




При предположениях о линейной регрессионной зависимости и нормальном законе условного распределения  эмпирическое уравнение регрессии можно написать без использования какого-либо критерия близости точек к кривой
эмпирическое уравнение регрессии можно написать без использования какого-либо критерия близости точек к кривой 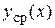 .
.
В корреляционноманализе вычисляют сначала средние арифметические, несмещенные оценки средних квадратических отклонений и коэффициентов корреляции: 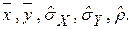 Тогда эмпирическое уравнение регрессии записывается следующим образом:
Тогда эмпирическое уравнение регрессии записывается следующим образом: 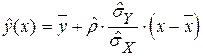
Оно имеет тот же вид, что и само уравнение регрессии для двумерного нормального распределения. Поскольку X и Y – обе случайные величины, то можно записать еще одно эмпирическое уравнение регрессии:
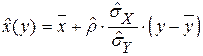
В регрессионном анализе может быть использован тот же метод, только вычисляемые значения нельзя трактовать как оценки параметров распределения. Но лучше записывать эмпирическое уравнение регрессии в виде:
 ,
,
где 
Доверительный интервал для условного математического ожидания имеет вид, приведенный при изложении метода наименьших квадратов. Оценку среднего квадратического отклонения условного распределения можно вычислять по более простой формуле:
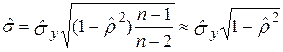
4.3. Использование регрессионных моделей
Пусть получена модель 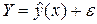 , причем найдены оценки:
, причем найдены оценки: 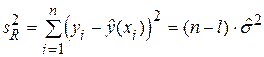 ,
, 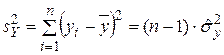 ,
,
где 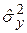 имеет смысл оценки дисперсии только в корреляционном анализе, т.е. когда проводится пассивный эксперимент.
имеет смысл оценки дисперсии только в корреляционном анализе, т.е. когда проводится пассивный эксперимент.
Прежде всего, оценивается величина, называемая выборочным коэффициентом детерминации, а часто просто коэффициентом детерминации и характеризующая степень тесноты детерминированной связи:
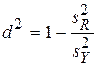
Чем ближе к единице этот коэффициент, тем ближе статистическая зависимость между y и x к функциональной (детерминированной), если, конечно, в качестве функции 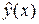 не взят, вопреки здравому смыслу, полином n –ой степени, проходящий через все точки
не взят, вопреки здравому смыслу, полином n –ой степени, проходящий через все точки  .
.
Находится оценка корреляционного отношения:
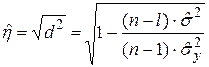
В случае линейной регрессии и при нормальном законе выполняется равенство: 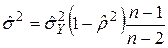 . Если эту формулу подставить в предыдущую, в которой принять l= 2, то получим:
. Если эту формулу подставить в предыдущую, в которой принять l= 2, то получим: 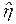 =
= 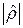 . Если при предположении нелинейной регрессии величина оказалась близкой к , значит, в качестве можно брать линейную функцию. Нетрудно убедиться, что всегда
. Если при предположении нелинейной регрессии величина оказалась близкой к , значит, в качестве можно брать линейную функцию. Нетрудно убедиться, что всегда 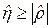 .
.
Регрессионная модель используется для косвенного оценивания значения 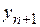 по вновь полученной информации только о значении
по вновь полученной информации только о значении 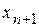 , если, конечно, можно считать неизменными условия наблюдений. Подставляя в выражение для , мы оценим только среднее значение величины y с некоторым доверительным интервалом (для линейной регрессии он приведен выше). При больших значениях n величиной доверительного интервала можно пренебречь. Тогда оценку индивидуального значения мы можем написать в виде интервала, в который с заданной вероятностью p попадет это значение:
, если, конечно, можно считать неизменными условия наблюдений. Подставляя в выражение для , мы оценим только среднее значение величины y с некоторым доверительным интервалом (для линейной регрессии он приведен выше). При больших значениях n величиной доверительного интервала можно пренебречь. Тогда оценку индивидуального значения мы можем написать в виде интервала, в который с заданной вероятностью p попадет это значение:
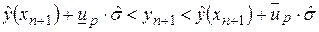 ,
,
где 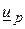 и
и 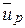 – нижний и верхний квантили распределения случайной величины
– нижний и верхний квантили распределения случайной величины 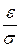 (в случае нормального распределения = – ). При малых n или значениях , далеко отстоящих от
(в случае нормального распределения = – ). При малых n или значениях , далеко отстоящих от 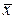 , надо пользоваться толерантным интервалом, который получается путем расширения приведенного выше интервала с каждой стороны на половину длины доверительного интервала.
, надо пользоваться толерантным интервалом, который получается путем расширения приведенного выше интервала с каждой стороны на половину длины доверительного интервала.
В частности, для нормального условного распределения и при 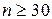 можно приблизительно с вероятностью p = 0,95 утверждать, что будет находиться в интервале
можно приблизительно с вероятностью p = 0,95 утверждать, что будет находиться в интервале
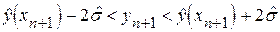 .
.
В случае, когда параметр 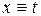 – время (в частном случае, когда t=1,2,3,…, регрессионная модель называется трендовой), косвенное оценивание обычно представляет собой прогнозирование. Однако регрессионные модели для прогнозирования надо использовать очень осторожно.
– время (в частном случае, когда t=1,2,3,…, регрессионная модель называется трендовой), косвенное оценивание обычно представляет собой прогнозирование. Однако регрессионные модели для прогнозирования надо использовать очень осторожно.
Во-первых, прогноз можно осуществлять, как правило, лишь на небольшую глубину в стабильной обстановке, т.е. при предположении о неизменности основных условий протекания процессов.
Во-вторых, регрессионная модель в случаях, когда , не учитывает инерционность системы, она допускает возможность резких изменений величины y через малое время  .
.
Эти же замечания можно сделать и по отношению к пространственному параметру x, представляющему собой, например, расстояние.
В таких случаях лучше использовать (желательно в сочетании с экспертными методами) модели случайных процессов, учитывающих автокорреляцию: марковских, полумарковских, процессов с независимыми приращениями, т.е. 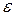 должна быть не случайной величиной, а случайным процессом.
должна быть не случайной величиной, а случайным процессом.
Прогнозирование на основе регрессионных моделей можно осуществлять и когда x не является параметром времени, но значения 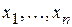 по сравнению с
по сравнению с 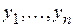 сдвинуты во времени, т.е. имеют временной лаг, который можно принять за глубину прогноза.
сдвинуты во времени, т.е. имеют временной лаг, который можно принять за глубину прогноза.
Косвенное оценивание по регрессионным моделям часто позволяет значительно сэкономить ресурсы.
Кроме косвенного оценивания регрессионные модели могут служить эталоном нормально протекающих процессов в природе или человеческой деятельности. Например, между средней зарплатой и количеством автомобилей в регионе (в частности, районе области) имеется определенная статистическая зависимость. Однако некоторые регионы могут иметь низкую среднюю заработную плату и в то же время большое число автомобилей на душу населения. Это наводит на мысль о наличии очень развитой теневой экономики в регионе.
Задача. На предприятии ведется учет числа рекламаций, получаемых от потребителей. Пусть детали типа A отправляются одному потребителю, а детали типа B – другому. Ежемесячное число рекламаций x и y по деталям типа A и B соответственно представлено в таблице:
| Месяцы | ||||||||||||
| x | ||||||||||||
| y |
Провести корреляционный анализ на наличие временного лага l 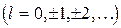 между значениями параметров, построить регрессионную модель и предложить метод прогноза числа рекламаций.
между значениями параметров, построить регрессионную модель и предложить метод прогноза числа рекламаций.
При l = 0 для статистической обработки надо брать пары: (105;68); (102;71) и т.д.
При l = 1 – пары (105;71); (102;69) и т.д. (этих пар будет только 11).
При l = –1 – пары (102;68); (100;71) и т.д.
Пусть сначала l = 0. Находим:
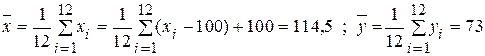
Вычислим несмещенные оценки дисперсий. Это легче сделать по следующим формулам:
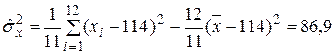
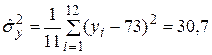
Находим оценки средних квадратических отклонений:

Определим несмещенную оценку ковариации:
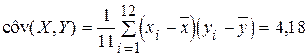
Наконец, вычисляем оценку коэффициента корреляции:
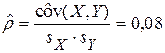
Отсюда следует, что при l = 0 величины X и Y практически некоррелированы.
Пусть теперь l = 2. Находим
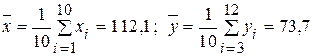
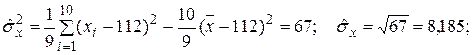
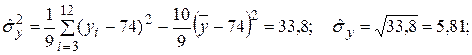
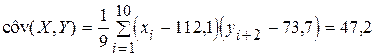
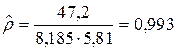
Оценка коэффициента корреляции при l = 2 оказалась близкой к 1, что означает наличие почти детерминированной зависимости между x и y. В этом можно убедиться, если точки 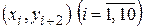 нанести на координатную плоскость (x, y).
нанести на координатную плоскость (x, y).
Можно также самостоятельно убедиться в том, что при других l оценки коэффициента корреляции будут меньше 0,993. Значит, в статистических данных исходной таблицы имеется лаг l =2. Это означает, что, получив число рекламаций, поступивших, например, за январь по деталям типа A, можно довольно точно спрогнозировать число рекламаций по деталям типа B, которое будет в марте. Прогнозирование надо осуществлять на основе уравнения регрессии:

В частности, при x = 125 получим 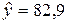 . Это число мало отличается от числа y = 82 (см. таблицу). Но это – прогноз в среднем.
. Это число мало отличается от числа y = 82 (см. таблицу). Но это – прогноз в среднем.
Точность индивидуального прогноза определяется, во-первых, естественным разбросом, т.е. дисперсией условного распределения 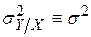 , а во-вторых, ограниченностью выборки, т.е. доверительным интервалом для величины , который зависит от x.
, а во-вторых, ограниченностью выборки, т.е. доверительным интервалом для величины , который зависит от x.
Определим оценку среднего квадратического отклонения условного распределения по более простой формуле: 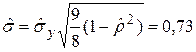 . С целью определения доверительного интервала для условного математического ожидания
. С целью определения доверительного интервала для условного математического ожидания  при
при 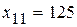 зададимся значением
зададимся значением 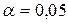 . Из табл. 3П Приложения находим квантиль
. Из табл. 3П Приложения находим квантиль 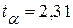 распределения Стьюдента с (n – 2) степенями свободы, т.е. при k = 8. Тогда, учитывая, что
распределения Стьюдента с (n – 2) степенями свободы, т.е. при k = 8. Тогда, учитывая, что 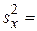
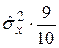 , находим:
, находим:
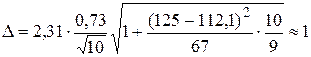 .
.
Доверительный интервал имеет вид: 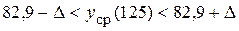 ,
,
т.е. 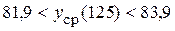
Зададим вероятность p = 0,95 попадания индивидуального значения 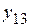 в искомый интервал при предположении, что математическое ожидание
в искомый интервал при предположении, что математическое ожидание 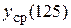 известно точно. Из табл. 1П Приложения найдем квантиль =1,96. Тогда этот интервал имеет вид:
известно точно. Из табл. 1П Приложения найдем квантиль =1,96. Тогда этот интервал имеет вид:
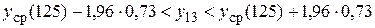
или: 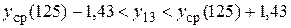
Объединяя полученные два интервала, запишем интервал для индивидуального прогноза величины :
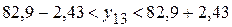 или:
или: 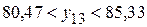
Этот интервал зависит от двух вероятностей: 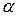 и p.
и p.
5. Проверка статистических гипотез
5.1. Основные понятия
Определение. Статистическая гипотеза (или просто – гипотеза) – это некоторое предположение относительно характеристик генеральной(-ых) совокупности(-ей), выдвигаемое на основе выборки(-ок).
Гипотез может быть несколько (например, в задачах классификации, распознавания образов), но обычно их число равно двум. При этом выделяют основную гипотезу, соответствующую наиболее вероятному состоянию некоторой системы или наиболее вероятному виду объекта, подлежащего распознаванию. Ее обозначают H0. Наряду с основной гипотезой часто рассматривают альтернативную – Н1. Например, в технологической системе, производящей продукцию, обычно выделяют исправное и неисправное состояния. Числовые характеристики (математическое ожидание, дисперсия или вероятность попадания случайных величин в заданную область, т.е. процент годных единиц продукции) генеральных совокупностей, соответствующих продукции, выпущенной исправной и неисправной технологической системой, имеют разные значения. Распознать состояние технологической системы можно на основе информации о выборке из генеральной совокупности, если заранее провести необходимые исследования.
Задачи проверки гипотез относят к задачам статистического анализа. Различают параметрические и непараметрические гипотезы, простые и сложные.
Непараметрическая гипотеза – гипотеза о характере распределения (-ий). Различают три вида гипотез: 1) гипотеза о виде распределения, выдвигаемая на основе одной выборки (например, распределение является нормальным); 2) гипотеза о равенстве (об одинаковости) распределений, выдвигаемая на основе выборок, извлекаемых из разных генеральных совокупностей или слоев; 3) гипотеза об одинаковости видов распределений, выдвигаемая на основе выборок, извлекаемых из разных генеральных совокупностей или слоев.
Параметрическая гипотеза – гипотеза о значениях параметров распределения(-ий) известного вида или числовых характеристик случайной величины.
Параметр распределения или числовую характеристику случайной величины будем обозначать h. Это может быть и вектор. Проверка параметрических гипотез применяется для двух типов задач: сравнение оценки числовой характеристики (математического ожидания, вероятности успеха и пр.) с конкретным числом либо сравнение между собой оценок, полученных по нескольким выборкам, взятым из разных генеральных совокупностей или различных слоев.
Задачи I типа применяются для обоснования принятия решений при выборочном контроле качества продукции, распознавании образов, обработке результатов тестирования, контроле состояния или умонастроений различных слоев общества, контроле окружающей среды, контроле истинного экономического состояния предприятий, и т.д.
Задачи II типа применяются с целью решения вопроса о возможном объединении генеральных совокупностей в одну, для оценки возможности применения к разным генеральным совокупностям одной и той же методики выборочного контроля, для сравнительной оценки эффективности различных способов деятельности и т.д. Эти задачи составляют основу дисперсионного анализа.
Проверка параметрических гипотез для задач I типа осуществляется с применением различных критериев оптимальности принимаемых решений: Неймана-Пирсона, Байеса, Вальда (минимаксного или максиминного критерия), Гурвица и др. Задачи I типа часто успешнее решаются в рамках теории исследования операций методами теории статистических решений (ее называют также статистическими играми или играми с природой), более общей по сравнению с теорией проверки гипотез.
Простая гипотеза – параметрическая гипотеза о значении параметра (одномерного или многомерного). Обычно пишут: Н0: h= h0, Н1: h = h1.
Сложная гипотеза – параметрическая гипотеза о совокупности значений параметра. Гипотезы Н1: h ¹ h0 и Н1: h < h0, являются сложными. Сложной может быть и Н0. Области S0 и S1 значений параметра h, соответствующие сложным гипотезам Н0 и Н1, могут не пересекаться, а могут иметь и общие элементы.
Правило, по которому принимают или отвергают гипотезу H0, называют критерием. Правило зависит от вида альтернативной гипотезы. Оно определяет границу в пространстве выборки x =(x1, x2, …, xn), где n – объем выборки, или в пространстве так называемых тестовых статистик t, являющихся функциями от x1, …, xn. Тестовыми статистиками обычно являются точечные оценки числовых характеристик и функции от них. Граница отделяет области принятия R (или G) и отклонения 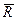 (или
(или 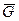 ) гипотезы H0, где R соответствует пространству выборки, а G – пространству тестовых статистик. Принятие или отклонение гипотезы H0 влечет за собой принятие некоторого решения в процессе управления, основанного на выборочных исследованиях (в том числе – неточных измерениях). Критерием часто называют саму тестовую статистику.
) гипотезы H0, где R соответствует пространству выборки, а G – пространству тестовых статистик. Принятие или отклонение гипотезы H0 влечет за собой принятие некоторого решения в процессе управления, основанного на выборочных исследованиях (в том числе – неточных измерениях). Критерием часто называют саму тестовую статистику.
Ввиду случайности выборки возможны ошибки в принятии или отклонении гипотезы H0: ошибкой I рода называют отклонение гипотезы H0 в то время, когда она верна, ошибкой II рода называют принятие гипотезы H0 в то время, когда верна альтернативная гипотеза H1. Значит, можно говорить и о вероятностях ошибок I и II рода. Как правило, ими называют условные вероятности ошибок, предполагая, что H0 и H1 – простые гипотезы.
Вероятностью ошибки первого рода называют условную вероятность отклонения гипотезы H0 (при условии, что она верна):
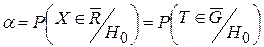
Вероятностью ошибки второго рода называют условную вероятность принятия гипотезы H0 (при условии, что верна альтернативная гипотеза H1):
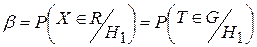
Вероятности a и b называют также условными рисками или просто рисками. Их выбирают обычно из ряда: 0,1; 0,05; 0,01; 0,005; 0,001. Вероятность a называют еще и уровнем значимости, а вероятность 1-b – мощностью критерия.
Если отклонение гипотезы H0 означает автоматическое принятие гипотезы H1, то a – условная вероятность принятия гипотезы H1. Но в результате отклонения гипотезы H0 могут приниматься и другие решения. Чаще всего – это получение дополнительной информации: берется еще одна выборка, уточняются предположения относительно вида закона распределения и пр.
Если известны априорные вероятности p и q гипотез H0 и H1 соответственно, то вводят в рассмотрение безусловные вероятности ошибок I и II рода (безусловные риски): aб=р∙a, bб=q∙b. Это – вероятности произведения событий.
В случае сложных гипотез H0 (если h 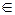 S0) и H1 (если h S1) условные риски a и b зависят от значения параметра h. Тогда вместо них рассматривают полные условные вероятности ошибок:
S0) и H1 (если h S1) условные риски a и b зависят от значения параметра h. Тогда вместо них рассматривают полные условные вероятности ошибок:
aп.y=  , bп.y=
, bп.y= 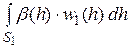 ,
,
где w0(h) и w1 (h) – плотности вероятностей параметра h, при условии, что справедлива гипотеза H0 или H1 соответственно.
В распространенном частном случае, когда альтернативная сложная гипотеза H1 есть логическое отрицание основной сложной гипотезы H0 и известны априорные вероятности p и q=1-p гипотез H0 и H1 соответственно, априорное распределение параметра h, согласно модифицированной формуле полной вероятности, можно представить в виде:
w(h)=pw0(h)+ qw1(h)
В этом случае часто бывает легче оценить сначала w(h). Тогда
p= 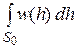 , q =
, q = 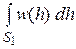 ,
,
w0(h)= 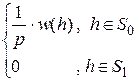 , w1(h)=
, w1(h)= 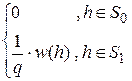
Рассматривают также полные безусловные вероятности ошибок:
aп.б=paп.y = 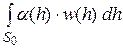 , bп.б = qbп.y =
, bп.б = qbп.y = 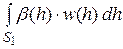
В зависимости от задачи может использоваться только одна вероятность ошибки I рода или обе. В случае, когда гипотеза H0 – простая, а альтернативная гипотеза H1 – сложная, обычно используют только один условный риск a.
При практическом применении теории проверки гипотез в задачах принятия решений в условиях неопределенности часто возникают трудности с определением границ между сложными гипотезами H0 и H1. Например, какие партии продукции, подлежащие выборочному контролю, считать приемлемыми, а какие неприемлемыми или какие предприятия, подлежащие выборочному инспектированию, считать злостными нарушителями законов? Такие задачи можно решать методами теории статистических решений, которая в таких случаях может обходиться без термина “гипотеза”. Для их решения используется также сравнительно недавно созданный аппарат теории расплывчатых множеств, однако при правильном его применении результаты решения задач совпадают с результатами, получаемыми на основе использования теории вероятностей и математической статистики.
5.2. Проверка непараметрических гипотез
Проверка основана на использовании только основной гипотезы H0 (альтернативная совпадает с ее логическим отрицанием). В этом случае имеет смысл вводить в рассмотрение только одну вероятность ошибки первого рода a.
Рассмотрим только первый вид непараметрической гипотезы из трех, упомянутых выше. Иначе говоря, рассмотрим только задачи одного типа. Это задачи подбора теоретического распределения (экспоненциального, нормального и т.д.) на основе выборки из генеральной совокупности. Применяются, например, при периодическом контроле процесса изготовления партий продукции, методика контроля качества которых основана на предположении о нормальном распределении параметра изделия внутри партии.
Проверка непараметрических гипотез для этих задач осуществляется на основе некоторого критерия согласия, который основан на использовании меры расхождения между теоретическим распределением и результатами обработки информации о выборке. Обычно используют критерии Пирсона, Колмогорова. Здесь рассмотрим только один – критерий Пирсона. Он наиболее распространен.
Критерий согласия Пирсона (критерий c2) относительно закона распределения
Основан на использовании тестовой статистики t≡u, являющейся мерой расхождения между теоретическим и эмпирическим распределениями:
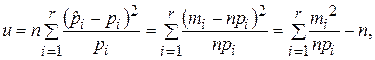
где r – количество интервалов разбиения области значений параметра x при построении гистограммы или эмпирической функции распределения;
mi (i=1, …, r) – количество значений параметра x ввыборке, оказавшихся в i- оминтервале [bi-1, bi);
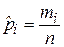 – эмпирические вероятности попадания X в интервал [bi-1, bi):
– эмпирические вероятности попадания X в интервал [bi-1, bi):
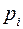 – вероятности попадания случайной величины X в интервал [bi-1, bi):
– вероятности попадания случайной величины X в интервал [bi-1, bi):
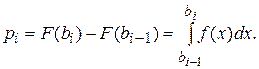
Закон распределения случайной величины U при увеличении n приближается к распределению c2 с (r-l-1) степенями свободы, где l– число неизвестных параметров распределения.
Из двух гипотетических теоретических распределений лучше согласуется с выборочными данными то, при котором величина u окажется меньше.
На практике процедуру подбора теоретического распределения осуществляют следующим образом. Исходя из построенной гистограммы, делают предположение о виде закона распределения, в качестве значений параметров которого принимают точечные оценки, вычисляемые по выборке, например, методом максимального правдоподобия или методом моментов. Затем по приведенным выше формулам определяют вероятности pi и величину u.
Критерий согласия состоит в следующем. Если окажется, что u< 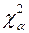 , где – квантиль распределения c2, определяемый из соответствующей таблицы при p=a и k=n–l–1, то гипотезу Н0 о законе распределения принимают, в противном случае – отвергают. При использовании такого правила вероятность отвергнуть гипотезу Н0 при условии, что она справедлива, равна a.
, где – квантиль распределения c2, определяемый из соответствующей таблицы при p=a и k=n–l–1, то гипотезу Н0 о законе распределения принимают, в противном случае – отвергают. При использовании такого правила вероятность отвергнуть гипотезу Н0 при условии, что она справедлива, равна a.
Задача. Проверить гипотезу о нормальном распределении величины X заработной платы работников определенной отрасли или предприятия на уровне значимости a = 0,05 по выборке объема n =100 человек. Результаты выборочного обследования приведены в табл.7 (интервалы заработной платы – в долларах).
аблица 7
| i | [bi-1;bi) | mi | FN(bi-1) | FN(bi) | pi= FN(bi)- -FN(bi-1) | npi | 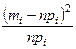
| |
| [190;192) | 0,0014 | 0,1611 | 0,1597 | 15,97 | 0,059 | |||
| [192;194) | ||||||||
| [194;196) | ||||||||
| [196;198) | 0,1611 | 0,3745 | 0,2134 | 21,34 | 0,020 | |||
| [198;200) | 0,3745 | 0,6366 | 0,2621 | 26,21 | 0,122 | |||
| [200;202) | 0,6366 | 0,8437 | 0,2071 | 20,71 | 0,141 | |||
| [202;204) | 0,8437 | 0,9987 | 0,1550 | 15,5 | 0,016 | |||
| [204;206) | ||||||||
| [206;208) | ||||||||
| å | — | — | — | 0,9973 | 99,73 | 0,358 |
Таблица дополнена вычислениями, производимыми в следующем порядке. Вычисляем оценки математического ожидания и дисперсии по формулам:
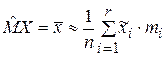
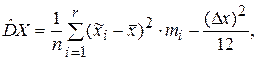
где 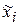 – середина i-го интервала r=9 - количество интервалов,
– середина i-го интервала r=9 - количество интервалов,
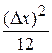 – поправка Шеппарда, Dx = 2.
– поправка Шеппарда, Dx = 2.
Получаем  ,
, 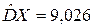 ,
, 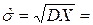 3
3
Для облегчения вычисления величины u объединяем первые три интервала и последние три. Определяем значения функции распределения нормированной случайной величины, используя таблицы функции Лапласа:
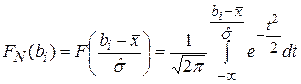 (i=0,1,…,5)
(i=0,1,…,5)
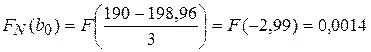
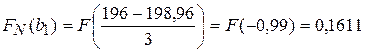
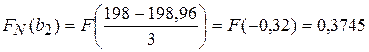

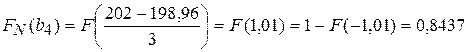

Заполняем всю таблицу и получаем:
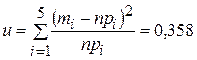
По таблицам для распределения c2 при p=a=0,05 и k=5-2-1=2 определяем 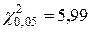 . Так как 0,358<5,99, то гипотезу о нормальном распределении зарплаты принимаем, причем в качестве параметров этого распределения берем: а=198,96 и s =3.
. Так как 0,358<5,99, то гипотезу о нормальном распределении зарплаты принимаем, причем в качестве параметров этого распределения берем: а=198,96 и s =3.
5.3. Проверка простых параметрических гипотез
5.3.1. Критерий Неймана-Пирсона для двух простых гипотез
Критерий основан на использовании отношения правдоподобия, которое для непрерывных и независимых случайных величин Х1, Х2, …, Хn имеет вид:
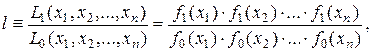
где f0(x) и f1(x) – плотности вероятности, соответствующие гипотезам Н0 и Н1
Если l <1, то более правдоподобна гипотеза Н0, а при l >1- гипотеза Н1
Однако решения принимаются не только исходя из того, какая гипотеза более правдоподобна, но и из других соображений, например, с учетом того, какой экономический ущерб может быть при совершении ошибок в принятии решений. Этот ущерб может быть учтен путем задания значения величины a.
Пусть L0(x1,…,xn) 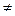 0. Тогда для заданного a существует такая константа c= с(a), что условная вероятность Р((l(x1,…,xn) > c)/Н0) = a.
0. Тогда для заданного a существует такая константа c= с(a), что условная вероятность Р((l(x1,…,xn) > c)/Н0) = a.
Область 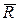 в пространстве х1,…,xn, выражаемая неравенством l(х1,…,xn)>c(a), называется критической областью.
в пространстве х1,…,xn, выражаемая неравенством l(х1,…,xn)>c(a), называется критической областью.
Критерий Неймана-Пирсона в общем случае состоит в следующем. Если выборка x1,x2,…,xn такова что l(х1,…,xn) < с(a), то гипотеза Н0 принимается, в противном случае – отвергается.
Критерий Неймана-Пирсона при заданной вероятности a минимизирует вероятность ошибки второго рода b, которая зависит от гипотезы Н1. Этот критерий положен, в частности, в основу международных и отечественных стандартов по методам статистического контроля качества продукции.
Пример 1. Пусть имеется выборка х1,…,xn из генеральной совокупности, причем известно, что Х~N(a,s2 ), т.е. Х распределена по нормальному закону с математическим ожиданием а и дисперсией s2. Пусть s известна, основная гипотеза Н0: а =а0, а альтернативная Н1: а=а1, причем а1 > a0. Функция правдоподобия для гипотез Н0 и Н1 имеет вид (см. п. 3.3.5.2):
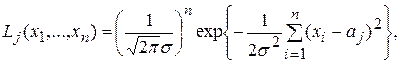 где j=0;1
где j=0;1
Отношение правдоподобия (после преобразований):
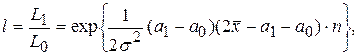
где 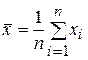 – тестовая статистика.
– тестовая статистика.
Неравенство l >с равносильно неравенству 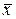 >сa, где ca
>сa, где ca  – некоторая константа, так как l( ) – монотонно возрастающая функция ввиду того, что а1>а0, так что
– некоторая константа, так как l( ) – монотонно возрастающая функция ввиду того, что а1>а0, так что 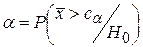
Известно, что если Х~N(a,s2 ), то 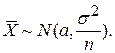 Значит
Значит
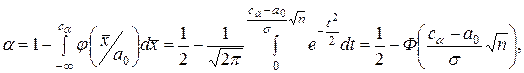
где 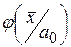 – условная плотность вероятности величины
– условная плотность вероятности величины 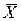 (см. рис.18).
(см. рис.18).
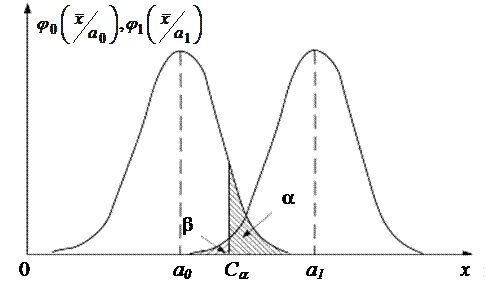
 рис. 17
рис. 17
Обозначим 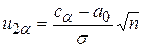 . Тогда имеем следующее уравнение:
. Тогда имеем следующее уравнение:
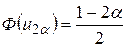
Квантиль u2α при заданном a находится из таблиц функции Лапласа. И тогда
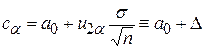
Заметим, что выражение для D совпадает с выражением для половины длины доверительного интервала при доверительной вероятности, равной 1-2a (см. п. 3.4.1).
Правило принятия решения будет следующим: если 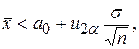 то гипотезу H0 принимают, если
то гипотезу H0 принимают, если 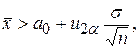 то ее отклоняют.
то ее отклоняют.
Вероятность ошибки второго рода (см. рис.18):
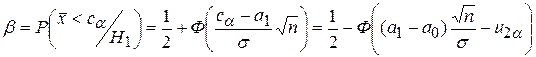
Отсюда можно сделать выводы:
1) величина b уменьшается с ростом a при n=const и с ростом n при a=const
2) при заданных a, b, a0, a1 объем выборки находится из условия:
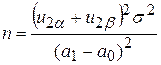
Пример 2. Пусть в примере 1 вместо гипотезы H1: a=a1 (a1>a0) рассматривается сложная гипотеза H1: a1¹a0. Тогда гипотезу H0 следует принимать, если:
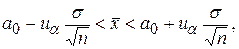
Запишем это выражение иначе:

Но 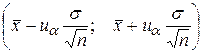 – не что иное, как доверительный интервал для математического ожидания MX при доверительной вероятности 1-a. Значит, правило принятия решения можно сформулировать иначе: если величина a0 окажется в пределах построенного доверительного интервала, то H0 принимают, в противном случае – отклоняют.
– не что иное, как доверительный интервал для математического ожидания MX при доверительной вероятности 1-a. Значит, правило принятия решения можно сформулировать иначе: если величина a0 окажется в пределах построенного доверительного интервала, то H0 принимают, в противном случае – отклоняют.
Здесь использование вероятности b бессмысленно, так как при a1¹a0, сколь угодно близком к a0, получаем b=1–a/2, т.е. слишком большое число.
Пример 3. Пусть имеется выборка х1,…,xn, где xi=0 или xi=1 при любом i, причем все Хi независимы и имеют распределение Бернулли с одной и той же вероятностью p = P(Xi=1). Пусть гипотезы H0: p=p0, H1: p=p1, причем p1>p0.
Функции правдоподобия для гипотез H0 и H1 имеют вид:
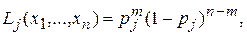 если в выборке m единиц (остальные – нули).
если в выборке m единиц (остальные – нули).
Отношение правдоподобия:
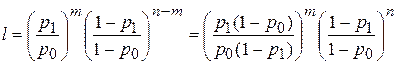
Неравенство l>c можно заменить неравенством m>ca, так как l(m) – возрастающая функция, так что
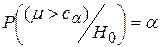
Величина m распределена по биномиальному закону:
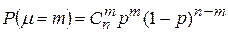
Поэтому 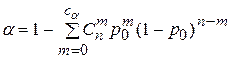
Искомая величина ca является корнем этого уравнения. Но поскольку ca=0,1,2,…, то может оказаться, что это равенство, строго говоря, не выполняется. Тогда надо брать такое 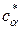 , при котором правая часть уравнения окажется меньше заданного a, при условии, что при ca= - 1 правая часть больше a. Величина определяется численными методами.
, при котором правая часть уравнения окажется меньше заданного a, при условии, что при ca= - 1 правая часть больше a. Величина определяется численными методами.
Если заданы величины p0, p1, a, b, то объем выборки n и границу находят из системы уравнений:
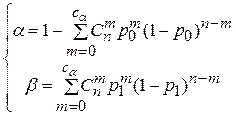
В литературе, международных и отечественных стандартах по методам статистического контроля качества продукции приведены таблицы для определения n и . Там p – доля дефектных изделий в партии, – контрольный норматив (приемочное число), a и b называют рисками поставщика и потребителя соответственно, p0 и p1 – соответственно приемочным и браковочным уровнями дефектности. Если число дефектных изделий в выборке m£ , партию продукцию принимают, в противном случае бракуют.
В социологических исследованиях для решения задач проверки гипотез относительно вероятности p0 часто используют вместо биномиального распределения величины m нормальное с математическим ожиданием np0 и дисперсией np0(1-p0). Однако такую замену можно осуществлять только при np0(1-p0)>9.
адача 1.
В функции налоговой инспекции входит проверка закрепленных за ней предприятий с целью выявления фактов сокрытия доходов от налогообложения. Предположим, ни один такой факт не является допустимым и при тотальной проверке предприятия можно вскрыть все факты сокрытия доходов. Однако налоговая инспекция предпочитает производить сначала выборочные проверки: из N осуществленных торговых сделок проверять только п, причем п<0,1·N. По результатам выборочной проверки может быть принято одно из двух решений: проверку прекратить (если не установлено ни одного факта сокрытия доходов) или произвести тотальную проверку.
Пусть налоговая инспекция считает не допустимым, чтобы уходили от ответственности предприятия, осуществляющие не менее 20% своих торговых сделок с сокрытием доходов. Необходимо:
а) определить при п=8 и п=16 вероятности ошибок при принятии решений:
a – вероятность перехода к тотальной проверке законопослушного предприятия,
b – вероятность не разоблачения предприятия, осуществляющего 20% своих торговых сделок с сокрытием доходов от налогообложения;
б) определить объем выборки n при заданном b=0,1.
Переведем эту задачу на язык задачи проверки гипотез (см. пример 3). У нас р - доля торговых сделок с сокрытием доходов. Гипотезы: Н0 – предприятие законопослушное, Н1 – предприятие скрывает доходы, причем Н0: р=р0=0, Н1: р=р1=0,2. Тестовая статистика m – число сделок (в выборке объема n) с сокрытием доходов. Решения четко соответствуют принятию или отклонению гипотезы Н0, т.е. правило принятия гипотезы Н0 (ввиду того, что р0=0) очевидно: при m=0 Н0 принимается, а при m>0 – отклоняется. Иначе говоря, ca=0. И тогда очевидно, что a=Р((m>0)/H0)=0. Остается одна вероятность b.
Тестовая статистика, как случайная величина, распределена приблизительно по биномиальному закону. Значит:
b = (1-р1)n = 0,8n
Отсюда можно определить b при заданном n либо n при заданном b:
n = log0,8b = lgb / lg0,8
а) При п=8 имеем b=0,88=0,168, при п=16 b=0,816=0,028.
б) При b=0,1 имеем п=lg0,1/ lg0,8 = -1/ -0,097» 10,3
Округляем n в сторону увеличения, чтобы обеспечить b<0,1. Тогда п=11, b(11)=0,811=0,086.
Таким образом, если брать выборку п=11, то примерно каждые 9 предприятий из 100, осуществляющих 20% своих сделок с сокрытием доходов, не будут разоблачены.
адача 2.
Внесем небольшое изменение в условие задачи 1. Предположим, налоговая инспекция считает допустимым, что не более 2% сделок на предприятии осуществляется с сокрытием доходов от налогообложения. Возьмем р0=0,02. По-прежнему ca=0. Вычислим a для п=8 и п=11.
Очевидно a=1-(1-р0)n =1-0,98n
При п=8 имеем a=1-0,988=0,15, при п=11 a=1-0,9811=0,20
Таким образом, при объеме выборки n =11 в среднем каждое пятое законопослушное, но работающее на грани дозволенного предприятие будет подвергаться тотальной проверке.
5.3.2. Критерий Байеса для двух простых гипотез и другие критерии
Критерий Байеса основан на предположениях, что гипотезы являются случайными событиями и известны априорные вероятности гипотез: p0=P(H0), p1=P(H1)=1-p0 (не путать с обозначениями в предыдущем примере 3), а также известна матрица потерь (ее называют платежной матрицей):
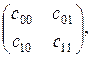
где cij – потери (обычно, экономические) в результате принятия гипотезы Hi в то время как справедлива гипотеза Hj. Потери c00 и c11 от принятия правильных решений обычно имеют знак минус. Их модуль равен выигрышу (доходу).
В соответствии с критерием Байеса, при получении значения тестовой статистики t (в частности, t – среднее арифметическое), определяемой по выборке объема n, необходимо принимать гипотезу H0, если выполняется неравенство:
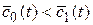 или g(t)≡
или g(t)≡ 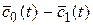 <0,
<0,
где 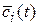 – апостериорные средние потери в случае принятия гипотезы Hi (i=0;1):
– апостериорные средние потери в случае принятия гипотезы Hi (i=0;1):
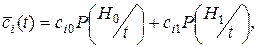
g(t)=0 – граница, отделяющая области принятия G и отклонения гипотезы Н0, 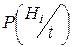 – апостериорная вероятность гипотезы Hi, определяемая по формуле Байеса, которая для непрерывной тестовой статистики имеет вид:
– апостериорная вероятность гипотезы Hi, определяемая по формуле Байеса, которая для непрерывной тестовой статистики имеет вид:
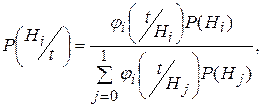 i=0;1,
i=0;1,
где 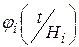 – условная плотность вероятности тестовой статистики T (при условии справедливости гипотезы Hi), вид и параметры которой определяются через информацию о плотностях
– условная плотность вероятности тестовой статистики T (при условии справедливости гипотезы Hi), вид и параметры которой определяются через информацию о плотностях 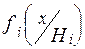 ≡ fi (x).
≡ fi (x).
Условие принятия гипотезы Н0 после подстановки формул имеет вид:
 или
или 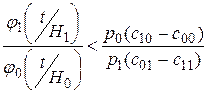 .
.
Для дискретной случайной величины Т в формулах должна стоять вероятность 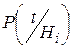 вместо .
вместо .
Потери сij, вообще говоря, часто зависят от t, но, как правило, такая зависимость слабая, поэтому их обычно считают величинами постоянными.
Все формулы справедливы, если под t понимать вектор тестовых статистик, например, среднее арифметическое и оценку среднего квадратического отклонения – s. Тогда  – многомерная плотность вероятности.
– многомерная плотность вероятности.
Вычисление величин потерь требует выбора начала отсчета. Поэтому иногда выбирают c00=0 и c11=0, а c10 и c01 оценивают относительно c00 и c11 соответственно. Все 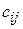 следует оценивать из анализа планируемых решений после принятия гипотез, а также возможных последствий. Потери часто вычисляют как математические ожидания в других вероятностных пространствах.
следует оценивать из анализа планируемых решений после принятия гипотез, а также возможных последствий. Потери часто вычисляют как математические ожидания в других вероятностных пространствах.
При c00=0, c11=0, c10=c01 условие принятия гипотезы Н0 имеем вид:
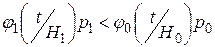 .
.
Этот критерий равносилен критерию максимума апостериорной вероятности
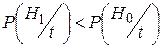 ,
,
в соответствии с которым принимается та гипотеза, апостериорная вероятность которой больше.
Если к тому же р1=р0 , то получим неравенство, равносильное критерию максимума правдоподобия l <1 (см. п. 5.3.1.), при условии, что вектор тестовых статистик t является исчерпывающим для видов распределений fi (x) (i=0;1).
Вместо матрицы потерь часто используют матрицу выигрышей: 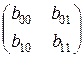
Тогда правило принятия гипотезы Н0: 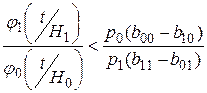
Для конкретных видов распределений fi(x) все эти правила можно получить в более простом виде. В частности, если распределения нормальные с известными дисперсиями, то тестовой статистикой t будет среднее арифметическое и правило принятия гипотезы Н0 запишется в виде квадратного неравенства. Один или два корня квадратного уравнения будут границами области G.
Критерий Байеса, вообще говоря, – это критерий минимума средних потерь (или максимума среднего выигрыша), т.е. математического ожидания потерь. В задачах проверки простых гипотез он выглядит следующим образом:
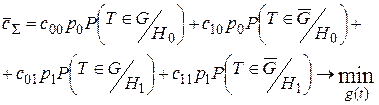
Иначе говоря, граница g(t)=0 между областями принятия и отклонения гипотезы H0 должна задаваться таким образом, чтобы суммарные средние потери от принятия решений (если предположить, что аналогичные ситуации будут повторяться) были минимальны. Произведем в данном выражении замену:
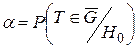 , 1– a=
, 1– a= 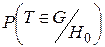 , b=
, b= 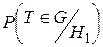 , 1– b=
, 1– b= 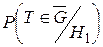 .
.
Заметим, что условные вероятности ошибок I и II рода a и b в общем случае являются функциями от функции g(t), т.е. функционалами. После преобразований и отбрасывания постоянных величин критерий Байеса может быть записан в виде так называемого критерия минимума среднего риска (средних потерь по сравнению с правильными решениями):

Величины p0×a=aб и p1×b=bб называют безусловными вероятностями ошибок первого и второго рода.
Заменяя в этом выражении
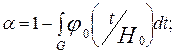

и отбрасывая постоянную, получим:
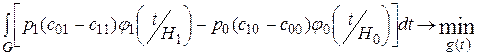
Минимум этого функционала достигается в случае, если подынтегральное выражение меньше нуля, т.е.
Получили условие принятия гипотезы Н0, выведенное прежде.
Замечание. Использование простых гипотез во многих практических ситуациях приводит к слишком грубым правилам принятия решений. Причина состоит в том, что порой трудно решить, каким состояниям системы должны соответствовать гипотезы H0 и H1. Например, при какой доле дефектных изделий партию продукции следует считать удовлетворительного качества, а при какой – неудовлетворительного? А условные плотности вероятности тестовой статистики T, а значит, и правило принятия решений, сильно зависят от того, что принять за H0 и H1. В таких ситуациях можно перейти к использованию сложных гипотез, т.е. к непрерывным множествам возможных состояний системы. Тогда область возможных значений параметра h можно разбить на две области S0 и S1, одна из которых соответствует гипотезе H0, другая – гипотезе H1 (область S1 в случае двухстороннего ограничения на значения параметра будет неодносвязанной). Можно выделить и три односвязанные области. Вместо вероятностей 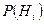 должны быть известны плотности распределения wi(h).
должны быть известны плотности распределения wi(h).
Однако применение сложных гипотез далеко не всегда позволяет улучшить правила принятия решений. Потери сij от принятия гипотезы Hi в то время как справедлива гипотеза Hj часто получаются слишком усредненными. Применение теории проверки гипотез не позволяет учитывать потери как функцию от h. В распространенном частном случае, как уже отмечалось в подразделе 5.1., когда альтернативная сложная гипотеза H1 есть логическое отрицание основной сложной гипотезы H0, легче бывает оценить априорное распределение w(h) параметра h, чем распределения w0(h) и w1(h). Аналогично обстоит дело и в том случае, если имеется 3 гипотезы, составляющее полную группу событий, или более. Тогда надо вообще отказаться от применения теории проверки гипотез и для решения практической задачи использовать теорию статистических решений.
5.4. Дисперсионный анализ
Дисперсионный анализ является одним из методов статистического анализа и используется для выявления влияния факторов, являющихся качественными признаками (т.е. параметрами, измеряемыми в шкале наименований), на характеристики некоторой случайной величины Y. Например, – для выявления влияния способа рекламирования товара на объем его продаж; места торговой точки на цену продукции; технологии производства продукции или услуг на некоторый показатель качества продукции или услуг. В этом случае будет иметь место однофакторный дисперсионный анализ. Если же изучается, например, не только влияние технологии, но и уровень квалификации персонала, то будет иметь место двухфакторный дисперсионный анализ.
В дисперсионном анализе имеют дело со сгруппированными данными (см. п.п. 3.3.2.; 3.3.3.), точнее – с расслоенной выборкой. При этом каждый слой соответствует определенному значению некоторого качественного признака j (j =1,2,3,…, d). Качественный признак называется фактором, а его значение – уровнем фактора. Таким образом, расслоенная выборка – это совокупность всех случайных выборок, каждая из которых получена при определенном (фиксированном) значении уровня фактора. При однофакторном анализе выборка является расслоенной по одному фактору. При двухфакторном – по двум, т.е. имеется два способа расслоения. Однофакторный анализ используется для двух ситуаций. В первой уровни фактора фиксируются заранее (например, способ рекламирования товара). Во второй ситуации уровни фактора являются случайной выборкой из генеральной совокупности уровней фактора (например, мест торговли). Двухфакторный анализ кроме этих двух ситуаций используется еще и в смешанной ситуации.
Оценка влияния фактора на характеристики случайной величины Y производится методами проверки параметрических гипотез, когда альтернативная гипотеза H1 является логическим отрицанием основной простой гипотезы H0, т.е. H1 = 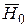 . При этом вводится в рассмотрение только условная вероятность ошибки первого рода a. Гипотезы проверяются по отношению как к дисперсиям, так и к математическим ожиданиям случайной величины Y внутри каждого слоя. В результате обычно получают ответ на главный вопрос: можно ли рассматривать (и насколько уверенно) все выборки из слоев как случайные выборки из одной генеральной совокупности значений случайной величины Y. Если можно, то это как раз и означает, что влиянием факторов можно пренебречь. В противном случае оценивают степень влияния каждого фактора.
. При этом вводится в рассмотрение только условная вероятность ошибки первого рода a. Гипотезы проверяются по отношению как к дисперсиям, так и к математическим ожиданиям случайной величины Y внутри каждого слоя. В результате обычно получают ответ на главный вопрос: можно ли рассматривать (и насколько уверенно) все выборки из слоев как случайные выборки из одной генеральной совокупности значений случайной величины Y. Если можно, то это как раз и означает, что влиянием факторов можно пренебречь. В противном случае оценивают степень влияния каждого фактора.
Здесь рассмотрим только однофакторный дисперсионный анализ. Сначала рассмотрим первую ситуацию. Пусть фактор j имеет d уровней. Уровень j (j=1,2,3,…d) будем характеризовать величиной смещения ∆ j = аj – MY, где аj≡MYj и MY – математические ожидания случайных величин Yj и Y в j -м слое и во всей генеральной совокупности соответственно, а также дисперсией 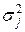 случайной величины Yj в j -м слое. Тогда модель зависимости между случайной величиной Y и фактором j можно записать в виде:
случайной величины Yj в j -м слое. Тогда модель зависимости между случайной величиной Y и фактором j можно записать в виде:
Y(j)≡ Yj = MY+ ∆ j + εj, где εj

