




Обработка одного оператора SQL - это самый простой способ выполнения SQL-запросов SQL. Шаги, используемые для обработки одного оператора SELECT, который ссылается только на локальные базовые таблицы (без представлений или удаленных таблиц), иллюстрируют основной процесс[7].
Допускается анализировать оптимизацию и в наиболее широком значении. Оптимизатор запросов подбирает самый наилучший метод выполнения запроса в базе популярных в оптимизаторе стратегий исполнения простых компонентов запроса и методов композиции наиболее трудоёмких стратегий в основе элементарных. Тем самым, место поиска рационального плана исполнения запроса ограничено предварительно зафиксированными простыми стратегиями. Следовательно значимым течением изысканий, напрямую сопредельным к вопросам оптимизации, представляется отбор новых, наиболее результативных простых стратегий. В контексте реляционных СУБД это больше всего принадлежит к исследованию результативных алгоритмов исполнения реляционной процедуры соединения более накладной реляционной процедуры.
Оптимизация операторов SELECT возможна. Вывод SELECT является непроцедурным, в нем не указаны точные шаги, которые сервер базы данных должен использовать для извлечения запрошенных данных. Это означает, что сервер базы данных должен анализировать оператор, чтобы определить наиболее эффективный способ извлечения запрошенных данных. Это называется оптимизацией оператора SELECT. Компонент, который делает это, называется оптимизатором запросов.
Ввод оптимизатора состоит из запроса, схемы базы данных (определения таблиц и индексов) и статистики базы данных. Результатом оптимизатора является план выполнения запроса, иногда называемый планом запроса или просто планом.
Входы и выходы оптимизатора запросов при оптимизации одного оператора SELECT показаны на следующей диаграмме (рисунок 3).
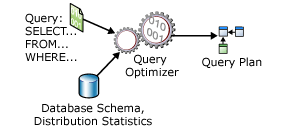
Рисунок 3 –Вход и выход оптимизатора
Оператор SELECT определяет только следующее[15]:
- Формат результирующего набора. Это чаще всего указывается в списке выбора. Однако другие предложения, такие как ORDER BY и GROUP BY, также влияют на окончательную форму набора результатов.
- Таблицы, содержащие исходные данные. Это указано в предложении FROM.Как логически связаны таблицы для целей инструкции SELECT. Это определено в спецификациях соединения, которые могут отображаться в предложении WHERE или в предложении ON, следующем за FROM.
- Условия, в которых строки в исходных таблицах должны удовлетворять требованиям для инструкции SELECT. Они указаны в предложениях WHERE и HAVING.
План выполнения запроса - это определение следующего:
1. Последовательность, в которой доступны исходные таблицы.
Как правило, существует множество последовательностей, в которых сервер базы данных может обращаться к базовым таблицам для построения набора результатов. Например, если оператор SELECT ссылается на три таблицы, сервер базы данных может сначала получить доступ к «TableA», использовать данные из таблицы A для извлечения соответствующих строк из «TableB», а затем использовать данные из «TableB» для извлечения данных из «TableC».
2. Методы, используемые для извлечения данных из каждой таблицы.
Как правило, существуют разные способы доступа к данным в каждой таблице. Если требуется только несколько строк с определёнными значениями ключа, сервер базы данных может использовать индекс. Если требуются все строки в таблице, сервер базы данных может игнорировать индексы и выполнять сканирование таблицы. Если все строки в таблице необходимы, но есть индекс, чьи столбцы ключей находятся в ORDER BY, выполнение сканирования индекса вместо сканирования таблицы может сохранить отдельный вид набора результатов. Если таблица очень маленькая, сканирование таблицы может быть наиболее эффективным методом почти для всего доступа к таблице.
Процесс выбора одного плана выполнения из потенциально многих возможных планов называется оптимизацией. Оптимизатор запросов является одним из наиболее важных компонентов системы базы данных SQL. Хотя некоторые служебные данные используются оптимизатором запросов для анализа запроса и выбора плана, эти служебные данные обычно сохраняются несколько раз, когда оптимизатор запросов выбирает эффективный план выполнения. Например, двум строительным компаниям могут быть предоставлены одинаковые чертежи для дома. Если одна компания проводит вначале несколько дней, чтобы планировать, как они построят дом, а другая компания начнет строить без планирования, компания, которая тратит время на планирование своего проекта, вероятно, закончит сначала[18].
Оптимизатор запросов SQL Server является оптимизатором затрат. Каждый возможный план выполнения имеет связанную стоимость с точки зрения количества используемых вычислительных ресурсов. Оптимизатор запросов должен проанализировать возможные планы и выбрать тот, у которого самая низкая оценочная стоимость. Некоторые сложные инструкции SELECT имеют тысячи возможных планов выполнения. В этих случаях оптимизатор запросов не анализирует все возможные комбинации. Вместо этого он использует сложные алгоритмы для нахождения плана выполнения, который имеет стоимость, близкую к минимально возможной стоимости[3].
Рассмотрим пример оптимизатора запросов SQL Server. Он не выбирает только план выполнения с самой низкой стоимостью ресурсов. Он выбирает план, который возвращает результаты пользователю с разумной стоимостью в ресурсах и который быстрее возвращает результаты. Например, обработка параллельного запроса обычно использует больше ресурсов, чем обработка по очереди, но быстрее выполняет запрос. Оптимизатор SQL Server будет использовать параллельный план выполнения, чтобы возвращать результаты, если нагрузка на сервер не пострадает[19].
Оптимизатор запросов основан на статистике распределения, когда оценивает затраты ресурсов на различные методы для извлечения информации из таблицы или индекса. Статистика распределения хранится для столбцов и индексов. Они указывают на избирательность значений в определённом индексе или столбце. Например, в таблице, представляющей автомобили, многие автомобили имеют один и тот же производитель, но каждый автомобиль имеет уникальный идентификационный номер автомобиля (VIN). Индекс VIN более селективен, чем индекс производителя. Если статистика индекса не является текущей, оптимизатор запросов может не сделать лучший выбор для текущего состояния таблицы. Дополнительные сведения о сохранении статистики индекса см. В разделе Использование статистики для повышения производительности запросов.
Оптимизатор запросов важен, поскольку он позволяет динамически настраивать сервер базы данных на изменение условий в базе данных, не требуя ввода от программиста или администратора базы данных. Это позволяет программистам сосредоточиться на описании конечного результата запроса. Они могут доверять тому, что оптимизатор запросов будет строить эффективный план выполнения для состояния базы данных каждый раз, когда выполняется оператор[8].

