




Character sets can be categorized in many different ways, but the distinctions that matter most to PL/SQL programmers are the following:
· Single-byte versus multibyte
· Fixed-width versus variable-width
Let's return for a moment to the 7-bit ASCII character set. The seven bits used to represent each character fit into a single byte, and each character is represented using a separate byte. Consequently, 7-bit ASCII is considered a single-byte character set. It's also considered a fixed-width character set, in that each character is represented using the same number of bytes (one in this case) as every other character.
Character sets capable of representing more than 256 characters—for example, the Unicode UTF-8 character set—often use single bytes to represent the traditional ASCII characters and perhaps some other commonly used characters, and multiple bytes to represent everything else. In UTF-8 characters are represented by as many as three bytes; for example, the letter G is represented numerically as 71 (or 0x41 in hexadecimal), whereas the Euro symbol (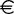 ) is represented as three bytes: 0xE282AC. In addition, some UTF-8 characters may be represented using surrogate pairs, which are special sequences of two characters that always use a total of four bytes. Character sets such as UTF-8 are multibyte because they use more than one byte for some characters, and they are variable-width because the number of bytes used per character is not always the same.
) is represented as three bytes: 0xE282AC. In addition, some UTF-8 characters may be represented using surrogate pairs, which are special sequences of two characters that always use a total of four bytes. Character sets such as UTF-8 are multibyte because they use more than one byte for some characters, and they are variable-width because the number of bytes used per character is not always the same.
A third class of character sets is multibyte and fixed-width. The Unicode UTF-16 character set is a good example of this class, as each UTF-16 character is represented using exactly two bytes. The letter A, for example, is represented as two bytes with values of 0 and 65 respectively.
|


