




ѕод упаковкой (сжатием, уплотнением) понимают такое перекодирование данных, которое позвол€ет уменьшить по сравнению с исходным объем пам€ти, необходимый дл€ их хранени€.
ѕрограммы Ц архиваторы служат дл€ сжати€ файлов, что позвол€ет хранить их в сжатом виде в одном архивном файле (архиве), что позвол€ет уменьшить объЄм занимаемой файлами пам€ти.
—жатие информации Ц это процесс преобразовани€ информации, хран€щейс€ в файле, к виду при котором уменьшаетс€ избыточность в еЄ представлении и соответственно требуетс€ меньший объЄм пам€ти дл€ хранени€.
”паковка данных используетс€ дл€ экономии дискет при переносе программ и данных с одного компьютера на другой. ¬ упакованном виде удобно хранить временно не используемые программы и данные, а также копии файлов, создаваемые на случай утраты оригиналов.
—озданные архивы можно обновл€ть, добавл€ть в них файлы, удал€ть файлы из архива, провер€ть архив на целостность. ѕри необходимости файлы можно вывести их архива - разархивировать.
јрхивный файл Ц это специальным образом организованный файл, содержащий в себе один или несколько файлов в сжатом или не сжатом виде и служебную информацию об именах файлов, дате и времени их создани€ или модификации, размерах и т.п.
јрхиваци€ (упаковка) Ц помещение (загрузка) исходных файлов в архивный файл в сжатом или не сжатом виде.
–азархиваци€ (распаковка) Ц процесс восстановлени€ файлов из архива точно в таком виде, какой они имели до загрузки в архив. ѕри распаковке файлы извлекаютс€ из архива и помещаютс€ на диск или в оперативную пам€ть.
ѕрограммы, осуществл€ющие упаковку и распаковку файлов, называют программами-архиваторами.
ƒл€ сжати€ файлов пользовател€ми ѕ широко используетс€ множество программ архиваторов.
ѕреимущества архиваторов:
1. позвол€ют сжимать от 22 % до 90% информации;
2. позвол€ют обновл€ть программное обеспечение, причем архиватор сам следит за процессом обновлени€;
3. позвол€ют создавать самораспаковывающиес€ архивы;
4. позвол€ют содержать в одном файле группу однородных файлов.
5. поддержка непрерывных архивов, в которых степень сжати€ может быть на 10 - 50% больше, чем при обычных методах сжати€, особенно при упаковке большого количества маленьких похожих файлов;
6. поддержка многотомных архивов;
7. создание самораспаковывающихс€ (SFX) обычных и многотомных архивов с помощью стандартного или дополнительных модулей SFX;
8. восстановление физически поврежденных архивов;
9. другие дополнительные функции, например, шифрование, добавление архивных комментариев (с поддержкой ESC-последовательностей ANSI), протоколирование ошибок и пр.
ј рхив содержит оглавление, в котором находитс€ следующа€ информаци€:
- им€ файла,
- дата и врем€ создани€ или модификации,
- объем файла до и после архивации,
- процент сжати€,
- код циклического контрол€ дл€ каждого файла (контрольна€ сумма)
јрхиваторов очень много: ARJ, RAR, ZIP, CAB, LZH, GIF, TIF, PCX Е
јрхивные файлы могут быть непрерывными, многотомными, самораспаковывающимис€.
|
|
|
Ќепрерывный архив Ц это архив, запакованный специальным способом, при котором все сжимаемые файлы рассматриваютс€ как один последовательный поток данных.
“ома Ц это фрагменты архива, состо€щего из нескольких частей. “ома поддерживаютс€ только в формате RAR, вы не можете создавать тома ZIP. ќбычно тома используютс€ дл€ сохранени€ большого архива на нескольких дискетах или других сменных носител€х.
—амораспаковывающийс€ (SFX, от англ. SelF-eXtracting) архив Ц это архив, к которому присоединен исполнимый модуль. Ётот модуль позвол€ет извлечь файлы, просто запустив архив как обычную программу. “аким образом, дл€ извлечени€ содержимого SFX-архива не требуетс€ дополнительных внешних программ. SFX-архивы, как и любые другие исполнимые файлы, обычно имеют расширение.EXE.
—амораспаковывающийс€ архивный файл Ц это загрузочный, исполн€емый модуль, который способен к самосто€тельной разархивации наход€щихс€ в нЄм файлов без использовани€ программы архиватора
SFX-архивы удобны в тех случа€х, когда нужно передать кому-то архив, но вы не уверены, что у адресата есть соответствующий архиватор дл€ извлечени€ файлов. ¬ы также можете использовать SFX-архивы дл€ распространени€ своих собственных программ.
—тепень сжати€ информации зависит от типа файла, а также от выбранного метода упаковки. —тепень (качество) сжати€ файлов характеризуетс€ коэффициентом сжати€ с, определ€емым как отношение объЄма сжатого файла Vc к объЄму исходного файла Vo, выраженное в процентах: с = 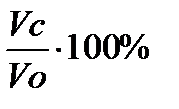 .
.
„ем меньше величина —, тем выше степень сжати€ информации.
Ќесмотр€ на изобилие алгоритмов сжати€ данных, теоретически есть только три способа сжати€. Ёто либо изменение содержани€ данных, либо изменение их структуры, либо одновременно и то и другое.
≈сли при сжатии данных происходит изменение их содержани€, потер€ информации, то метод сжати€ необратим и при восстановлении данных из сжатого файла не происходит полного восстановлени€ исходной последовательности. “акие методы называют также методами сжати€ с регулируемой потерей информации. ќни применимы только дл€ тех типов данных, дл€ которых формальна€ утрата части содержани€ не приводит к значительному снижению потребительских свойств. ¬ первую очередь это относитс€ к мультимедийным данным: видеор€дам, музыкальным запис€м, звукозапис€м и рисункам. ћетоды сжати€ с потерей информации обычно обеспечивают гораздо более высокую степень сжати€, чем обратимые методы, но их нельз€ примен€ть к текстовым документам, базам данных и, тем более, к программному коду.
≈сли при сжатии данных происходит только изменение их структуры, то метод сжати€ обратим. »з результирующего кода можно восстановить исходный массив путем применени€ обратного метода. ќбратимые методы примен€ютс€ дл€ сжати€ любых типов данных.
—уществует достаточно много обратимых методов сжати€ данных, однако в их основе лежит сравнительно небольшое количество теоретических алгоритмов.
јлгоритм RLE
¬ основу алгоритмов RLE (от англ. слов Run Length Encoding Цкодирование путЄм учЄта повторений) положен принцип вы€влени€ повтор€ющихс€ последовательностей данных и замены их простой структурой, в которой указываетс€ код данных и коэффициент повтора.
Ќапример, дл€ последовательности: 0; 0; 0; 127; 127; 0; 255; 255; 255; 255 (всего 10 байтов) образуетс€ следующий вектор:
| «начение | оэффициент повтора |
|
|
|
ѕри записи в строку он имеет вид:
0; 3; 127; 2; 0; 1; 255; 4 (всего 8 байтов)
¬ данном примере коэффициент сжати€ равен 8/10=0,8=80%
ѕон€ть идею этого метода упаковки позвол€ет следующий анекдот. ќдин полководец решил написать достаточно объЄмные мемуары. —оставленные воспоминани€ звучали примерно так: Ф”тром € вскочил на своего кон€ и помчалс€ в штаб армии. ѕодковы кон€ издавали звук У÷ок-цок- цок- цок- цок- цок- цокЕФ. „ерез двое суток € соскочил с кон€ и вошЄл в штаб.Ф. ƒл€ увеличени€ объЄма литературного произведени€ словосочетание УцокФ было написано на двухстах страницах. ќчевидно, что информативность произведени€ не изменилась бы, если вместо 200 страниц перечислени€ цокающих звуков было бы указано: Ф«атем следует 64000Фраз звуки Уцок-цокФ У.
ѕрограммные реализации алгоритмов RLE отличаютс€ простотой, высокой скоростью работы, но в среднем обеспечивают недостаточное сжатие. Ќаилучшими объектами дл€ данного алгоритма €вл€ютс€ графические файлы, в которых большие одноцветные участки изображени€ кодируютс€ длинными последовательност€ми одинаковых байтов. Ётот метод может давать заметный выигрыш на некоторых типах файлов баз данных, имеющих таблицы с фиксированной длиной полей. ƒл€ текстовых данных методы RLE, как правило, неэффективны.
јлгоритм KWE
¬ основу алгоритмов кодировани€ по ключевым словам Keyword Encoding положено кодирование лексических единиц исходного документа группами байтов фиксированной длины. ѕримером лексической единицы может служить слово (последовательность символов, ограниченна€ справа и слева пробелами или символами конца абзаца). –езультат кодировани€ сводитс€ в таблицу, котора€ прикладываетс€ к результирующему коду и представл€ет собой словарь. ќбычно дл€ англо€зычных текстов прин€то использовать двухбайтную кодировку символов. ќбращающиес€ при этом пары байтов называют токенами.
Ёффективность данного метода существенно зависит от длины документа, поскольку из-за необходимости прикладывать к архиву словарь длина кратких документов не только не уменьшаетс€, но даже возрастает.
ƒанный алгоритм наиболее эффективен дл€ англо€зычных текстовых документов и файлов баз данных. ƒл€ русско€зычных документов, отличающихс€ увеличенной длиной слов и большим количеством приставок, суффиксов и окончаний, не всегда удаетс€ ограничитьс€ двухбайтными токенами, и эффективность метода значительно снижаетс€.
јлгоритм ’афмана
¬ основе этого алгоритма лежит кодирование не байтами, а битовыми группами.
Ј ѕеред началом кодировани€ производитс€ частотный анализ кода документа и вы€вл€етс€ частота повторени€ каждого из встречающихс€ символов.
Ј „ем чаще встречаетс€ тот или иной символ, тем меньшим количеством битов он кодируетс€ (соответственно, чем реже встречаетс€ символ, тем длиннее его кодова€ битова€ последовательность).
Ј ќбразующа€с€ в результате кодировани€ иерархическа€ структура прикладываетс€ к сжатому документу в качестве таблицы соответстви€.
¬ св€зи с тем, что к каждому архиву необходимо прикладывать таблицу соответстви€, на файлах малых размеров алгоритм ’афмана мало эффективен. ѕрактика также показывает, что его эффективность зависит от заданной предельной длины кода (размера словар€). ¬ среднем наиболее эффективными €вл€ютс€ архивы с размером словар€ от 512 до 1024 единиц (длина кода до 18-20 бит).
—интетические алгоритмы
–ассмотренные выше алгоритмы в Ђчистом видеї на практике не примен€ютс€ из-за того, что эффективность каждого из них сильно зависит от начальных условий. ¬ св€зи с этим, современные средства архивации данных используют наиболее сложные алгоритмы, основанные на комбинации нескольких теоретических методов. ќбщим принципом в работе таких синтетических алгоритмов €вл€етс€ предварительный просмотр и анализ исходных данных дл€ индивидуальной настройки на особенности обрабатываемого материала.
2. „исло 11110 перевести в другие системы счислени€.
|
|
|
| 11110=11011112 | |||||||||||||
11110=1578
11110=6F16
3. ¬ыполнить действи€:
101011102+111100012
+11110001
1010112-100012=
10001 пр€мой код числа
01110 обратный код числа
+ 1
01111 дополнительный код
+ 101111
1010112-100012=110102

