Базы данных
Основу внутримашинного информационного обеспечения ИС составляют базы данных или банки данных.
Для того чтобы понять сущность баз данных, рассмотрим их отличие от файловой организации данных. ИТ и ИС первоначально основывались на файловой организации данных.
Особенности файловой организации данных:
- ориентирована на отдельные несложные задачи; используется при незначительных объемах информации;
- предполагает локальный способ организации данных в форме каталогов и подкаталогов;
- каждая программа (ПО, приложение) работает с одним или несколькими файлами данных, структура которых прямо зависит от приложений. Приложение – это программа или комплекс программ, предназначенных для выполнения однотипных работ.
- информационные возможности системы полностью определяются возможностями приложений;
- любые изменения в структуре данных возможны только при условии соответствующего изменения приложений;
- информация, содержащаяся в файлах данных одного приложения, в большинстве случаев недоступна для других приложений.
Файловую организацию программного и информационного обеспечения можно представить в виде схемы:

На схеме видно, что некоторые приложения могут использовать одни и те же файлы данных; в других случаях требуется специальная программа-конвертер для преобразования данных из одного формата в другой, доступный для использования другим приложением. Каждое из приложений хранит внутри себя описание используемых данных.
Недостатки файловой организации:
1. Зависимость данных от приложений (файлы данных жестко привязаны к ПО).
Использование файлов данных возможно только вместе с соответствующими приложениями. Это, во-первых, ограничивает сферу использования данных: они не могут использоваться в тех местах, где не установлено соответствующее программное обеспечение. Во-вторых, возможности обработки информации ограничены алгоритмами, заложенными в материнской программе, а разработка нового программного обеспечения на базе существующих файлов затруднено, так как описания данных и их структуры опять же хранятся внутри материнской программы.
2. Трудоемкость внесения изменений данных и программ.
Любые изменения в структуре информации требуют соответствующего изменения приложения, то есть необходимо дополнительное программирование. Это ставит пользователя в зависимость от разработчиков ПО, а также увеличивает затраты на поддержание работоспособности АИС. Кроме того, если одни и те же файлы данных используются несколькими приложениями, то потребуется переработка всех этих связанных программных средств.
3. Избыточность информации и дублирование данных.
Разные приложения могут использовать одну и ту же информацию, например, нормативно-справочные данные. Однако каждое приложение использует файлы данных собственного формата, поэтому приходится дублировать эту информацию для каждой из использующих программ. Это увеличивает затраты на хранение и использование излишней информации, на программирование (поскольку в различных программах повторяются одни и те же процедуры обработки данных), а также при внесении любых изменений в данные (так как эту процедуру приходится повторять для каждого из приложений).
4. Разобщение данных. Отсутствие связи между файлами. Исключает работу в диалоге. Трудности по обеспечению актуальности, достоверности и непротиворечивости данных.
Файлы данных, используемые разными приложениями, не связаны или только частично связаны между собой. Это приводит к затруднениям при решении задач, использующих данные разных программ, к противоречивости данных, к нарушению их целостности.
5. Снижение оперативности информации из-за дублирования, переработки большого числа файлов, отсутствия целостности данных.
Основные понятия базы данных и модели представления данных
Для ИС целесообразна организация хранения хорошо структурированных данных, доступных различным прикладным программам – приложениям. Таким средством хранения являются базы данных или банки данных, которые составляют основу внутримашинного информационного обеспечения ИС.
База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей.
База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами организации.
База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
В определениях явно или неявно присутствуют отличительные признаки БД:
1. БД хранится и обрабатывается в вычислительной системе.
Таким образом, любые некомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются.
2. Данные в БД логически структурированы (систематизированы) с целью обеспечения их эффективного поиска и обработки.
Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика (определенный круг значений некоторого класса информационных единиц) и допустимые операции.
3. БД включает схему, или метаданные (структурированные данные, представляющие собой характеристики описываемых сущностей), описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью).
Схема данных включает в себя описания содержания, структуры и ограничений целостности.
Свойства БД:
- обеспечивает совместное хранение данных с их взаимосвязями и описаниями;
- объясняет значения и структуру данных;
- поддерживает ограничения, накладываемые на данные (например, определяет тип данных, их размерность, точность и т.п.);
- хранимые данные являются «открытыми», т.е. понятными для любых приложений, работающих с базой;
- является самостоятельным информационным ресурсом (ИР), который может многократно использоваться различными приложениями, оставаясь при этом независимым от них.
БД представляет собой ИР структурированных данных, предназначенный для многоцелевого, многократного использования в конкретных предметных областях.
Для организации данных в БД необходимо построение информационно-логической модели представления данных в некоторой предметной области. Предметная (прикладная) область – часть реального мира, рассматриваемая в пределах данного контекста, под которым понимается область исследования или объект некоторой деятельности. Предметная область – совокупность связанных между собой функций и задач управления, с помощью которых достигается выполнение поставленной цели.
Модель данных – это некоторая абстракция, которая позволяет систематизировать информацию и отражает ее свойства по содержанию, структуре, объему, связям, динамике.
Основные элементы инфологической модели – информационные объекты (сущности) и взаимосвязи (структурные связи) между ними.
Информационный объект – это модель некоторого реального объекта, процесса или явления, представленная в виде совокупности логически связанных реквизитов.
Наиболее распространены иерархическая, сетевая, реляционная и постреляционная модели представления данных. Они отличаются способом представления связей между объектами.
Иерархическая и сетевая модели предполагают наличие связей между данными, имеющими какой-либо признак.
Иерархическая модель отображает объекты-сущности и их связи в виде ориентированного дерева-графа, где возможны только односторонние связи от старших вершин к младшим (рис.1).

Рис.1. Структура иерархической модели
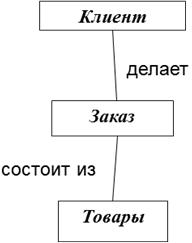
Отношения между данными строятся по типу «родитель – потомки» и изображаются в виде дерева. У каждого объекта только один родитель, но может быть несколько потомков. У корневого объекта нет родителя. Ребра между объектами отображают отношения. На ребре указывается название отношения. Например, между объектами «клиент» и «заказ» может быть отношение, которое называется «делает», а между «заказ» и «товары» – отношение «состоит из».
Сетевая модель организации данных (рис.2) является расширением иерархической модели и предоставляет бóльшие возможности по сравнению с последней, однако сложнее в реализации и использовании. В модели теоретически возможны связи «всех со всеми»; потомок может иметь любое число предков.
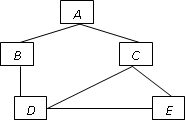
Рис.2. Представление связей в сетевой модели
Достоинство иерархической и сетевой моделей – быстрый доступ к информации в БД.
Недостатки иерархической и сетевой моделей: требуются значительные ресурсы памяти ЭВМ (поскольку каждый элемент данных должен содержать ссылки на другие элементы); недостаток основной памяти ЭВМ снижает скорость обработки данных; сложность реализации СУБД.
Реляционная модель является простейшей и наиболее привычной формой представления данных в виде таблицы или связанных между собой таблиц.
В теории множеств таблице соответствует термин отношение (relation). Для манипуляций с таблицами используется аппарат реляционной алгебры и реляционного исчисления, где для отношений определены известные операции с множествами (объединение, вычитание, пересечение, соединение и т.д.).
Достоинства реляционной модели:
1. Простота структуры данных и доступность для понимания табличной формы.
2. Применение при проектировании строгого математического аппарата.
3. Независимость данных и использующих их программ. Для изменения структуры БД необходимы минимальные изменения в прикладных программах.
4. Для построения запросов и написания приложений нет необходимости знания конкретной организации БД во внешней памяти.
5. Сравнительная простота инструментальных средств поддержки модели.
6. Наилучшее соответствие структуре экономической информации. Модель доминирует при построении ЭИС.
Недостатки реляционной модели:
1. Низкая скорость доступа и необходимость большого объема внешней памяти. Зависимость скорости работы от размера БД.
2. Жесткость структуры данных (например, невозможность задания строк таблицы произвольной длины).
3. Сложная структура данных при большом количестве таблиц.
4. Невозможность представления любой предметной области.
Для преодоления недостатков реляционной модели развиваются постреляционные, многомерные, объектно-ориентированные, объектно-реляционные, семантические и др. модели данных. Многие из них служат для интеграции баз данных, баз знаний и языков программирования.
Структура реляционной БД
Если в базе нет никаких данных (БД пустая), то она всё равно является полноценной БД, так как в ней содержится информация в виде структуры базы. Структура БД определяет методы занесения и хранения данных.
БД может содержать различные объекты; основными объектами являются таблицы. Простейшая БД имеет одну таблицу, и структура базы соответствует структуре её таблицы.
Структуру таблицы образуют столбцы и строки, аналогами которых в структуре простейшей БД являются поля и записи. Если записи в таблице отсутствуют, значит, ее структура образована только набором полей. Изменение состава полей базы или их свойства соответствует изменению структуры БД, т.е. получается новая БД.
Итак, некоторое количество структурированных элементов и отношений между ними образуют базу данных.
Наименьший из них (элементарный) – элемент данных – является значением поля (атрибута).
Поле (атрибут) – элементарная единица логической организации данных, которая соответствует отдельной, неделимой единице информации – реквизиту. Свойства поля: имя, тип, размер, точность, формат.
Полям соответствуют столбцы. Поле отражает определенную характеристику сущности, размещает однородные значения данных, т.е. все данные в столбце имеют одинаковый тип (числовой, символьный или другой) и длину.
Обычный атрибут может не иметь никакого значения (атрибут имеет нулевое значение). Например, в таблице СОТРУДНИКИ у сотрудника Степановой нет рабочего телефона (рис.3).
Запись (кортеж) состоит из элементов данных, соответствует показателю и содержит данные об одном экземпляре сущности (объекта) – одном счете, одном работнике, одном предприятии и т.д.
Записям соответствуют строки; они однотипны по структуре, отличаются друг от друга хотя бы одним значением (т.е. одинаковые строки отсутствуют). «Однотипные» означает, что все записи обладают одним и тем же набором атрибутов (полей), хотя для каждой записи поле может принимать свое собственное значение.
Агрегат данных занимает промежуточное положение между элементом данных и записью; состоит из нескольких реквизитов, совокупность которых рассматривается как одно целое. Агрегат данных может быть простым (состоит только из элементов данных) и составным (состоит из элементов и простых агрегатов).
Набор из однотипных записей называется файлом БД (таблицей) и соответствует массиву информации. Файл БД не всегда соответствует физическому файлу. Информация файла БД может содержаться в нескольких физических файлах, и наоборот, несколько файлов БД могут содержаться внутри одного физического файла.
Каждая таблица (отношение) содержит сведения об одной сущности (объекте) предметной области, имеет уникальное имя и состоит из однотипных записей (строк). Рассмотрим таблицу СОТРУДНИКИ (с данными о сотрудниках предприятия):

Рис.3
У всех трех записей атрибуты (столбцы) одинаковы, однако принимают разные значения. Так, для 1-й записи атрибут "Табельный №" принимает значение "008976", для 2-й записи – "008980" и т.д. Значения некоторых атрибутов у разных записей могут совпадать, например, 1-я и 2-я записи имеют одинаковое значение атрибута "Код отдела" (024).
Для идентификации (однозначного определения) каждой записи таблица имеет уникальный атрибут (первичный ключ, ключевое поле). Значение первичного ключа уникально, т.е. не может повторяться в нескольких записях. Оно позволяет отыскать единственную запись в таблице и отличить одну запись от другой. В таблице СОТРУДНИКИ ключом является атрибут "Табельный №".
Первичный ключ может состоять из нескольких полей; тогда он называется составным ключом.
В качестве ключей целесообразно применять числовые коды: код товара, номер заказа и т.п. Ключ не может иметь нулевое значение.
Совокупность взаимосвязанных файлов БД (предприятия, счета, банки) представляет собой базу данных (рис.4). Если связи между файлами нет, то их совокупность нельзя считать базой данных.
Таким образом, реляционная БД представляет собой множество взаимосвязанных двумерных таблиц.
На схеме показано три информационных файла БД, связанных между собой следующим образом: «ПРЕДПРИЯТИЯ обслуживаются БАНКАМИ, у них открыты СЧЕТА в этих банках».

Рис.4
Создание логических связей между таблицами
Назначение межтабличных связей:
- объединение данных из разных таблиц;
- обеспечение целостности данных;
- рациональное хранение данных и автоматизация задач обслуживания базы.
Межтабличные связи обеспечиваются одинаковыми полями двух таблиц (ключами связи).
При этом одна из таблиц является главной, другая таблица – связанной (или подчиненной). Главная таблица участвует в связи своим первичным ключом. Ключ связи подчиненной таблицы называют внешним ключом, так как он ссылается на первичный ключ другой ("внешней") таблицы.
Существует несколько типов связей между объектами. Наиболее распространены три типа связи: «один к одному», «один ко многим», «многие ко многим».
Связь «один-к-одному» (1:1). A B. Предполагает, что одному экземпляру объекта А соответствует один экземпляр объекта B, и наоборот. То есть, каждой записи одной таблицы соответствует одна запись в другой таблице. Используется редко, как правило, для разделения широких таблиц.
Связь «один-ко-многим» (1: ∞ или 1: М). A B. Одному экземпляру объекта А соответствует несколько экземпляров объекта B, но каждый экземпляр объекта В связан строго с одним экземпляром объекта А.
Именно по этому типу, как правило, устанавливают связи между таблицами. То есть, каждой записи в одной таблице соответствует много записей в другой, но каждой записи во второй таблице соответствует только одна запись в первой.
Для двух таблиц связь по типу (1: ∞) организуется на основе общего поля главной и подчиненной таблиц. Причем в главной таблице оно является первичным ключом, т.е. на стороне «один» должно выступать ключевое поле, содержащее уникальные, неповторяющиеся значения. В подчиненной таблице ключ связи (внешний ключ) может быть либо частью уникального ключа, либо не входить в состав ключа, т.е. на стороне «многие» значения поля могут повторяться.
Рассмотрим две таблицы с информацией о сотрудниках и об отделах:
|
| 
|
Между таблицами можно установить связь "СОТРУДНИК - работает в - ОТДЕЛЕ". Для получения информации об отделе, в котором работает сотрудник, надо взять значение атрибута "Код отдела" в таблице "СОТРУДНИКИ" и найти соответствующий код в таблице "ОТДЕЛЫ". Таким образом, две записи из разных таблиц как бы объединяются в одну:

Ключами связи таблиц являются поля "Код" главной таблицы ОТДЕЛЫ и "Код отдела" подчиненной таблицы СОТРУДНИКИ. Поле "Код" является первичным ключом таблицы ОТДЕЛЫ. Если бы это было не так, и коды отделов в этой таблице повторялись, невозможно было бы определить, о каком из отделов говорится в первой таблице СОТРУДНИКИ. Второй ключ связи – "Код отдела" таблицы СОТРУДНИКИ – является внешним ключом, так как он ссылается на ключ «Код» "внешней" таблицы ОТДЕЛЫ.
Поле «Код отдела» таблицы СОТРУДНИКИ не может быть уникальным, поскольку в каком-либо отделе может работать сколь угодно сотрудников.
Связь «многие-ко-многим» (∞: ∞). A B. Одному экземпляру объекта А соответствует несколько экземпляров объекта B, и наоборот – одному экземпляру объекта В соответствует несколько экземпляров объекта А. Такая связь в явном виде не может быть установлена, поэтому используется третья связующая таблица.
Целостность данных
Одно из главных требований к БД – целостность данных.
Целостность данных подразумевает поддержание полной, непротиворечивой и адекватной информации. Не должно быть ситуации, когда заказывается товар, который отсутствует на складе, или в результате ошибки ввода информация о сотруднике не соответствует данным картотеки на сотрудников.
Для поддержания целостности данных внешний ключ должен ссылаться на существующее значение первичного ключа. Например, если в таблице СОТРУДНИКИ указать код отдела со значением 028, а в таблице ОТДЕЛЫ отдела с таким кодом нет, то целостность данных нарушится, т.е. будет показан сотрудник несуществующего отдела. Поэтому база данных или работающее с ней приложение должны запрещать ввод значений внешнего ключа, ссылающегося на несуществующее значение первичного ключа.
Нарушение целостности может возникнуть и в случае, когда удаляется одна из записей таблицы, имеющей ключ. Например, при удалении из таблицы ОТДЕЛЫ 3-ей записи, содержащей значение ключа 024, 1-я и 2-я записи таблицы СОТРУДНИКИ будут ссылаться на несуществующий отдел.
Способы обеспечения целостности данных в случае удаления записей:
· Запрет на удаление записей, на которые существуют ссылки. Означает запрет на удаление или изменение данных в ключевом поле главной таблицы, если с ним связаны какие-либо поля других таблиц. Например, нельзя удалить запись об отделе с кодом 024, пока существует в этом отделе хотя бы один сотрудник.
· "Каскадное" уничтожение (или обновление) ссылающихся записей. Означает, что при удалении (или изменении) данных в ключевом поле главной таблицы автоматически удаляются (или изменяются) данные в полях связанных таблиц. При удалении записи об отделе 024 в таблице ОТДЕЛЫ все записи о сотрудниках этого отдела в таблице СОТРУДНИКИ также будут удалены.
· Внешние ключи записей, ссылающихся на удаляемую запись, принимают нулевое значение. При удалении из таблицы «ОТДЕЛЫ» записи об отделе с кодом 024 атрибут "Код отдела" для первых двух сотрудников в таблице "СОТРУДНИКИ" примет нулевое значение.
Нормализация данных
Нормализация – это установление ограничений при создании таблиц с целью устранения дублирования информации, снижения времени на ее ввод и корректировку, отслеживания противоречивости в данных.
Выполняется нормализация путем удаления из таблиц повторяющихся данных и переноса их в новые таблицы, записи которых не содержат повторяющихся значений.
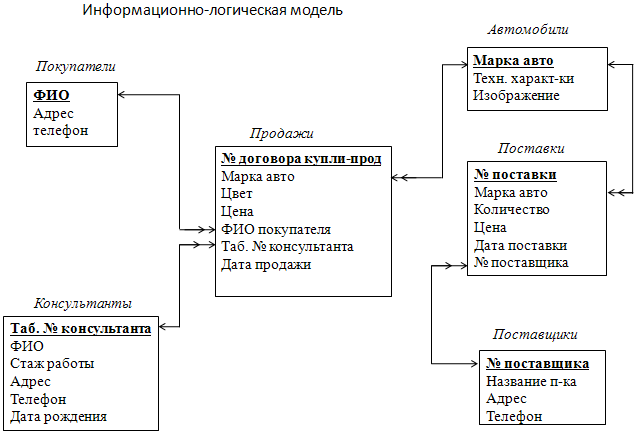
Рассмотрим нормализацию данных на примере создания реляционной модели, описывающей предметную область «Деятельность автосалона».
В исходных таблицах «Продажи» и «Поставки» представлены данные, которые могут быть отражены в системе. В базе должны храниться сведения о том, кто и когда приобрел автомобиль, кто занимался работой с клиентами, информация о поставках машин.

Метод нормализации основан на концепции нормальных форм ограничений. Выделяют 1-ю нормальную форму (1Н.Ф.), 2Н.Ф., 3Н.Ф., Н.Ф. Бойса-Кодда, 4Н.Ф., 5Н.Ф. (или форму проекции-соединения). При нормализации выполняют переход от одной Н.Ф. к другой. Каждая следующая Н.Ф. сохраняет в себе свойства предыдущих и, в некотором смысле, лучше их. На практике 3-я Н.Ф. отношений достаточна, и приведением к ней процесс нормализации обычно заканчивается.
Ограничения 1-ой Н.Ф. заключаются в неделимости (атомарности) значений всех атрибутов таблицы. Данное требование является базовым, поэтому любая реляционная таблица, по определению, уже находится в 1Н.Ф.
В исходных таблицах «Продажи» и «Поставки» это требование не выполняется – на пересечении строк и столбцов встречается более одного значения (т.е. эти таблицы – нереляционные).
В таблицах «Продажи 1Н.Ф.» и «Поставки 1Н.Ф.» эта ситуация исправлена, таблицы удовлетворяют ограничениям 1-й Н.Ф.

В таблицах необходимо установить ключевые поля, значения которыходнозначно идентифицируют записи.
В таблице «Продажи 1Н.Ф.» ни одно из полей не может рассматриваться в качестве простого ключа – все поля содержат повторяющиеся значения: покупатель может неоднократно совершить покупку; каждый консультант работает с несколькими клиентами; одну и ту же марку машин могут приобрести несколько покупателей; в один и тот же день может быть совершено несколько сделок.
Поэтому использован составной ключ, части которого могут быть, например, поля «Дата продажи» и «ФИО покупателя» – зная два этих значения, можно узнать и данные о покупателе, и сведения о приобретенной им машине, и кто из консультантов работал с данным клиентом (при допущении, что клиент приобретает не более одного авто в день). Составные ключи обозначены затенением.
В таблице «Поставки 1Н.Ф.» также не получится обойтись одним простым ключом. В один день могут быть поставки от нескольких поставщиков; один поставщик неоднократно поставляет машины в салон, машины одной марки могут быть приняты от разных поставщиков.
Поэтому составной ключ состоит из нескольких полей: «Дата поставки», «Название поставщика» и «Марка авто». Они однозначно определяют значения и всех остальных полей одной из записей (сколько авто конкретной марки получено, по какой цене и пр.).
Далее выполняется переход к ограничениям 2-й Н.Ф. Отношение находится во 2-й Н.Ф., если выполняются требования 1-й Н.Ф. и каждый неключевой атрибут полностью зависит от всех частей ключа. Для перехода от 1-й Н.Ф. ко 2-й Н.Ф. необходимо:
- выявить неключевые атрибуты, которые полностью зависят от всех частей составного ключа и оставить их в таблице;
- выявить, от каких частей ключа зависят остальные неключевые атрибуты и вынести их в отдельные таблицы: часть ключа (одно или несколько полей) + поля, находящиеся в зависимости от этой части. В результате каждое неключевое поле окажется в полной зависимости от ключа.
В таблице «Продажи 1Н.Ф.» от всех частей ключа (от значений обоих полей «ФИО покупателя» и «Дата продажи») зависят поля «Марка авто», «Техн. характеристики», «Фото», «Цвет», «Цена», «ФИО консультанта», «Стаж работы», «Адрес консультанта», «Тел. конс.», «Дата рождения». Эти поля остаются в исходной таблице. Поля же «Адрес покупателя» и «Телефон покупателя» зависят только от одной части ключа – от поля «ФИО покупателя», и они выносятся в отдельную таблицу «Покупатели». Обе таблицы соединяются линией связи по атрибуту связи («ФИО покупателя»).

В таблице «Поставки 1Н.Ф.» от всех частей ключа (от значений всех полей «Дата поставки», «Название поставщика» и «Марка авто») зависят только поля «Количество» и «Цена». Поля «Адрес поставщика» и «Телефон поставщика» зависят от части ключа «Название поставщика». Поля «Техн. характеристики» и «Фото» зависят от части ключа «Марка авто». В итоге таблица разделится на три таблицы: «Поставки», «Поставщики» и «Автомобили».

Последний переход выполняется к ограничениям 3-й Н.Ф. Отношение находится в 3-й Н.Ф., если выполняются требования 2-й Н.Ф., и каждый неключевой атрибут непосредственно, напрямую(нетранзитивно) зависит от ключа. При транзитивной зависимости атрибутов Х и Y существует такой промежуточный атрибут Z, что имеются прямые зависимости X→Z и Z→Y.
Для перехода от 2Н.Ф. к 3Н.Ф. необходимо:
- выявить поля, от которых зависят другие неключевые поля;
- создать новую таблицу для каждого такого поля и зависящих от него полей;
- удалить перемещенные поля из исходной таблицы, оставив те из них, которые станут внешними ключами.
В схеме «Продажи-Покупатели 2Н.Ф.» поля «Техн. характеристики» и «Фото» зависят от ключа не напрямую, а через неключевой атрибут «Марка авто». Эти поля выносятся в отдельную таблицу «Автомобили». Таблица «Продажи» и новая таблица «Автомобили» связываются по полю «Марка авто».
Поля «Стаж работы», «Адрес конс.», «Тел», «Дата рожд.» зависят от неключевого поля «ФИО консультанта». Они также выносятся в отдельную таблицу «Консультанты», которая связывается с таблицей «Продажи» по полю «ФИО консультанта». В результате получен набор таблиц в 3-ей Н.Ф.

В схеме «Поставки-Поставщики-Автомобили 2Н.Ф.» отсутствуют транзитивные зависимости, поэтому 2-я Н.Ф. отношений тождественна 3-ей Н.Ф.
Обе схемы могут быть самостоятельными базами: БД по поставкам и БД по продажам. Однако, в связи с тем, что осуществляются и поставки, и продажи товара одного ассортимента, то желательно информацию как о поставках товара, так и о его продаже отразить в одной базе. Поэтому обе схемы связаны по таблице «Автомобили».

В результате определены информационные объекты модели: «Консультанты»; «Автомобили»; «Покупатели»; «Поставщики»; «Поставки»; «Продажи».

Реквизитный состав объектов:
Консультанты (ФИО, Стаж работы, Адрес, Телефон, Дата рождения);
Автомобили (Марка, Технические характеристики, Изображение);
Покупатели (ФИО, Адрес, Телефон);
Поставщики (Название, Адрес, Телефон);
Поставки (Марка автомобиля, Количество, Цена, Дата, Название пост-ка);
Продажи (Марка автомобиля, Цвет, Цена, ФИО покупателя, ФИО консультанта, Дата).

Установим связи между объектами по типу «один-ко-многим» (1: ∞) и «многие-ко-многим» (∞: ∞).
Связи по типу 1:М между объектами:
«Покупатели» и «Продажи» - одному покупателю может быть продано несколько машин, но одна сделка по продаже осуществляется строго с одним покупателем.
«Автомобили» и «Продажи» - одна марка авто может быть продана несколько раз, но за одну сделку продается только одна марка. «Консультанты» и «Продажи» - один консультант обслуживает несколько сделок, но одну продажу обслуживает строго один консультант.
«Автомобили» и «Поставки» - одна марка авто может неоднократно поставляться.
«Поставщики» и «Поставки» - один поставщик совершает несколько поставок, но одну поставку совершает строго один поставщик.
Связи по типу М:М между объектами:
«Покупатели» и «Консультанты» устанавливается через связующую таблицу «Продажи» - один покупатель в разное время может обслуживаться несколькими консультантами, один консультант может обслуживать несколько покупателей. Здесь связующая таблица «Продажи» выступает как таблица взаимодействия объектов «Покупатели» и «Консультанты».
«Покупатели» и «Автомобили» (связующая таблица «Продажи») - один покупатель может приобрести автомобили разных марок, автомобили одной марки могут быть проданы нескольким покупателям.
«Консультанты» и «Автомобили» (связующая таблица «Продажи») - один консультант продает автомобили разных марок, одну марку могут продать разные консультанты.
«Поставщики» и «Автомобили» (связующая таблица «Поставки» - взаимодействие объектов) - один поставщик поставляет автомобили разных марок, каждая марка может быть поставлена разными поставщиками.
Для перехода от составных ключей к простым в таблицы вводятся числовые коды: «№ поставки», «№ поставщика», «№ продажи», «Таб. № консультанта».
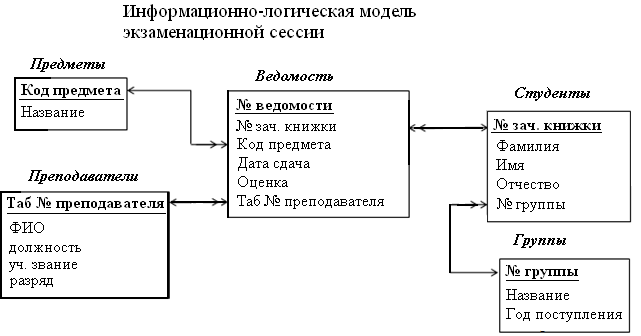
Ниже представлена информационно-логическая модель учета результатов экзаменационной сессии студентами ВУЗа. Объекты модели: студенты, группы, предметы, преподаватели. Взаимодействие объектов – экзаменационная ведомость.