




ЭЛЕКТРОННЫЙ КОНСПЕКТ ЛЕКЦИЙ
База данных (БД) — это поименованная совокупность данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения, манипулирования данными, независимо от прикладных программ.
Основными функциями БД являются:
· хранение информации и организация ее защиты;
· периодическое изменение хранимых данных (обновление, удаление, добавление);
· поиск и отбор данных по запросам пользователей и прикладных программ;
· обработка найденных записей и вывод результатов в заданной форме.
В операционных системах, в среде которых функционирует база данных, специальных средств для создания и обработки БД не предусмотрено. Поэтому необходим комплекс программ, который бы обеспечивал автоматизацию функций БД; этот комплекс называется системой управления базой данных (СУБД) и представляет собой совокупность программ и языковых средств, предназначенных для создания, ведения и использования БД. СУБД — это пакет прикладных программ, расширяющих возможности операционной системы по обработке БД.
Описание предметной области, выполненное без ориентации на используемые в дальнейшем программные и технические средства, называется инфологической моделью предметной области. Такой информацией являются ведения о классах объектов предметной области и их количеств в каждом классе, о фиксируемых свойствах этих объектов, о связях между ними, динамике их изменения. Инфологическая модель служит связующим звеном между специалистами предметной области и проектировщиками БД.
Модель данных логического уровня, СУБД, называют даталогической моделью. Эта модель представляет собой отображение логических связей между элементами данных безотносительно к их содержанию и среде хранения. Даталогическая модель строится с учетом ограничений конкретной СУБД. При построении даталогической модели учитываются особенности отображаемой предметной области. База данных предполагает интегрированное и взаимосвязанное хранение данных, поэтому для проектирования данной модели необходимо иметь соответствующее описание предметной области.
В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели. Сначала стали использовать иерархические даталогические модели. Иерархические БД состоят из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного “ корневого” типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждый из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи. Пример типа дерева приведен на рис.9.
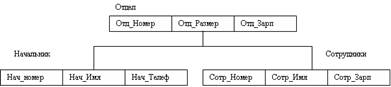
Рис. 9. Иерархическая модель данных.
Здесь Отдел является предком для Начальника и Сотрудники, а Начальник и Сотрудники – потомки отдела. Между типами записи поддерживаются связи. Никакой потомок не может существовать без своего родителя, причем предок должен быть один.
Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности.
Сетевые модели также создавались для мало ресурсных ЭВМ. Сетевой подход к организации данных является расширением иерархического. В этой модели потомок может иметь любое число предков. Сетевая БД (рис. 10) состоит из набора записей и набора связей между этими записями, а если говорить более точно, из наборов экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка.
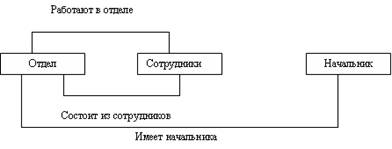
Рис.10. Сетевая модель данных.
При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными. Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей.
Сегодня наиболее распространены реляционные (основанные на двумерных таблицах) модели данных, состоящих из строк (записей) и именованных столбцов (полей):
| Ф.И.О. | Отдел | Должность | № кабинета |  Телефон Телефон
| Имена полей |

| Запись | ||||

| |||||
| Поле |
Каждая таблица описывает некоторый класс объектов выбранной предметной области, например служащих, а каждая строка-запись содержит информацию о конкретном объекте (служащем). Каждый же столбец-поле описывает один из атрибутов данного объекта, например Ф.И.О.
Основными понятиями реляционных баз данных являются:тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего некоторую информацию о сотрудниках некоторой организации (рис. 11):
|







|
|
|
|
|
|
|
|
|





|

|

Рис. 11. Основные понятия реляционных баз данных.
Тип данных. Это понятие в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных и числовых данных, битовых строк, специализированных числовых данных (таких как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и «деньги».
Домен. Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена. Наиболее правильная интуитивная трактовка понятия домена — понимание его как допустимого потенциального множества значений данного типа. Например, домен «Имена» в нашем примере определен на базовом типе строк символов, но в число его значений будут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака). Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов «Номера пропусков» и «Номера групп» относятся к типу целых чисел, но не являются сравнимыми. В большинстве реляционных СУБД понятие домена не используется.
Схема отношения, схема базы данных. Схема отношения — это именованное множество пар имя атрибута, имя домена (или типа, если понятие домена не поддерживается). Степень, или «арность», схемы отношения — мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, т. е. оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, целесообразно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Схема БД (в структурном смысле) — это набор именованных схем отношений.
Кортеж, отношение. Кортеж, соответствующий данной схеме отношения, — это множество пар имя атрибута, значение, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым степень, или «арность», кортежа, т. е. число элементов в нем, совпадает с «арностью» соответствующей схемы отношения. То есть кортеж — это набор именованных значений заданного типа. Отношение — это множество кортежей, соответствующих одной схеме отношения. Практически ориентированное понимание реляционной базы данных: обычным житейским представлением отношения является таблица, заголовок которой — схема отношения, а строки — кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят «столбец таблицы», имея в виду «атрибут отношения». Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД. Реляционная база данных — это набор отношений, имена которых совпадают с именами схем отношений в схеме БД. Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
К числу достоинств реляционного подхода можно отнести:
- наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
- наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
- возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Для привязки даталогической модели к среде хранения используется физическая модель. Она определяет используемые запоминающие устройства, способ расположения элементов данных в памяти, способы физической реализации логических отношений между элементами данных. Модель физического уровня (или внутреннего уровня) строится с учетом ограничений СУБД и операционной системы.
Модель каждого из последующих уровней строится на основе фиксированных характеристик моделей предшествующих уровней (рис.12).
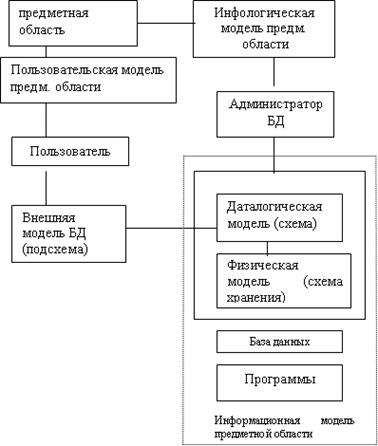
Рис. 12. Отражение предметной области в БД.
Указанные классы моделей имеют разный уровень абстракции. Выделение моделей разных уровней абстракции позволяет:
· разделить сложный процесс отображения «предметная область – база данных» на несколько итеративных более простых отображений;
· обеспечить специализацию разработчиков баз данных; возможность работать разными категориям пользователей с моделью соответствующего уровня;
· предоставить возможность активного и конструктивного участия в разработке баз данных лицам, не имеющим профессиональных навыков в области обработки данных;
· создать предпосылки автоматизации проектирования баз данных путем формализованного перехода с одного уровня моделей на другой.

