




Хешування даних
Для прискорення доступу до даних можна використовувати попереднє їх впорядкування у відповідності зі значеннями ключів. При цьому можуть використовуватися методи пошуку в упорядкованих структурах даних, наприклад, метод дихотомічного пошуку, що суттєво скорочує час пошуку даних за значенням ключа. Проте при добавленні нового запису потрібно дані знову впорядкувати. Втрати часу на повторне впорядкування можуть значно перевищувати виграш від скорочення часу пошуку. Тому для скорочення часу доступу до даних використовується так зване випадкове впорядкування або хешування. При цьому дані організуються у вигляді таблиці за допомогою хеш-функції h, яка використовується для „обчислення” адреси за значенням ключа.

У попередній главі описувався алгоритм інтерполяційного пошуку, який використовує інтерполяцію для пришвидшення пошуку. Порівнюючи шукане значення зі значеннями елементів у відомих точках, цей алгоритм може визначити імовірне розміщення шуканого елемента. По суті, він створює функцію, яка встановлює відповідність між шуканим значенням і індексом позиції, в якій він повинен знаходитися. Якщо перше передбачення помилкове, то алгоритм знову використовує цю функцію, передбачаючи нове розміщення, і так далі, до тих пір, поки шуканий елемент не буде знайдено.
Хешування використовує аналогічний підхід, відображаючи елементи в хеш-таблиці. Алгоритм хешування використовує деяку функцію, яка визначає імовірне розміщення елемента в таблиці на основі значення шуканого елементу.
Ідеальною хеш-функцією є така хеш-функція, яка для будь-яких двох неоднакових ключів дає неоднакові адреси. Підібрати таку функцію можна у випадку, якщо всі можливі значення ключів відомі наперед. Така організація даних носить назву „досконале хешування”.
Наприклад, потрібно запам’ятати декілька записів, кожен з яких має унікальний ключ зі значенням від 1 до 100. Для цього можна створити масив з 100 комірками і присвоїти кожній комірці нульовий ключ. Щоб добавити в масив новий запис, дані з нього просто копіюються у відповідну комірку масиву. Щоб добавити запис з ключем 37, дані з нього копіюються в 37 позицію в масиві. Щоб знайти запис з певним ключем – вибирається відповідна комірка масиву. Для вилучення запису ключу відповідної комірки масиву просто присвоюється нульове значення. Використовуючи цю схему, можна добавити, знайти і вилучити елемент із масиву за один крок.
У випадку наперед невизначеної множини значень ключів і обмеженні розміру таблиці підбір досконалої функції складний. Тому часто використовують хеш-функції, які не гарантують виконанні умови.
Наприклад, база даних співробітників може використовувати в якості ключа ідентифікаційний номер. Теоретично можна було б створити масив, кожна комірка якого відповідала б одному з можливих чисел; але на практиці для цього не вистарчить пам’яті або дискового простору. Якщо для зберігання одного запису потрібно 1 КБ пам’яті, то такий масив зайняв би 1 ТБ (мільйон МБ) пам’яті. Навіть якщо можна було б виділити такий об’єм пам’яті, така схема була б дуже неекономною. Якщо штат фірми менше 10 мільйонів співробітників, то більше 99 процентів масиву буде пустою.
Щоб вирішити цю проблему, схеми хешування відображають потенційно велику кількість можливих ключів на достатньо компактну хеш-таблицю. Якщо на фірмі працює 700 співробітників, можна створити хеш-таблицю з 1000 комірок. Схема хешування встановлює відповідність між 700 записами про співробітників і 1000 позиціями в таблиці. Наприклад, можна розміщати записи в таблиці у відповідності з трьома першими цифрами ідентифікаційного номеру. При цьому запис про співробітника з номером 123456789 буде знаходитися в 123 комірці таблиці.
Очевидно, що оскільки існує більше можливих значень ключа, ніж комірок в таблиці, то деякі значення ключів можуть відповідати одним і тим коміркам таблиці. Даний випадок носить назву „колізія”, а такі ключі називаються „ключі-синоніми”.
Щоб уникнути цієї потенційної проблеми, схема хешування повинна включати в себе алгоритм вирішення конфліктів, який визначає послідовність дій у випадку, якщо ключ відповідає позиції в таблиці, яка вже зайнята іншим записом.
Усі методи використовують для вирішення конфліктів приблизно однаковий підхід. Вони спочатку встановлюють відповідність між ключем запису і розміщенням в хеш-таблиці. Якщо ця комірка вже зайнята, вони відображають ключ на іншу комірку таблиці. Якщо вона також вже зайнята, то процес повторюється знову до тих пір, поки нарешті алгоритм не знайде пусту комірку в таблиці. Послідовність позицій, які перевіряються при пошуку або вставці елемента в хеш-таблицю, називається тестовою послідовністю.
В результаті, для реалізації хешування необхідні три речі:
· Структура даних (хеш-таблиця) для зберігання даних;
· Функція хешування, яка встановлює відповідність між значеннями ключа і розміщенням в таблиці;
· Алгоритм вирішення конфліктів, який визначає послідовність дій, якщо декілька ключів відповідають одній комірці таблиці.
Методи розв’язання колізій
Для розв’язання колізій використовуються різноманітні методи, які в основному зводяться до методів „ланцюжків” і „відкритої адресації”.
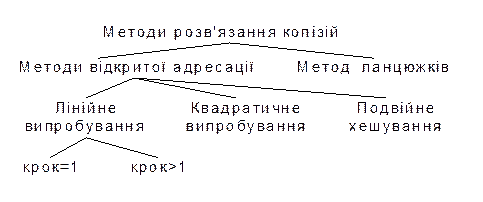
Методом ланцюжків називається метод, в якому для розв’язання колізій у всі записи вводяться покажчики, які використовуються для організації списків – „ланцюжків переповнення”. У випадку виникнення колізій при заповненні таблиці в список для потрібної адреси хеш-таблиці добавляється ще один елемент.
Пошук в хеш-таблиці з ланцюжками переповнення здійснюється наступним чином. Спочатку обчислюється адреса за значенням ключа. Потім здійснюється послідовний пошук в списку, який зв’язаний з обчисленим адресом.
Процедура вилучення з таблиці зводиться до пошуку елемента в його вилучення з ланцюжка переповнення.
Схематичне зображення хеш-таблиці при такому методі розв’язання колізій приведене на наступному рисунку.

Якщо сегменти приблизно однакові за розміром, то у цьому випадку списки усіх сегментів повинні бути найбільш короткими при даній кількості сегментів. Якщо вихідна множина складається з N елементів, тоді середня довжина списків буде рівна N/B елементів. Якщо можна оцінити N і вибрати B якомога ближчим до цієї величини, то в списку буде один-два елементи. Тоді час доступу до елемента множини буде малою постійною величиною, яка залежить від N.
Одна з переваг цього методу хешування полягає в тому, що при його використанні хеш-таблиці ніколи не переповнюються. При цьому вставка і пошук елементів завжди виконується дуже просто, навіть якщо елементів в таблиці дуже багато. Із хеш-таблиці, яка використовує зв’язування, також просто вилучати елементи, при цьому елемент просто вилучається з відповідного зв’язного списку.
Один із недоліків зв’язування полягає в тому, що якщо кількість зв’язних списків недостатньо велика, то розмір списків може стати великим, при цьому для вставки чи пошуку елемента необхідно буде перевірити велику кількість елементів списку.
Метод відкритої адресації полягає в тому, щоб, користуючись якимось алгоритмом, який забезпечує перебір елементів таблиці, переглядати їх в пошуках вільного місця для нового запису.
Лінійне випробування зводиться до послідовного перебору елементів таблиці з деяким фіксованим кроком
a=h(key) + c*i,
де i – номер спроби розв’язати колізію. При кроці рівному одиниці відбувається послідовний перебір усіх елементів після поточного.
Квадратичне випробування відрізняється від лінійного тим, що крок перебору елементів нелінійно залежить від номеру спроби знайти вільний елемент
a = h(key2) + c*i + d*i2
Завдяки нелінійності такої адресації зменшується кількість спроб при великій кількості ключів-синонімів. Проте навіть відносно невелика кількість спроб може швидко привести до виходу за адресний простір невеликої таблиці внаслідок квадратичної залежності адреси від номеру спроби.
Ще один різновид методу відкритої адресації, яка називається подвійним хешуванням, базується на нелінійній адресації, яка досягається за рахунок сумування значень основної і додаткової хеш-функцій.
a=h1(key) + i*h2(key).
Розглянемо алгоритми вставки і пошуку для методу лінійного випробування.
Вставка:
1. i = 0
2. a = h(key) + i*c
3. Якщо t(a) = вільно, то t(a) = key, записати елемент і зупинитися
4. i = i + 1, перейти до кроку 2
Пошук:
1. i = 0
2. a = h(key) + i*c
3. Якщо t(a) = key, то зупинитися – елемент знайдено
4. Якщо t(a) = вільно, то зупинитися – елемент не знайдено
5. i = i + 1, перейти до кроку 2
Аналогічно можна було б сформулювати алгоритми добавлення і пошуку елементів для будь-якої схеми відкритої адресації. Відмінності будуть лише у виразі, який використовується для обчислення адреси (крок 2).
З процедурою вилучення справа складається не так просто, так як вона в даному випадку не буде оберненою до процедури вставки. Справа в тому, що елементи таблиці знаходяться в двох станах: вільно і зайнято. Якщо вилучити елемент, перевівши його в стан вільно, то після такого вилучення алгоритм пошуку буде працювати некоректно. Нехай ключ елемента, який вилучається, має в таблиці ключі синоніми. У цьому випадку, якщо за ним в результаті розв’язання колізій були розміщені елементи з іншими ключами, то пошук цих елементів після вилучення завжди буде давати негативний результат, так як алгоритм пошуку зупиняється на першому елементі, який знаходиться в стані вільно.
Скоректувати цю ситуацію можна різними способами. Самий простий із них полягає в тому, щоб проводити пошук елемента не до першого вільного місця, а до кінця таблиці. Проте така модифікація алгоритму зведе нанівець весь виграш в прискоренні доступу до даних, який досягається в результаті хешування.
Інший спосіб зводиться до того, щоб відслідкувати адреси всіх ключів-синонімів для ключа елемента, що вилучається, і при необхідності розмістити відповідні записи в таблиці. Швидкість пошуку після такої операції не зменшиться, але затрати часу на саме розміщення елементів можуть виявитися значними.
Існує підхід, який не має перерахованих недоліків. Його суть полягає в тому, що для елементів хеш-таблиці добавляється стан „вилучено”. Даний стан в процесі пошуку інтерпретується, як зайнято, а в процесі запису як вільно.
Тепер можна сформулювати алгоритми вставки, пошуку і вилучення для хеш-таблиці, яка має три стани елементів.
Вставка:
1. i = 0
2. a = h(key) + i*c
3. Якщо t(a) = вільно або t(a) = вилучено, то t(a) = key, записати елемент і стоп
4. i = i + 1, перейти до кроку 2
Вилучення:
1. i = 0
2. a = h(key) + i*c
3. Якщо t(a) = key, то t(a) = вилучено, стоп елемент вилучений
4. Якщо t(a) = вільно, то стоп елемент не знайдено
5. i = i + 1, перейти до кроку 2
Пошук:
1. i = 0
2. a = h(key) + i*c
3. Якщо t(a) = key, то стоп – елемент знайдено
4. Якщо t(a) = свободно, то стоп – елемент не знайдено
5. i = i + 1, перейти до кроку 2
Алгоритм пошуку для хеш-таблиці, яка має три стани, практично не відрізняється від алгоритму пошуку без врахування вилучення. Різниця полягає в тому, що при організації самої таблиці необхідно відмічати вільні і вилучені елементи. Це можна зробити, зарезервувавши два значення ключового поля. Інший варіант реалізації може передбачати введення додаткового поля, в якому фіксується стан елемента. Довжина такого поля може складати всього два біти, що достатньо для фіксації одного з трьох станів.

