




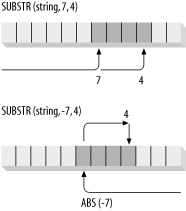
You will find that in practice SUBSTR is very forgiving. Even if you violate the rules for the values of the starting position and the number of characters to be substringed, SUBSTR will not generate errors. Instead, for the most part, it will return NULL—or the entire string—as its answer.
Here are some examples of SUBSTR:
· Return the last character in a string:
SUBSTR ('Another sample string', -1) --> 'g'This is the cleanest way to get the single last character. A more direct, but also more cumbersome approach is this:
SUBSTR ('Sample string', LENGTH ('Sample string'), 1) --> 'g'In other words, calculate the LENGTH of the string and the one character from the string that starts at that last position. Yuck.
· Remove an element from a string list. This is, in a way, the opposite of SUBSTR: I want to extract a portion or substring of a string and leave the rest of it intact. Oddly enough, I will use SUBSTR to perform this task. Suppose that my screen maintains a list of selected temperatures as follows:
|HOT|COLD|LUKEWARM|SCALDING|The vertical bar delimits the different items on the list. When the user deselects "LUKEWARM", I have to remove it from the list. The best way to accomplish this task is to determine the starting and ending positions of the item to be removed, and then use SUBSTR to take apart the list and put it back together—without the specified item. Let's walk through this process a step at a time. For example:
DECLARE my_list VARCHAR2(50); to_delete VARCHAR2(20); start_pos NUMBER; end_pos NUMBER;BEGIN my_list:= '|HOT|COLD|LUKEWARM|SCALDING|'; to_delete:= 'LUKEWARM'; start_pos:= INSTR(my_list, to_delete); --first char to delete end_pos:= start_pos + LENGTH(to_delete); --last char to delete my_list:= SUBSTR (my_list, 1, start_pos-1) || SUBSTR (my_list, end_pos+1);DBMS_OUTPUT.PUT_LINE(my_list);END;The output is:
|HOT|COLD|SCALDING|· Use SUBSTR to extract the portion of a string between the specified starting and ending points. I run into this requirement all the time. SUBSTR requires a starting position and the number of characters to pull out. Often, however, I have only the starting position and the ending position—and I then have to compute the number of characters in between. Is that just the difference between the end and start positions? Or is it one more or one less than that? Invariably, I get it wrong the first time and have to scribble a little example on scrap paper to prove the formula to myself.
So to save you the trouble, I offer a tiny function called betwnstr (for "BETWeeN STRing"). This function encapsulates the calculation you must perform to come up with the number of characters between the start and end positions, which is end_position - start_position + 1.
/* File on web: betwnstr.sf */FUNCTION betwnstr (string_in IN VARCHAR2, start_in IN INTEGER, end_in IN INTEGER) RETURN VARCHAR2ISBEGIN RETURN SUBSTR (string_in, start_in, end_in - start_in + 1);END;While this function does not provide the full flexibility offered by SUBSTR (for example, with negative starting positions), it offers a starting point for the kind of encapsulation you should be performing in these situations.
Like the INSTR and LENGTH families of functions, SUBSTR offers permutations useful in dealing with multibyte character sets and Unicode. The following PL/SQL block illustrates the difference between character and byte semantics:
DECLARE --NVARCHAR2 = UTF-16 in this example. x NVARCHAR2(50 CHAR):= UNISTR('The character a\0303 is the same as ã');BEGIN DBMS_OUTPUT.PUT_LINE(SUBSTR(x,25,4)); DBMS_OUTPUT.PUT_LINE(SUBSTRB(x,49,8));END;The output is:
samesameThe word "same" occupies four characters beginning at character position 25. In terms of bytes, though, it occupies eight bytes beginning at byte position 49. Because we're using the UTF-16 character set, each character occupies two bytes. The first 24 characters occupy the first 48 bytes; thus the 25th character begins at the 49th byte, and occupies bytes 49 and 50.
| TO_CHAR |
The TO_CHAR function converts national character set data into its database character set equivalent. The specification of TO_CHAR, at least for this usage, is as follows:
FUNCTION TO_CHAR( char_data IN NVARCHAR2) RETURN VARCHAR2The TO_CHAR function is defined to accept any of the following types as input: NCHAR, NVARCHAR2, CLOB, and NCLOB. The return type is always VARCHAR2.
Following is an example of TO_CHAR's being used to translate a string from the national character set into the database character set:
DECLARE a VARCHAR2(30); b NVARCHAR2(30):= 'Corner? What corner?';BEGIN a:= TO_CHAR(b);END;See the discussion of TO_NCHAR under Section 8.5 later in this chapter for information on converting in the other direction. Also see the TRANSLATE...USING function.
|

| TO_MULTI_BYTE |
TO_MULTI_BYTE translates single-byte characters to their multibyte equivalents. Some multibyte character sets, notably UTF-8, provide for more than one representation of a given character. In UTF-8, for example, letters such as "G" can be represented using one byte or using three bytes. TO_MULTI_BYTE lets you convert between the two representations. The function specification is as follows:
FUNCTION TO_MULTI_BYTE ( string IN VARCHAR2) RETURN VARCHAR2The datatype of the input value that you pass to TO_MULTI_BYTE determines the output datatype. The output datatype will always match the input datatype.
Following is an example of TO_MULTI_BYTE being used to convert the letter G into its multibyte representation. This example was generated on a system using UTF-8 as the national character set.
DECLARE g_one_byte NVARCHAR2 (1 CHAR):= 'G'; g_three_bytes NVARCHAR2 (1 CHAR); g_one_again NVARCHAR2(1 CHAR); dump_output VARCHAR2(30);BEGIN --Convert single-byte "G" to its multibyte representation g_three_bytes:= TO_MULTI_BYTE(g_one_byte); DBMS_OUTPUT.PUT_LINE(LENGTHB(g_one_byte)); DBMS_OUTPUT.PUT_LINE(LENGTHB(g_three_bytes)); SELECT DUMP(g_three_bytes) INTO dump_output FROM dual; DBMS_OUTPUT.PUT_LINE(dump_output); --Convert that multibyte representation back to a single byte g_one_again:= TO_SINGLE_BYTE(g_three_bytes); DBMS_OUTPUT.PUT_LINE(g_one_again || ' is ' || TO_CHAR(LENGTHB(g_one_again)) || ' byte again.');END;The output is:
13Typ=1 Len=3: 239,188,167G is 1 byte again.As you can see, the call to TO_MULTI_BYTE in line 8 returned a three-byte UTF-8 representation of the letter G. We then invoked TO_SINGLE_BYTE to convert that three-byte representation back into one byte.
| TO_SINGLE_BYTE |
TO_SINGLE_BYTE translates multibyte characters to their single-byte equivalents—exactly the reverse of what TO_MULTI_BYTE does. The specification is as follows:
FUNCTION TO_SINGLE_BYTE ( string IN VARCHAR2) RETURN VARCHAR2The datatype returned by TO_SINGLE_BYTE will always correspond to the input datatype. See the discussion of TO_MULTI_BYTE for an example of TO_SINGLE_BYTE in use.
| TRANSLATE |
The TRANSLATE function is a variation on REPLACE. REPLACE replaces every instance of a set of characters with another set of characters; that is, REPLACE works with entire words or patterns. TRANSLATE replaces single characters at a time, translating the nth character in the search set to the nth character in the replacement set. The specification of the TRANSLATE function is as follows:
FUNCTION TRANSLATE ( string_in IN VARCHAR2, search_set IN VARCHAR2, replace_set VARCHAR2)RETURN VARCHAR2where string_in is the string in which characters are to be translated, search_set is the set of characters to be translated (if found), and replace_set is the set of characters that will be placed in the string. Unlike REPLACE, where the last argument can be left off, you must include all three arguments when you use TRANSLATE. Any of the three arguments may, however, be NULL, in which case TRANSLATE always returns NULL.
Here are some examples of TRANSLATE:
TRANSLATE ('abcd', 'ab', '12') --> '12cd' TRANSLATE ('12345', '15', 'xx') --> 'x234x' TRANSLATE ('grumpy old possum', 'uot', '%$*') --> 'gr%mpy $ld p$ss%m' TRANSLATE ('my language needs the letter e', 'egms', 'X') --> 'y lanuaX nXXd thX lXttXr X'; TRANSLATE ('please go away', 'a', NULL) --> NULLYou can deduce a number of the usage rules for TRANSLATE from the above examples, but we'll spell them out here:
· If the search set contains a character not found in the string, then no translation is performed for that character.
· If the string contains a character not found in the search set, then that character is not translated.
· If the search set contains more characters than the replace set, then the "trailing" search characters that have no match in the replace set are removed from the string. In the following example, "a", "b", and "c" are changed to "z", "y", and "x", respectively. But the letter "d" is removed from the return string entirely because it had no corresponding character in the replace set.
TRANSLATE ('abcdefg', 'abcd', 'zyx') --> 'zyxefg'In these cases, NULL is the matching "character" for all extra characters in the search set. When you replace a character with NULL, it is the same as removing that character from the string.
· If any of the three arguments is NULL, then the result of the translation is NULL. This is consistent with a basic tenet of NULLs: apply an operation to an unknown value, and you always get an unknown value.
The TRANSLATE function comes in handy when you need to change a whole set of characters in a string, regardless of the order in which they appear.
| TRANSLATE...USING |
This function exists to provide ANSI compatibility, and translates character data between character sets. Because TRANSLATE... USING is so unusual, we provide the syntax for using it, rather than its specification:
TRANSLATE( text USING {CHAR_CS | NCHAR_CS}where:
text
Is the text you wish to translate. This may be a character variable, an expression, or a literal text string.
CHAR_CS
Specifies that the input text should be converted into the database character set.
NCHAR_CS
Specifies that the input text should be converted into the national character set.
The output datatype will be either VARCHAR2 or NVARCHAR2, depending on whether you are converting to the database or the national character set, respectively.
Following is a simple example showing the use of this function:
In this example, the characters in the string are represented using the database character set. TRANSLATE... USING converts those characters into their national character set equivalents.
|
| TRIM |
Oracle added the TRIM function in the Oracle8i release to increase compliance with the ANSI SQL standard. TRIM combines the functionality of RTRIM and LTRIM into one function. TRIM is a bit different from other SQL functions in that it allows the use of keywords where you would normally expect arguments. Well, what do you expect from a function designed by a committee?
TRIM is unusual in the same manner as TRANSLATE...USING, so again we provide syntax rather than a specification:
TRIM ([LEADING | TRAILING | BOTH] [ trim_character ] FROM trim_source )where:
trim_source
Is the string you wish to trim.
trim_character
Specifies the character you wish to remove from one or both ends of the string. The default is to trim spaces.
LEADING | TRAILING | BOTH
Indicates whether you wish to trim from the beginning of the string (LEADING), from the end of the string (TRAILING), or both (BOTH). The default is to trim from both ends.
Following are some examples of TRIM:
· Remove leading and trailing spaces from a string:
· TRIM(' Brighten the corner where you are. '); --> 'Brighten the corner where you are.'· Remove only leading spaces:
· x:= ' Brighten the corner where you are. ';· TRIM (LEADING FROM x) --> 'Brighten the corner where you are. '· Remove trailing periods:
· x:= 'Brighten the corner where you are.';· y:= '.';· TRIM (TRAILING y FROM x) --> 'Brighten the corner where you are'Given that TRIM is ANSI-standard, is there any reason to ever again use RTRIM or LTRIM? It turns out that there is. When using TRIM, you can specify only one character to trim. Using LTRIM and RTRIM, you can specify a string of characters to trim. For example:
RTRIM('Brighten the corner where you are.,:!..;:', '.,;:!') --> 'Brighten the corner where you are'With one function call, RTRIM has removed all trailing punctuation from the input string. Such a feat is simply not possible using TRIM. Well, it's possible if you wish to write a recursive PL/SQL function of your own that in turn invoked TRIM once for each possible punctuation character... but why bother?
| UNISTR |
UNISTR is the opposite of ASCIISTR, and converts a string into Unicode. You can represent non-printable characters in the input string using the \XXXX notation, where XXXX represents the Unicode code point value for a character. The specification for UNISTR is:
FUNCTION UNISTR ( string1 IN VARCHAR2) RETURN VARCHAR2;Following is an example of UNISTR in use:
BEGIN DBMS_OUTPUT.PUT_LINE(UNISTR('The letter \00E3 is not an ASCII character.'));END; The letter ã is not an ASCII character.
|
UNISTR gives you convenient access to the entire universe of Unicode characters, even those you cannot type directly from your keyboard.
| UPPER |
The UPPER function converts all letters in the specified string to uppercase. UPPER (and LOWER) is an overloaded function, and will return a fixed-length string if the incoming string is fixed-length. The specifications for the UPPER function are:
FUNCTION UPPER ( string1 IN CHAR) RETURN CHARFUNCTION UPPER ( string1 IN VARCHAR2) RETURN VARCHAR2UPPER will not change any characters in the string that are not letters, as case is irrelevant for numbers and special characters such as the dollar sign.
Here are some examples of the effect of UPPER:
UPPER ('Munising MI 49862') --> 'MUNISING MI 49862'UPPER ('Jenny') --> 'JENNY'The UPPER and LOWER functions are useful for guaranteeing a consistent case when comparing strings.

