




Необходимость исследования исходных данных на подчинение или неподчинение нормальному закону распределения обуславливается тем, что основные методы анализа - дисперсионных, регрессионный и корреляционный, в качестве одной из предпосылок, требуют нормального закона распределения.
Можно считать, что случайная величина распределена по нормальному закону распределения, если выполняются условия, являющиеся следствием из нормального закона распределения. Для проверки находят среднее абсолютное отклонение:
 (18)
(18)
Затем проверяют выполнение следующих условий:
1. Количество положительных и отрицательных отклонени от среднего - приблизительно равно.
2. Половина (или чуть больше) отклонений от среднего по абсолютной величине меньше среднего абсолютного отклонения:
 (19)
(19)
3. Ни одно из отклонений не превышает среднее абсолютное отклонение больше, чем в 3 раза:

Проведение такого исследования позволяет определить значения, которые являются “выбросами”.
Проанализировать выборку на подчинение нормальному закону распределения можно по характиристикам одномерного распределения, к которым относятся:
1. Меры положения (среднее, медиана, мода и др.).
2. Меры рассеивания (размах, коэффициент вариации, дисперсия, среднеквадратичное отклонение).
3. Меры формы (асиметрия, эксцесс и др.).
Существуют и другие возможные проверки.
Если все эти условия выполняются, то можно считать, что гипотеза о нормальном распределении не противоречит имеющимся данным.
Рассмотрим определение характеристик одномерного распределения.
Пример 5. При отборе средней пробы различных партий руды и ее последующего анализа были найдены значения  случайной величины Х - содержания меди в j -той пробе.Определить среднее, медиану, моду, размах, дисперсию, среднеквадратичное отклонение, асиметрию, эксцесс для выборки Х, приведенной в табл. 5.
случайной величины Х - содержания меди в j -той пробе.Определить среднее, медиану, моду, размах, дисперсию, среднеквадратичное отклонение, асиметрию, эксцесс для выборки Х, приведенной в табл. 5.
Таблица 5. Простой статистический ряд.
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
 ,% ,%
| 20,7 | 21,6 | 19,4 | 20,5 | 18,1 | 16,4 | 20,7 | 19,4 | 20,7 | 16,4 | 19,4 | 18,1 | 19,4 | 16,4 | 21,6 | 22,1 | 18,3 | 19,2 | 20,7 | 18,1 |
Решение
Среднее - среднее арифметическое определяется по формуле:
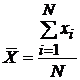 (20)
(20)
Для приведенных в табл.5 значений:
 (21)
(21)
Медиана - это значение, которое делит ранжированный вариационный ряд на две части, равные по числу вариант.
Для получения ранжированного вариационного ряда необходимо расположить исходные данные (табл. 5) в порядке возрастания (табл.6). Варианта х i - это како-либо конкретное значение выборки; частота ni показывает сколько раз повторяется значение х i в выборке.
Таблица 6. Статистическое распределение частот.
| № п/п | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Варианты | 16,4 | 18,1 | 18,3 | 19,2 | 19,4 | 20,5 | 20,7 | 21,6 | 22,1 |
| Частоты ni | 3 | 3 | 1 | 1 | 4 | 1 | 4 | 2 | 1 |
Если число вариант четное, то
 , (22)
, (22)
где х k и xk +1 - серединные варианты выборки.
В нашем случае число вариант нечетное (9), следовательно, медиана равна 19,4.
Если в множестве четное количеств чисел, то функция МЕДИАНА (Excel) вычисляет среднее двух чисел, находящихся в середине множества.
Мода - это значение, которое наблюдается наибольше число раз.
В нашем случае число 19,4 повторяется 4 раза. Значит мода равна 19,4.
Если в выборке нет повторяющихся значений, то модой является число, близкое к среднему, или совпадающее с ним. В Excel если множество данных не содержит одинаковых данных, то функция МОДА возвращает значение ошибки #Н/Д.
Размах - разность между наибольшей и наименьшей вариантами. В нашем примере это 22,1 - 16,4 = 5,7.

Дисперсия для признака метрической шкалы - это средний квадрат отклонений индивидуальных значений. Рассчитывают общую дисперсию, групповую дисперсию, межгрупповую дисперсию и т.п. В общем виде
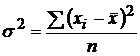
Для нашего случая

В Excel ДИСП использует следующую формулу:
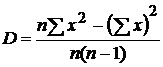
В нашем случае:

Среднеквадратичное отклонение - это мера того, насколько широко разбросаны точки данных относительно их среднего.

В нашем случае:

В Excel Стандартное отклонение (СТАНДОТКЛОНА) вычисляется с использованием "не Байесовского" или "n-1" метода по формуле:


Дисперсия, среднеквадратичное отклонение являются моментами случайной величины.
Метод моментов часто используется в прикладных задачах, когда вместо полного определения случайной величины в виде законов распределения вероятностей ее определяют при помощи числовых характеристик - чисел (вещественных), выражающих характерные особенности случайной величины, называемых моментами случайной величины.
Таблица - некоторые моменты случайной величины
| Порядок момента | Дискретные случайные величины | Непрерывные случайные величины | Обозначения |
| Начальный момент | |||
 , k=1,2,...,n , k=1,2,...,n
| 
| ||
| Начальный момент первого порядка (k=1) | 
| 
| M[X], mx, m. |
| Центральный момент | |||
 k=1,2,...,n k=1,2,...,n
| 
| ||
| Первый центральный момент всегда равен 0, | |||
| Второй центральный момент (k=2) | 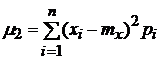
| 
| D[X], Dx, σx2, σ2. |
 =0.
=0.
Начальный момент первого порядка - математическое ожидание (средние значение при достаточном числе опытов) случайной величины.
Второй центральный момент - дисперсия случайной величины - математическое ожидание квадрата отклонения случайной величины от ее математического ожидания, т.е. D[X] = M[(x - mx)2]
Корень квадратный из второго центрального момента называется средним квадратичным отклонением (или стандартом).
Для определения асимметрии и эксцесса используют моменты 3-го и 4-го порядков.
Асимметрия - характеризует степень несимметричности распределения относительно его среднего. Положительная асимметрия 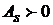 указывает на отклонение распределения в сторону положительных значений. Отрицательная асимметрия
указывает на отклонение распределения в сторону положительных значений. Отрицательная асимметрия  указывает на отклонение распределения в сторону отрицательных значений.
указывает на отклонение распределения в сторону отрицательных значений.
В первом приближении можно воспользоваться мерой асимметрии, как относительной статистической характеристикой, равной разнице между средним значением и медианою или модою, разделенной на среднеквадратичное отклонение.

 .
.
В нашем случае значения медианы и моды равны.
 - левосторонняя асимметрия,
- левосторонняя асимметрия,
Комплексная оценка асимметрии и эксцесса выполняется на основе центральных моментов распределения.

Пользуясь свойствами математического ожидания получают соотношения, связывающие начальные и центральные моменты. Так,
 .
.
Определяем начальные моменты:
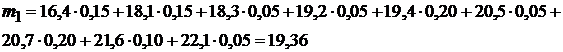
В нашем случае математическое ожидание случайной величины и значение среднего совпали.
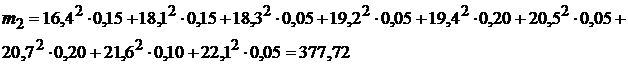


Тогда получаем:

Или по третьему центральному моменту с учетом математического ожидания:

При правосторонней асимметрии коэффициент , при левосторонней . Считается, что при  асимметрия низкая, если
асимметрия низкая, если  не превышает 0,5 - средняя, при
не превышает 0,5 - средняя, при 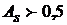 высокая.
высокая.
В Excel уравнение для асимметрии определяется следующим образом:


Если имеется менее трех точек данных, или стандартное отклонение равно нулю, то функция СКОС возвращает значение ошибки #ДЕЛ/0!.
Эксцесс характеризует относительную остроконечность или сглаженность распределения по сравнению с нормальным распределением. Для нормального распределения  . Если
. Если  , то это говорит о наличии островершинного распределения. При плосковершинном распределении
, то это говорит о наличии островершинного распределения. При плосковершинном распределении  .
.
 ,
,
где начальные моменты и центральный момент связаны по формуле:




В нашем случае  - распределение плосковершинное.
- распределение плосковершинное.
В некоторых учебника эксцесс вычисляют по формуле
 .
.
Тогда для нормального распределения  . Положительный эксцесс
. Положительный эксцесс  обозначает относительно остроконечное распределение. Отрицательный эксцесс
обозначает относительно остроконечное распределение. Отрицательный эксцесс  обозначает относительно сглаженное распределение.
обозначает относительно сглаженное распределение.
В Excel для расчета эксцесса используется формула (2.2), которая ориентирована на для нормального распределения.

 Т.к. , то распределение плосковершинное.
Т.к. , то распределение плосковершинное.
При использовании Excel следует учитывать, что если задано менее четырех точек данных или если стандартное отклонение выборки равняется нулю, то функция ЭКСЦЕСС возвращает значение ошибки #ДЕЛ/0!. Кроме того, если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые значения учитываются.
Проделанные расчеты сведены в таблицу.
Таблица - расчет некоторых числовых характеристик
| № п/п | Числовая характеристика | Расчетная формула | Значение | Excel | Значение |
| 1. | Среднее | 
| 19,36 | 
| 19,36 |
| 2. | Медиана | 
| 19,4 |
| 19,4 |
| 3. | Мода | Значение, которое наблюдается наибольше число раз | 19,4 | Если множество данных не содержит одинаковых данных, то функция МОДА возвращает значение ошибки #Н/Д. | 19,4 |
| 4. | Размах |
| 5,7 |
| 5,7 |
| 5. | Дисперсия | 
| 2,91 | 
| 3,06 |
| 6. | Среднеквадратичное отклонение | 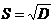
| 1,71 |
| 1,75 |
| 7. | Асимметрия | 
| -0,02 |  Если имеется менее трех точек данных, или стандартное отклонение равно нулю, то функция СКОС возвращает значение ошибки #ДЕЛ/0!.
Если имеется менее трех точек данных, или стандартное отклонение равно нулю, то функция СКОС возвращает значение ошибки #ДЕЛ/0!.
| -0,34 |

| -0,02 | ||||


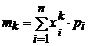
| -0,31 | ||||
| 7. | Эксцесс | 

| 1,20 |  Если задано менее четырех точек данных или если стандартное отклонение выборки равняется нулю, то функция ЭКСЦЕСС возвращает значение ошибки #ДЕЛ/0!. Если задано менее четырех точек данных или если стандартное отклонение выборки равняется нулю, то функция ЭКСЦЕСС возвращает значение ошибки #ДЕЛ/0!.
| -2,25 |
Ответ: В результате проделанных вычислений мы определили для выборки Х: среднее  , медиану
, медиану 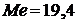 , моду
, моду  , размах 5,7, дисперсию
, размах 5,7, дисперсию  , среднеквадратичное отклонение
, среднеквадратичное отклонение  , асиметрию
, асиметрию  , эксцесс .
, эксцесс .
Пример 4. В результате химического эксперимента полученны следующие данные (табл.5). Проверить на подчинение нормальному закону распределения следующую выборку.
Таблица 5. Результаты химического эксперимента в ходе химико-технологического процесса
| Время | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Температура | 188 | 188 | 188 | 188 | 188 | 188 | 188 | 187 | 187 | 187 | 187 | 187 | 187 | 187 | 187 | 187 | 187 | 187 | 187 | 187 |
| Давление 1 | 3,86 | 3,60 | 2,94 | 3,57 | 2,95 | 3,99 | 3,73 | 3,05 | 3,23 | 2,53 | 3,22 | 3,43 | 3,43 | 3,66 | 3,70 | 3,70 | 3,72 | 3,85 | 3,45 | 3,45 |
| Давление 2 | 4 | 3 | 3 | 3 | 3 | 4 | 3,7 | 3 | 3 | 3 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 3 | 3 |
| Давление 3 | 4 | 3 | 2 | 3 | 2 | 4 | 3,7 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | 4 | 3 | 3 |
| Скорость на входе | 3,74 | 3,53 | 2,81 | 3,51 | 2,82 | 3,87 | 3,68 | 2,94 | 3,08 | 3,52 | 3,08 | 3,30 | 3,29 | 3,59 | 3,60 | 3,55 | 3,61 | 3,78 | 3,40 | 3,39 |
| Концентрация 1 | 0,86 | 0,55 | 0,74 | 0,49 | 0,78 | 0,83 | 0,33 | 0,72 | 0,95 | 0,65 | 0,93 | 0,88 | 0,91 | 0,55 | 0,72 | 0,98 | 0,80 | 0,58 | 0,43 | 0,43 |
| Концентрация 2 | 0,93 | 0,74 | 0,86 | 0,70 | 0,88 | 0,91 | 0,57 | 0,85 | 0,98 | 0,81 | 0,96 | 0,94 | 0,96 | 0,74 | 0,85 | 0,99 | 0,90 | 0,76 | 0,66 | 0,66 |
| Концентрация 3 | 0,07 | 0,05 | 0,06 | 0,05 | 0,06 | 0,07 | 0,04 | 0,6 | 0,07 | 0,06 | 0,07 | 0,07 | 0,07 | 0,05 | 0,06 | 0,07 | 0,7 | 0,06 | 0,05 | 0,05 |
| Давление 4 | 2 | 3 | 2 | 3 | 2 | 2 | 2,2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | 2 | 3 | 3 | 3 |
| РН1 | 5 | 5 | 5 | 5 | 5 | 5 | 4,9 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| РН2 | 3 | 2 | 3 | 2 | 3 | 3 | 2,7 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 | 3 | 3 | 2 | 2 | 2 |
| РН3 | 3 | 3 | 2 | 3 | 2 | 3 | 3,3 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| РН4 | 5 | 4 | 4 | 4 | 4 | 5 | 4,1 | 4 | 4 | 3 | 4 | 4 | 4 | 4 | 4 | 5 | 4 | 4 | 4 | 4 |
| Концентрация 4 | 0,2 | 0,1 | 0,2 | 0,1 | 0,2 | 0,2 | 0,8 | 0,2 | 0,2 | 0,1 | 0,1 | 0,1 | 0,1 | 0,1 | 0,1 | 0,2 | 0,1 | 0,1 | 0,1 | 0,1 |
Решение 1.
1. «Лист1» переименовываем в «Расчет1».Заносим исходные данные в Excel. Поскольку нам необходимо будет анализировать данные каждой строки (выполнять вычислительные действия), то потребуется место, куда результаты вычислений будут заноситься. Поэтому будем добавлять пустые строки после строки исходных данных.
Добавление строк в осуществляется следующим образом:
Наводим курсор на номер строку (самая первая колонка, формируемая автоматически Excel). Левой клавишей мыши выделяем строку, перед которой будет вставлена дополнительная строка. Правой клавишей мыши вызываем меню и выбираем «добавить ячейки» (Рис.17).

Рис. 17. Добавление строк в Excel.
Добавление столбцов производится аналогично добавлению строк. После столбца А (наименования) добавляем 1 столбец. В него будем заносить вычисления среднего значения и среднего отклонения, которые используются в расчетах.
2. Определяем отклонение от среднего для формулы (18).
2.1. Определяем среднее значение.
Помещаем курсор в ячейку, где будут производится расчеты. На панели инструментов выбираем «Мастер функций» (fx), в открывшемся меню выбираем «СРЗНАЧ» и в поле «Число 1» вводим интервал, среднее значение которого следует вычислить. Нажимаем «ОК». (Рис. 18)
 Рис. 18. Расчет среднего значения в Excel.
Рис. 18. Расчет среднего значения в Excel.
2.2. Определяем отклонение от среднего.
Для этого, в ячейку С4 вводим расчетную формулу
=С4-$В$4 (20)
Знак $ с двух сторон от имени столбца означает, что при дальнейших копировании расчетной формулы, значение из ячейки В4 не изменяется. Вычисления по формуле (20) выполняется для всех значений строки. (см. Выполнение расчета (Рис.4)).
3. Проверяем положение о том, что ни одно из отклонений не превышает среднее абсолютное отклонение больше, чем в 3 раза - .
3.1. Определяем среднее отклонене.
Помещаем курсор в ячейку, где будут производится расчеты. В нашем примере - В5. На панели инструментов выбираем «Мастер функций» (fx), в открывшемся меню выбираем «СРОТКЛ» и в поле «Число 1» вводим интервал, среднее значение которого следует вычислить. Нажимаем «ОК». (Рис. 18)
 Рис. 18. Расчет среднего значения в Excel.
Рис. 18. Расчет среднего значения в Excel.
3.2. Определяем превышение отклонения от среднего более, чем в 3 раза. Для этого в ячейку С5 вводим расчетную формулу:
=3*$B$5-ABS(C4). (21)
Повторяем этот расчет для всех значений строки, как и с п.п.2.2. Если в ячейки получаем значение со знаком “-“, то это указывает на то, что случайная величина явяется выбросом.
Для того, чтобы выполнить аналогичные расчеты для характеристик “давление 1”, “давление 2” и т.п., мы копируем интервал А4-С5 и вставляем в ячейку А7, предварительно добавив 2 пустые строки после строки 6. Поскольку в расчетных формулах в ячейках С4 и С5 задействованы ячейки со знаком $, то в расчетных формулах в ячейках С7 и С8 следует изменить $B$4 на $B$7 и $B$5 на $B$8.
Когда расчеты по всей выборке закончены, мы копируем их и вставляем на следуюший Лист Excel. И на этой странице проводим удаление столбцов, содержащих выбросы.
3.4. Удаление выбросов.
Наличие выбросов определяем по значениям со знаком “-“ в строках, где определяли 3-х кратное превышение отклонений от среднего. Выделяем эти столцы мышкой при нажатой клавише Ctrl, правым кликом мышки вызываем подменю, в котором выбираем функцию «удалить».
3.5. Получаем новую выборку. Помечаем отклонения отклонения от среднего более, чем в 3 раза. Копируем расчеты на следующий лист, удаляем столбцы с отмеченными отклонениями. Эти действия выполняем до тех пор, пока не получим выборку, которая не содержит выбросов.
4. Определяем количество положительных и отрицательных отклонений от среднего.
Копируем последний расчет, который не содержит выбросов на новый лист. Выделяем курсором мыши диапазон значений отклонений от среднего (С4:I4), копируем, в «Правка» выбираем «Специальная вставка», в открывшемся окне мышкой выбираем «значения» (рис. 19) и «ОК» и вставляем в ячейку (С5).

Рис. 19. Вставка значений для выполнения сортировки Excel.
Затем выделяем вставленный диапазон значений и выполняем: «Данные», «Сортировка» - «Сортировать в пределах указанного выделения», «Сортировка диапазона». Сортировка значений производится «по строкам», «по убыванию». Если у Вас в поле «Сортировать по» указаны столбцы, то следует в «Параметры» изменить «сортировать строки диапазона» на «сортировать столбцы диапазона». В результате в строке значения комплектуются от положительных к отрицательным.
В ячейке А6 изменяем текст на «количество отрицательных_положительных отклонений». А в ячейку В6 будем заносить количества положительных и отрицательных отклонений (например: 7_4).
Повторяем эту процедуру для всех параметров выборки. После чего удаляем строки, содержащие расчетные формулы, начиная со строки 4.
В результате получаем таблицу, как представлено на рис.

Рисунок 1. Определение количества положительных и отрицательных отклонений от среднего.
Отметим, что для давления 2, 3, изображенных на рис.1 отклонений не наблюдается вообще.
5. Определяем характеристики одномерного распределения.
Для определения характеристик одномерного распределения используем данные без выбросов. Т.е. Копируем итоговый расчет п.4. на новый лист, удаляем строки с расчетами количества отклонений от среднего, оставляем только матрицу данных.
На панели меню Excel выбираем «Сервис», «Анализ данных», «Описательная статистика», как показано на рис.21.

Рис.21. Использование функции «Описательная статистика» для анализа на подчинение выборки нормальному закону распределения.
При заполнении таблицы «Описательная статистика» следует обратить внимание на то, что в поле «входной интервал» сначала устанавливается курсор мыши, а затем на листе Excel выделяется мышкой входной диапазон значений. Аналогично курсор мыши устанавливается в поле «выходной интервал», после чего указывается ячейка, с которой начнется вывод расчетной информации.
В результате расчета, проведенного в Exel, мы получаем основные характеристики итоговой статистики, как показано на рис.22.

Рис.22. Основные характеристики выборки.
По приведенным данным анализируем выборку на подчинение нормальному закону распределения:
1. Количество выбросов.
2. Количество положительных и отрицательных отклонений от среднего. Если они не равны, то можно выдвинуть предположение о недостаточной надежности данных по исследуемому факторы.
3. Охарактеризовать выбору по мерам форм, положения и рассеивания.
В нашем случае вывод по работе может быть следующим:
Выбросы наблюдались с пробах 1, 3, 5-10, 14-18.
Количество положительных и отрицательных отклонений примерно равно для факторов: Р1,, V, С1, С2, С3, рН1, рН3. По фактору Т превалирую отрицательные отклонения. Для Р2, Р3, рН2, рН4, рН5, С4 отклонения отсутствуют.
По мерам формы к нормальному закону распределения не подчиняются нормальному закону распределения Р2, Р3, рН2, рН4, рН5, С4.
Высокая левосторонняя асимметрия наблюдается для Т, высокая правосторонняя асимметрия - для Р1 и V. Средняя асимметрия характерна для С1, С2, С3, рН3 (правосторонняя) и рН1 (левосторонняя).
Относительно сглаженное распределение наблюдается для Т, С1, С2, С3, рН1, рН3. Для Р1, V характерно относительно остроконечное распределение.
По мерам положения и рассеивания к нормальному закону распределения можно отнести факторы Т, Р1, V, С3, рН1, рН3. Последние два имеют достаточно большое рассеивания. Еще большая степень рассеивания у С1 и С2.
Данные расчетов для Т, рН1 и рН3 имеют достаточной уровень надежности.
Для дальнейшего исследования данных проводим корреляционный и регрессионный анализ.

