




–асчет результатов анализа требует правильной записи исходных данных, проверки наличи€ дрейфа и вы€влени€ грубых промахов. ѕосле вычислени€ результаты усредн€ют, округл€ют и представл€ют в форме доверительных интервалов. ѕолученные результаты часто сопоставл€ют друг с другом или с некоторыми посто€нными величинами (нормативами). Ќа каждой из перечисленных стадий используют статистические алгоритмы. »х выбор зависит от характера распределени€ данных, т. е. от методики анализа. “ак, если известно, что результаты подчин€ютс€ распределению ѕуассона, то отбраковку промахов и расчет доверительных интервалов ведут иными способами, чем при нормальном распределении. ƒалее будет рассмотрен наиболее важный случай Ц обработка нормально распределенных данных. ≈сли характер распределени€ неизвестен, результаты анализа обрабатывают с применением более сложных статистических алгоритмов (робастные методы, непараметрические критерии), описанных в специальной литературе.
«апись исходных данных. Ќемедленно после любого пр€мого измерени€ (взвешивани€, титровани€, фотометрировани€, измерени€ потенциала и т. п.) его результат должен быть записан в лабораторный журнал. Ќельз€ субъективно отбирать результаты (записывать одни, которые представл€ютс€ Ђправильнымиї, и не записывать другие). Ќе прин€то также отмечать Ђболее надежныеї и Ђменее надежныеї результаты измерений, все варианты одной выборки (например, объемы титранта, затраченные на повторные титровани€) должны учитыватьс€ в одинаковой степени. Ёто важное условие называет условием равноточности.
–езультаты пр€мых измерений записывают так, чтобы предпоследн€€ цифра не вызывала сомнений, а последн€€ Ц соответствовала абсолютной погрешности ( D ) данного измерени€. “ак, если объем титранта записан в виде 24 мл, это означает, что измерение проведено с погрешностью 1 мл; если же пользовались более точными приборами с погрешностью 0,1 мл, запись должна быть сделана в виде 24,0 мл, с трем€ значащими цифрами.
«начащими называют все достоверно известные цифры в числовом результате измерени€, а также первую из недостоверных. ¬ правильно записанном результате измерени€ значащими €вл€ютс€ все цифры, кроме 0, а также 0, если он стоит после других значащих цифр. Ќе следует путать число значащих цифр и число дес€тичных знаков (цифр, сто€щих после зап€той). ѕри подсчете количества значащих цифр положение зап€той не имеет значени€. “ак, в числе 0,0020 две значащие цифры и четыре дес€тичных знака, а в числе 200 Ц три значащих цифры и нет дес€тичных знаков. ѕри подобных подсчетах не учитываютс€ цифры в степенных множител€х, например, в числе 6,023Ј1023 Ц четыре значащих цифры. ќчень большие и очень малые величины рекомендуетс€ записывать именно в таком виде.
„исло значащих цифр характеризует относительную погрешность измерений. ≈сли результаты измерений записаны правильно, то, сопоставл€€ записи по числу значащих цифр, можно выделить более точные и менее точные данные. ¬озможно даже сопоставление разнородных величин, например, значений объема, массы и силы тока. „ем больше значащих цифр, тем ниже относительна€ погрешность и, следовательно, тем точнее соответствующие данные. ќдна значаща€ цифра указывает, что соответствующа€ величина измерена с относительной погрешностью от 10 до 100 %; две значащие цифры указывают на относительную погрешность от 1 до 10 %; три Ц от 0,1 до 1 % и т. д. –азумеетс€, записыва€ результат титровани€ или взвешивани€, нельз€ ни прибавл€ть лишние значащие цифры, ни тер€ть точность измерений из-за необоснованных округлений.
|
|
|
–езультаты всех измеренийзаписывают в лабораторный журнал в пор€дке их получени€. ≈сли данные получены при многократном измерении свойств одной и той же пробы, или при исследовании множества однотипных проб, относ€щихс€ к одному и тому же объекту (Ђпараллельные пробыї), следует проверить, не наблюдаетс€ ли дрейф результатов. Ќо дл€ достоверного вывода о наличии дрейфа нужно иметь выборку большого объема (7 и более вариант) и примен€ть специальные статистические алгоритмы. ѕолучив же результаты трех последовательных титрований Ц 19,9; 19,8 и 19,7 мл Ц нельз€ считать, что методика дает дрейф, дл€ такого вывода слишком мало данных! ≈сли наличие дрейфа доказано с требуемой надежностью, то проводить статистическую обработку результатов нельз€. Ќужно найти причину дрейфа, устранить ее, а затем повторить анализ.
¬ы€вление и отбраковка грубых промахов. ¬ полученной выборке всегда вызывают сомнени€ наименьший и наибольший результаты Ц не грубые ли это промахи? —уществуют специальные алгоритмы дл€ проверки наличи€ грубых промахов. »х выбирают в зависимости от того, по какому закону распределены варианты генеральной совокупности (все возможные результаты измерений данной величины по данной методике). ”читывают также, сколько вариант входит в имеющуюс€ в распор€жении аналитика выборку, известно ли стандартное отклонение дл€ данной методики измерений, а также другие факторы. Ќадежность любой методики отбраковки промахов тем выше, чем больше вариант было в выборке. ≈сли при повторных измерени€х получено не менее 5 вариант, причем известно, что варианты распределены нормально, а стандартное отклонение методики неизвестно Ц отбраковку промахов провод€т с помощью Q-теста. ƒл€ проверки сомнительной варианты х 1 (наименьшего результата) рассчитывают Qэксп по формуле:
Qэксп =  . (2.7)
. (2.7)
ѕри проверке сомнительной варианты xn (наибольшего результата) пользуютс€ формулой:
Qэксп =  , (2.8)
, (2.8)
где xn и x 1 Ц крайние варианты в ранжированной выборке, а x 2 и xn Ц1 Ц варианты, ближайшие к ним. —омнительна€ варианта (х 1 или xn) отбрасываетс€, если по абсолютной величине Qэксп оказываетс€ больше, чем Qтабл дл€ желаемой надежности вывода (P) и данного числа вариант (n). ќбычно используетс€ значение P = 0,95. ≈сли же Qэксп < Qтабл, считают, что с требуемой надежностью промах не вы€влен, и сомнительную варианту оставл€ют.
ѕример 2.4. –ассмотрим выборку 19,7; 20,6; 19,8; 19,7; 19,9; 19,6. ≈сть ли здесь промахи?
–ешение. —омнени€ вызывает втора€, наибольша€ варианта. ѕо формуле (2.8) Qэксп = (20,6 Ц 19,9) / (20,6 Ц 19,6) = 0,7 / 1,0 = 0,7. ¬оспользовавшись статистическими таблицами, находим Qтабл. ƒл€ n = 6 и P = 0,95 значение Qтабл равно 0,64. —ледовательно, с надежностью 0,95 можно считать второе титрование ошибочным, а его результат Ц грубым промахом. ќтбраковка промаха приведет к изменению среднего результата титровани€ и другому значению стандартного отклонени€.
|
|
|
≈сли в одной и той же выборке одновременно присутствуют два промаха, то вы€вить их с помощью Q-теста обычно не удаетс€. ¬ таких случа€х рекомендуетс€ использовать более строгие критерии, например, пользоватьс€ методом максимальных относительных отклонений. ѕодсчитывают, на сколько выборочных стандартных отклонений отстоит от среднего арифметического кажда€ из сомнительных вариант. ¬арианты, дл€ которых отношение (х Ц  )/ s превыс€т некоторое критическое (табличное) значение, учитывающее объем выборки и требуемую надежность вывода, считают грубыми промахами и отбрасывают. Ётот критерий, как и Q-тест, применим лишь к тем выборкам, которые отвечают нормальному распределению. —татистические критерии такого типа называют параметрическими.
)/ s превыс€т некоторое критическое (табличное) значение, учитывающее объем выборки и требуемую надежность вывода, считают грубыми промахами и отбрасывают. Ётот критерий, как и Q-тест, применим лишь к тем выборкам, которые отвечают нормальному распределению. —татистические критерии такого типа называют параметрическими.
¬ аналитическом контроле технологических процессов, в отличие от научных исследований, по экономическим соображени€м не провод€т большого числа повторных измерений, не анализируют множество параллельных проб одного материала. ак правило, ограничиваютс€ двум€ измерени€ми. ¬ы€вить, не €вл€етс€ ли одно из двух полученных значений х грубым промахом, нельз€ ни с помощью Q-теста, ни с помощью других критериев. Ќо можно воспользоватьс€ тем, что воспроизводимость измерений по данной методике известна. ќна оцениваетс€ стандартным отклонением (s), указанным в описании методики или установленным при аттестации методики. Ќадо определить, на сколько единиц s отличаютс€ обе полученные варианты. ѕри нормальном распределении веро€тность случайного расхождени€ вариант больше чем на 4s очень мала (< 0,05). ≈сли реальное отличие двух результатов анализа окажетс€ больше 4s, одну из вариант следует считать грубым промахом. ѕо€вление Ђнесовместимыхї вариант не дает оснований отбраковать какую-то из них, но указывает на необходимость повторени€ анализа. “огда, получив еще несколько вариант, можно будет определить, какое из первоначальных измерений дало грубый промах, и отбросить соответствующий результат. »ногда критерий совместимости (4s) замен€ют более строгим (6s) или менее строгим (3s). ¬ описании же методики анализа обычно выражают этот критерий пр€мо в единицах измер€емой величины, даже не указыва€ s. Ќапример, пишут: Ђесли результаты определени€ ванади€, найденные при анализе двух параллельных проб одной и той же стали, отличаютс€ менее чем на 0,1 % (абс.), то их среднее арифметическое считают равным действительному содержанию ванади€. ≈сли же отличие полученных результатов больше 0,1 %, то необходимо проанализировать еще две-три пробы, а затем вы€вить и отбраковать грубый промахї.
ѕри дальнейшем изложении будем предполагать, что в исходных данных грубые промахи уже вы€влены и исключены.
ќкругление результатов расчета. –езультат анализа, вычисленный с помощью калькул€тора или компьютера, округл€ют, чтобы точность результата расчета соответствовала бы точности исходных данных. ќкругление ведут по общеприн€тым математическим правилам, но, определ€€ степень округлени€, руководствуютс€ следующими рекомендаци€ми:
при сложении и вычитании в результате расчета оставл€ют столько дес€тичных знаков, сколько их было в самом неточном слагаемом. Ќапример, 20,3402 г + 0,12 гї 20,46 г. «десь одно из слагаемых было известно с точностью до четвертого дес€тичного знака, до 0,0001 г, а другое, менее точно определенное, Ц лишь до второго, до 0,01 г, поэтому и сумму округл€ют до второго знака, до сотых долей грамма.
при умножении и делении в результате расчета оставл€ют столько значащих цифр, сколько их было в наименее точном из исходных сомножителей (содержащем наименьшее число значащих цифр). Ќапример, 25,1645 г / 25,0 млї 1,01 г/мл. „астное округлено до трех значащих цифр, посколько столько их было в делителе. ≈сли в качестве сомножителей используют посто€нные коэффициенты, не €вл€ющиес€ результатом измерени€ и известные совершенно точно, то число значащих цифр в этих коэффициентах не учитывают.
при извлечении корн€ и возведении в степень относительна€ погрешность и число значащих цифр сохран€ютс€. —ледовательно, 0,92 ї 0,8, а не 0,81;  ї 17,3, но
ї 17,3, но  ї 2!
ї 2!
|
|
|
при логарифмировании и потенцировании в мантиссе должно быть оставлено столько значащих цифр, сколько их имеетс€ в логарифмируемом числе, и наоборот;
при многоступенчатых расчетах промежуточные результаты рекомендуетс€ записывать с лишними значащими цифрами. ƒо нужной степени округл€ют лишь окончательный результат. ѕеречисленные выше рекомендации относ€тс€ не только к результатам анализа, но и к любым расчетам, включающим результаты измерений.
–асчет доверительных интервалов. –езультат анализа желательно выражать в виде доверительного интервала.
ƒоверительным интервалом называют интервал значений х, в котором в отсутствие систематических ошибок с заданной веро€тностьюP находитс€ неизвестное истинное содержание определ€емого компонента.
ќбычно доверительные интервалы рассчитывают дл€ – = 0,95. »ногда используют значени€ доверительной веро€тности P = 0,90 или – = 0,99, а дл€ наиболее ответственных анализов можно даже вз€ть – = 0,999. ѕоследнее означает, что веро€тность нахождени€ истинного значени€ (m) измер€емой величины вне границ интервала (так называемый уровень значимости) не превысит 0,001, т. е. будет менее одного шанса из тыс€чи. ѕри прочих равных услови€х ширина доверительного интервала должна быть тем больше, чем больше желаема€ веро€тность P.
≈сли значение s дл€ данной методики анализа известно, границы доверительного интервала рассчитать довольно просто. ћожно найти эти границы, даже исход€ из единичного результата анализа. ¬ этом случае пользуютс€ формулой:
(x Ц u s) < m < (x + u s). (2.9)
оэффициент u зависит от выбранной доверительной веро€тности (P). ≈го наход€т с использованием таблицы функций Ћапласа. «начени€м –, равным 0,90; 0,95; 0,99 и 0,999, в этой таблице соответствуют значени€ u, равные 1,65; 1,96; 2,58; 3,29.
Ћучше рассчитывать границы доверительного интервала, исход€ из среднего результата, полученного по выборке из n вариант. ѕри n > 1 применима формула:
(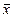 Ц u s /
Ц u s / 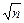 ) < m < ( + u s / ). (2.10)
) < m < ( + u s / ). (2.10)
¬еличину u s / (или u s, если n = 1) называют полушириной доверительного интервала. ƒл€ оценки истинного значени€ измер€емой величины часто пользуютс€ двухсигмовым интервалом (x ± 2s), в такой интервал неизвестное значение m попадает с веро€тностью, чуть большей 95 %. ≈сли доверительный интервал получаетс€ слишком широким, следует увеличить в n раз число параллельных проб или повторных измерений, в этом случае ширина интервала сократитс€ в раз. ћожно даже оценить, сколько раз надо повтор€ть анализ, чтобы получить требуемую полуширину доверительного интервала (D X).
√ораздо сложнее достоверно оценить границы доверительного интервала при неизвестной величине s. Ёта задача встает перед аналитиками очень часто: в их распор€жении оказываетс€ лишь небольша€ выборка экспериментальных данных (результатов повторных измерений или результатов анализа параллельных проб), и нужно оценить границы, в которых с заданной веро€тностью находитс€ неизвестное истинное содержание компонента. «адача решаетс€ по-разному, смотр€ по тому, каково распределение вариант, получаемых с помощью данной методики измерений. ƒл€ нормально-распределенных вариант используетс€ способ, предложенный в начале ’’ века английским математиком ¬. √оссетом (—тьюдентом). ќн доказал, что с надежностью – можно считать, что
( Ц t s / ) < m < ( + t s / ),(2.11)
где t Ц коэффициент, завис€щий от P и n. ѕри прочих равных услови€х величина t снижаетс€ по мере роста n и возрастает по мере роста P. «начени€ t (коэффициентов —тьюдента) приведены в виде таблиц во всех статистических справочниках. ѕри пользовании ими следует учитывать, что вместо P в них часто указывают значени€ уровней значимости (a), дополн€ющие P до единицы, а вместо n указывают число степеней свободы df. ѕри расчете доверительных интервалов df = n Ц 1.
|
|
|
„тобы обеспечить более высокую веро€тность попадани€ неизвестного истинного значени€ измер€емой величины в границы доверительного интервала, придетс€ расшир€ть этот интервал. “ой же цели можно добитьс€, увеличива€ число повторных измерений, либо переход€ к другой методике, дающей лучшую сходимость (меньшее значение s).
ѕример 2.5. ѕолучена выборка из п€ти вариант 17, 21, 18, 20, 19. «десь  = 19; s = 1,58. ѕо таблицам —тьюдента находим: t = 2,78 (P = 0,95, n = 5). ќтсюда Δ х = 1,97, а округл€€ Δ x в большую сторону до одной значащей цифры (при расчете доверительных интервалов обычно поступают именно так), можно считать, что Δ хї 2. “огда истинное значение измер€емой величины с 95 %-ной надежностью должно попасть в доверительный интервал 19 ± 2, т. е. от 17 до 21.
= 19; s = 1,58. ѕо таблицам —тьюдента находим: t = 2,78 (P = 0,95, n = 5). ќтсюда Δ х = 1,97, а округл€€ Δ x в большую сторону до одной значащей цифры (при расчете доверительных интервалов обычно поступают именно так), можно считать, что Δ хї 2. “огда истинное значение измер€емой величины с 95 %-ной надежностью должно попасть в доверительный интервал 19 ± 2, т. е. от 17 до 21.
Ќеобходимо помнить, что формулы —тьюдента справедливы только при одновременном выполнении трех условий: а) методика измерений не дает систематических погрешностей; б) результаты измерений по данной методике подчин€ютс€ нормальному распределению, независимы друг от друга и равноточны; в) отсутствуют дрейф и грубые промахи.
—опоставление результатов анализа. —татистическое сравнение результатов анализа позвол€ет химику делать обоснованные выводы. јналитикам требуетс€ оценивать степень различи€ результатов анализа, полученных дл€ одного и того же объекта по разным методикам. ј другие специалисты таким же образом сравнивают результаты анализа, полученные по одной и той же методике дл€ нескольких однотипных объектов. ¬ы€вленные различи€ могут оказатьс€ статистически достоверными, тогда они будут воспроизводитьс€ при повторении анализов. ≈сли же различи€ статистически недостоверны, их можно объ€снить не действительными отличи€ми сравниваемых методик или объектов анализа, а случайными факторами и малым объемом сопоставл€емых выборок.
–езультаты анализов обычно сравнивают по воспроизводимости и по среднему значению. ƒл€ этого вначале надо выполнить несколько (не менее двух) серий однотипных анализов и записать полученные выборки. ¬арианты сравниваемых выборок должны быть однотипными по своей природе, иметь одинаковую размерность и близкую величину. ќбъем выборок может различатьс€. Ќеобходимо заранее проверить характер распределени€ вариант, отбраковать грубые промахи и убедитьс€ в отсутствии дрейфа. —опоставление выборок по воспроизводимости должно предшествовать сравнению средних
—равнение двух выборок по воспроизводимости обычно ведут с помощью критери€ ‘ишера. Ќесколько выборок сопоставл€ют более сложными способами, пользу€сь критери€ми Ѕартлета, охрена и др. ≈сли хот€т использовать критерий ‘ишера, наход€т дисперсии обеих сопоставл€емых выборок и дел€т большую на меньшую, независимо от объема той и другой. ѕолученное значение F =  сопоставл€ют с табличным значением критери€ ‘ишера дл€ некоторого значени€ доверительной веро€тности (например, дл€ P = 0,95) с учетом числа вариант в той и другой выборке. ѕри F > Fтабл делают вывод о достоверном различии выборок по воспроизводимости измерений.
сопоставл€ют с табличным значением критери€ ‘ишера дл€ некоторого значени€ доверительной веро€тности (например, дл€ P = 0,95) с учетом числа вариант в той и другой выборке. ѕри F > Fтабл делают вывод о достоверном различии выборок по воспроизводимости измерений.
—равнение средних значений двух выборок провод€т по критерию —тьюдента. “акое сопоставление возможно, если: а) в обеих выборках отсутствуют грубые промахи; б) измер€ема€ величина имеет нормальное распределение; в) дисперсии обеих выборок близки между собой. ƒл€ сравнени€ средних вначале вычисл€ют t по формуле:
 , (2.12)
, (2.12)
где в числителе сто€т средние арифметические первой и второй выборок, а в знаменателе Ц обобщенное стандартное отклонение. ѕоследнюю величину считают по-разному:
sd =  при n 1 = n 2 = n, (2.13)
при n 1 = n 2 = n, (2.13)
sdї 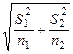 при n 1 ї n 2. (2.14)
при n 1 ї n 2. (2.14)
¬еличину t сравнивают с табличным значением дл€ выбранной доверительной веро€тности, при этом учитывают число вариант в каждой выборке. –азличие средних достоверно, если найденное значение t больше, чем tтабл . ≈сли t меньше, чем tтабл, то различие средних считаетс€ статистически недоказанным. ќднако в этом случае не следует утверждать, что результаты анализа, представленные данными двух выборок, достоверно совпадают.
ѕример 2.6. —одержание вредного вещества в сточной воде до очистки определ€ли по трем параллельным пробам. ѕолучили следующие результаты (в мг/л): 129, 117 и 136. ќтобрали также три пробы очищенной сточной воды и проанализировали по той же методике. –езультаты: 98, 111 и 107 мг/л. ƒостоверно ли уменьшение среднего содержани€ примеси в результате очистки сточной воды или его можно объ€снить случайными погрешност€ми анализа?
|
|
|
–ешение. ѕрежде всего находим 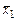 = 127,
= 127,  = 105. ”меньшение среднего результата невелико и действительно может быть следствием случайных ошибок анализа, поэтому необходима статистическа€ проверка. ритерий ‘ишера дл€ P = 0,95 и соответствующего числа вариант равен 19,2. ƒисперсии:
= 105. ”меньшение среднего результата невелико и действительно может быть следствием случайных ошибок анализа, поэтому необходима статистическа€ проверка. ритерий ‘ишера дл€ P = 0,95 и соответствующего числа вариант равен 19,2. ƒисперсии:  = 92,
= 92,  = 44. ќтношение дисперсий
= 44. ќтношение дисперсий  = 2,08, оно намного меньше, чем Fтабл. “аким образом, воспроизводимость анализов до и после очистки можно считать примерно одинаковой. Ёто позвол€ет сравнивать по способу —тьюдента средние содержани€ примеси до и после очистки воды. “абличное значение t дл€ P = 0,95 и 4 степеней свободы равно 2,78. ѕо формуле (2.13) находим: sd = 6,8. ѕо формуле (2.12) t эксп = (127 Ц 105) / 6,8 = 3,26, что больше t табл. —ледовательно, различие средних статистически значимо, его нельз€ объ€снить случайными погрешност€ми анализа. Ёффект очистки невелик, но достоверен (на уровне P = 0,95).
= 2,08, оно намного меньше, чем Fтабл. “аким образом, воспроизводимость анализов до и после очистки можно считать примерно одинаковой. Ёто позвол€ет сравнивать по способу —тьюдента средние содержани€ примеси до и после очистки воды. “абличное значение t дл€ P = 0,95 и 4 степеней свободы равно 2,78. ѕо формуле (2.13) находим: sd = 6,8. ѕо формуле (2.12) t эксп = (127 Ц 105) / 6,8 = 3,26, что больше t табл. —ледовательно, различие средних статистически значимо, его нельз€ объ€снить случайными погрешност€ми анализа. Ёффект очистки невелик, но достоверен (на уровне P = 0,95).
–ассмотренный выше алгоритм используют и при вы€влении дрейфа. ¬ этом случае всю совокупность результатов (в пор€дке их получени€) дел€т на две части. «атем оценивают различие средних значений обеих групп. ≈сли они достоверно различаютс€, дрейф считают статистически доказанным. ќднако этот способ применим не всегда, существуют и другие способы проверки. —татистические алгоритмы позвол€ют сравнивать результаты анализа не только друг с другом, но и с некоторыми нормативами. Ётот прием широко примен€етс€ в аналитическом контроле производства.
2.6. јприорна€ оценка точности анализа
и пути ее повышени€*
“очность любой методики анализа можно оценить двум€ разными методами, хорошо дополн€ющими друг друга.
1. ћожно оценить погрешности всех исходных данных (элементарные погрешности), а затем сложить их по специальным правилам. —пособ применим дл€ любых косвенных измерений, он позвол€ет еще до проведени€ анализа (заранее, априорно) быстро оценить общую погрешность будущего анализа. ќднако обычно ее реальна€ величина оказываетс€ выше ранее сделанных прогнозов. Ёто св€зано с по€влением дополнительных систематических погрешностей, св€занных с Ђхимическимиї факторами (неверно выбранным индикатором, неполным переводом вещества в осадок, наложением сигналов разных компонентов пробы и т. п.). ¬прочем, дополнительные погрешности можно заранее оценить, а затем исключить.
2. ћожно математически обработать результаты множества анализов, уже проведенных по исследуемой методике. –езультаты сопоставл€ютс€ с данными, относ€щимис€ к некоторым эталонам или стандартной методике. —оответствующие анализы и расчеты провод€тс€ по строго определенным правилам, в рамках процедуры, называемой метрологической аттестацией методики. “акой способ длителен и трудоемок, но дает гораздо более надежные результаты, чем априорные оценки.
ќценка элементарных погрешностей. „асто в описании методик измерений (взвешивани€, измерени€ объема и т. п.) величины соответствующих элементарных погрешностей (далее Ц D) не указаны. “огда дл€ оценки D сравнивают результат измерени€ с другим, полученным с помощью иного прибора или по иной методике, дл€ которых погрешность измерений пренебрежимо мала. –асхождение результатов, полученных по провер€емой и по эталонной методикам, считают равным искомой величине D. ≈сли же эталонных способов измерени€ в нашем распор€жении нет, можно приблизительно оценить D с помощью р€да простых приемов.
Ј —амый простой и распространенный способ Ц по цене делени€ измерительного прибора. “ак, жела€ отмерить 250 мл раствора с помощью цилиндра, у которого делени€ нанесены через 10 мл, можно ошибитьс€ на 10 мл. Ёто значение и берут в качестве оценки элементарной погрешности[2]. ƒанный способ не учитывает ни воспроизводимости измерений, ни систематических ошибок, т. е. дает заниженную оценку D.
Ј ћожно вычислить D, если измерить по той же методике или с помощью того же прибора другой образец, однотипный исследуемому, но c точно известным значением m. јбсолютные погрешности измерений дл€ обоих образцов считают одинаковыми. Ётот способ оценки также не учитывает воспроизводимость измерений.
Ј ѕровод€т несколько повторных измерений соответствующей величины дл€ одного и того же объекта и оценивают расхождени€ полученных результатов. “ак, если на одних и тех же весах одна и та же масса оказалась при повторных взвешивани€х 0,6547 г; 0,6608 г; 0,6531 г; 0,6472 г, то с учетом разброса результатов следует считать, что абсолютна€ погрешность этих весов имеет величину пор€дка 0,01 г. Ётот способ оценки также дает заниженное значение D, не включающее систематическую составл€ющую общей погрешности. Ќе исключено, что при использовани€ подход€щего эталона абсолютна€ погрешность весов оказалась бы большей, например 0,10 г.
ѕравила сложени€ погрешностей. „тобы оценить возможную погрешность косвенных измерений, надо складывать погрешности всех исходных данных (элементарные погрешности) по специальным правилам. ѕри этом следует учитывать как характер элементарных погрешностей (случайные или систематические, независимые или взаимосв€занные), так и то, какие именно математические действи€ производ€тс€ над исходными данными при расчете результата анализа. ѕусть y Ц результат анализа (или другого косвенного измерени€), рассчитываемый на основе нескольких x Ц результатов пр€мых измерений, от€гощенных погрешност€ми. ƒопустим, что известны только максимально возможные значени€ каждой из элементарных погрешностей (по абсолютной величине). «наки каждой погрешности не учитывают. ƒопустим также, что при получении каждого x основную роль играют систематические погрешности (эта ситуаци€ весьма типична). ¬ таких случа€х результирующую погрешность (D y) рассчитывают по формулам:
при y = x 1 + x 2 или при y = x 1 Ц x 2
½D y ½ = ½D x 1½ + ½ D x 2 ½, (2.15)
при y = x 1 x 2 или при y = x 1 / x 2
½D y / y ½ = ½D x 1 / x 1½ + ½D x 2 / x 2½. (2.16)
ак видно из формулы (2.15), при оценке точности сумм и разностей суммируют модули абсолютных погрешностей всех слагаемых. ак видно из (2.16), при оценке точности произведений или частных суммируют модули относительных погрешностей сомножителей.
≈сли погрешности измерени€ разных x в основном нос€т случайный характер, то при y = x 1 x 2 или y = x 1 / x 2следует заранее оценить относительное стандартное отклонение каждого аргумента, а затем использовать формулу:
(s y / y)2 = (s x 1/ x 1)2 + (s x 2/ x 2)2. (2.17)
ѕример 2.7. ѕогрешность аналитических весов Dg по модулю не превышает 0,001 г, масса тары с навеской (m) Ц 10,192 г, а масса пустой тары (m 0) Ц 10,002 г. ќпределить абсолютную (D m) и относительную (D m, %) погрешность определени€ массы навески (mн).
–ешение. »спользуем формулу (2.15), это приводит к D m = 2 D g = 0,002 г. ћасса навески равна 0,190 г. ќтносительна€ погрешность вз€ти€ навески Ђпо разностиї: 0,002 г Ј 100 % / 0,190 гї 1 %. «аметим, что массу навески мы определили с довольно большой относительной погрешностью, тогда как единичное взвешивание тары давало очень небольшую относительную погрешность (пор€дка 0,01 %)! «десь про€вл€етс€ общее правило: относительна€ погрешность разности двух близких величин гораздо больше относительной погрешности исходных измерений.
ѕример 2.8. ¬ мерной колбе готов€т по точной навеске раствор некоторого вещества. онцентрацию (—) рассчитывают по результатам пр€мых измерений массы реактива (m), объема колбы (V) и содержани€ (m) основного вещества в реактиве. Ёто содержание известно с точностью до 1 % и равно 99 %. Ќавеска реактива массой 5,000 г вз€та на весах, дающих погрешность пор€дка 0,001 г. ќбъем мерной колбы на 50 мл известен с точностью до 0,1 мл. ќценить относительную погрешность концентрации полученного раствора.
–ешение. онцентрацию раствора рассчитываем по формуле — = m m / V, котора€ приводит к значению — = 0,100 г/мл. “ак как в ходе расчета проводили действи€ умножени€ и делени€, сложение элементарных погрешностей требует применени€ формулы (2.16). ѕрогнозируема€ относительна€ погрешность концентрации равна:
D C / C = Dm / m + D m/m + D V/V = (1/99) + (0,001/5) + (0,1/50) ї
ї 0,01 + 0,0002 + 0,002ї 0,012, т. е. 1,2 %.
—опоставление слагаемых по величине показывает, что основную роль в данном случае играет неопределенность состава реактива, гораздо меньшее значение имеет неточность объема мерной колбы, а вли€нием погрешности взвешивани€ можно пренебречь. “ак поступают, когда одно слагаемое на пор€док (в 10 и более раз) меньше других.
¬ случа€х, не требующих высокой точности расчетов, можно считать, что точность конечного результата анализа (y) определ€етс€ лишь одним Ц наименее точным Ц слагаемым или сомножителем. ¬ этом случае также следует сопоставл€ть либо абсолютные, либо относительные погрешности всех исходных данных. ј именно: при сложении и вычитании наименее точным слагаемым считают то, у которого была сама€ больша€ абсолютна€ погрешность, тогда можно считать, что D yї D x. ѕри умножении или делении наименее точным сомножителем считают тот, у которого сама€ больша€ относительна€ погрешность. ¬ этом случае D y / yї D x / x. ≈сли же y получают, умножа€ результат пр€мого измерени€ x на посто€нный, точно известный коэффициент , не €вл€ющийс€ результатом измерени€, относительна€ погрешность y равна относительной погрешности x и не зависит от .
”чет дополнительных погрешностей. ƒопустим, железо в руде определ€ют титриметрическим методом. ¬начале отбирают некоторую пробу руды и точно измер€ют ее массу (m, г), взвешива€ пробу на аналитических весах. «атем пробу раствор€ют в кислоте, перевод€т соединени€ железа в ионы Fe2+. полученному раствору постепенно прибавл€ют из бюретки раствор KMnO4 с точно известной концентрацией (—), прекраща€ этот процесс (титрование) при по€влении розовой окраски, свидетельствующей о достижении точки эквивалентности. ќбъем затраченного раствора KMnO4 (титранта) точно измер€ют (V, мл). Ќаконец, подставл€ют V, C и m в соответствующие расчетные формулы (см. раздел 5.2) и вычисл€ют массовую долю железа в руде (w), основыва€сь на известном уравнении реакции между Fe2+ и KMnO4. «атем суммируют погрешности измерени€ V, C и m по формуле (2.16), аналогично примеру 9.
ƒополнительные погрешности анализа по изложенной методике могли быть св€заны с неоднородностью состава руды, погрешност€ми пробоотбора, неполным переводом железа в ионы Fe2+, неверно установленным моментом окончани€ титровани€ и т. п. ¬ пробе могли присутствовать другие вещества, которые реагировали с титрантом (чтобы проверить это предположение, потребовалось бы провести качественный анализ руды).
Ќекоторые дополнительные погрешности можно исключить, изменив методику анализа. ƒругие можно оценить расчетным путем, а затем исключить их, введ€ соответствующие поправки в результат анализа. ћожно, в частности, учесть неполное осаждение определ€емого вещества (Ђпотери при осажденииї), неточный подбор индикатора (Ђиндикаторные погрешностиї), вли€ние примесей в реактивах (Ђхолостой опытї) и т. п. “ак, если основным источником погрешности будет неполное осаждение Fe(OH)3 из-за проведени€ осаждени€ в слишком кислой среде или в присутствии веществ, св€зывающих Fe3+ в растворимые комплексные соединени€, следует ожидать получени€ заниженных результатов анализа. ћожно даже рассчитать, какова будет ошибка анализа, если проводить осаждение при том или другом значении рЌ. ¬месте с тем, если в пробе железной руды, которую анализируют гравиметрическим методом, имеетс€ примесь алюмини€ или титана, то гидроксиды этих элементов будут осаждатьс€ вместе с гидроксидом железа. ѕосле прокаливани€ осадка его масса окажетс€ больше массы оксида железа, результат определени€ железа будет завышенным. “от же эффект дадут примеси железа в растворител€х и химических реактивах, используемых в ходе анализа. “акие погрешности можно и нужно исключить, введ€ в результат анализа поправку на холостой опыт.
сожалению, многие дополнительные погрешности (например, погрешности пробоотбора или персональные) заранее рассчитать и исключить очень трудно, их вли€ние оцениваетс€ только в ходе метрологической аттестации методики.
ћетрологическа€ аттестаци€ методики. „тобы результаты количественного химического анализа были официально признаны (Ђимели юридическую силуї), соответствующа€ методика анализа должна быть заранее согласована с органами √осстандарта, а дл€ этого требуетс€ провести ее метрологическую аттестацию. ѕри этом можно использовать разные способы, в частности: анализ стандартных образцов, сравнение с более точной методикой, имеющей известные метрологические характеристики (стандартной методикой), а также метод добавок (Ђвведено Ц найденої).
ѕринципы этих методов уже были охарактеризованы в разделе 2.4. ћетрологическа€ аттестаци€ требует определенного (весьма большого) объема экспериментальных данных и проводитс€ по детально разработанным правилам, изложенным в нормативных документах √осстандарта. ¬ качестве примера рассмотрим метод аттестации, основанный на применении стандартных образцов. ¬ этом случае в лаборатории надо будет проанализировать не менее трех однотипных —ќ, близких по свойствам и составу, но существенно различных по содержанию определ€емого компонента (’). —одержание ’ должно охватывать интервал концентраций, в котором планируетс€ примен€ть аттестуемую методику. аждый —ќ анализируют не менее 10 раз, причем аналитический сигнал в каждом случае также измер€ют несколько раз. «атем массив полученных данных обрабатывают с помощью специальных компьютерных программ, получа€ дл€ каждого —ќ значени€ четырех статистических показателей. Ёто показатель сходимости sсх, показатель воспроизводимости sвоспр, показатель правильности Dс и показатель точности D. ¬се четыре показател€ получают в тех же единицах, в которых представлены сами результаты. ƒва первых показател€ характеризуют случайную составл€ющую общей погрешности (без учета и с учетом пробоотбора), третий Ц систематическую составл€ющую, четвертый Ц общую погрешность. –езультаты аттестации позвол€ют пон€ть, одинакова или различна погрешность анализа дл€ разных содержаний определ€емого компонента. ≈сли эти погрешности достаточно малы, методика утверждаетс€. ѕолученные в ходе аттестации показатели методики используют дл€ расчета допустимых расхождений между результатами повторных анализов, а также дл€ статистического контрол€ работы лаборатории.
—пособы повышени€ точности анализа. ƒл€ достижени€ этой цели надо прежде всего пон€ть, кака€ из составл€ющих общей погрешности Ц случайна€ или систематическа€ Ц в данном случае €вл€етс€ основной. »менно ее и следует снижать в первую очередь, а затем перейти к устранению другой составл€ющей, меньшей по величине. ƒобитьс€ высокой точности только путем повышени€ правильности или только путем повышени€ воспроизводимости анализа нельз€, надо использовать оба направлени€. —пособы устранени€ случайных и систематических погрешностей различны. –азумеетс€, существуют и общие рекомендации, при выполнении которых уменьшаютс€ обе погрешности (тщательное выполнение операций, описанных в методике; сокращение числа операций; использование приборов высокого качества, поверенных с помощью надежных эталонов; оптимизаци€ условий проведени€ анализа и т. п.), но этого недостаточно, нужны специализированные способы, которые мы и рассмотрим по отдельности.
—нижение вли€ни€ случайных погрешностей достигаетс€ трем€ основными способами: а) стабилизаци€ условий проведени€ анализа; б) увеличение числа повторных измерений; в) повышение количества и размера проб исследуемого материала.
—табилизаци€ условий требует, чтобы все операции, выполн€емые по ходу анализа, и особенно измерение аналитического сигнала проводились на одних и тех же приборах, с применением одной и той же мерной посуды, одних и тех же растворов и реагентов, одним и тем же человеком (этот подход иногда снижает не только случайную, но и систематическую погрешность). ƒаже пор€док смешивани€ реактивов должен быть одним и тем же. ¬ли€ние колебаний рЌ при переходе от пробы к пробе можно устранить с помощью буферных растворов; вли€ние колебаний температуры Ц путем термостатировани€ исследуемых проб. олебани€ напр€жени€ в сети не скажутс€ на результатах анализа, если включать измерительный прибор через дополнительный стабилизатор. —писок подобных рекомендаций можно продолжить, они специфичны дл€ каждого метода анализа. —табилизаци€ условий достигаетс€ и путем автоматизации анализа Ц компьютерна€ программа, в отличие от человека-оператора, обеспечит дл€ всех проб строго одинаковую методику проведени€ анализа.
”величение числа повторных измерений аналитического сигнала существенно снижает вли€ние случайных погрешностей. —овременные автоматизированные аналитические приборы оснащают программным обеспечением, в котором предусматриваетс€ интегрирование и усреднение результатов многократных измерений. Ќапример, потенциал электрода измер€етс€ ежесекундно в течение 100 секунд, а затем по сохраненным в пам€ти прибора результатам повторных измерений автоматически вычисл€етс€ среднее арифметическое. »менно оно затем высвечиваетс€ на шкале прибора или используетс€ дл€ автоматического расчета концентрации.
≈сли основной вклад в общую дисперсию результатов анализа вносит не стади€ измерени€ сигнала, а пробоотбор (так бывает нередко, особенно при анализе твердых и неоднородных материалов), то многократные измерени€ сигнала не помогут добитьс€ высокой воспроизводимости результатов анализа в целом. Ќеобходимо случайным образом отбирать большее число проб исследуемого материала, а затем усредн€ть полученные результаты. “ак как неоднородность состава твердых материалов (например, горных пород или почвы) выражена преимущественно на микроуровне, следует брать пробы по возможности большего объема, а затем измельчать их, тщательно перемешивать и лишь затем уменьшать массу пробы.
ƒл€ профилактики систематических погрешностей особенно важны: выбор оптимальной методики, отделение и маскирование мешающих веществ, правильна€ настройка измерительных приборов, применение чистых реактивов, выбор наиболее подход€щих эталонов, а также использование оптимальных способов расчета. ≈сть способы, специфичные дл€ каждого метода анализа, они будут рассмотрены при изучении этих методов. ќднако есть и общие способы, т. е. приемы, применимые дл€ любых объектов и методов анализа. ќдним из таких приемов €вл€етс€ рандомизаци€. Ётот терминозначает перевод систематической погрешности в разр€д случайных, а затем ее уменьшение путем усреднени€. “ак, определение концентрации ионов кадми€ можно проводить по нескольким разным методикам. ажда€ из них дает некоторую систематическую погрешность, одни методики будут давать завышенное, другие Ц заниженное содержание кадми€. ¬ серии результатов, полученных по разным методикам, погрешности приобретут случайный характер, будут компенсировать друг друга при усреднении. —реднее арифметическое окажетс€ близким к истинному содержанию кадми€. ¬ыигрыш будет тем большим, чем больше разных методик используют.
онтрольные вопросы
1. „то обозначают термины Ђколичество веществаї, Ђмол€рна€ концентраци€ї, Ђмольна€ дол€ї, Ђэквивалентї? ак св€заны друг с другом мол€рна€ и нормальна€ концентраци€ одного и того же раствора? ак рассчитать мол€рную концентрацию раствора, если известна его процентна€ концентраци€ (массова€ дол€) и плотность?
2. ѕриведите 3Ц4 примера пр€мых измерений и столько же примеров косвенных измерений, которые можно провести в химической лаборатории. акие средства измерений примен€ют при выполнении химических анализов?
3. „то такое Ђабсолютна€ погрешностьї? акую размерность может она иметь при проведении количественного химического анализа? — какой абсолютной погрешностью измер€ют объем раствора, если пользуютс€: а) мерной колбой на 200,0 мл; б) пипеткой на 5,00 мл; в) бутылкой на 0,5 л?
4. „то такое Ђотносительна€ погрешностьї? ќцените относительную погрешность, с которой взвешивают продукты (~ 0,5 кг) на торговых весах. ќцените относительную погрешность, с которой берут навески анализируемых веществ (~ 0,25 г) на аналитических весах. C какой относительной погрешностью нам известны атомные массы элементов, если судить по тому, как они записаны в таблице атомных масс?
5. „ем отличаютс€ друг от друга систематическа€ и случайна€ погрешности измерений? ак оценить ту и другую? огда можно считать одну из этих величин незначимой по сравнению с другой?
6. ѕочему результат химического анализа можно считать случайной величиной? акие ¬ам известны теоретические распределени€ случайных величин? „ем отличаетс€ нормальное распределение случайных величин от других распределений?
7. „то такое воспроизводимость, сходимость, правильность, точность? ак ¬ы понимаете термины Ђвыборкаї, Ђдисперси€ї, Ђвариантаї, Ђматематическое ожиданиеї?
8. ак рассчитать стандартное отклонение некоторой выборки? √де в химическом анализе используетс€ эта величина? ак св€зана воспроизводимость результатов анализа с концентрацией определ€емого компонента? „то такое Ќ√ќ— и как можно оценить ее величину?
9. ак можно проверить правильность результатов анализа? акой из известных ¬ам способов проверки наиболее надежен?
10. ѕроверьте с помощью Q-теста, €вл€етс€ ли результат единичного анализа Ц 37,6 % Ц грубым промахом, если при повторении анализа того же материала получены результаты 37,2 %, 36,9 %, 37,4 % 37,0 %. ¬ каких случа€х така€ проверка может привести к ошибочным выводам?
11. ак правильно записать мол€рную концентрацию раствора NaCl, если навеску хлорида натри€ массой 1,763 г растворили в мерной колбе на 25,0 мл и довели полученный раствор водой до метки?
12. –асставьте несколько величин в пор€дке возрастани€ точности их измерени€: 0,002 м3; 920; 2100; 8100 г; 2,10 мл; 2100,0; 2,0Ј105 мин. ¬се величины записаны правильно, с учетом абсолютной погрешности соответствующих измерений.
13. —формулируйте известные вам по школьному курсу математики правила округлени€. —колько значащих цифр следует оставить в результате анализа, если его вычисл€ли путем умножени€ и делени€ результатов некоторых пр€мых измерений? —формулируйте правила записи результатов косвенных измерений при сложении и вычитании.
14. –ассчитайте по —тьюденту доверительный интервал дл€ влажности некоторого образца (в %), если три повторных результата анализа этого образца оказались равны 67, 64 и 66 %. ƒоверительную веро€тность выберите самосто€тельно. ¬ каких случа€х ¬аш расчет привел бы к ошибочной оценке измер€емой величины?
15. ¬ каких случа€х после получени€ результата анализа можно внести численную поправку к этому результату? ак это можно сделать и почему этого лучше не делать?
16. ак сравнить между собой результаты анализа одного и того же материала по двум разным методикам, если анализ по каждой методике повтор€ли несколько раз?
[1] ћетрологи считают, что систематической погрешностью можно пренебречь, если çq ç < 0,8 s. », напротив, случайной погрешностью можно пренебречь, если çq ç > 8 s. ¬ данном случае это условие выполн€етс€.
[2] ѕоэтому в этом случае надо было записать отмеренный объем как 0,25 л или 2,5Ј102 мл, но не как Ђ250 млї!

