




Управления потоками
Основной задачей любой коммуникационной системы является передача данных между взаимодействующими приложениями с требуемой скоростью и с приемлемой задержкой. На первый взгляд, для этого необходимо чтобы производительность узлов коммутации всегда превосходила интенсивность обрабатываемого ими трафика. Однако, его стохастический характер делает выполнение этого условия крайне затруднительным. Даже реализация механизмов контроля характеристик входящих в сеть потоков и внедрение сложных дисциплин обслуживания очередей в узлах коммутации не всегда защищает сеть от локальных и глобальных перегрузок, при которых нормальная работа приложений становится невозможной.
3.4.1. Перегрузки – источники возникновения и следствия
Перегрузка – это состояние сети, при котором ее производительность неограниченно и неуправляемо падает. Вычисление номинального значения производительность сети, в общем случае, является достаточно сложной задачей, и здесь этот вопрос не рассматриваются. В контексте материала этого раздела будем считать номинальной производительностью сети максимально достижимый объем данных, передаваемых сетью в единицу времени, при приемлемом уровне задержки их доставки.
Можно определить идеальную сеть, как систему, сохраняющую свою производительность на номинальном уровне при сколь угодно большом уровне интенсивности поступающих в неё потоков данных (на графиках рис. 3.15 нагрузка и производительность сети нормированы к их номинальным значениям).
 |
Однако, требование ограниченности времени задержки доставки пакетов при любой нагрузке приводит к требованию неограниченности вычислительной мощности узлов, выполняющих обработку (маршрутизацию) трафика. В условиях же конечной производительности устройств коммутации постоянство производительности сети при больших нагрузках предполагает наличие у них бесконечных буферов, позволяющих сохранить «избыточные» блоки данных. Очевидным следствием этого является бесконечный рост очередей в устройствах коммутации и, соответственно, рост задержки доставки данных (рис. 3.15.б). В реальных условиях (конечные буферы в узлах коммутации и ограниченная их вычислительная мощность) зависимость производительности сети от нагрузки будет иметь вид, представленный на рис. 3.16.
Рост производительности замедляется при уровнях нагрузки, превышающих некоторое значение LA. Это является следствием роста служебного трафика сетевой системы управления потоками, возникающей необходимостью изменения маршрутов доставки блоков данных через сеть и т.д. Состояние сети при нагрузках  часто называют состоянием управляемой перегрузки. При уровнях нагрузки, больших LБ производительность сети начинает падать, поскольку буферы узлов коммутации уже заполнены и прибывающие блоки данных уничтожаются. Последнее вызывает их повторную передачу, что только усугубляет состояние перегрузки, и производительность сети стремится к нулю.
часто называют состоянием управляемой перегрузки. При уровнях нагрузки, больших LБ производительность сети начинает падать, поскольку буферы узлов коммутации уже заполнены и прибывающие блоки данных уничтожаются. Последнее вызывает их повторную передачу, что только усугубляет состояние перегрузки, и производительность сети стремится к нулю.
 |
Состояние перегрузки сети может возникать не только вследствие чрезмерного роста интенсивности входящего трафика, но и по причинам локального характера, т.е. вследствие блокирования отдельных участков сети. Ограничимся лишь двумя примерами подобных явлений.
Если буферная память узлов коммутации является общей для всех его интерфейсов и буферы узла А (рис. 3.17) полностью заняты данными, предназначенными к передаче узлу Б, а буферы последнего полностью заняты блоками данных, адресованными узлу А, то передача по каналу А-Б будет блокирована а коммутаторы А и Б начнут уничтожать все прибывающие кадры (ни один кадр не может быть принят и буферы не могут освободить место для приема).
 |
На рис.3.18 представлена еще одна достаточно реальная ситуация, когда интенсивность одного из поступающих на узел коммутации потоков данных (поток А) оказывается существенно больше интенсивности другого потока. С высокой степенью вероятности интенсивный поток полностью займет буферную память коммутатора и, следовательно, блокирует поток Б.
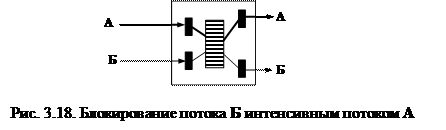 |
Описанные состояния являются предельными вариантами перегрузки участка сети и их называют заторами. В этих случаях увеличение объема буферной памяти не решает проблему, ибо ведет лишь к увеличению задержки в узле коммутации. Единственным выходом остается уничтожение «избыточных» блоков данных и информирование источников потоков о необходимости уменьшения их интенсивности.
Нарушение информационного обмена может возникать не только вследствие перегрузки сети, но и по «вине» приемного узла, который не успевает обрабатывать прибывающие данные и они либо уничтожаются, либо накапливаются в сети, что рано, или поздно, приводит к исчерпанию ее ресурсов. Таким образом, для предупреждения перегрузок необходимо:
- ограничить входные потоки уровнями, не создающими перегрузок локальных узлов коммутации сети, или
- внедрить механизмы, позволяющие как приемнику, так и сети сформировать и быстро передать источнику потока требование об ограничении интенсивности генерации данных; при этом, источник должен иметь возможность адекватно и своевременно отреагировать на это требование.
Именно эти операции (ограничение входных потоков, генерация сигнала перегрузки и реакция на него источника) являются содержанием процедур управления потоками.
3.4.2 Управление сетевым трафиком – цель и механизмы
Цель управления трафиком не сводится только к предупреждению перегрузок сети. В общем случае ее можно определить как достижение эффективного использования и справедливого распределения ресурсов сети (пропускной способности линий связи, процессорного времени, буферов узлов коммутации). Эффективное использование означает, что пропускная способность каналов связи используется почти полностью, буферы коммутирующих устройств не переполнены и требования к качеству транспортировки информационных потоков удовлетворяются. Справедливость распределения ресурсов определить сложнее. Одним из вариантов может быть следующее: «Справедливое распределение ресурсов сети оптимизирует качество передачи потоков данных всех сетевых приложений». Совершенно очевидно, что реализация этого принципа требует строгого определения понятий качества передачи потоков и задания критерия оптимизации. Эти вопросы являются предметом проектирования конкретных сетей.
Средства достижения «справедливого» распределения и эффективного использования ресурсов» весьма разнообразны и включают в себя резервирование сетевых ресурсов для обслуживания определенных потоков, управление очередями в УК и управление потоками. Ведущую роль в этой триаде играет управление потоками. В сетях с коммутацией пакетов эффективная система управления потоками жизненно необходима, а ее элементы присутствуют на разных уровнях стека протоколов.
На сетевом, транспортном и вышележащих уровнях стека протоколов могут применяться методы локального и глобального управления потоками. Локальное управление позволяет предотвращать перегрузки в местах их возникновения. Такое управление требует обмена служебной информацией между соседними узлами коммутации, что усложняет их программное обеспечение и увеличивает служебный сетевой трафик. Тем не менее, методы локального управления широко используется в различных сетях, а для канальных протоколов - они единственно возможные.
Глобальное управление предполагает либо ограничение числа блоков данных, поступающих в сеть с данным потоком в единицу времени вне зависимости от состояния сети, либо ограничение интенсивности входящего потока только при возникновении перегрузок, либо комбинацию этих методов. Достоинством глобального управления является минимальное участие в этом процессе собственно сетевых узлов коммутации.
Ограничение общего числа блоков данных, поступающих в сеть в единицу времени, может быть достигнуто выделением каждому потоку определенной квоты его интенсивности. Определение величины такой квоты и оценка ее приемлемости как для приложения, так и для сети представляет довольно непростую задачу, что и ограничивает возможности применения этого метода. Квотирование чаще всего реализуется генерацией специальных служебных кадров (токенов, маркеров), каждый из которых является разрешением передачи одного блока данных. Поступающий в сеть блок данных потока уносит с собой один токен; если данные есть, а свободных токенов нет, то кадры (пакеты) этого потока в сеть не поступают.
Более гибким методом предупреждения перегрузок является управление интенсивностью трафика отдельных потоков на основании сигналов обратной связи от сети и приемника. Собственно интенсивность потока при этом регулируется узлом-источником, например, изменением его окна передачи. Как сетевой узел, так и приемник, испытывая перегрузку, могут отправить передатчику узла-источника специальное сообщение, содержащее требование уменьшить окно передачи, вплоть до значения Ws=0, при которомпередача данных прекращается. Однако сетевые узлы далеко не всегда отправляют сообщения о перегрузках передатчику (стараются не загружать сеть служебными сообщениями), а получатель может и не подозревать о возникновении локальных перегрузок в сети. Но отправитель, если он использует подтверждаемый сервис, способен обнаружить такую перегрузку зафиксировав чрезмерную задержку подтверждений доставки своих блоков данных или рост уровня их потерь, т.е. рост числа повторных передач. Таким образом, можно регулировать величину окна передачи, используя в качестве управляющего сигнала специальные сообщения сети и приемника, величину времени полного оборота и факт потери блоков данных.
Регулирование размера окна по потерям - алгоритмы Тахо и Рино
 В условиях низкого уровня ошибок в физических средах передачи, потери кадров могут служить для передатчика индикатором перегрузки сетевых устройств коммутации, либо премного узла. На рис.3.20 представлена упрощенная модель, в которой единственное соединение использует узел коммутации, обрабатывающий С кадров/сек.
В условиях низкого уровня ошибок в физических средах передачи, потери кадров могут служить для передатчика индикатором перегрузки сетевых устройств коммутации, либо премного узла. На рис.3.20 представлена упрощенная модель, в которой единственное соединение использует узел коммутации, обрабатывающий С кадров/сек.
Общая стратегия регулирования окна может быть следующей: отправитель, в условиях отсутствия потерь увеличивает свое окно передачи по какому-то закону; обнаружив потерю сегмента (истек тайм-аут получения подтверждения его доставки) размер окна уменьшается до значения W = 1. В непрерывном времени алгоритм описывается простым логическим выражением:
Если потерь нет То  Иначе W = 1.
Иначе W = 1.
Здесь t - текущее время, u – скорость роста величины окна передачи.
Проанализируем характер изменение величины окна. Минимальное время реакции передатчика равно времени полного оборота (RTT=  ). За время передатчик отправляет W кадров. Коммутатор успевает обработать
). За время передатчик отправляет W кадров. Коммутатор успевает обработать 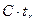 кадров и еще x кадров могут находиться в его буферной памяти, размер которой составляет В кадров. Величина окна W может расти до значения
кадров и еще x кадров могут находиться в его буферной памяти, размер которой составляет В кадров. Величина окна W может расти до значения  не приводя к потерям. Потери начинают возникать, когда буферная память коммутатора полностью заполняется. Поскольку факт возникновения потери кадра будет зафиксирован передатчиком через время тайм-аута (RTO), минимальное значение которого равно времени полного оборота, то текущее значение окна передачи к моменту индикации потери достигает значения
не приводя к потерям. Потери начинают возникать, когда буферная память коммутатора полностью заполняется. Поскольку факт возникновения потери кадра будет зафиксирован передатчиком через время тайм-аута (RTO), минимальное значение которого равно времени полного оборота, то текущее значение окна передачи к моменту индикации потери достигает значения
 .
.
От этого значения размер окна уменьшается до значения W =1. Рис.3.21 иллюстрирует рассмотренный процесс изменение W (t). Такую стратегию реализует простейший алгоритм регулирования окна передачи Оld Tacho.
 |
Результат не очень хорош – средняя величина окна передачи далека от значения, необходимого для номинальной загрузки канала, а  >
>  , т.е. создаются условия, стимулирующие перегрузку сети. Ослабить влияние этих недостатков можно:
, т.е. создаются условия, стимулирующие перегрузку сети. Ослабить влияние этих недостатков можно:
1. модификацией закона изменения величины окна, предупреждающей как его чрезмерное увеличение, так и чрезмерное уменьшение;
2. посредством уменьшения времени задержки обратной связи, т.е. времени реакции передатчика на факт потери кадра.
Эти усовершенствования реализуются в алгоритмах Tacho и Reno.
Алгоритм Tacho. Размер окна от единичного значения увеличивается достаточно быстро (интенсивная загрузка имеющейся пропускной способности), но при достижении некоторого порогового значения скорость его роста существенно уменьшается (аккуратная дозагрузка остающейся свободной пропускной способности). Так, например, если в предыдущем цикле регулирования потеря кадра была зафиксирована при  , то в следующем цикле величина W быстро увеличивается от 1 до значения
, то в следующем цикле величина W быстро увеличивается от 1 до значения  (например, по закону
(например, по закону  ). После достижения указанного значения и до момента фиксации потери кадра величина W растет медленно (например, на единицу за время полного оборота). При фиксации потери, окно уменьшается до единичного значения и цикл регулирования повторяется. Иллюстрация этого процесса приведена на рис. 3.22.
). После достижения указанного значения и до момента фиксации потери кадра величина W растет медленно (например, на единицу за время полного оборота). При фиксации потери, окно уменьшается до единичного значения и цикл регулирования повторяется. Иллюстрация этого процесса приведена на рис. 3.22.
 |
Эти усовершенствования преобразуют простейший алгоритм регулирования окна передачи в алгоритм медленного старта и предупреждения перегрузок (Slow start with congestion avoidance). На интуитивном уровне этим фазам можно дать следующую интерпретацию. Фаза медленного старта – это экспериментальная оценка «емкости» соединения, т.е. числа сегментов данных, которые могут одновременно находиться в канале между конечными узлами. Эта оценка должна быть проведена аккуратно (отсюда отказ от установления величины окна сразу в значение  ), но достаточно быстро (отсюда удвоение текущего значения окна за время RTT). Фаза предупреждения перегрузки – это очень аккуратная попытка заполнить канал максимально возможным числом блоков данных (поскольку ACK-и приходят, то можно аккуратно его «догружать»).
), но достаточно быстро (отсюда удвоение текущего значения окна за время RTT). Фаза предупреждения перегрузки – это очень аккуратная попытка заполнить канал максимально возможным числом блоков данных (поскольку ACK-и приходят, то можно аккуратно его «догружать»).
Дальнейшим развитием алгоритма Tacho явилось ускорение повторной передачи. Сигналом для ускоренной повторной передачи кадра, т.е. передачи его ранее истечения соответствующего тайм-аута, служит получение трех кадров АСК с неизменным значением  . Это заметно сокращает время «простоя» передатчика и способствует лучшему использованию пропускной способности соединения. При этом, индикация потери блока данных по истечению таймера повторной передачи также сохраняется.
. Это заметно сокращает время «простоя» передатчика и способствует лучшему использованию пропускной способности соединения. При этом, индикация потери блока данных по истечению таймера повторной передачи также сохраняется.
Алгоритм Reno исключает фазу медленного старта и вводит быстрое восстановление окна передачи после потери. В каждом цикле алгоритм стартует при 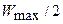 , увеличивает окно до
, увеличивает окно до  (фаза предупреждения перегрузки) и сбрасывает его значение к
(фаза предупреждения перегрузки) и сбрасывает его значение к  после фиксации потери пакета по трем дубликатным ACK. При определении потери блока данных по признаку истечения тайм-аута величина окна устанавливается равной 1. Рис. 3.23 иллюстрирует особенности работы этого алгоритма.
после фиксации потери пакета по трем дубликатным ACK. При определении потери блока данных по признаку истечения тайм-аута величина окна устанавливается равной 1. Рис. 3.23 иллюстрирует особенности работы этого алгоритма.

В алгоритме Reno введено еще одно усовершенствование – быстрое восстановление размера окна передачи (Fast Recovery). Оно имеет целью уменьшить задержки пакетов в канале и повысить коэффициент использования его пропускной способности.
Пусть потеря кадра произошла в момент, когда W = M. Зафиксировав этот факт (по третьему АСК с неизменным  ), отправитель уменьшает значение W до (M/2) (а не до 1) и дублирует кадр А. Поскольку к этому моменту не на все ранее отосланные сегменты были получены подтверждения, то при получении каждого нового АСК с окно передачи увеличивается на 1 (быстрое восстановление окна передачи). Это позволяет передать еще ряд пакетов, номера которых находятся в диапазоне разрешенных окном передачи. (Здесь реализуется логика: «АСК получен, следовательно, один блок успешно покинул сеть и можно послать еще один»). По завершению передачи блоков, разрешенных окном W, отправитель ожидает прибытия подтверждения повторной отправки кадра А – этот момент и является границей фазы быстрого восстановления.
), отправитель уменьшает значение W до (M/2) (а не до 1) и дублирует кадр А. Поскольку к этому моменту не на все ранее отосланные сегменты были получены подтверждения, то при получении каждого нового АСК с окно передачи увеличивается на 1 (быстрое восстановление окна передачи). Это позволяет передать еще ряд пакетов, номера которых находятся в диапазоне разрешенных окном передачи. (Здесь реализуется логика: «АСК получен, следовательно, один блок успешно покинул сеть и можно послать еще один»). По завершению передачи блоков, разрешенных окном W, отправитель ожидает прибытия подтверждения повторной отправки кадра А – этот момент и является границей фазы быстрого восстановления.
После получения подтверждения на кадр с номером А значение окна передачи устанавливается равным W = M/2 и далее реализуется режим регулирования, предотвращающий возникновение перегрузок (т.е. режим медленного роста величины окна). В случае невозможности реализации повторной передачи утерянного кадра до истечения тайм-аута (получено менее 3 дубликатных АСК, либо все кадры разрешенные окном уже отправлены, а подтверждения не получены) окно передачи устанавливается в 1. Достоинством алгоритма Reno, в сравнении с Tacho, является лучшее использование пропускной способности канала в фазе повторной передачи и, почти полное исключение фазы медленного старта.
Транспортный протокол ТСР в своих ранних версиях для регулирования окна передачи использовал алгоритм Tahoe (медленный старт, предотвращение перегрузки и быстрая повторная передача). В последующих версиях применялся алгоритм Reno.

