћексема ж €вл€Ї собою посл≥довн≥сть символ≥в вх≥дноњ програми, що в≥дпов≥даЇ шаблону токена. Ќаприклад, в ≥нструкц≥њ Pascal
const pi = 3.1416;
п≥др€док pi €вл€Ї собою лексему токена "≥дентиф≥катор". ѕриклади ≥нших токен≥в наведено на рис. 2.2.
| “окен | ѕриклад лексем | неформальний опис шаблона |
| const | const | const |
| if | if | if |
| relation | <, <=, =, <>, >, >= | < або <= або = або про або > або >= |
| id | pi, count, D2 | Ѕуква, за котрою ≥дуть букви або цифри |
| num | 3.1416, 0, 6.02E23 | Ѕудь-€ка числова константа |
| literal | "core dumped" | Ѕудь-€к≥ символи м≥ж парними лапками, за виключенн€м самих лапок |
–ис. 2.2. ѕриклади токен≥в
Ѕудемо розгл€дати токени €к терм≥нальн≥ символи граматики вх≥дноњ мови, дл€ позначенн€ €ких використовувати вид≥ленн€ ≥ншим шрифтом. Ћексеми, що в≥дпов≥дають шаблонам токен≥в, представл€ють у вх≥дн≥й програм≥ р€дки символ≥в, €к≥ розгл€даютьс€ разом €к лексична одиниц€.
” б≥льшост≥ мов програмуванн€ в €кост≥ токен≥в виступають ключов≥ слова, оператори, ≥дентиф≥катори, константи, р€дки л≥терал≥в ≥ символи пунктуац≥њ, наприклад дужки, коми й крапки з комами. ” наведеному вище приклад≥, коли у вх≥дному потоц≥ зустр≥чаЇтьс€ посл≥довн≥сть символ≥в pi, синтаксичному анал≥затору повертаЇтьс€ токен, що представл€Ї ≥дентиф≥катор. ѕоверненн€ токена найчаст≥ше реал≥зуЇтьс€ шл€хом передач≥ ц≥лого числа або покажчика, що в≥дпов≥даЇ системному токену.
Ўаблон - правило, що описуЇ наб≥р лексем, €к≥ можуть представл€ти певний токен у вх≥дн≥й програм≥. “ак, шаблон токена const (рис. 2.2) €вл€Ї собою просто р€док const, що Ї ключовим словом. Ўаблон токена relation - наб≥р вс≥х шести оператор≥в пор≥вн€нн€ в Pascal. ƒл€ точного опису шаблон≥в складних токен≥в типу id (дл€ ≥дентиф≥катора) ≥ num (дл€ числа) потр≥бно використати регул€рн≥ вирази, €ким присв€чений розд≥л 2.2.
” багатьох мовах р€д р€дк≥в Ї зарезервованим, тобто њхн≥й зм≥ст визначений ≥ не може бути зм≥нений користувачем. якщо ключов≥ слова не зарезервован≥, лексичний анал≥затор повинен ум≥ти визначити, ≥з чим в≥н маЇ справу - ключовим словом або ≥дентиф≥катором, уведеним користувачем.
јтрибути токен≥в
якщо шаблону в≥дпов≥даЇ к≥лька лексем, лексичний анал≥затор повинен забезпечити додаткову ≥нформац≥ю про лексеми дл€ наступних фаз комп≥л€ц≥њ. Ќаприклад, шаблон num в≥дпов≥даЇ €к р€дку 0, так й 1, ≥ при генерац≥њ коду надто важливо знати, €кий саме р€док в≥дпов≥даЇ токену.
|
|
|
Ћексичний анал≥затор збер≥гаЇ ≥нформац≥ю про токени у пов'€заних з ними атрибутах. “окени визначають роботу синтаксичного анал≥затора; атрибути Ц трансл€ц≥ю токен≥в. Ќа практиц≥ токени звичайно мають Їдиний атрибут Ц покажчик на запис у таблиц≥ символ≥в, у €к≥й збер≥гаЇтьс€ ≥нформац≥€ про токен. ƒл€ д≥агностичних ц≥лей можуть знадобитис€ €к лексеми ≥дентиф≥катор≥в, так ≥ номера р€дк≥в, у €ких вони вперше з'€вилис€ в програм≥. ¬с€ ц€ (й ≥нша) ≥нформац≥€ може збер≥гатис€ в записах у таблиц≥ символ≥в.
ѕриклад 2.1
“окени й пов'€зан≥ з ними значенн€ атрибут≥в дл€ ≥нструкц≥њ Fortran
≈ = ћ*C**2
записуютьс€ €к посл≥довн≥сть пар:
< id, покажчик на запис у таблиц≥ символ≥в дл€ ≈>
<assign_op, >
< id, покажчик на запис у таблиц≥ символ≥в дл€ ћ>
<mult_op, >
<id, покажчик на запис у таблиц≥ символ≥в дл€ C>
< ехр_ор, >
<num, ц≥ле значенн€ 2>.
ѕом≥тимо, що в де€ких парах немаЇ необх≥дност≥ в значенн≥ атрибута Ч першого компонента ц≥лком достатньо, щоб ≥дентиф≥кувати лексему. ” цьому невеликому приклад≥ токен num заданий атрибутом ≥з ц≥лим значенн€м. омп≥л€тор може збер≥гати р€док символ≥в, що становл€ть число, у таблиц≥ символ≥в, зробивши, таким чином, ат≠рибут токена num покажчиком на запис у таблиц≥ символ≥в.
јлфавит, р€дки ≥ мови

