




Экономической статистики
Математико-статистические методы изучения связей в современных системах экономического анализа применяются весьма широко и включают корреляционный, регрессионный, дисперсионный, кластерный анализ. Указанные методы используются в системе стохастического моделирования и, в определенной степени, представляют собой дополнение и углубление системы детерминированного анализа. В практике экономического анализа безопасности коммерческой деятельности, а также в системе анализа налогообложения эти методы могут широко использоваться по мере необходимости. При использовании этих методов, как правило, требуется обеспечить достижение следующих целей анализа:
· оценка уровней влияния факторов на результативный показатель, по которым нельзя построить жестко детерминированную модель;
· изучение и сравнение уровней влияния факторов, которые невозможно включить в одну и ту же детерминированную модель;
· выделение и оценка уровней влияния сложных факторов, которые не могут быть выражены каким-то одним количественным показателем (характеристикой).
Применение стохастического подхода, в отличие от детерминированного подхода, требует выполнения некоторых предпосылок. Прежде всего, это требование наличия достаточно большой совокупности объектов. Так, если для анализа детерминированной модели достаточно даже одного объекта, то для анализа стохастической модели необходима уже совокупность объектов. Кроме того, для стохастического анализа нужен достаточный объем наблюдений, так как лишь по одному-двум наблюдениям нельзя судить о характере стохастической связи.
Особенностью использования стохастических моделей в экономике, в отличие от многих других областей исследования, считается трудность получения совокупности данных достаточного объема. Если, например, в ходе технического исследования можно повторить тот или иной эксперимент, то в экономике этого сделать нельзя. Поэтому в системе экономического анализа нередко приходится работать в условиях малых выборок (менее 20 наблюдений). Кроме того, одним из требований статистических расчетов при построении регрессии является достаточность количества наблюдений, которое в 6-8 раз должно превышать количество исследуемых факторов, что в практике экономического анализа наблюдается крайне редко.
Поскольку стохастическая модель, как правило, выражается уравнением регрессии, ее построение требует соблюдения ряда следующих условий:
· случайность наблюдений;
· качественная и количественная однородность совокупности (показателем количественной однородности совокупности является показатель вариации, который рассматривается ниже);
· наличие специального математического аппарата для проведения вычислений.
При этом следует учитывать, что стохастическое моделирование предназначено для решения трех основных задач:
1. Установление факта наличия или отсутствия статистически значимой связи между изучаемыми результативными и факторными признаками.
2. Прогнозирование неизвестных значений результативных показателей по заданным значениям факторных признаков (это, по существу, задачи интерполяции и экстраполяции).
3. Выявление причинных связей между изучаемыми показателями, измерение их тесноты и сравнительный анализ степени влияния.
Проведение стохастического моделирования и выявление связей представляет собой достаточно сложный процесс, состоящий из нескольких этапов, на каждом из которых необходимо выполнить определенные процедуры. Ниже приводятся характеристики основных этапов стохастического моделирования.
Этап 1. Качественный анализ.
Данный этап включает следующий набор действий:
· постановка цели анализа;
· определение совокупности данных, используемых для анализа;
· определение результативных признаков;
· определение факторных признаков;
· выбор периода анализа;
· выбор метода анализа.
Этап 2. Предварительный анализ моделируемой
совокупности данных.
Данный этап стохастического моделирования предполагает выполнение следующих действий:
· проверка однородности совокупности;
· исключение аномальных наблюдений;
· уточнение необходимого объема выборки;
· установление законов распределения изучаемых переменных.
Этап 3. Построение регрессионной модели экономического
объекта.
Данный этап моделирования включает выполнение следующих действий:
· перебор (чередование, выбор) конкурирующих вариантов построения модели;
· уточнение перечня исследуемых факторов, включаемых в модель;
· расчет оценок параметров уравнений регрессии.
Этап 4. Оценка адекватности модели.
На данном этапе выполняются следующие операции:
· проверка статистической значимости уравнения регрессии в целом и его отдельных параметров;
· проверка соответствия формальных свойств полученных оценок задачам исследования.
Этап 5. Экономическая интерпретация и практическое
использование модели.
На данном этапе выполняются следующие действия:
· определение пространственно-временной устойчивости полученных зависимостей;
· оценка прогностических свойств модели.
Перечисленные выше процедуры стохастического анализа имеют ряд методологических особенностей и теоретических аспектов. В этом смысле необходимо выделить следующее:
1. Для анализа следует брать всю имеющуюся совокупность данных. Если эта совокупность слишком велика, необходимо обеспечить тщательность составления выборки из этой совокупности. Выборки должна быть типичной (практически проверенной) для данного круга явлений, в противном случае анализ не будет иметь смысла, поскольку его результаты не позволят сделать значимые выводы для всей совокупности данных.
2. В качестве результативных признаков в экономическом анализе используют либо показатели экономического эффекта (выручка, товарооборот, объем реализации и т.п.), либо показатели экономической эффективности (рентабельность, оборачиваемость, производительность и т.п.). Более предпочтительно использование не абсолютных, а относительных показателей. Этому есть несколько причин, в том числе сравнимость относительных показателей и большая близость их распределений нормальному закону распределения. Последнее обстоятельство также весьма важно, поскольку нормальность распределения признаков является основной предпосылкой корреляционно-регрессионного анализа.
3. В качестве факторных признаков следует выбирать показатели, которые комплексно характеризуют исследуемое экономическое явление. При этом также предпочтительнее ориентироваться на относительные показатели.
- В анализе экономических явлений выделяют два подхода – статистический и динамический. Чаще используется статистический подход, так как он отличается относительной простотой и не требует применения сложных математических методов. Динамический анализ (исследование рядов данных во времени) часто предполагает рассмотрение автокорреляционных зависимостей, что требует применения сложного эконометрического инструментария.
5. Предварительная обработка рядов данных начинается с установления законов распределения (распределение данных должно быть близко к нормальному). В условиях использования малых выборок проверка нормальности распределения проводится путем сравнения эмпирических коэффициентов асимметрии и эксцесса с их средними квадратическими ошибками (их аналитические выражения приводятся ниже). При этом должна быть подтверждена нормальность распределения рядов данных.
6. Проверка однородности сводится к проверке уровня коэффициента вариации. Если совокупность неоднородна, следует исключить из нее наиболее отклоняющиеся, «аномальные» наблюдения, поскольку именно эти наблюдения, скорее всего, нетипичны для данного исследования. Для устранения таких аномальных наблюдений используется правило «трех сигм».
7. Уточнение перечня факторов может осуществляться, например, путем расчета матрицы парных коэффициентов корреляции. Перебор (выбор) конкурирующих вариантов модели, осуществляется, как правило, с использованием компьютеров и прикладных программ.
- Проверка устойчивости модели осуществляется расчетом ее параметров на усеченной или расширенной совокупности, а также на той же совокупности, но уже в другом интервале времени.
Характеристики и методы обработки расчетных данных
в стохастическом моделировании
При изучении некоторой совокупности данных в системе стохастического моделирования используют ряд специфических характеристик. К таким характеристикам относятся средние значения и другие, которые рассматриваются ниже. При стохастическом анализе больших массивов данных обычно интересуются двумя аспектами:
· величинами, которые характеризуют ряд значений как целого (т.е. характеристиками общности);
· величинами, которые описывают различие между членами совокупности (т.е. характеристиками вариации, разброса значений).
Так, все средние величины относятся к первой группе показателей (к характеристикам общности), поскольку являются характеристиками изучаемой совокупности как целого.
Кроме средних величин, в качестве показателей (характеристик) общности также используются следующие величины:
· середина интервала;
· мода;
· медиана.
Середина интервала возможных значений какого-либо показателя 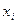 определяется по следующей формуле:
определяется по следующей формуле:
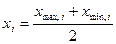 . (6)
. (6)
Мода представляет собой такое значение изучаемого признака, которое среди всех его значений встречается наиболее часто (можно сказать, что это типичное значение случайной величины). В этом случае говорят об унимодальном распределении. Если же чаще других встречаются два или более различных значений, то такую совокупность данных называют соответственно бимодальной или мультимодальной. Если же ни одно из значений совокупности не встречается чаще других (например, все значения совокупности встречаются по одному разу или равное количество раз), то такая совокупность считается безмодальной.
Медиана представляет собой такое значение изучаемой величины, которое делит изучаемую совокупность на две равные части, в которых количество членов со значениями меньше медианы равно количеству членов со значениями больше медианы. Медиану можно найти только в таких совокупностях данных, которые содержат нечетное количество членов.
В отличие от средней величины, медиана не зависит от крайних значений показателей (если увеличивается максимальное или минимальное значение исследуемого показателя, то вместе с ним возрастают все средние величины, но медиана остается неизменной). Поэтому медиана представляется более удобной характеристикой совокупности в тех случаях, когда совокупность данных неоднородна и имеет резкие флуктуации в сторону минимума или в сторону максимума.
В качестве показателей (характеристик) вариации чаще всего используются следующие величины:
· размах вариации;
· среднее линейное отклонение;
· среднеквадратическое отклонение;
· дисперсия;
· коэффициент вариации.
Размах вариации является одним из показателей вариации и характеризует пределы колеблемости (вариацию) индивидуальных значений признака () в совокупности. Размах вариации (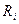 ) представляет собой разность между наибольшим (
) представляет собой разность между наибольшим (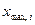 ) и наименьшим (
) и наименьшим (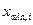 ) значениями i -го признака:
) значениями i -го признака:
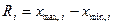 . (7)
. (7)
Среднее линейное отклонение (или средний модуль отклонения 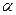 ) представляет собой отклонение значения признака () от среднего арифметического (
) представляет собой отклонение значения признака () от среднего арифметического (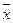 ) и вычисляется по формуле
) и вычисляется по формуле
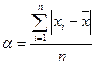 . (8)
. (8)
В случае использования весовых коэффициентов (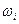 ) формула расчета средневзвешенного среднего линейного отклонения будет иметь следующий вид:
) формула расчета средневзвешенного среднего линейного отклонения будет иметь следующий вид:
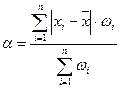 , (9)
, (9)
где - частота, с которой в изучаемой совокупности
встречается значение признака .
Наибольшее распространение при изучении вариации (разброса) значений числовых данных получили величины среднеквадратического отклонения и дисперсии.
Дисперсия представляет собой математическое ожидание квадрата отклонения случайной величины от ее математического ожидания.
Дисперсией также называют средний квадрат отклонения значений признака от его среднего отклонения в генеральной совокупности. Чем больше величина дисперсии, тем сильнее разброс значений признака вокруг среднего.
Расчет величины дисперсии (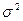 ) ведут как по формуле взвешенной дисперсии, так и по формуле невзвешенной дисперсии. Формула расчета невзвешенной дисперсии имеет вид
) ведут как по формуле взвешенной дисперсии, так и по формуле невзвешенной дисперсии. Формула расчета невзвешенной дисперсии имеет вид
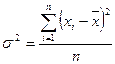 , (10)
, (10)
где - математическое ожидание случайной величины .
В свою очередь, значение математического ожидания случайной величины можно определить по формуле
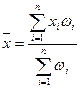 . (11)
. (11)
Формула расчета взвешенной дисперсии имеет такой вид:
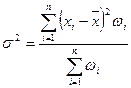 . (12)
. (12)
Среднеквадратическое отклонение (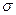 ) представляет собой корень второй степени из среднего квадрата отклонений значений признака от их средней величины (математического ожидания). Расчет среднеквадратического отклонения ведется по следующим формулам:
) представляет собой корень второй степени из среднего квадрата отклонений значений признака от их средней величины (математического ожидания). Расчет среднеквадратического отклонения ведется по следующим формулам:
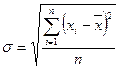 ; (13)
; (13)
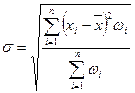 ; (14)
; (14)
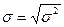 . (15)
. (15)
Чем больше величина или , тем сильнее разброс значений () вокруг среднего. Следует отметить, что всегда больше модуля среднего линейного отклонения . Так, для нормально распределенных величин имеет место соотношение
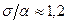 . (16)
. (16)
Если соотношение (16) не выполняется, то это свидетельствует о том, что в исследуемом массиве данных есть элементы, неоднородные с основной массой, т.е. сильно выбивающиеся по своей величине из общего ряда. В зависимости от решаемой задачи следует определить порядок исключения этих выбивающихся элементов из рассмотрения, либо не использовать их при построении некоторых моделей, поскольку эти элементы являются как бы исключениями из правила.
Как следует из определения величина среднеквадратического отклонения зависит от абсолютных значений изучаемого признака: чем больше величины , тем больше будет .
Поэтому вводится показатель коэффициента вариации (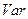 ), чтобы сравнивать ряды данных, отличающихся по абсолютным величинам:
), чтобы сравнивать ряды данных, отличающихся по абсолютным величинам:
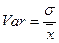 . (17)
. (17)
Коэффициент вариации является относительной мерой вариации и представляет собой отношение среднеквадратического отклонения () к средней величине признака (). Коэффициент вариации является показателем количественной неоднородности исследуемой совокупности данных. При этом его значение, равное =33% считается критическим. Если 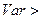 33%, то исследуемую совокупность нельзя признать однородной.
33%, то исследуемую совокупность нельзя признать однородной.
Чем меньше величина , тем меньше данные в совокупности отличаются друг от друга (тем меньше варианты признака отличаются один от другого по величине, тем однороднее исследуемая совокупность данных).
Таким образом, коэффициент вариации , будучи относительной величиной, абстрагирует различия абсолютных величин рядов данных и дает возможность их объективного сравнения.
Другими важнейшими аналитическими характеристиками вариационных рядов в системе стохастического моделирования являются асимметрия и крутизна распределения исследуемых данных. Наряду с показателями общности и вариации они играют существенную роль в применении методов изучения связей.
Степень асимметрии распределения данных характеризуется коэффициентом асимметрии (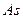 ):
):
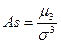 , (18)
, (18)
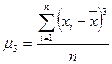 ; (19)
; (19)
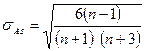 , (20)
, (20)
где  - количество наблюдений.
- количество наблюдений.
Какое-либо распределение случайных величин (данных) будет считаться симметричным в том случае, если = 0. Чем больше величина данного распределения, тем оно более асимметрично. Если распределение асимметрично, это означает, что одна из его ветвей имеет более пологий «спуск», чем другая ветвь распределения данных. В случае отрицательного коэффициента асимметрии ( < 0) более пологий «спуск» полигона данных наблюдается слева, а в противоположном случае ( > 0) – справа. В первом случае асимметрию называют левосторонней ( < 0), во втором случае ( > 0) – правосторонней.
Крутизна распределения данных исследования характеризуется показателем эксцесса (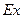 ):
):
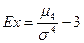 ; (21)
; (21)
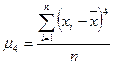 ; (22)
; (22)
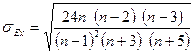 . (23)
. (23)
Для нормального распределения = 0. Большой положительный эксцесс ( > 0) означает, что в совокупности данных есть «ядро», слабо варьирующее по данному признаку, окруженное редкими, сильно отличающимися от него значениями. Большое отрицательное значение показателя эксцесса ( < 0) говорит об отсутствии такого «ядра» в распределении данных. Графически это можно представить так: если распределению соответствует отрицательный эксцесс ( < 0), то соответствующий полигон распределения данных имеет более пологую вершину, а если распределению соответствует положительный эксцесс ( < 0), то полигон распределения данных более крутой по сравнению с нормальным распределением.
Перечисленные характеристики распределения данных в системе стохастического моделирования позволяют сформулировать условия предварительной обработки рядов данных. Такая предварительная обработка данных исследования начинается с установления законов их распределения: распределение данных должно удовлетворять нормальному закону (или быть близким к нормальному распределению).
В условиях малых выборок, т.е. в обычной ситуации для экономических исследований, проверка нормальности распределений признаков проводится методом сравнения эмпирических коэффициентов асимметрии и эксцесса, аналитические выражения которых представлены в формулах (18) – (23), с их средними квадратическими ошибками (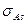 и
и 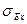 ).
).
При этом нормальность распределения подтверждается, если выполнены следующие неравенства:
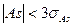 ; (24)
; (24)
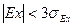 . (25)
. (25)
Проверка однородности данных сводится к проверке следующего соотношения ( - коэффициент вариации):
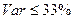 . (26)
. (26)
Если будет установлена, что рассматриваемая совокупность данных неоднородна, то следует исключить из нее наиболее отклоняющиеся, «аномальные» данные, поскольку они, скорее всего, нетипичны для проводимого исследования.
Для устранения «аномальных» данных из дальнейшего рассмотрения используется правило «трех сигм». Указанное правило гласит: наблюдение (конкретное значение исследуемого признака) признается «аномальным» и отбрасывается, если его отклонение от выборочной средней (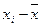 ) более чем в 3 раза превышает среднеквадратическое отклонение выборки ().
) более чем в 3 раза превышает среднеквадратическое отклонение выборки ().
Согласно правилу «трех сигм», считается практически невозможным событие, заключающееся в отклонении значения нормально распределенной случайной величины от его математического ожидания или выборочной средней больше, чем на три среднеквадратических отклонения (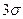 ). Вероятность такого события равна 0,0027.
). Вероятность такого события равна 0,0027.
Следовательно, для нормально распределенных данных должно выполняться следующее условие:
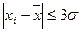 . (27)
. (27)
Уточнение перечня исследуемых факторов в системе моделирования с нормальным многомерным распределением может осуществляться, например, путем расчета матрицы парных коэффициентов корреляции.

