




Инструкция по оформлению статей на конференцию ИТиС-2017
1. Статья объемом от 3 до 10 страниц формата А4 в редакторе Microsoft Word.
2. Размеры полей: левое – 2 см, правое – 2 см, верхнее – 2 см, нижнее – 2см. Шрифт TimesNewRoman, размер – 14, интервал – одинарный (для всей статьи).
3. Порядок размещения материала:
- сведения об авторах (не более трех), которые состоят из инициалов и фамилий в именительном падеже (через запятую, заглавными буквами, по центру, без точки);
- название статьи (заглавными буквами, без абзаца, по центру, без заключительной точки);
- аннотация на русском языке (не более 500 знаков);
- текст статьи (абзац 1,25, ссылки на литературу в квадратных скобках);
- иллюстрации в статье могут быть двух типов – «плавающие» – прижатые к верхнему или нижнему краю области текста, и «встроенные» – размещенные между абзацами внутри колонок текста;
- при использовании графических средств иллюстрацию выполнять как единый объект «рисунок».
- сложные формулы набирать с помощью редактора MathType. Настройки редактора формул: Full – 12pt; Subscript/Superscript – 7pt; Sub-subscript – 5pt; Symbol – 18pt; Sub-symbol – 12pt;
- литература указывается в конце основного текста с заголовком «Библиографический список», без заключительной точки, нумерация источников цифрами с точкой;
- контактная информация об авторах статьи: название организации/института/ университета (без абзаца, по центру, без точки), должность, ученое звание, электронная почта;
- фамилии и инициалы авторов, название статьи и аннотация на английском языке.
ПРИМЕР ОФОРМЛЕНИЯ СТАТЬИ
С. А. Петунин
РАЗРАБОТКА СТАТИСТИЧЕСКИХ МЕТОДОВ АНАЛИЗА ИСТОРИЧЕСКИХ ДАННЫХ ЗАГРУЗКИ HPC-СИСТЕМ
Предложена методика анализа загрузки промышленных суперкомпьютеров уровня предприятия, базирующаяся на оценке статистических шаблонов программных приложений.
Обеспечение эффективной загрузки ресурсов высокопроизводительных вычислительных систем напрямую связано с созданием и использованием адаптивной технологии взаимодействия технического персонала и пользователей, которая бы учитывала не только особенности аппаратуры вычислительных кластеров, но и специфику рабочей нагрузки запускаемых приложений. Построение подобной системы обработки информации, ориентированной на качественное проведение массовых расчетов, невозможно без хорошего понимания статистических характеристик и шаблонов пользовательских заданий.
Большинство известных классификационных моделей рабочей нагрузки опирается на следующую интерпретацию [1; 2]:
- определение совокупности вычислительных заданий как объектов потребления суперкомпьютерных ресурсов;
- выделение групп субъектов-пользователей, генерирующих эти задания и имеющих различия по активности и параметрам запрашиваемых ресурсов […].
Для обеспечения подобной классификации необходимо обязать пользователя указывать эти дополнительные поля при запуске задания. […]. Таким образом, предлагается расширить традиционную модель кластеризации входного потока заданий на основе поведения пользователей следующим образом:
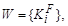
где i =1, 2, …, n (n — количество кластеров);
F = <пользователь | задача | код |…> (тип фактора) методика кластеризации:
k-means и др.;
параметры вектора: < A, { Ri }, { Ki }>
A — активность по фактору (доля заданий, %);
Ri — запрашиваемые ресурсы (например, R 1 — количество запрашиваемых узлов, R 2 — запрашиваемое время);
Ki — дополнительная группа параметров.
В таблице приведен пример вычисленных статистических характеристик ресурсной модели с параметрами R 1 (узлы) и R 2 (время выполнения) при группировке входного потока по двум категориям («пользователи» и «задачи») в 3 кластера, проведенной для 6-месячной выборки. Значения параметров нормализованы для проведения кластеризации. Графический результат кластеризации иллюстрируется на рис. 1.


Рис. 1. Кластеризация по ресурсной модели в категориях «пользователь» и «задача»
Полученные статистические шаблоны поведения входного потока возможно использовать:
- при выборе и тюнинге алгоритмов управления заданиями;
- для назначения единых политик распределения ресурсов для кластерных групп.
Значения нормализованных параметров
ресурсной модели кластеризации
| Кластер | Доля заданий, % | mean узлы R1 | sd узлы | mean TRUN R 2 | sd TRUN |
| KUSER 1 | 1.3 | 0.6 | 0.8 | 0.6 | |
| KUSER 2 | 1.2 | 1.0 | 3.7 | 1.0 | |
| KUSER 3 | 1.5 | 0.8 | 1.4 | 0.9 | |
| KTASK 1 | 2.8 | 3.2 | 2.1 | 1.4 | |
| KTASK 2 | 3.5 | 3.1 | 4.8 | 5.5 | |
| KTASK 3 | 5.7 | 5.9 | 42.5 | 42.0 |
Существует три штатных подхода для анализа эффективности выполнения параллельного приложения:
1) проведение профилирования своей программы самим пользователем;
2) сбор и анализ некоторых данных о выполнении программы на уровне системы мониторинга;
3) анализ временны´ х характеристик использования ресурсов, сохраненных планировщиком в исторической базе данных […].
Применим следующую методику: в качестве индикаторов эффективности алгоритмов решателей программ определим и исследуем поведение двух параметров:
1. Доля затрат на системное время — коэффициент эффективности Kef1. Kef1 = Tsys / (Tsys + Tuser). Если его величина, находящаяся в интервале (0,1), превышает значение 0,5, это говорит о том, что более половины времени своего выполнения программа тратила на вызовы ядра операционной системы.
2. Второй индикатор показывает отношение разницы между потребленным вычислительным ресурсом кластера (процессорным временем TCPU) и суммой времен системной и пользовательской фазы задания, используемых в предыдущей формуле. Можно попытаться интерпретировать это отношение как коэффициент «непараллельности» задания — Kef2.
Kef 2 = (TCPU – (Tsys + Tuser)) / TCPU […].
Поддержка описанных выше методик анализа эффективности реализована в составе общих возможностей аналитического программного комплекса ANTIK. Программа обеспечивает следующий основной функционал:
- проведение статистического анализа временных, […];
- формирование отчетов с обобщенной статистикой по различным группам;
- визуализацию всех статистических данных как базовых, так и консолидированных в виде различных графических представлений (рис. 3);

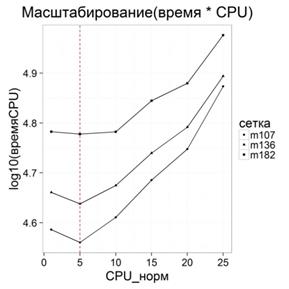
Рис. 3. Определение точек перегиба масштабирования вычислительных узлов для временных метрик расчетной модели
- обеспечение интерактивности работы аналитика с возможностью замены и масштабирования исследуемых показателей непосредственно на визуализируемых графиках;
- проведение анализа эффективности выполненных заданий с помощью специальных оценочных коэффициентов;
- унификацию и легкость импорта исторических данных планировщика slurm в систему анализа из любой суперкомпьютерной системы без необходимости описания ее вычислительной конфигурации.
Программное обеспечение реализовано с помощью статистической системы программирования на базе языка R. Для построения интерфейсной части ANTIK используется веб-фреймворк shiny.
Библиографический список
1. Mishra, A. K. Towards Characterizing Cloud Backend Workloads: Insights from Google Compute Clusters / A. K. Mishra, J. L. Hellerstein, W. Cirne, C. R. Das // ACM SIGMETRICS Performance Evaluation Review. 2010. Vol. 37, № 4. P. 34–41.
2. Moreno, I. S. Analysis, Modeling and Simulation of Workload Patterns in Large-Scale Utility Cloud / I. S. Moreno, P. Garraghan, P. Townend, J. Xu // IEEE Transactions on Emerging Topics in Computing. 2014.
3. Petunin, S. A. Management of HPC Clusters: Development and Maintenance / S. A. Petunin, K. V. Ivanov, A. B. Novikov // Proc. of the 15th International Workshop on Computer Science and Information Technologies CSIT’2013’. Vienna; Budapest; Bratislava, 2013. P. 43–46.
4. Петунин, С. А. Методика начального анализа рабочей нагрузки вычислительных кластеров / С. А. Петунин // Информационные технологии и системы: тр. Четвертой Междунар. науч. конф., Банное. Россия, 25 февр. — 1 марта 2015 г. Челябинск: Изд-во Челяб. гос. ун-та, 2015. С. 129–130.
Сведения об авторе
Петунин Сергей Александрович — кандидат физико-математических наук, главный специалист Всероссийского научно-исследовательского института автоматики им. Н. Л. Духова, Москва. E-mail.
S. A. Petunin

