




Оглавление.
1. Основные понятия.
2. Определение неизвестной функции распределения.
3. Определение неизвестных параметров распределения.
4. Доверительный интервал. Доверительная вероятность.
5. Применение критерия Стьюдента для сравнения генеральных
совокупностей.
6. Элементы теории корреляции.
7. Проверка гипотезы о нормальном распределении генеральной
совокупности. Критерий согласия Пирсона.
1. Основные понятия.
Математическая статистика - это раздел математики, в котором изучаются методы обработки и анализа экспериментальных данных, полученных в результате наблюдений над массовыми случайными событиями, явлениями.
Наблюдения, проводимые над объектами, могут охватывать всех членов изучаемой совокупности без исключения и могут ограничиваться обследованиями лишь некоторой части членов данной совокупности. Первое наблюдение называется сплошным или полным, второе частичным или выборочным.
Естественно, что наиболее полную информацию дает сплошное наблюдение, однако к нему прибегают далеко не всегда. Во-первых, сплошное наблюдение очень трудоемко, а во-вторых, часто бывает практически невозможно или даже нецелесообразно. Поэтому в подавляющем большинстве случаев прибегают к выборочному исследованию.
Совокупность, из которой некоторым образом отбирается часть ее членов для совместного изучения, называется генеральной совокупностью, а отобранная тем или иным способом часть генеральной совокупности - выборочная совокупность или выборка.
Объем генеральной совокупности  теоретически ничем неограничен
теоретически ничем неограничен 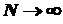 , на практике же он всегда ограничен.
, на практике же он всегда ограничен.
Объем выборки 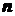 может быть большим или малым, но он не может быть меньше двух.
может быть большим или малым, но он не может быть меньше двух.
Отбор в выборку можно проводить случайным способом (по способу жеребьевки или лотереи). Либо планово, в зависимости от задачи и организации обследования. Для того, чтобы выборка была представительной, необходимо обращать внимание на размах варьирования признака и согласовывать с ним объем выборки.
2. Определение неизвестной функции распределения.
Итак, мы сделали выборку. Разобьем диапазон наблюдаемых значений 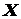 на интервалы
на интервалы  ,
,  , ….
, ….  одинаковой длины
одинаковой длины  . Для оценки необходимого числа интервалов
. Для оценки необходимого числа интервалов  можно использовать следующие формулы:
можно использовать следующие формулы:
 . (5.1)
. (5.1)
Далее пусть mi - число наблюдаемых значений , попавших в i -ый интервал. Разделив mi на общее число наблюдений n, получим частоту  , соответствующую i -ому интервалу:
, соответствующую i -ому интервалу: 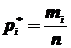 , причем
, причем  . Составим следующую таблицу:
. Составим следующую таблицу:
| Номер интервала | Интервал | mi | 
|
| 1 |
| m1 | 
|
| 2 |
| m2 | 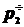
|
| ... | ... | ... | ... |
| k |
| mk | 
|
которая называется статистическим рядом. Эмпирической (или статистической) функцией распределения случайной величины называется частота события, заключающегося в том, что величина в результате опыта примет значение, меньшее x:

На практике достаточно найти значения статистической функции распределения F*(x) в точках  , которые являются границами интервалов статистического ряда:
, которые являются границами интервалов статистического ряда:
 (5.2)
(5.2)
Следует заметить, что  при
при  и
и  при
при  . Построив точки
. Построив точки  и соединив их плавной кривой, получим приближенный график эмпирической функции распределения (рис. 5.1). Используя закон больших чисел Бернулли, можно доказать, что при достаточно большом числе испытаний с вероятностью, близкой к единице, эмпирическая функция распределения
и соединив их плавной кривой, получим приближенный график эмпирической функции распределения (рис. 5.1). Используя закон больших чисел Бернулли, можно доказать, что при достаточно большом числе испытаний с вероятностью, близкой к единице, эмпирическая функция распределения  отличается сколь угодно мало от неизвестной нам функции распределения
отличается сколь угодно мало от неизвестной нам функции распределения  случайной величины .
случайной величины .

Часто вместо построения графика эмпирической функции распределения поступают следующим образом. На оси абсцисс откладывают интервалы , ,…. . На каждом интервале строят прямоугольник, площадь которого равна частоте  , соответствующей данному интервалу. Высота hi этого прямоугольника равна
, соответствующей данному интервалу. Высота hi этого прямоугольника равна  , где - длинна каждого из интервалов. Ясно, что сумма площадей всех построенных прямоугольников равна единице.
, где - длинна каждого из интервалов. Ясно, что сумма площадей всех построенных прямоугольников равна единице.
Рассмотрим функцию  , которая в интервале
, которая в интервале  постоянна и равна
постоянна и равна  . График этой функции называется гистограммой. Он представляет собой ступенчатую линию (рис. 5.2). С помощью закона больших чисел Бернулли можно доказать, что при малых и больших с практической достоверностью
. График этой функции называется гистограммой. Он представляет собой ступенчатую линию (рис. 5.2). С помощью закона больших чисел Бернулли можно доказать, что при малых и больших с практической достоверностью  как угодно мало отличается от плотности распределения
как угодно мало отличается от плотности распределения  непрерывной случайной величины .
непрерывной случайной величины .
Таким образом на практике определяется вид неизвестной функции распределения случайной величины.
3. Определение неизвестных параметров распределения.
Таким образом мы получили гистограмму, которая дает наглядность. Наглядность представленных результатов позволяет сделать различные заключения, суждения об исследуемом объекте.
Однако на этом обычно не останавливаются, а идут дальше, анализируя данные на проверку определенных предположений относительно возможных механизмов изучаемых процессов или явлений.
Несмотря на то, что данных в каждом обследовании сравнительно немного, мы бы хотели, чтобы результаты анализа достаточно хорошо описывали бы все реально существующее или мыслимое множество (т.е. генеральную совокупность).
Для этого делают некоторые предположения о том, как вычисленные на основе экспериментальных данных (выборке) показатели соотносятся с параметрами генеральной совокупности.
Решение этой задачи составляет главную часть любого анализа экспериментальных данных и тесно связано с использованием ряда теоретических распределений, рассмотренных выше.
Широкое использование в статистических выводах нормального распределения имеет под собой как эмпирическое, так и теоретическое обоснование.
Во-первых, практика показывает, что во многих случаях нормальное распределение действительно является довольно точным представлением экспериментальных данных.
Во-вторых, теоретически показано, что средние значения интервалов гистограмм распределены по закону, близкому к нормальному.
Однако следует четко представлять, что нормальное распределение - это лишь чисто математический инструмент и совсем необязательно, чтобы реальные экспериментальные данные точно описывались нормальным распределением. Хотя во многих случаях, допуская небольшую ошибку, можно говорить, что данные распределены нормально.
Ряд показателей, такие как среднее, дисперсия и т.д., характеризуют выборку и называются статистиками. Такие же показатели, но относящиеся к генеральной совокупности в целом, называются параметрами. Таким образом, можно сказать, что статистики служат для оценки параметров.
Генеральной средней  называется среднее арифметическое значений
называется среднее арифметическое значений 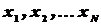 генеральной совокупности объема :
генеральной совокупности объема :

Выборочной средней  называется среднее арифметическое выборки
называется среднее арифметическое выборки 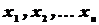 объема :
объема :
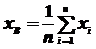 , (5.3)
, (5.3)
или
 (5.4)
(5.4)
если выборка имеет вид таблицы.
Выборочную среднюю принимают в качестве оценки генеральной средней.
Генеральной дисперсией  называется среднее арифметическое квадратов отклонения значений генеральной совокупности от их среднего значения :
называется среднее арифметическое квадратов отклонения значений генеральной совокупности от их среднего значения :

Генеральным средним квадратическим отклонением  называется корень квадратный из генеральной дисперсии:
называется корень квадратный из генеральной дисперсии:  .
.
Выборочной дисперсией  называется среднее арифметическое квадратов отклонения значений выборки от их среднего значения
называется среднее арифметическое квадратов отклонения значений выборки от их среднего значения  :
:

Выборочное среднее квадратическое отклонение  определяется как
определяется как  .
.
Для лучшего совпадения с результатами экспериментов, вводят понятие эмпирической (или исправленной) дисперсии  :
:

Для оценки генерального среднего квадратического отклонения служит исправленное среднее квадратическое отклонение, или эмпирический стандарт  :
:
 (5.5)
(5.5)
В случае, когда все значения выборки различны, т.е.  ,
,  , формулы для и
, формулы для и 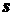 принимают вид:
принимают вид:
 (5.6)
(5.6)
4. Доверительный интервал. Доверительная вероятность.
Различные статистики, получаемые результате вычислений, представляют собой точечные оценки соответствующих параметров генеральной совокупности.
Если из генеральной совокупности извлечь некоторое количество выборок и для каждой из них найти интересующие нас статистики, то вычисленные значения будут представлять собой случайные величины, имеющие некоторый разброс вокруг оцениваемого параметра.
Но, как правило, в результате эксперимента в распоряжении исследователя имеется одна выборка. Поэтому значительный интерес представляет получение интервальной оценки, т.е. некоторого интервала, внутри которого, как можно предположить, лежит истинное значение параметра.
Вероятности, признанные достаточными для уверенных суждениях о параметрах генеральной совокупности на основании статистик, называются доверительными.
Для примера рассмотрим как оценку параметра  .
.
Известно, что если выборки извлекаются из генеральной совокупности с параметрами:

то распределение выборочных средних будет иметь среднее, равное , дисперсию  , среднее квадратическое
, среднее квадратическое  , где - объем выборки и будет приближаться к нормальному.
, где - объем выборки и будет приближаться к нормальному.
Для такого распределения, как известно,  наблюдений лежит в интервале
наблюдений лежит в интервале  ,
,  в интервале
в интервале  и
и  в интервале
в интервале  .
.
 (5.7)
(5.7)
где  .
.
С надежностью  доверительный интервал
доверительный интервал  покрывает неизвестный параметр с точностью
покрывает неизвестный параметр с точностью  . Здесь мы задаемся надежностью , а зная по таблицам для функции Лапласа находим параметр
. Здесь мы задаемся надежностью , а зная по таблицам для функции Лапласа находим параметр  и далее - доверительный интервал.
и далее - доверительный интервал.
Но истинное значение параметра генеральной совокупности  нам неизвестно. Поэтому на практике вместо параметра используют выборочное среднее квадратическое отклонение . То есть доверительный интервал определяется выражением
нам неизвестно. Поэтому на практике вместо параметра используют выборочное среднее квадратическое отклонение . То есть доверительный интервал определяется выражением
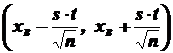 (5.8)
(5.8)
Но здесь параметр уже параметр распределения Стьюдента, который находится по соответствующим таблицам при данных и , где - задаваемая надежность. Этот интервал покрывает неизвестный параметр с надежностью  , где и находятся по формулам (5,3), (5.4) и (5.5), (5.6) соответственно.
, где и находятся по формулам (5,3), (5.4) и (5.5), (5.6) соответственно.
Пример. Найти доверительный интервал для оценки математического ожидания нормальной случайной величины с надежностью  , зная выборочную среднюю
, зная выборочную среднюю  , объем выборки
, объем выборки 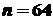 , среднее квадратическое отклонение
, среднее квадратическое отклонение  .
.
Решение. Имеем 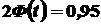 . Отсюда
. Отсюда  . По таблице значений функции Лапласа находим
. По таблице значений функции Лапласа находим  . Отсюда
. Отсюда

5. Применение критерия Стьюдента для сравнения генеральных совокупностей.
Например, нам надо оценить эффективность действия рекламы какого-то товара. До запуска рекламы продажа товара по неделям (в шт.) имела следующий вид:

После выпуска рекламы продажа этого же товара по неделям стала иметь вид:

Следовательно, доверительный интервал с надежностью для первой выборки равен
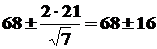
А для второй

 |
Таким образом, если по средним мы можем сделать положительный вывод о влиянии рекламы товара, то по доверительным интервалам мы вправе сомневаться: уж очень велики интервалы и они значительно перекрывают друг друга (см. рис. 5.3).
Однако нам необходимо со всей определенностью истолковать результаты эксперимента.
Мы можем высказать два предположения (статистические гипотезы).
1. Нулевая гипотеза. Между генеральными совокупностями с параметрами  и
и 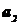 ,
,  и
и  разница равна нулю, т.е.
разница равна нулю, т.е. 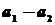 . Следовательно, разница между выборочными средними
. Следовательно, разница между выборочными средними  возникла случайно, в процессе группировки данных.
возникла случайно, в процессе группировки данных.
2. Альтернативная гипотеза, т.е. противоположная.
Для проверки этих гипотез существуют специальные параметры, которые табулированы и приводятся в соответствующих справочниках.
В частности, если сравниваемые генеральные совокупности имеют нормальный закон распределения, то сравнение выборочных средних проводят с помощью  или критерия Стьюдента:
или критерия Стьюдента:

 .
.
Согласно нулевой гипотезе  , отсюда:
, отсюда:
 (5.9)
(5.9)
Нулевая гипотеза (разницы нет) отвергается, если  для заданной надежности и числа (степеней свободы)
для заданной надежности и числа (степеней свободы) 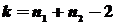 . Здесь
. Здесь 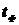 - фактический коэффициент Стьюдента, найденный по формуле (5.9), а
- фактический коэффициент Стьюдента, найденный по формуле (5.9), а 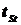 - теоретический коэффициент, найденный по специальным таблицам.
- теоретический коэффициент, найденный по специальным таблицам.
Для нашего примера 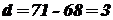 ,
,  . Следовательно,
. Следовательно,  . По таблицам, для надежности и числа
. По таблицам, для надежности и числа 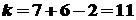 , находим
, находим 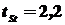 . Итак,
. Итак,  и нулевая гипотеза сохраняется: разница между результатами опыта и контроля оказалась статистически недостоверной.
и нулевая гипотеза сохраняется: разница между результатами опыта и контроля оказалась статистически недостоверной.
Таблица Стьюдента.
| k | Уровни надежности | ||
| 95 % | 99 % | 99,9 % | |
| 7 | 2,37 | 3,50 | 5,51 |
| 8 | 2,31 | 3,36 | 5,04 |
| 9 | 2,26 | 3,25 | 4,78 |
| 10 | 2,23 | 3,17 | 4,59 |
6. Элементы теории корреляции.
Между различного рода признаками, случайными величинами практически всегда существует взаимосвязь. Только иногда эту связь мы замечаем, но в большинстве случаев эти взаимосвязи ускользают от нашего внимания.
В одних случаях получается функциональная связь, когда между признаками  и
и  существует однозначная зависимость:
существует однозначная зависимость:  . Например
. Например  ,
,  и т.д.
и т.д.
В других случаях получается корреляционная зависимость, когда одному значению признака соответствуют несколько значений признака 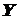 . То есть здесь мы имеем дело со статистической связью. Например, связь между ростом человека и его весом, связь между стажем работника и качеством его труда и т.д.
. То есть здесь мы имеем дело со статистической связью. Например, связь между ростом человека и его весом, связь между стажем работника и качеством его труда и т.д.
Корреляционная связь между признаками может быть линейной и нелинейной, положительной и отрицательной. Задача корреляционного анализа сводится к установлению формы и направления связи между признаками, измерению ее тесноты и к оценке достоверности выборочных коэффициентов корреляции.
Корреляционным моментом  случайных величин и называют математическое ожидание произведения отклонений этих величин от своих математических ожиданий:
случайных величин и называют математическое ожидание произведения отклонений этих величин от своих математических ожиданий:

Корреляционный момент служит для характеристики связи между величинами и .
Корреляционный момент равен нулю, если и независимы, следовательно, если корреляционный момент не равен нулю, то и — в какой-то степени зависимые случайные величины.
Теорема 1. Корреляционный момент двух независимых случайных величин и равен нулю.
Доказательство: т.к. и — независимые случайные величины, то их отклонения от своих математических ожиданий  и
и  также независимы. Пользуясь свойствами математического ожидания (математическое ожидание произведения независимых случайных величин равно произведению математических ожиданий сомножителей) и отклонения (математическое ожидание отклонения равно нулю), получим
также независимы. Пользуясь свойствами математического ожидания (математическое ожидание произведения независимых случайных величин равно произведению математических ожиданий сомножителей) и отклонения (математическое ожидание отклонения равно нулю), получим

Из определения корреляционного момента следует, что он имеет размерность, равную произведению размерностей величин и , т.е. величина корреляционного момента зависит от единиц измерения случайных величин. Поэтому для одних и тех же двух величин величина корреляционного момента имеет различные значения в зависимости от того, в каких единицах были измерены величины.
Такая особенность корреляционного момента является недостатком этой числовой характеристики, т.к. сравнение корреляционных моментов различных систем случайных величин становится затруднительным. Для того чтобы устранить этот недостаток, вводят новую числовую характеристику—коэффициент корреляции  .
.
Коэффициентом корреляции случайных величин и называют отношение корреляционного момента к произведению средних квадратических отклонений этих величин:
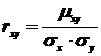
Так как размерность  равна произведению размерностей величин и ,
равна произведению размерностей величин и ,  имеет размерность величины ,
имеет размерность величины ,  имеет размерность величины , то
имеет размерность величины , то  — безразмерная величина.
— безразмерная величина.
Таким образом, величина коэффициента корреляции не зависит от выбора единиц измерения случайных величин. В этом и состоит преимущество коэффициента корреляции перед корреляционным моментом.
Очевидно, коэффициент корреляции независимых случайных величин равен нулю (т.к.  ).
).
Абсолютная величина коэффициента корреляции не превышает единицы: 
На практике мы имеем дело с выборками, а не с генеральными совокупностями. Поэтому на практике рассчитывают выборочный коэффициент корреляции, который может быть достоверным или нет. Выборочный коэффициент корреляции рассчитывается по следующей формуле:
 (5.10)
(5.10)
Коэффициент корреляции удобный показатель связи, получивший широкое применение в практике. Это отвлеченное число, лежащее в пределах от -1 до +1. При независимом варьировании признаков, когда связь между ними отсутствует,  . При
. При  существует положительная связь между признаками (с ростом растет и ). При
существует положительная связь между признаками (с ростом растет и ). При  - отрицательная связь - с ростом признака признак уменьшается. Чем больше
- отрицательная связь - с ростом признака признак уменьшается. Чем больше  по модулю, тем теснее связь между признаками. При
по модулю, тем теснее связь между признаками. При  между признаками существует функциональная связь.
между признаками существует функциональная связь.
Лишь один недостаток имеется у этого ценного показателя - он способен характеризовать лишь линейный связи. При наличии нелинейной связи между коррелирующими признаками следует использовать другие показатели.
Выборочный коэффициент корреляции служит оценкой генерального параметра  , и, как случайная величина, сопровождается ошибками. Поэтому здесь также проверяется гипотеза о значимости выборочного коэффициента корреляции.
, и, как случайная величина, сопровождается ошибками. Поэтому здесь также проверяется гипотеза о значимости выборочного коэффициента корреляции.
Пусть двумерная генеральная совокупность  распределена нормально. Из этой совокупности извлечены выборки объемом и по ним найден выборочный коэффициент корреляции
распределена нормально. Из этой совокупности извлечены выборки объемом и по ним найден выборочный коэффициент корреляции  , который оказался отличным от нуля. Так как выборки отобраны случайно, еще нельзя заключить, что коэффициент корреляции генеральной совокупности также отличен от нуля. А, поскольку нас интересует именно этот коэффициент, возникает необходимость при заданном уровне значимости
, который оказался отличным от нуля. Так как выборки отобраны случайно, еще нельзя заключить, что коэффициент корреляции генеральной совокупности также отличен от нуля. А, поскольку нас интересует именно этот коэффициент, возникает необходимость при заданном уровне значимости  проверить нулевую гипотезу
проверить нулевую гипотезу  :
:  о равенстве нулю генерального коэффициента корреляции при конкурирующей гипотезе
о равенстве нулю генерального коэффициента корреляции при конкурирующей гипотезе  :
:  .
.
Если нулевая гипотеза отвергается, значит, выборочный коэффициент корреляции значимо отличается от нуля (кратко говоря, значим), а и коррелированны, т. е. связаны линейной зависимостью.
Если же нулевая гипотеза будет принята, значит, выборочный коэффициент корреляции является незначимым, а и некоррелированные, т. е. не связаны линейной зависимостью.
В качестве критерия проверки нулевой гипотезы примем случайную величину

Величина при справедливости нулевой гипотезы имеет распределение Стьюдента с  степенями свободы.
степенями свободы.
Обозначим значение критерия, вычисленное по данным наблюдений, через 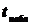 и сформулируем правило проверки нулевой гипотезы.
и сформулируем правило проверки нулевой гипотезы.
Правило. Для того чтобы при заданном уровне значимости проверить нулевую гипотезу : 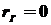 о равенстве нулю генерального коэффициента корреляции при конкурирующей гипотезе : , надо вычислить наблюдаемое значение критерия:
о равенстве нулю генерального коэффициента корреляции при конкурирующей гипотезе : , надо вычислить наблюдаемое значение критерия:
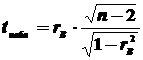 (5.11)
(5.11)
и по таблице критических точек распределения Стьюдента, по заданному уровню значимости и числу степеней свободы найти критическую точку  .
.
Если  — нет оснований отвергнуть нулевую гипотезу, если
— нет оснований отвергнуть нулевую гипотезу, если  - то ее отвергают.
- то ее отвергают.
В то время как задача корреляционного анализа - установить, являются ли данные случайные величины взаимосвязанными, цель регрессионного анализа - описать эту связь аналитической зависимостью, т.е. с помощью уравнения. Мы рассмотрим самый несложный случай, когда связь между точками на графике может быть представлена прямой линией. Уравнение этой прямой линии 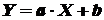 , где
, где
 ,
,  (5.12)
(5.12)
Зная уравнение прямой, мы можем находить значение функции по значению аргумента в тех точках, где значение известно, а - нет. Эти оценки бывают очень нужны, но они должны использоваться осторожно, особенно, если связь между величинами не слишком тесная. Отметим также, что из сопоставления формул для  и видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.
и видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.
7. Проверка гипотезы о нормальном распределении генеральной совокупности. Критерий согласия Пирсона.
Ранее предполагалось, что закон распределения генеральной совокупности известен. Если же он неизвестен, но есть основания предположить, что он имеет определенный вид (назовем его  ), то проверяют нулевую гипотезу: генеральная совокупность распределена по закону .
), то проверяют нулевую гипотезу: генеральная совокупность распределена по закону .
Проверка гипотезы о предполагаемом законе неизвестного распределения производится так же, как и проверка гипотезы о параметрах распределения, т. е. при помощи специально подобранной случайной величины — критерия согласия.
Критерием согласия  называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Имеется несколько критериев согласия, но мы ограничимся описанием применения критерия Пирсона к проверке гипотезы о нормальном распределении генеральной совокупности (критерий аналогично применяется и для др. распределений). Для этого будем сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
Обычно эмпирические и теоретические частоты различаются. Возможно, что расхождение случайно (незначимо) и объясняется либо малым числом наблюдений, либо способом их группировки, либо другими причинами. Возможно, что расхождение частот неслучайно (значимо) и объясняется тем, что теоретические частоты вычислены исходя из неверной гипотезы о нормальном распределении генеральной совокупности.
Критерий Пирсона отвечает на вопрос «Случайно ли расхождение частот?». Правда, как и любой критерий, он не доказывает справедливость гипотезы, а лишь устанавливает на принятом уровне значимости ее согласие или несогласие с данными наблюдений.
Итак, пусть по выборке объема получено эмпирическое распределение: варианты -  :
:  , эмпирические частоты -
, эмпирические частоты - 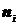 :
: 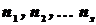 .
.
Допустим, что в предположении нормального распределения генеральной совокупности вычислены теоретические частоты  . При уровне значимости требуется проверить нулевую гипотезу: генеральная совокупность распределена нормально.
. При уровне значимости требуется проверить нулевую гипотезу: генеральная совокупность распределена нормально.
В качестве критерия проверки нулевой гипотезы примем случайную величину
 .
.
Эта величина случайная, т.к. в различных опытах она принимает различные, заранее не известные значения. Ясно, что, чем меньше различаются эмпирические и теоретические частоты, тем меньше величина критерия, и, следовательно, он в известной степени характеризует близость эмпирического и теоретического распределений.
Стоит заметить, что возведение в квадрат разностей частот устраняет возможность взаимного погашения положительных и отрицательных разностей. Делением на  достигают уменьшения каждого из слагаемых – иначе сумма была бы настолько велика, что приводила бы к отклонению нулевой гипотезы даже тогда, когда она справедлива.
достигают уменьшения каждого из слагаемых – иначе сумма была бы настолько велика, что приводила бы к отклонению нулевой гипотезы даже тогда, когда она справедлива.
Доказано, что при  закон распределения случайной величины независимо от того, к какому закону распределения подчинена генеральная совокупность, стремится к закону распределения
закон распределения случайной величины независимо от того, к какому закону распределения подчинена генеральная совокупность, стремится к закону распределения  с степенями свободы. Поэтому случайная величина обозначена через , а сам критерий называют критерием согласия «хи квадрат».
с степенями свободы. Поэтому случайная величина обозначена через , а сам критерий называют критерием согласия «хи квадрат».
Число степеней свободы находят по равенству 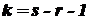 , где — число групп выборки; — число параметров предполагаемого распределения, которые оценены по данным выборки.
, где — число групп выборки; — число параметров предполагаемого распределения, которые оценены по данным выборки.
В частности, если предполагаемое распределение — нормальное, то оценивают два параметра (математическое ожидание и среднее квадратическое отклонение), поэтому  и число степеней свободы
и число степеней свободы  .
.
Так как односторонний критерий более жестко отвергает нулевую гипотезу, чем двусторонний, построим правостороннюю критическую область, исходя из требования, чтобы вероятность попадания критерия в эту область в предположении справедливости нулевой гипотезы была равна принятому уровню значимости :
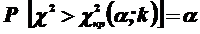 .
.
Обозначим значение критерия, вычисленное по данным наблюдений, через  и сформулируем правило проверки нулевой гипотезы.
и сформулируем правило проверки нулевой гипотезы.
Правило: для того чтобы при заданном уровне значимости проверить нулевую гипотезу  (генеральная совокупность распределена нормально), надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
(генеральная совокупность распределена нормально), надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
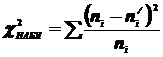
и по таблице критических точек распределения , по заданному уровню значимости и числу степеней свободы 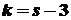 найти критическую точку
найти критическую точку  . Если
. Если  — нет оснований отвергнуть нулевую гипотезу, если
— нет оснований отвергнуть нулевую гипотезу, если  — нулевую гипотезу отвергают.
— нулевую гипотезу отвергают.

