




| Виды выборки | ||||||
| Вероятностная (случайная) | Целенаправленная (неслучайная) | |||||
| Простая случайная | Систематическая (механическая) | Стратифицированная (серийная) | Гнездовая | Квотная | Метод основного массива | Стихийная |
Обобщив разнообразные точки зрения, можно заключить, что во всех случаях типы выборки делятся на вероятностные (случайные) и невероятностные (неслучайные, целевые, целенаправленные). Ярких представителей каждого типа немного, например, случайная безвозвратная выборка явно принадлежит первому типу, а квотная наилучшим образом характеризует достоинства и недостатки второго, невероятностного типа. Гораздо больше таких видов и методов выборки, которые можно отнести к смешанным. Их можно включить и в первый и во второй типы, а можно отнести лишь к одному из них. Ошибки не будет и в том случае, если придумать некий третий тип, назвать его, допустим, комбинационным и занести туда смешанные виды. Их особенность состоит в том, что вероятностные приемы отбора в них присутствуют частично — на одном из этапов, в нарушенном виде (смещенная выборка), в одном из элементов или приемов отбора. Их недостаток заключается в том, что репрезентативность получаемой информации находится под вопросом. Хотя это вовсе не означает, что смешанные типы выборки всегда нерепрезентативны. Они могут быть репрезентативными, а могут и не быть, поэтому объявлять такие типы выборки нерепрезентативными нельзя. В них сложно установить репрезентативность, используя классические статистические приемы. Но кто говорит, что в будущем наука не шагнет дальше, прибавив к традиционным какие-либо нетрадиционные способы определения репрезентативности данных?
Репрезентативность выборки означает, что с некоторой наперед заданной или вычисленной на фактической выборке погрешностью установленное на выборочной совокупности можно отождествить с генеральной совокупностью или, если использовать язык статистики, найти оценки параметров генеральной совокупности.
Во-первых, каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку.
Во-вторых, во избежание направленного отбора выбор единиц генеральной совокупности нужно производить независимо от изучаемого признака.
В-третьих, отбор должен производиться по возможности из однородных совокупностей.
В-четвертых, число единиц генеральной совокупности, отобранных для обследования, должно быть достаточно большим.
Процесс непосредственного определения репрезентативности выборки складывается из этапов: сопоставление средних показателей распределений выборочной и генеральной совокупностей; сопоставление форм распределения этих показателей. Средний показатель распределения обычно берется как средняя арифметическая или средневзвешенная арифметическая этого распределения.
В случае изучения совокупностей с альтернативными признаками вместо средней арифметической вычисляется доля единиц, обладающих рассматриваемой характеристикой, относительно всей совокупности. Если обозначить объем совокупности символом N, а явление с данным признаком — М, то Р —доля явлений с этим признаком определяется:

i> + Q = l(100%)
l-P = Q,
где Q — доля явлений с альтернативным признаком.
Пользоваться выводами, полученными на основании исследования выборочной совокупности, можно в том случае, если разность между средними арифметическими (или средними долями) признаков выборочной и генеральной совокупностей стремится к нулю. Предполагается, что это требование удовлетворяется при выполнении четырех условий, оговоренных выше. Правда, зная только выборочные средние показатели, нельзя дать точные оценки их разности, так как неизвестны средние показатели генеральной совокупности. Кроме того, сами значения выборочных средних могут колебаться в зависимости от того, какие единицы генеральной совокупности попадут в выборку. Поэтому оценка репрезентативности выборочной совокупности по средним показателям ее распределения сводится к поиску ошибки репрезентативности.
Сравнение выборочной и генеральной совокупностей по средним показателям не дает полного представления о генеральной совокупности. Так, в двух совокупностях с одинаковыми средними показателями расхождения между максимальным и минимальным значением признака, определяющие форму его распределения, могут быть различны. Если представить такое распределение графически, то оно образует симметричную колоколообраз-ную (нормальную) кривую, отражающую тот факт, что сумма многих независимых произвольно распределенных случайных переменных приближенно распределяется по нормальному закону. Ордината у, которая определяет высоту кривой для каждой точки х, представляет собой плотность вероятности для значения хг
Максимум плотности вероятности приходится на среднее значение переменной и равен единице. Это означает, что чем меньше случайное значение переменной отличается от ее среднего значения, тем больше вероятность его проявления. И наоборот, чем больше отклонение значений переменной от ее средней величины, тем вероятность их появления меньше. Таким образом, значения отклонений от средних величин, т.е. значения вида jc;- х, несут информацию о вариации изучаемых переменных. Если бы все значения признака были одинаковы и совпадали с его средней величиной, то совокупность значения этого признака была бы предельно однородной.
Обычно число положительных отклонений от среднего арифметического значения совокупности примерно равно числу отрицательных отклонений, т.е. сумма всех отклонений неизбежно стремится к нулевому значению.
Поэтому, если бы потребовалось просуммировать все отклонения признака в совокупности, эта сумма всегда была бы равна нулю:
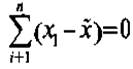
Во избежание этого каждое отклонение возводят в квадрат и находят сумму квадратов — дисперсию.
Нормальное распределение в полной мере характеризуется параметрами: х — среднее значение признака и а — среднее квадратичное (стандартное) отклонение. Среднее jc определяет положение распределения относительно оси х; стандартное отклонение показывает форму кривой; чем больше значение о, тем шире кривая и тем ниже ее максимум.
Площадь под нормальной кривой располагается таким образом, что в границах 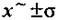 находится 68 % всего распределения признака, в границах
находится 68 % всего распределения признака, в границах
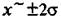 — 95,5, в пределах
— 95,5, в пределах 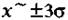 — 99,7%. Вероятность того, что разность между случайной переменной, распределенной примерно по нормальному закону, и ее средним значением по абсолютной величине превосходит За. меньше 0,3%. Отсюда следует, что практически со стопроцентной точностью можно утверждать:
— 99,7%. Вероятность того, что разность между случайной переменной, распределенной примерно по нормальному закону, и ее средним значением по абсолютной величине превосходит За. меньше 0,3%. Отсюда следует, что практически со стопроцентной точностью можно утверждать:
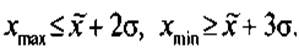
Оценка репрезентативной выборочной совокупности по форме распределения показателей представляет собой сравнение мер вариации этих показателей в выборочной и генеральной совокупностях. Дисперсия генеральной совокупности известна далеко не всегда, однако в математической статистике доказано, что между генеральной и выборочной дисперсиями существует соотношение вида:
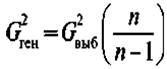
где п — объем выборки.
Проблема репрезентативности выборки имеет важное значение как проблема правомерности экстраполяции выводов, полученных при анализе выборочной совокупности, на всю генеральную совокупность12.

