




1. Найти и удержать единственный экземпляр сегмента. Эта операция подобна первой операции поиска GET UNIQUE, единственным отличием этой операции является то, что после выполнения этой операции над найденным экземпляром сегмента допустимы операции модификации (изменения) данных.
Синтаксис:
GET HOLD UNIQUE <имя сегмента> WHERE <список поиска>2. Найти и удержать следующий с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую операции поиска GET NEXT с возможностью выполнения последующей модификации данных.
Синтаксис:
GET HOLD NEXT [WHERE дополнительные условия>]3. Получить и удержать следующий для того же родителя. Эта операция является аналогом операции поиска 3, но разрешает выполнение операций модификации данных после себя.
Синтаксис:
GET HOLD NEXT WITHIN PARENT [ where <дополн.условия>]Операторы модификации данных
1. Удалить
Это первая из трех операций модификации.
Синтаксис:
DELETEЭта команда не имеет параметров. Почему? Потому что операции модификации действуют на экземпляр сегмента, найденный командами поиска с удержанием. А он всегда единственный текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента. Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
2. Обновить
Синтаксис:
UPDATEКак же происходит обновление, если мы и в этой команде не задаем никаких параметров. СУБД берет данные из рабочей области пользователя, где в шаблонах записей соответствующих внутренних переменных находятся значения полей каждого сегмента внешней модели, с которой работает данный пользователь. Именно этими значениями и обновляется текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации UPDATE, необходимо присвоить соответствующим переменным новые значения.
Ввести новый экземпляр сегмента.
INSERT <имя сегмента>Эта команда позволяет ввести новый экземпляр сегмента, имя которого определено в параметре команды. Если мы вводим данные в сегмент, который является подчиненным некоторому родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим, набор операций поиска и манипулирования данными в иерархической БД невелик, но он вполне достаточен для получения доступа к любому экземпляру любого сегмента БД. Однако следует отметить, что способ доступа, который применяется в данной модели, связан с последовательным перемещением от одного экземпляра сегмента к другому. Такой способ напоминает движение летательного аппарата или корабля по заданным координатам и называется навигационным.
СЕТЕВАЯ МОДЕЛЬ ДАННЫХ
Сетевая модель данных. Одна из первых сетевых моделей данных, разработанная группой CODASYL (Conference of Data System Languages), была предложена в 1969 г. и развивалась до 80-х годов.
(Оригинал смотри здесь http://coronet.iicm.tugraz.at/wbtmaster/allcoursescontent/netlib/library.htm)
Первоначально сетевая модель замышлялась как инструмент для программистов. В качестве базового языка программирования был выбран Cobol.
К известным сетевым системам управления базами данных относятся: DBMS, IDMS, TOTAL, VISTA, СЕТЬ, СЕТОР, КОМПАС и др.
Основное достоинство сетевой модели – это высокая эффективность затрат памяти и оперативность.
Недостаток – сложность и жесткость схемы базы, а также сложность понимания. Кроме того, в этой модели ослаблен контроль целостности, так как в ней допускается устанавливать произвольные связи между записями.
Сравнивая иерархические и сетевые базы данных, можно сказать следующее. В целом иерархические и сетевые модели обеспечивают достаточно быстрый доступ к данным. Но поскольку в сетевых базах основная структура представления информации имеет форму сети, в которой каждая вершина (узел) может иметь связь с любой другой, то данные в сетевой базе более равноправны, чем в иерархической, так как доступ к информации может быть осуществлен, начиная с любого узла.
Однако следует отметить жесткость организации данных в иерархических и сетевых моделях. Доступ к информации осуществляется только в соответствии со связями, определенными при проектировании структуры конкретной базы данных. Базы данных с такими моделями сложно реорганизовывать.
Недостатком этих моделей является и сложность механизма доступа к данным, а также необходимость на физическом уровне четко определять связи данных. А поскольку каждый элемент данных должен содержать ссылки на некоторые другие элементы, то для этого требуются значительные ресурсы памяти ЭВМ. Кроме того, для таких моделей характерна сложность реализации систем управления базами данных.
________________
Сетевая модель – это структура, у которой любой элемент может быть связан с любым другим элементом (рис. 18). Реальный пример иерархической модели представлен на рис. 19.

Рис. 18. Представление связей в сетевой модели данных

Рис. 19. Пример сетевой модели данных
Сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей. Тем самым наборы записей образуют сеть. Связи между записями могут быть произвольными, и эти связи явно присутствуют и хранятся в базе данных.
Над данными в сетевой базе могут выполняться следующие операции:
· Добавить – внести запись в базу данных.
· Извлечь – извлечь запись из базы данных.
· Обновить – изменить значение элементов предварительно извлеченной записи.
· Удалить – убрать запись из базы данных.
· Включить в групповое отношение – связать существующую подчиненную запись с записью-владельцем.
· Исключить из группового отношения – разорвать связь между записью-владельцем и записью-членом.
· Переключить – связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении.
________________
Базовыми объектами сетевой модели являются:
· элемент данных;
· агрегат данных;
· запись;
· набор данных.
Элемент данных — то же, что и в иерархической модели, то есть минимальная информационная единица, доступная пользователю с использованием СУБД.
Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов:
· агрегат типа вектор и
· агрегат типа повторяющаяся группа.
Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа вектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом:
| Адрес | |||
| Город | Улица | дом | квартира |
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
| Зарплата | |
| Месяц | Сумма |
| . | . |
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию "сегмент" в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи.
Следующим базовым понятием в сетевой модели является понятие "Набор". Набором называется двухуровневый граф, связывающий отношением "один-ко-многим" два типа записи.

Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора.
Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение "многие-ко-многим" между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора.
Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
В качестве примера рассмотрим таблицу, на основе которой организуем два набора и определим связь между ними:
| Преподаватель | Группа | День недели | № пары | Аудитория | Дисциплина |
| Иванов | Понедельник | 22-13 | КИД | ||
| Иванов | Понедельник | 22-13 | КИД | ||
| Карпова | Вторник | 22-14 | БЗ и ЭС | ||
| Карпова | Вторник | 22-14 | БЗ и ЭС | ||
| Карпова | Вторник | 22-14 | БД | ||
| Смирнов | Вторник | 23-07 | ГВП | ||
| Смирнов | Вторник | 23-07 | ГВП |
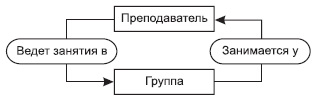
Экземпляров набора Ведет занятия будет 3 (по числу преподавателей), экземпляров набора Занимается у будет 4 (по числу групп). На рис.20 представлены взаимосвязи экземпляров данных наборов.
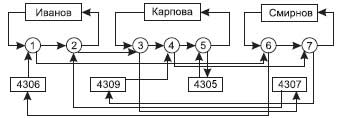
Рис. 20. Пример взаимосвязи экземпляров двух наборов
Среди всех наборов выделяют специальный тип набора, называемый "Сингулярным набором", владельцем которого формально определена вся система. Сингулярный набор изображается в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора, но у которой не определен тип записи "Владелец набора". Например, сингулярный набор М.

Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому если в задаче алгоритм обработки информации предполагает обеспечение произвольного доступа к некоторому типу записи, то для поддержки этой возможности необходимо ввести соответствующий сингулярный набор.
В общем случае сетевая база данных представляет совокупность взаимосвязанных наборов, которые образуют на концептуальном уровне некоторый граф.

