




Проектирование информационных систем охватывает три основные области:
- проектирование объектов данных, которые будут реализованы в базе данных;
- проектирование программ, экранных форм, отчетов, которые будут обеспечивать выполнение запросов к данным;
- учет конкретной среды или технологии, а именно: топологии сети, конфигурации аппаратных средств, используемой архитектуры (файл-сервер или клиент-сервер), параллельной обработки, распределенной обработки данных и т.п.
В реальных условиях проектирование — это поиск способа, который удовлетворяет требованиям функциональности системы средствами имеющихся технологий с учетом заданных ограничений.
2. Стратегии конструирования ПО: «водопад» и инкрементная стратегия.
Существуют 3 стратегии конструирования ПО:
однократный проход (водопадная стратегия) — линейная последовательность этапов конструирования;
инкрементная стратегия. В начале процесса определяются все пользовательские и системные требования, оставшаяся часть конструирования выполняется в виде последовательности версий. Первая версия реализует часть запланированных возможностей, следующая версия реализует дополнительные возможности и т. д., пока не будет получена полная система;
эволюционная стратегия. Система также строится в виде последовательности версий, но в начале процесса определены не все требования. Требования уточняются в результате разработки версий.
Характеристики стратегий конструирования
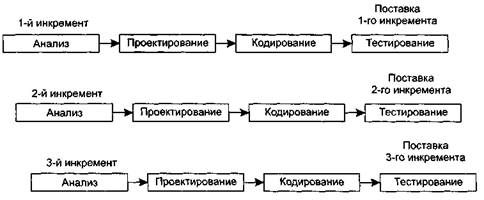
Инкрементная модель
Инкрементная модель является классическим примером инкрементной стратегии конструирования (рис. 1.4). Она объединяет элементы последовательной водопадной модели с итерационной философией макетирования.Каждая линейная последовательность здесь вырабатывает поставляемый инкремент ПО. Например, ПО для обработки слов в 1-м инкременте реализует функции базовой обработки файлов, функции редактирования и документирования; во 2-м инкременте — более сложные возможности редактирования и документирования; в 3-м инкременте — проверку орфографии и грамматики; в 4-м инкременте — возможности компоновки страницы. Первый инкремент приводит к получению базового продукта, реализующего базовые требования (правда, многие вспомогательные требования остаются нереализованными).План следующего инкремента предусматривает модификацию базового продукта, обеспечивающую дополнительные характеристики и функциональность. По своей природе инкрементный процесс итеративен, но, в отличие от макетирования, инкрементная модель обеспечивает на каждом инкременте работающий продукт.
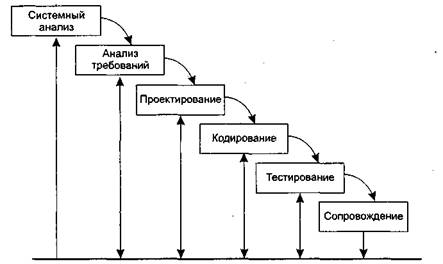
Каскадная модель или «водопад»
1. Стратегии конструирования ПО: эволюционные модели.
Спиральная модель — классический пример применения эволюционной стратегии конструирования.
Спиральная модель (автор Барри Боэм, 1988) базируется на лучших свойствах классического жизненного цикла и макетирования, к которым добавляется новый элемент — анализ риска, отсутствующий в этих парадигмах [19].

Спиральная модель: 1 — начальный сбор требований и планирование проекта; 2 — та же работа, но на основе рекомендаций заказчика; 3 — анализ риска на основе начальных требований; 4 — анализ риска на основе реакции заказчика; 5 — переход к комплексной системе; 6 — начальный макет системы; 7 — следующий уровень макета; 8 — сконструированная система; 9 — оценивание заказчиком
модель определяет четыре действия, представляемые четырьмя квадрантами спирали.
1. Планирование — определение целей, вариантов и ограничений.
2. Анализ риска — анализ вариантов и распознавание/выбор риска.
3. Конструирование — разработка продукта следующего уровня.
4. Оценивание — оценка заказчиком текущих результатов конструирования.
Интегрирующий аспект спиральной модели очевиден при учете радиального измерения спирали. С каждой итерацией по спирали (продвижением от центра к периферии) строятся все более полные версии ПО. В первом витке спирали определяются начальные цели, варианты и ограничения, распознается и анализируется риск. Если анализ риска показывает неопределенность требований, на помощь разработчику и заказчику приходит макетирование (используемое в квадранте конструирования). Для дальнейшего определения проблемных и уточненных требований может быть использовано моделирование. Заказчик оценивает инженерную (конструкторскую) работу и вносит предложения по модификации (квадрант оценки заказчиком). Следующая фаза планирования и анализа риска базируется на предложениях заказчика. В каждом цикле по спирали результаты анализа риска формируются в виде «продолжать, не продолжать». Если риск слишком велик, проект может быть остановлен.
В большинстве случаев движение по спирали продолжается, с каждым шагом продвигая разработчиков к более общей модели системы. В каждом цикле по спирали требуется конструирование (нижний правый квадрант), которое может быть реализовано классическим жизненным циклом или макетированием. Заметим, что количество действий по разработке (происходящих в правом нижнем квадранте) возрастает по мере продвижения от центра спирали.
Достоинства спиральной модели:
1) наиболее реально (в виде эволюции) отображает разработку программного обеспечения;
2) позволяет явно учитывать риск на каждом витке эволюции разработки;
3) включает шаг системного подхода в итерационную структуру разработки;
4) использует моделирование для уменьшения риска и совершенствования программного изделия.
Недостатки спиральной модели:
1) новизна (отсутствует достаточная статистика эффективности модели);
2) повышенные требования к заказчику;
3) трудности контроля и управления временем разработки.
Компонентно-ориентированная модель является развитием спиральной модели и тоже основывается на эволюционной стратегии конструирования. В этой модели конкретизируется содержание квадранта конструирования — оно отражает тот факт, что в современных условиях новая разработка должна основываться на повторном использовании существующих программных компонентов (рис. 1.7).

Компонентно-ориентированная модель
Программные компоненты, созданные в реализованных программных проектах, хранятся в библиотеке. В новом программном проекте, исходя из требований заказчика, выявляются кандидаты в компоненты. Далее проверяется наличие этих кандидатов в библиотеке. Если они найдены, то компоненты извлекаются из библиотеки и используются повторно. В противном случае создаются новые компоненты, они применяются в проекте и включаются в библиотеку.
Достоинства компонентно-ориентированной модели:
1) уменьшает на 30% время разработки программного продукта;
2) уменьшает стоимость программной разработки до 70%;
3) увеличивает в полтора раза производительность разработки.
2. Стратегии конструирования ПО: ХР-процесс
Процесс ориентирован на достаточно небольшие группы (не больше 10 человек). Применяется, когда требования меняются очень часто.
Четырьмя базовыми действиями в процессе являются:
1. Кодирование
2. Тестирование
3. Выслушивание заказчика
4. Проектирование
Базис XP образует следующие 12 методов:
1. Игра планирования – быстрое определение области действия следующей реализации путем объединения деловых приоритетов и технических оценок
2. Частая смена действий – подразумевает быстрый запуск производства простой системы
3. Метафора – вся разработка осуществляется на основе простой общедоступной истории, как работает вся система. Обеспечивает «видение проекта»
4. Простое проектирование – в процессе применяются самые простые решения, которые необходимы только на данном этапе проектирования
5. Тестирование. Осуществляется непрерывно. Прежде запуска проектируют тесты. Функциональное тестирование (черный ящик)
6. Реорганизация – система постоянно реструктурируется, но ее поведение не изменяется
7. Парное программирование. Является одним из наиболее спорных (увеличение расходов на персонал, но увеличение проектирования).
8. Коллективное владение кодом. Любой разработчик может улучшать любую часть кода в любое время.
9. Непрерывная интеграция. Система интегрируется и строится много раз в день по мере решения каждой задачи.
10. 40-часовая рабочая неделя.
11. Локальный заказчик. В группе постоянно должен находиться представитель заказчика.
12. Стандарты кодирования. При разработке должны обеспечиваться правила, обеспечивающие одинаковое представление кода во всех частях системы.
3. Тяжеловесные и облегченные процессы.
Традиционно для упорядочения и ускорения программных разработок предлагались строго упорядочивающие тяжеловесные (heavyweight) процессы. В этих процессах прогнозируется весь объем предстоящих работ, поэтому они называются прогнозирующими (predictive) процессами. Порядок, который должен выполнять при этом человек-разработчик, чрезвычайно строг — «шаг вправо, шаг влево — виртуальный расстрел!». Иными словами, человеческие слабости в расчет не принимаются, а объем необходимой документации способен отнять покой и сон у «совестливого» разработчика.
В последние годы появилась группа новых, облегченных (lightweight) процессов [29]. Теперь их называют подвижными (agile) процессами [8], [25], [36]. Они привлекательны отсутствием бюрократизма, характерного для тяжеловесных (прогнозирующих) процессов. Новые процессы должны воплотить в жизнь разумный компромисс между слишком строгой дисциплиной и полным ее отсутствием. Иначе говоря, порядка в них достаточно для того, чтобы получить разумную отдачу от разработчиков.
Подвижные процессы требуют меньшего объема документации и ориентированы на человека. В них явно указано на необходимость использования природных качеств человеческой натуры (а не на применение действий, направленных наперекор этим качествам).
Более того, подвижные процессы учитывают особенности современного заказчика, а именно частые изменения его требований к программному продукту. Известно, что для прогнозирующих процессов частые изменения требований подобны смерти. В отличие от них, подвижные процессы адаптируют изменения требований и даже выигрывают от этого. Словом, подвижные процессы имеют адаптивную природу.
Таким образом, в современной инфраструктуре программной инженерии существуют два семейства процессов разработки:
ü семейство прогнозирующих (тяжеловесных) процессов;
ü семейство адаптивных (подвижных, облегченных) процессов.
У каждого семейства есть свои достоинства, недостатки и область применения:
ü адаптивный процесс используют при частых изменениях требований, малочисленной группе высококвалифицированных разработчиков и грамотном заказчике, который согласен участвовать в разработке;
ü прогнозирующий процесс применяют при фиксированных требованиях и многочисленной группе разработчиков разной квалификации.
4. Модели качества процесса проектирования.
Базовым является модель зрелости процесса конструирования. Базовым понятием модели (СММ) является зрелость компании. Модель фиксирует критерий для оценки зрелости компании и предлагает рецепты для улучшения существующих в ней процессов.
В модели зафиксированы 5 уровней зрелости:
1. начальный уровень –означает, что процесс в компании не формализован, он не может строго планироваться и отслеживаться. Результат работы зависит от личных качеств отдельных сотрудников. Для перехода на 2-й уровень необходимо внедрить формальные процедуры, для выполнения основных элементов процесса конструирования.
2. повторяемый уровень;
3. определённый уровень – требует, чтобы все элементы процесса были определены, стандартизованы и за документированы;
4. управляемый уровень – наступает, когда в компании принимаются количественные показатели качества, как программных продуктов, так и процесса;
5. оптимизирующий уровень – подразумевает, что главной задачей компании становится улучшение существующих процессов и ввод новых технологий.
5. Управление риском.
Формула управления риском RE = P (UO) * L (UO), где
RE – показатель риска;
P – вероятность неудовлетворительного результата;
L – потеря при неудовлетворительном результате;
UO – Unsatisfactory Outcome.
Управление риском включает 6 действий:
1. идентификация риска – выявление элементов риска на проект;
2. анализ риска – включает в себя оценку вероятности и величины потери по каждому элементу риска.
3. ранжирование риска – упорядочивание элементов риска по степени их влияния;
4. планирование управления риском – подготовка к работе с каждым элементом риска;
5. разрешение риска;
6. наблюдение риска.
Идентификация риска
Выделяют 3 категории источников риска, а именно: проектный риск, технический риск, коммерческий риск.
Источниками проектного риска являются:
1. выбор бюджета, плана, человеческих ресурсов;
2. формирование требований к программному продукту;
3. сложность, размер и структура программного продукта;
4. методика взаимодействия с заказчиком.
К источникам технического риска относят:
1. трудности проектирования, реализации, формирование интерфейса, тестирование и сопровождение;
2. неточность спецификаций;
3. техническая неопределённость или отсталость технического решения.
Источники коммерческого риска:
1. создание продукта, не требующееся на рынке;
2. создание продукта, опережающего требования рынка;
3. потеря финансирования.
Планирование управления риском
Цель планирования – сформировать набор функций управления к каждому элементу риска.
Обычно выбирают 3 эталонных уровня риска:
1. превышение стоимости;
2. срыв планирования;
3. упадок производительности.
Шаги планирования:
1. исходными данными для планирования является набор четвёрок {Ri, Pi, Li, REi};
2. определяются эталонные уровни рисков в проекте;
3. разрабатываются зависимости между каждой четвёркой и каждым эталонным уровнем;
4. формируется набор эталонных точек, образующих сферу остановок;
5. для каждого элемента риска разрабатывается план управления. Предложения плана разрабатывается в виде ответов на вопросы: зачем, что, когда, какие, как и сколько.
6. Структурный анализ: основные определения, ПДД
Структурный анализ — один из формализованных методов анализа требований к ПО. Автор этого метода — Том Де Марко (1979). В этом методе программное изделие рассматривается как преобразователь информационного потока данных. Основной элемент структурного анализа — диаграмма потоков данных.
Диаграммы потоков данных – графическое средство для изображения информационного потока и преобразований, которым подвергаются данные при движении от входа к выходу системы.
Основные элементы:


Для полного описания требований к программному изделию должны быть описаны стрелки (потоки данных) и преобразователи (процессы). Для чего используется словарь требований данных и спецификации процессов.
Словарь требований содержит описание потоков данных и хранилищ данных. Большинство словарей содержат следующую информацию:
1. Имя – основное имя элемента данных, хранилища или внешнего объекта.
2. Алиас (прозвище) – другие имена того же объекта
3. Где и как используется объект, т.е. список процессов, который использует данный элемент, с указанием способа использования.
4. Описание содержания.
5. Дополнительная информация.
6. Спецификация процесса – описание преобразователя, она поясняет ввод данных в преобразователь, алгоритм обработки, характеристики производительности преобразователя и формируемые результаты.

В структурный анализ были введены диаграммы управляющих потоков. Они включают в себя:
1. обычные преобразователи;
2. потоки управления и потоки событий.
Вместо управляющих преобразователей используются указатели, ссылки на управляющую спецификацию.

Управляющая спецификация управляет преобразователями в ПДД на основе события, которое проходит в её окно по ссылке.

7. Классические методы проектирования: проектирование для потока данных типа «преобразование»
Исходными данными для метода являются компоненты модели анализа, которые представляются иерархией диаграмм потоков данных. Результат структурного проектирования – иерархическая структура программной системы. Действия структурного проектирования зависят от типа информационного потока в модели анализа. Различают 2 типа информационных потоков: поток преобразований и поток запросов.
Проектирование для потока данных типа «преобразований».
1. проверка основной системы модели. Модель включает в себя: контекстную диаграмму ПДДО словарь данных и спецификацию процессов. Оценивается их согласованность с их спецификацией.
2. проверка уточнения диаграмм потоков данных 1 и 2 уровней. Оценивается согласованность диаграмм и достаточность реализации преобразователей.
3. определение типа основного потока диаграмм потоков данных.
4. определение границ входящего и выходящего потоков, определение центра преобразований.
5. определение начальной структуры системы: иерархическая структура формируется нисходящим распространением управления. В такой структуре модули верхнего уровня принимают решение, модули нижнего уровня выполняют работу по вводу, выводу и обработке. Модули среднего уровня реализуются как функции управления, так и функции обработки.
6. Детализация структуры программируемой системы. Выполняется отображение преобразователей диаграмм потока данных в модули структуры ПС. Отображения выполняются движением по ПДД от границ центра преобразования вдоль входящего и выходящего потоков. Входящий поток проходится от конца к началу, а выходящий от начала к концу.
Для отображения центра преобразований каждый преобразователь отображается в модель, непосредственно подчиненный контроллеру центра. Проходится преобразуемый поток слева направо. Для каждого модуля полученной структуры на базе спецификации процессов модели анализа пишутся сокращенные описания обработки.
7. Уточнение иерархической структуры ПС. Модули разделяются и объединяются для:
- повышения связности и уменьшения сцепления
- упрощения реализации
- упрощения тестирования
- повышения удобства сопровождения
8. Классические методы проектирования: проектирование для потока данных типа «запрос»
1. Проверка основной системы модели. Модель включает в себя: контекстную диаграмму ПДДО словарь данных и спецификацию процессов. Оценивается их согласованность с их спецификацией.
2. проверка уточнения диаграмм потоков запросов 1 и 2 уровней. Оценивается согласованность диаграмм и достаточность реализации преобразователей.
3. определение типа основного потока диаграмм потоков запросов. Основной признак потока запросов явное переключение данных на один из путей действий.
4. определение центра запросов и типа для каждого потока действий. Если конкретный поток действий имеет тип преобразование, то для него указываются границы входящего, преобразуемого и выходящего потоков.
5. Определение начальной структуры ПС. В начальную структуру отображается та часть ПДД, в которой распространяется поток запросов. Начальная структура ПС для потока запросов стандарта и включает входящую ветвь и диспетчерскую ветвь. Структура входящей ветви формируется также, как в предыдущей методике. Диспетчерская ветвь включает диспетчер, находится на вершине ветви и контроллер потоков действий подчинены диспетчеру.
6. Детализация структуры ПС – производится отображение в структуру каждого потока действий.
7. Уточнение иерархической структуры (см. предыдущую методику)
9. Характеристики сложности иерархической структуры ПС.
Иерархическая структура программной системы — основной результат предварительного проектирования. Она определяет состав модулей ПС и управляющие отношения между модулями. В этой структуре модуль более высокого уровня (начальник) управляет модулем нижнего уровня (подчиненным).
Иерархическая структура не отражает процедурные особенности программной системы, то есть последовательность операций, их повторение, ветвления и т. д. Рассмотрим основные характеристики иерархической структуры, представленной на рис. 4.17.

Иерархическая структура программной системы
Первичными характеристиками являются количество вершин (модулей) и количество ребер (связей между модулями). К ним добавляются две глобальные характеристики — высота и ширина:
ü высота — количество уровней управления;
ü ширина — максимальное из количеств модулей, размещенных на уровнях управления.
В нашем примере высота = 4, ширина = 6.
Локальными характеристиками модулей структуры являются коэффициент объединения по входу и коэффициент разветвления по выходу.
Коэффициент объединения по входу Fan_in(i) — это количество модулей, которые прямо управляют i -м модулем.
В примере для модуля n: Fan_in(n)=4.
Коэффициент разветвления по выходу Fan_out(i) — это количество модулей, которыми прямо управляет i -й модуль.
В примере для модуля m: Fan_out(m)=3.
Возникает вопрос: как оценить качество структуры? Из практики проектирования известно, что лучшее решение обеспечивается иерархической структурой в виде дерева.
Степень отличия реальной проектной структуры от дерева характеризуется невязкой структуры. Как определить невязку?
Вспомним, что полный граф (complete graph) с п вершинами имеет количество ребер
ес = n (n -1)/2,
а дерево (tree) с таким же количеством вершин — существенно меньшее количество ребер
et=n- l.
Тогда формулу невязки можно построить, сравнивая количество ребер полного графа, реального графа и дерева.
Для проектной структуры с п вершинами и е ребрами невязка определяется по выражению
 .
.
Значение невязки лежит в диапазоне от 0 до 1. Если Nev = 0, то проектная структура является деревом, если Nev = 1, то проектная структура — полный граф.
Ясно, что невязка дает грубую оценку структуры. Для увеличения точности оценки следует применить характеристики связности и сцепления.
Хорошая структура должна иметь низкое сцепление и высокую связность.
Л. Констентайн и Э. Йордан (1979) предложили оценивать структуру с помощью коэффициентов Fan_in(i) и Fan_out(i) модулей [77].
Большое значение Fan_in(i) — свидетельство высокого сцепления, так как является мерой зависимости модуля. Большое значение Fan_out(i) говорит о высокой сложности вызывающего модуля. Причиной является то, что для координации подчиненных модулей требуется сложная логика управления.
Основной недостаток коэффициентов Fan_in(i) и Fan_out(i) состоит в игнорировании веса связи. Здесь рассматриваются только управляющие потоки (вызовы модулей). В то же время информационные потоки, нагружающие ребра структуры, могут существенно изменяться, поэтому нужна мера, которая учитывает не только количество ребер, но и количество информации, проходящей через них.
С. Генри и Д. Кафура (1981) ввели информационные коэффициенты ifan_in(i) и ifan_out(j) [35]. Они учитывают количество элементов и структур данных, из которых i -й модуль берет информацию и которые обновляются j -м модулем соответственно.
Информационные коэффициенты суммируются со структурными коэффициентами sfan_in(i) и sfan_out(j),которые учитывают только вызовы модулей.
В результате формируются полные значения коэффициентов:
Fan_in (i) = sfan_in (i) + ifan_in (i),
Fan_out (j) = sfan_out (j) + ifan_out (j).
На основе полных коэффициентов модулей вычисляется метрика общей сложности структуры:
S =  length(i) x (Fan_in(i) + Fan_out(i))2,
length(i) x (Fan_in(i) + Fan_out(i))2,
где length(i) — оценка размера i -го модуля (в виде LOC- или FP-оценки).
10. Структурный подход: связность модуля.
Связность модуля (Cohesion) — это мера зависимости его частей [58], [70], [77]. Связность — внутренняя характеристика модуля. Чем выше связность модуля, тем лучше результат проектирования, то есть тем «черней» его ящик (капсула, защитная оболочка модуля), тем меньше «ручек управления» на нем находится и тем проще эти «ручки».
Для измерения связности используют понятие силы связности (СС). Существует 7 типов связности:
1. Связность по совпадению(СС=0). В модуле отсутствуют явно выраженные внутренние связи.
2. Логическая связность(СС=1). Части модуля объединены по принципу функционального подобия. Например, модуль состоит из разных подпрограмм обработки ошибок. При использовании такого модуля клиент выбирает только одну из подпрограмм.
Недостатки:
ü сложное сопряжение;
ü большая вероятность внесения ошибок при изменении сопряжения ради одной из функций.
3. Временная связность(СС=3). Части модуля не связаны, но необходимы в один и тот же период работы системы.
Недостаток: сильная взаимная связь с другими модулями, отсюда — сильная чувствительность внесению изменений.
4.Процедурная связность (СС=5). Части модуля связаны порядком выполняемых ими действий, реализующих некоторый сценарий поведения.
5.Коммуникативная связность (СС=7). Части модуля связаны по данным (работают с одной и той же структурой данных).
6.Информационная (последовательная) связность (СС=9). Выходные данные одной части используются как входные данные в другой части модуля.
7.Функциональная связность (СС=10). Части модуля вместе реализуют одну функцию.
Отметим, что типы связности 1,2,3 — результат неправильного планирования архитектуры, а тип связности 4 — результат небрежного планирования архитектуры приложения.
Общая характеристика типов связности представлена в табл. 4.1.
Характеристика связности модуля
| Тип связности | Сопровождаемость | Роль модуля |
| Функциональная | «Черный ящик» | |
| Информационная (последовательная) | Лучшая сопровождаемость | Не совсем «черный ящик» |
| Кэммуникативная | «Серый ящик» | |
| Процедурная | «Белый» или «просвечивающий ящик» | |
| Временная | Худшая сопровождаемость | |
| Логическая | «Белый ящик» | |
| По совпадению |
11. Структурный подход: сцепление модулей.
Сцепление (Coupling) — мера взаимозависимости модулей поданным [58], [70], [77]. Сцепление — внешняя характеристика модуля, которую желательно уменьшать.
Количественно сцепление измеряется степенью сцепления (СЦ). Выделяют 6 типов сцепления.
1.Сцепление по данным(СЦ=1). Модуль А вызывает модуль В. Все входные и выходные параметры вызываемого модуля — простые элементы данных (рис. 4.13).

Сцепление поданным
2. Сцепление по образцу(СЦ=3). В качестве параметров используются структуры данных (рис. 4.14).

Сцепление по образцу
3.Сцепление по управлению(СЦ=4). Модуль А явно управляет функционированием модуля В (с помощью флагов или переключателей), посылая ему управляющие данные (рис. 4.15).

Сцепление по управлению
4. Сцепление по внешним ссылкам(СЦ=5). Модули А и В ссылаются на один и тот же глобальный элемент данных.
5. Сцепление по общей области(СЦ=7). Модули разделяют одну и ту же глобальную структуру данных (рис. 4.16).
6. Сцепление по содержанию(СЦ=9). Один модуль прямо ссылается на содержание другого модуля (не через его точку входа). Например, коды их команд перемежаются друг с другом (рис. 4.16).
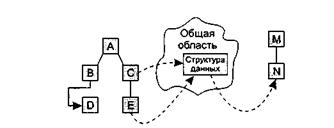
Сцепление по общей области и содержанию На рис. видим, что модули В и D сцеплены по содержанию, а модули С, Е и N сцеплены по общей области.
12. Основные понятия и методы структурного тестирования ПО.
Тестирование — процесс выполнения программы с целью обнаружения ошибок. Шаги процесса задаются тестами.
Каждый тест определяет:
ü свой набор исходных данных и условий для запуска программы;
ü набор ожидаемых результатов работы программы.
Другое название теста — тестовый вариант. Полную проверку программы гарантирует исчерпывающее тестирование. Оно требует проверить все наборы исходных данных, все варианты их обработки и включает большое количество тестовых вариантов. Увы, но исчерпывающее тестирование во многих случаях остается только мечтой — срабатывают ресурсные ограничения (прежде всего, ограничения по времени).
Хорошим считают тестовый вариант с высокой вероятностью обнаружения еще не раскрытой ошибки. Успешным называют тест, который обнаруживает до сих пор не раскрытую ошибку.
Целью проектирования тестовых вариантов является систематическое обнаружение различных классов ошибок при минимальных затратах времени и стоимости.
Тестирование обеспечивает:
ü обнаружение ошибок;
ü демонстрацию соответствия функций программы ее назначению;
ü демонстрацию реализации требований к характеристикам программы;
ü отображение надежности как индикатора качества программы.
А чего не может тестирование? Тестирование не может показать отсутствия дефектов (оно может показывать только присутствие дефектов). Важно помнить это (скорее печальное) утверждение при проведении тестирования.
Рассмотрим информационные потоки процесса тестирования. Они показаны на рис. 6.1.

Информационные потоки процесса тестирования
На входе процесса тестирования три потока:
ü текст программы;
ü исходные данные для запуска программы;
ü ожидаемые результаты.
Выполняются тесты, все полученные результаты оцениваются. Это значит, что реальные результаты тестов сравниваются с ожидаемыми результатами. Когда обнаруживается несовпадение, фиксируется ошибка — начинается отладка. Процесс отладки непредсказуем по времени. На поиск места дефекта и исправление может потребоваться час, день, месяц. Неопределенность в отладке приводит к большим трудностям в планировании действий.
После сбора и оценивания результатов тестирования начинается отображение качества и надежности ПО. Если регулярно встречаются серьезные ошибки, требующие проектных изменений, то качество и надежность ПО подозрительны, констатируется необходимость усиления тестирования. С другой стороны, если функции ПО реализованы правильно, а обнаруженные ошибки легко исправляются, может быть сделан один из двух выводов:
ü качество и надежность ПО удовлетворительны;
ü тесты не способны обнаруживать серьезные ошибки.
В конечном счете, если тесты не обнаруживают ошибок, появляется сомнение в том, что тестовые варианты достаточно продуманы и что в ПО нет скрытых ошибок. Такие ошибки будут, в конечном итоге, обнаруживаться пользователями и корректироваться разработчиком на этапе сопровождения (когда стоимость исправления возрастает в 60-100 раз по сравнению с этапом разработки).
Результаты, накопленные в ходе тестирования, могут оцениваться и более формальным способом. Для этого используют модели надежности ПО, выполняющие прогноз надежности по реальным данным об интенсивности ошибок.
Существуют 2 принципа тестирования программы:
ü функциональное тестирование (тестирование «черного ящика»);
ü структурное тестирование (тестирование «белого ящика»).
Тестирование «черного ящика»
Известны:функции программы.
Исследуется:работа каждой функции на всей области определения.
основное место приложения тестов «черного ящика» — интерфейс ПО.

Тестирование «черного ящика»
Эти тесты демонстрируют:
ü как выполняются функции программ;
ü как принимаются исходные данные;
ü как вырабатываются результаты;
ü как сохраняется целостность внешней информации.
При тестировании «черного ящика» рассматриваются системные характеристики программ, игнорируется их внутренняя логическая структура. Исчерпывающее тестирование, как правило, невозможно. Например, если в программе 10 входных величин и каждая принимает по 10 значений, то потребуется 1010 тестовых вариантов. Отметим также, что тестирование «черного ящика» не реагирует на многие особенности программных ошибок.
Тестирование «белого ящика»
Известна: внутренняя структура программы.
Исследуются:внутренние элементы программы и связи между ними

Тестирование «белого ящика»
Объектом тестирования здесь является не внешнее, а внутреннее поведение программы. Проверяется корректность построения всех элементов программы и правильность их взаимодействия друг с другом. Обычно анализируются управляющие связи элементов, реже — информационные связи. Тестирование по принципу «белого ящика» характеризуется степенью, в какой тесты выполняют или покрывают логику (исходный текст) программы. Исчерпывающее тестирование также затруднительно. Особенности этого принципа тестирования рассмотрим отдельно.
13. Способ тестирования базового пути
Тестирование базового пути — это способ, который основан на принципе «белого ящика». Автор этого способа — Том МакКейб (1976) [49].
Способ тестирования базового пути дает возможность:
ü получить оценку комплексной сложности программы;
ü использовать эту оценку для определения необходимого количества тестовых вариантов.
Тестовые варианты разрабатываются для проверки базового множества путей (маршрутов) в программе. Они гарантируют однократное выполнение каждого оператора программы при тестировании.
Для представления программы используется потоковый граф. Перечислим его особенности.
1. Граф строится отображением управляющей структуры программы. В ходе отображения закрывающие скобки условных операторов и операторов циклов (end if; end loop) рассматриваются как отдельные (фиктивные) операторы.
2. Узлы (вершины) потокового графа соответствуют линейным участкам программы, включают один или несколько операторов программы.
3. Дуги потокового графа отображают поток управления в программе (передачи управления между операторами). Дуга — это ориентированное ребро.
4. Различают операторные и предикатные узлы. Из операторного узла выходит одна дуга, а из предикатного — две дуги.
5. Предикатные узлы соответствуют простым условиям в программе. Составное условие программы отображается в несколько предикатных узлов. Составным называют условие, в котором используется одна или несколько булевых операций (OR, AND).
6. Замкнутые области, образованные дугами и узлами, называют регионами.
7. Окружающая граф среда рассматривается как дополнительный регион.
Цикломатическая сложность — метрика ПО, которая обеспечивает количественную оценку логической сложности программы. В способе тестирования базового пути Цикломатическая сложность определяет:
- количество независимых путей в базовом множестве программы;
- верхнюю оценку количества тестов, которое гарантирует однократное выполнение всех операторов.
Цикломатическая сложность вычисляется одним из трех способов:
1) цикломатическая сложность равна количеству регионов потокового графа;
2) цикломатическая сложность определяется по формуле
V(G)-E-N+2,
где Е — количество дуг, N — количество узлов потокового графа;
3) цикломатическая сложность формируется по выражению V(G) =p+ 1, где р — количество предикатных узлов в потоковом графе G.
Пример 1.Рассмотрим процедуру сжатия:
процедура сжатие
1 выполнять пока нет EOF
1 читать запись;
2 если запись пуста
3 то удалить запись:
4 иначе если поле а >= поля b
5 то удалить b;
6иначе удалить а;
7а конец если;
7а конец если;
7b конец выполнять;
8 конец сжатие;

Преобразованный потоковый граф процедуры сжатия
Она отображается в потоковый граф. Видим, что этот потоковый граф имеет четыре региона.
Путь 1: 1-8.
Путь 2: 1-2-3-7а-7b-1-8.
Путь 3: 1-2-4-5-7а-7b-1-8.
Путь 4: 1-2-4-6-7а-7b-1-8.
Заметим, что каждый новый путь включает новую дугу.
Все независимые пути графа образуют базовое множество.
14. Способы тестирования условий.
Цель — строить тестовые варианты для проверки логических условий программы. При этом желательно обеспечить охват операторов из всех ветвей программы.
Простое условие — булева переменная или выражение отношения.
Выражение отношения имеет вид
Е1 <оператор отношения> E2,
где El, Е2 — арифметические выражения, а в качестве оператора отношения используется один из следующих операторов: <, >, =,  ,
, 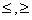 .
.
Составное условие состоит из нескольких простых условий, булевых операторов и круглых скобок. Будем применять булевы операторы OR, AND (&), NOT. Условия, не содержащие выражений отношения, называют булевыми выражениями.
Таким образом, элементами условия являются: булев оператор, булева переменная, пара скобок (заключающая простое или составное условие), оператор отношения, арифметическое выражение. Эти элементы определяют типы ошибок в условиях.
Если условие некорректно, то некорректен по меньшей мере один из элементов условия. Следовательно, в условии возможны следующие типы ошибок:
ü ошибка булева оператора (наличие некорректных / отсутствующих / избыточных булевых операторов);
ü ошибка булевой переменной;
ü ошибка булевой скобки;
ü ошибка оператора отношения;
ü ошибка арифметического выражения.
Способ тестирования условий ориентирован на тестирование каждого условия в программе. Методики тестирования условий имеют два достоинства. Во-первых, достаточно просто выполнить измерение тестового покрытия условия. Во-вторых, тестовое покрытие условий в программе — это фундамент для генерации дополнительных тестов программы.
Целью тестирования условий является определение не только ошибок в условиях, но и других ошибок в программах. Если набор тестов для программы А эффективен для обнаружения ошибок в условиях, содержащихся в А, то вероятно, что этот набор также эффективен для обнаружения других ошибок в А. Кроме того, если методика тестирования эффективна для обнаружения ошибок в условии, то вероятно, что эта методика будет эффективна для обнаружения ошибок в программе.
Существует несколько методик тестирования условий.
Простейшая методика — тестирование ветвей. Здесь для составного условия С проверяется:
ü каждое простое условие (входящее в него);
ü Тruе-ветвь;
ü False-ветвь.
Другая методика — тестирование области определения. В ней для выражения отношения требуется генерация 3-4 тестов. Выражение вида
Е1 <оператор отношения> Е2
проверяется тремя тестами, которые формируют значение Е1 большим, чем Е2, равным Е2 и меньшим, чем Е2.
Если оператор отношения неправилен, а Е1 и Е2 корректны, то эти три теста гарантируют обнаружение ошибки оператора отношения.
Для определения ошибок в Е1 и Е2 тест должен сформировать значение Е1 большим или меньшим, чем Е2, причем обеспечить как можно меньшую разницу между этими значениями.
Для булевых выражений с п переменными требуется набор из 2 n тестов. Этот набор позволяет обнаружить ошибки булевых операторов, переменных и скобок, но практичен только при малом п..
15. Способ тестирования потоков данных
В предыдущих способах тесты строились на основе анализа управляющей структуры программы. В данном способе анализу подвергается информационная структура программы.
Работу любой программы можно рассматривать как обработку потока данных, передаваемых от входа в программу к ее выходу.
Рассмотрим пример.
Пусть потоковый граф программы имеет вид, представленный на рис. 6.8. В нем сплошные дуги — это связи по управлению между операторами в программе. Пунктирные дуги отмечают информационные связи (связи по потокам данных). Обозначенные здесь информационные связи соответствуют следующим допущениям:
ü в вершине 1 определяются значения переменных а, b;
ü значение переменной а используется в вершине 4;
ü значение переменной b используется в вершинах 3, 6;
ü в вершине 4 определяется значение переменной с, которая используется в вершине 6.

Граф программы с управляющими и информационными связями
В общем случае для каждой вершины графа можно записать:
ü множество определений данных
DEF(i) = { х | i -я вершина содержит определение х};
ü множество использований данных:
USE (i) = { х | i -я вершина использует х}.
Под определением данных понимают действия, изменяющие элемент данных. Признак определения — имя элемента стоит в левой части оператора присваивания:
x:= f (…).
Использование данных — это применение элемента в выражении, где происходит обращение к элементу данных, но не изменение элемента. Признак использования — имя элемента стоит в правой части оператора присваивания:
#:= f (x).
Здесь место подстановки другого имени отмечено прямоугольником (прямоугольник играет роль метки-заполнителя).
Назовём DU-цепочкой (цепочкой определения-использования) конструкцию [х, i,j], где i,j — имена вершин; х определена в i -й вершине (х  DЕF(i)) и используется в j -й вершине (х USE(j)).
DЕF(i)) и используется в j -й вершине (х USE(j)).
В нашем примере существуют следующие DU-цепочки:
[а,1,4],[b, 1,3], [b, 1,6], [с, 4, 6].
Способ DU-тестирования требует охвата всех DU-цепочек программы. Таким образом, разработка тестов здесь проводится на основе анализа жизни всех данных программы.
Очевидно, что для подготовки тестов требуется выделение маршрутов — путей выполнения программы на управляющем графе. Критерий для выбора пути — покрытие максимального количества DU-цепочек.
Шаги способа DU-тестирования:
1) построение управляющего графа (УГ) программы;
2) построение информационного графа (ИГ);
3) формирование полного набора DU-цепочек;
4) формирование полного набора отрезков путей в управляющем графе (отображением набора DU-цепочек информационного графа, рис. 6.9);

Отображение DU-цепочки в отрезок пути
5) построение маршрутов — полных путей на управляющем графе, покрывающих набор отрезков путей управляющего графа;
6) подготовка тестовых вариантов.
Достоинства DU-тестирования:
ü простота необходимого анализа операционно-управляющей структуры программы;
ü простота автоматизации.
Недостаток DU-тестирования: трудности в выборе минимального количества максимально эффективных тестов.
Область использования DU-тестирования: программы с вложенными условными операторами и операторами цикла.
16. Функциональное тестирование: способ разбиения по эквивалентности, анализ граничных условий.
Способ разбиения по эквивалентности
Разбиение по эквивалентности — самый популярный способ тестирования «черного ящика» [3], [14].
В этом способе входная область данных программы делится на классы эквивалентности. Для каждого класса эквивалентности разрабатывается один тестовый вариант.
Класс эквивалентности — набор данных с общими свойствами. Обрабатывая разные элементы класса, программа должна вести себя одинаково. Иначе говоря, при обработке любого набора из класса эквивалентности в программе задействуется один и тот же набор операторов (и связей между ними).
каждый класс эквивалентности показан эллипсом. Здесь выделены входные классы эквивалентности допустимых и недопустимых исходных данных, а также классы результатов.
Классы эквивалентности могут быть определены по спецификации на программу.

Разбиение по эквивалентности
Например, если спецификация задает в качестве допустимых входных величин 5-разрядные целые числа в диапазоне 15 000...70 000, то класс эквивалентности допустимых ИД (исходных данных) включает величины от 15 000 до 70 000, а два класса эквивалентности недопустимых ИД составляют:
ü числа меньшие, чем 15 000;
ü числа большие, чем 70 000.
Класс эквивалентности включает множество значений данных, допустимых или недопустимых по условиям ввода.
Условие ввода может задавать:
1) определенное значение;
2) диапазон значений;
3) множество конкретных величин;
4) булево условие.
Сформулируем правила формирования классов эквивалентности.
1. Если условие ввода задает диапазон п...т, то определяются один допустимый и два недопустимых класса эквивалентности:
ü V_Class={ n.. .т } — допустимый класс эквивалентности;
ü Inv_С1аss1={ x |для любого х: х < п } — первый недопустимый класс эквивалентности;
ü Inv_С1аss2={ y |для любого у: у > т } — второй недопустимый класс эквивалентности.
2. Если условие ввода задает конкретное значение а, то определяется один допустимый и два недопустимых класса эквивалентности:
ü V_Class={ a };
ü Inv_Class1 ={х |длялюбого х: х < а };
ü Inv_С1аss2={ y |для любого у: у > а }.
3.Если условие ввода задает множество значений {а, b, с}, то определяются один допустимый и один недопустимый класс эквивалентности:
ü V_Class={ a, b, с };
ü Inv_С1аss={ x |для любого х: (х а)&(х b)&(х с)}.
4. Если условие ввода задает булево значение, например true, то определяются один допустимый и один недопустимый класс эквивалентности:
ü V_Class={true};
ü Inv_Class={false}.
После построения классов эквивалентности разрабатываются тестовые варианты. Тестовый вариант выбирается так, чтобы проверить сразу наибольшее количество свойств класса эквивалентности.
Способ анализа граничных значений
Как правило, большая часть ошибок происходит на границах области ввода, а не в центре. Анализ граничных значений заключается в получении тестовых вариантов, которые анализируют граничные значения [3], [14], [69]. Данный способ тестирования дополняет способ разбиения по эквивалентности.
Основные отличия анализа граничных значений от разбиения по эквивалентности:
1) тестовые варианты создаются для проверки только ребер классов эквивалентности;
2) при создании тестовых вариантов учитывают не только условия ввода, но и область вывода.
Сформулируем правила анализа граничных значений.
1. Если условие ввода задает диапазон п...т, тотестовые варианты должны быть построены:
ü для значений п и т;
ü для значений чуть левее п ичуть правее т на числовой оси.
Например, если задан входной диапазон -1,0...+1,0, то создаются тесты для значений - 1,0, +1,0, - 1,001, +1,001.
2. Если условие ввода задает дискретное множество значений, то создаются тестовые варианты:
ü для проверки минимального и максимального из значений;
ü для значений чуть меньше минимума и чуть больше максимума.
Так, если входной файл может содержать от 1 до 255 записей, то создаются тесты для О, 1, 255, 256 записей.
3. Правила 1 и 2 применяются к условиям области вывода.
Рассмотрим пример, когда в программе требуется выводить таблицу значений. Количество строк и столбцов в таблице меняется. Задается тестовый вариант для минимального вывода (по объему таблицы), а также тестовый вариант для максимального вывода (по объему таблицы).
4. Если внутренние структуры данных программы имеют предписанные границы, то разрабатываются тестовые варианты, проверяющие эти структуры на их границах.
5. Если входные или выходные данные программы являются упорядоченными множествами (например, последовательным файлом, линейным списком, таблицей), то надо тестировать обработку первого и последнего элементов этих множеств.
Большинство разработчиков используют этот способ интуитивно. При применении описанных правил тестирование границ будет более полным, в связи с чем возрастет вероятность обнаружения ошибок.
Рассмотрим применение способов разбиения по эквивалентности и анализа граничных значений на конкретном примере. Положим, что нужно протестировать программу бинарного поиска. Нам известна спецификация этой программы. Поиск выполняется в массиве элементов М, возвращается индекс I элемента массива, значение которого соответствует ключу поиска Key.
Предусловия:
1) массив должен быть упорядочен;
2) массив должен иметь не менее одного элемента;
3) нижняя граница массива (индекс) должна быть меньше или равна его верхней границе.
Постусловия:
1) если элемент найден, то флаг Result=True, значение I — номер элемента;
2) если элемент не найден, то флаг Result=False, значение I не определено.
Для формирования классов эквивалентности (и их ребер) надо произвести разбиение области ИД — построить дерево разбиений. Листья дерева разбиений дадут нам искомые классы эквивалентности. Определим стратегию разбиения. На первом уровне будем анализировать выполнимость предусловий, на втором уровне — выполнимость постусловий. На третьем уровне можно анализировать специальные требования, полученные из практики разработчика. В нашем примере мы знаем, что входной массив должен быть упорядочен. Обработка упорядоченных наборов из четного и нечетного количества элементов может выполняться по-разному. Кроме того, принято выделять специальный случай одноэлементного массива. Следовательно, на уровне специальных требований возможны следующие эквивалентные разбиения:
1) массив из одного элемента;
2) массив из четного количества элементов;
3) массив из нечетного количества элементов, большего единицы.
Наконец на последнем, 4-м уровне критерием разбиения может быть анализ ребер классов эквивалентности. Очевидно, возможны следующие варианты:
1) работа с первым элементом массива;
2) работа с последним элементом массива;
3) работа с промежуточным (ни с первым, ни с последним) элементом массива.
Структура дерева разбиений приведена

Дерево разбиений области исходных данных бинарного поиска
Это дерево имеет 11 листьев. Каждый лист задает отдельный тестовый вариант. Покажем тестовые варианты, основанные на проведенных разбиениях.
Тестовый вариант 1 (единичный массив, элемент найден) ТВ1:
ИД: М=15; Кеу=15.
ОЖ.РЕЗ.: Resutt=True; I=1.
Тестовый вариант 2 (четный массив, найден 1-й элемент) ТВ2:
ИД: М=15, 20, 25,30,35,40; Кеу=15.
ОЖ.РЕЗ.: Result=True; I=1.
Тестовый вариант 3 (четный массив, найден последний элемент) ТВЗ:
ИД: М=15, 20, 25, 30, 35, 40; Кеу=40.
ОЖ.РЕЗ:. Result=True; I=6.
Тестовый вариант 4 (четный массив, найден промежуточный элемент) ТВ4:
ИД: М=15,20,25,30,35,40; Кеу=25.
ОЖ.РЕЗ.: Result-True; I=3.
Тестовый вариант 5 (нечетный массив, найден 1-й элемент) ТВ5:
ИД: М=15, 20, 25, 30, 35,40, 45; Кеу=15.
ОЖ.РЕЗ.: Result=True; I=1.
Тестовый вариант 6 (нечетный массив, найден последний элемент) ТВ6:
ИД: М=15, 20, 25, 30,35, 40,45; Кеу=45.
ОЖ.РЕЗ.: Result=True; I=7.
Тестовый вариант 7 (нечетный массив, найден промежуточный элемент) ТВ7:
ИД: М=15, 20, 25, 30,35, 40, 45; Кеу=30.
ОЖ.РЕЗ.: Result=True; I=4.
Тестовый вариант 8 (четный массив, не найден элемент) ТВ8:
ИД: М=15, 20, 25, 30, 35,40; Кеу=23.
ОЖ.РЕЗ.: Result=False; I=?
Тестовый вариант 9 (нечетный массив, не найден элемент) ТВ9;
ИД: М=15, 20, 25, 30, 35, 40, 45; Кеу=24.
ОЖ.РЕЗ:. Result=False; I=?
Тестовый вариант 10 (единичный массив, не найден элемент) ТВ10:
ИД: М=15; Кеу=0.
ОЖ.РЕЗ.: Result=False; I=?
Тестовый вариант 11 (нарушены предусловия) ТВ11:
ИД: М=15, 10, 5, 25, 20, 40, 35; Кеу=35.
ОЖ.РЕЗ.: Аварийное донесение: Массив не упорядочен.
17. Функциональное тестирование: способ диаграмм причин-следствий.
Диаграммы причинно-следственных связей — способ проектирования тестовых вариантов, который обеспечивает формальную запись логических условий и соответствующих действий [3], [64]. Используется автоматный подход к решению задачи.
Шаги способа:
1) для каждого модуля перечисляются причины (условия ввода или классы эквивалентности условий ввода) и следствия (действия или условия вывода). Каждой причине и следствию присваивается свой идентификатор;
2) разрабатывается граф причинно-следственных связей;
3) граф преобразуется в таблицу решений;
4) столбцы таблицы решений преобразуются в тестовые варианты.
Изобразим базовые символы для записи графов причин и следствий (cause-effect graphs).
Сделаем предварительные замечания:
1) причины будем обозначать символами с i, а следствия — символами еi;
2) каждый узел графа может находиться в состоянии 0 или 1 (0 — состояние отсутствует, 1 — состояние присутствует).
Функция тождество (рис. 7.4) устанавливает, что если значение с 1 есть 1, то и значение е1 есть 1; в противном случае значение е1 есть 0.

Функция тождество
Функция не устанавливает, что если значение с 1 есть 1, то значение e1 есть 0; в противном случае значение е 1 есть 1.

Функция не
Функция или устанавливает, что если с 1 или с2 есть 1, то е1 есть 1, в противном случае e1 есть 0.

Функция или
Функция устанавливает, что если и с 1 и с2 есть 1, то е1 есть 1, в противном случае е1 есть 0.
Часто определенные комбинации причин невозможны из-за синтаксических или внешних ограничений. Используются перечисленные ниже обозначения ограничений.

Функция и
Ограничение Е (исключает, Exclusive, рис. 7.8) устанавливает, что Е должно быть истинным, если хотя бы одна из причин — а или b — принимает значение 1 (а и b не могут принимать значение 1 одновременно).

Ограничение Е (исключает, Exclusive)
Ограничение I (включает, Inclusive) устанавливает, что по крайней мере одна из величин, а, b, или с, всегда должна быть равной 1 (а, b и с не могут принимать значение 0 одновременно).

Ограничение I (включает, Inclusive)
Ограничение О (одно и только одно, Only one, рис. 7.10) устанавливает, что одна и только одна из величин а или b должна быть равна 1.

Ограничение О (одно и только одно, Only one)
Ограничение R (требует, Requires) устанавливает, что если а принимает значение 1, то и b должна принимать значение 1 (нельзя, чтобы а было равно 1, a b - 0).

Ограничение R (требует, Requires)
Часто возникает необходимость в ограничениях для следствий.
Ограничение М (скрывает, Masks) устанавливает, что если следствие а имеет значение 1, то следствие b должно принять значение 0.

Ограничение М (скрывает, Masks)
18. ООАП. Унифицированный процесс. Этапы разработки. Модели.
Обсудим назначение, цели, содержание и основные итоги каждого этапа унифицированного процесса разработки.
Этап НАЧАЛО (Inception)
Главное назначение этапа — запустить проект.
Цели этапа НАЧАЛО:
ü определить область применения проектируемой системы (ее предназначение, границы, интерфейсы с внешней средой, критерий признания — приемки);
ü определить элементы Use Case, критические для системы (основные сценарии поведения, задающие ее функциональность и покрывающие главные проектные решения);
ü определить общие черты архитектуры, обеспечивающей основные сценарии, создать демонстрационный макет;
ü определить общую стоимость и план всего проекта и обеспечить детализированные оценки для этапа развития;
ü идентифицировать основные элементы риска. Основные действия этапа НАЧАЛО:
ü формулировка области применения проекта — выявление требований и ограничений, рассматриваемых как критерий признания конечного продукта;
ü планирование и подготовка бизнес-варианта и альтернатив развития для управления риском, определение персонала, проектного плана, а также выявление зависимостей между стоимостью, планированием и полезностью;
ü синтезирование предварительной архитектуры, развитие компромиссных решений проектирования; определение решений разработки, покупки и повторного использования, для которых можно оценить стоимость, планирование и ресурсы.
В итоге этапа НАЧАЛО создаются следующие артефакты:
ü спецификация представления основных проектных требований, ключевых характеристик и главных ограничений;
ü начальная модель Use Case (20% от полного представления); а начальный словарь проекта;
ü начальный бизнес-вариант (содержание бизнеса, критерий успеха — прогноз дохода, прогноз рынка, финансовый прогноз);
ü начальное оценивание риска;
ü проектный план, в котором показаны этапы и итерации.
Этап РАЗВИТИЕ (Elaboration)
Главное назначение этапа — создать архитектурный базис системы.
Цели этапа РАЗВИТИЕ:
ü определить оста

